
Ох, уж эти категориальные данные — разноцветные символы в массивах данных, которые машины, кажется, просто не могут понять. Поэтому «красный» становится 1, «синий» — 2, а дата-сайентисты превращаются в языковых трансляторов (или, скорее, посредников).
Догадываюсь, о чем вы подумали: «Кодирование? Разве это не простое присвоение цифр категориям?». Если бы все было так просто! Предлагаю рассмотреть на одном небольшом наборе данных 6 методов кодирования (разумеется, с визуальными эффектами) — от простых меток до умопомрачительных циклических преобразований. К концу статьи вы поймете, почему выбор подходящего метода кодирования не менее важен, чем выбор идеального алгоритма.

Что такое категориальные данные и почему они нуждаются в кодировании
Прежде чем перейти к набору данных и методам кодирования, выясним, что такое категориальные данные и почему они требуют особого подхода в сфере машинного обучения.
Что такое категориальные данные?
Категориальные данные похожи на описательные этикетки, используемые в повседневной жизни. Они представляют собой характеристики или качества, которые можно объединить в категории.
Почему категориальные данные нуждаются в кодировании?
Дело в том, что большинство алгоритмов машинного обучения переваривают только числа. Они не могут отличить «солнечно» от «дождливо». Вот тут-то и приходит на помощь кодирование. Оно как бы переводит эти категории на язык, который понятен машинам и с которым они могут работать.
Типы категориальных данных
Не все категории созданы одинаковыми. Обычно выделяют два типа.
- Номинальные (nominal) — категории, которые не могут быть упорядочены. Например: «прогноз» (солнечно, пасмурно, дождливо) — номинальный тип: между этими погодными условиями нет естественного ранжирования.
- Порядковые (ordinal) — категории, которые можно упорядочить. Например: «температура» (очень низкая, низкая, высокая, очень высокая) — порядковый тип: существует четкая последовательность от самого холодной температуры к самой жаркой.

Почему необходимо правильно кодировать?
- Правильное кодирование позволяет сохранить важную информацию в данных.
- Способ кодирования может существенно повлиять на производительность модели.
- Неправильное кодирование чревато появлением непреднамеренных предубеждений или взаимосвязей.
Представьте, что мы закодировали «солнечный» как 1, а «дождливый» как 2. Модель может посчитать, что дождливых дней «больше, чем солнечных», а это не то, чего мы хотим!
Теперь, выяснив, что такое категориальные данные и почему они нуждаются в кодировании, посмотрим на примере небольшого набора данных, как можно работать с категориальными переменными, используя 6 методов кодирования.
Набор данных
Для иллюстрации методов кодирования воспользуемся простым набором данных о гольфе (в нем в основном категориальные столбцы). В этом наборе данных фиксируются различные погодные условия:
- Temperature (температура): High (высокая), Low (низкая), Extreme (экстремальная);
- Humidity (влажность): Dry (сухо), Humid (влажно);
- Wind (ветер): Yes (есть), No (нет);
- Outlook (прогноз): Sunny (солнечно), Rainy (дождливо), Overcast (облачно).
Последний столбец регистрирует скопление людей (Crowdedness) на поле для гольфа.

import pandas as pd
import numpy as np
data = {
'Date': ['03-25', '03-26', '03-27', '03-28', '03-29', '03-30', '03-31', '04-01', '04-02', '04-03', '04-04', '04-05'],
'Weekday': ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri'],
'Month': ['Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Apr', 'Apr', 'Apr', 'Apr', 'Apr'],
'Temperature': ['High', 'Low', 'High', 'Extreme', 'Low', 'High', 'High', 'Low', 'High', 'Extreme', 'High', 'Low'],
'Humidity': ['Dry', 'Humid', 'Dry', 'Dry', 'Humid', 'Humid', 'Dry', 'Humid', 'Dry', 'Dry', 'Humid', 'Dry'],
'Wind': ['No', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'No', 'Yes', 'Yes', 'No', 'Yes'],
'Outlook': ['sunny', 'rainy', 'overcast', 'sunny', 'rainy', 'overcast', 'sunny', 'rainy', 'sunny', 'overcast', 'sunny', 'rainy'],
'Crowdedness': [85, 30, 65, 45, 25, 90, 95, 35, 70, 50, 80, 45]
}
# Создание датафрейма (DataFrame) из словаря
df = pd.DataFrame(data)
Как видите, тут много категориальных переменных. Наша задача — закодировать эти переменные так, чтобы модель машинного обучения могла использовать их для предсказания, скажем, скопления людей на поле для гольфа.
Метод 1: кодирование меток
Кодирование меток (Label Encoding) присваивает уникальное целое число каждой категории в категориальной переменной.
Общее применение
Часто используется для порядковых переменных, которым присущ четкий порядок категорий, таких как уровни образования (например, начальное, среднее, высшее) и рейтинги товаров (например, 1 звезда, 2 звезды, 3 звезды).
В данном случае
В наборе данных о гольфе можно использовать кодирование меток для столбца Weekday (День недели). Каждому дню недели будет присвоен уникальный номер (например, Mon (понедельник) = 0, Tue (вторник) = 1 и т. д.). Однако следует соблюдать осторожность, поскольку для модели это может означать, что Sun (воскресенье) (6) «больше», чем Sat (суббота) (5), что не имеет смысла для данного анализа.
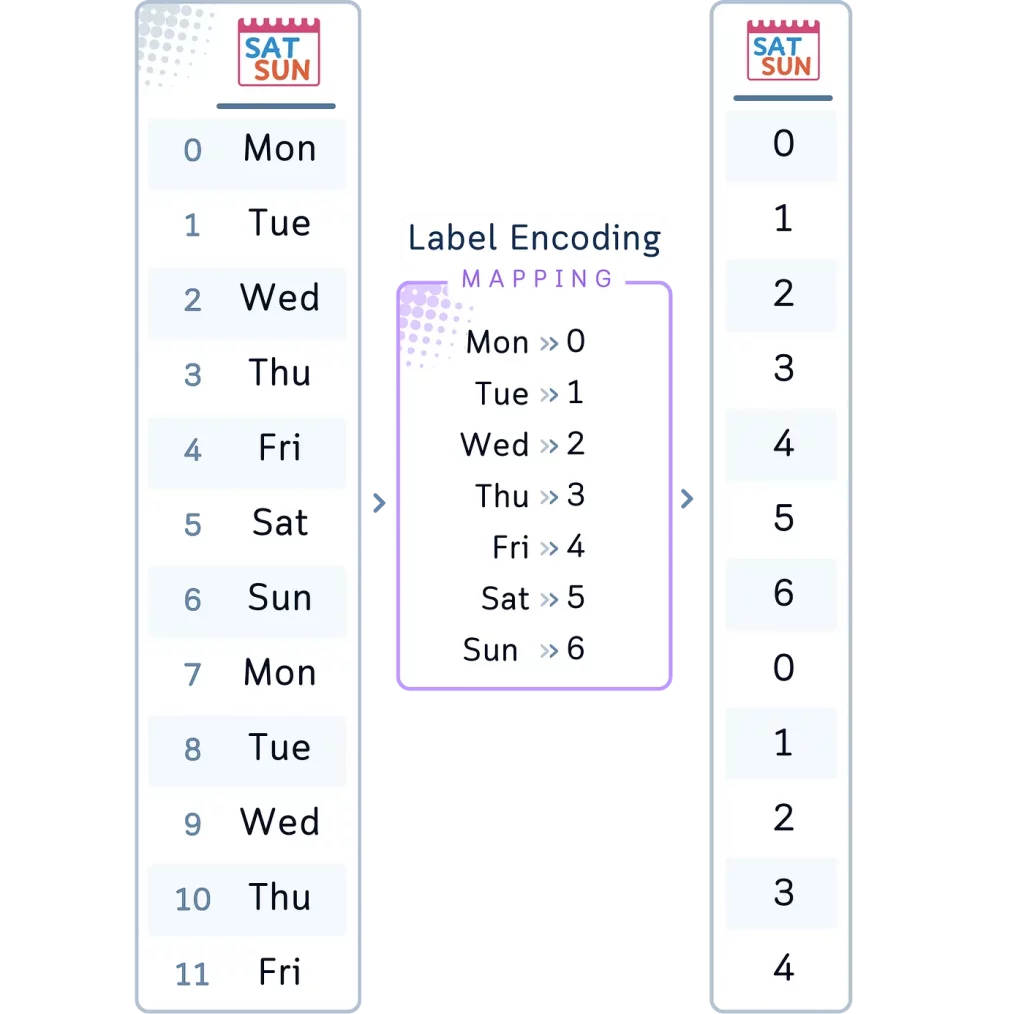
# 1. Кодирование меток для Weekday
df['Weekday_label'] = pd.factorize(df['Weekday'])[0]
Метод 2: прямое кодирование
Прямое кодирование (One-Hot Encoding) создает новый двоичный столбец для каждой категории в категориальной переменной.
Общее применение
Этот метод обычно используется для номинальных переменных, категории которых не могут быть упорядочены. Это особенно полезно при работе с переменными, имеющими относительно небольшое количество категорий.
В данном случае
Прямое кодирование идеально подходит для столбца Outlook (Прогноз). Можно создать три новых столбца: Outlook_sunny (солнечно), Outlook_overcast (облачно) и Outlook_rainy (дождливо). В каждой строке в одном из этих столбцов будет стоять 1, а в остальных — 0, что будет означать состояние погоды на конкретный день.
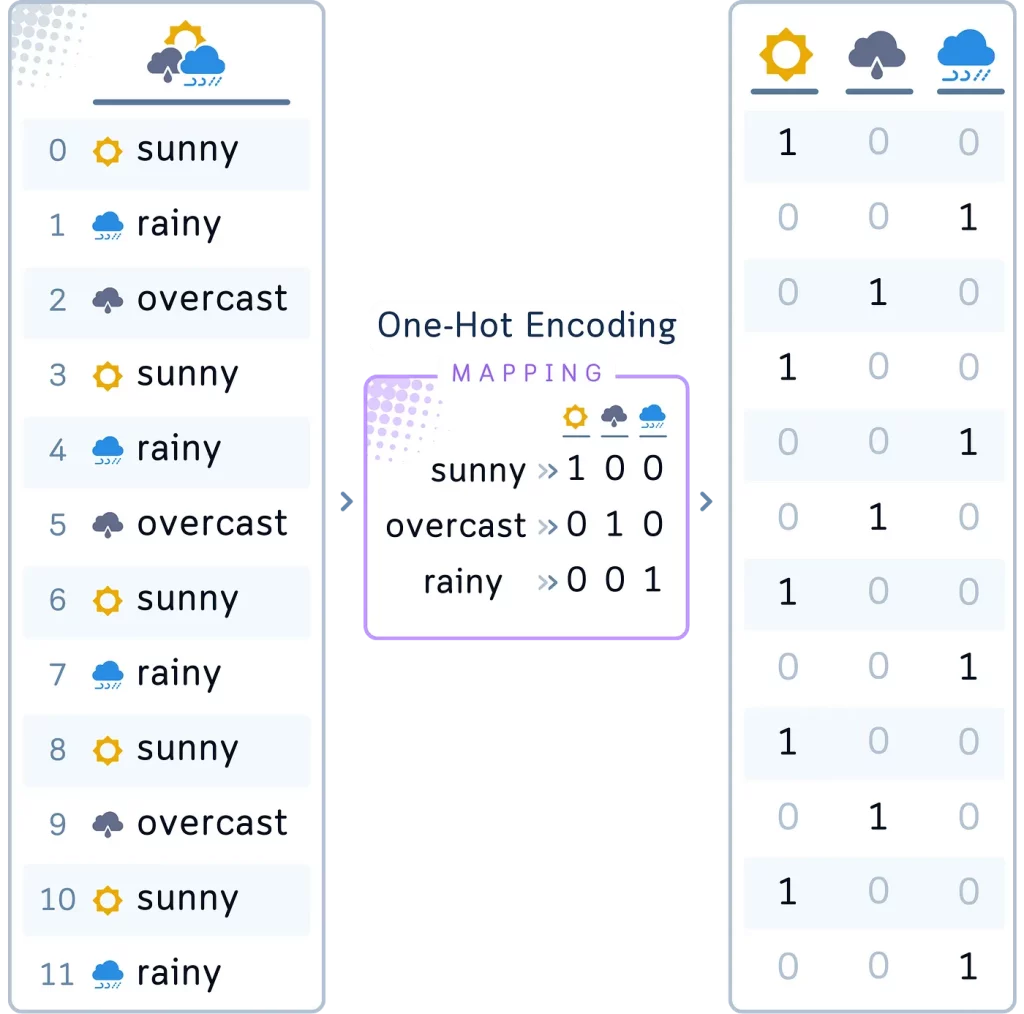
# 2. Прямое кодирование для Outlook
df = pd.get_dummies(df, columns=['Outlook'], prefix='Outlook', dtype=int)
Метод 3: двоичное кодирование
Двоичное кодирование (Binary Encoding) представляет каждую категорию в виде двоичного числа (0 и 1).
Общее применение
Часто используется, когда есть только две категории, в основном в ситуации «да/нет».
В данном случае
Хотя в столбце Wind (Ветер) всего две категории — Yes (да) и No (нет), — можно использовать двоичное кодирование для демонстрации этого метода. В результате получим один двоичный столбец, в котором одна категория (например, No) будет представлена как 0, а другая (Yes) — как 1.
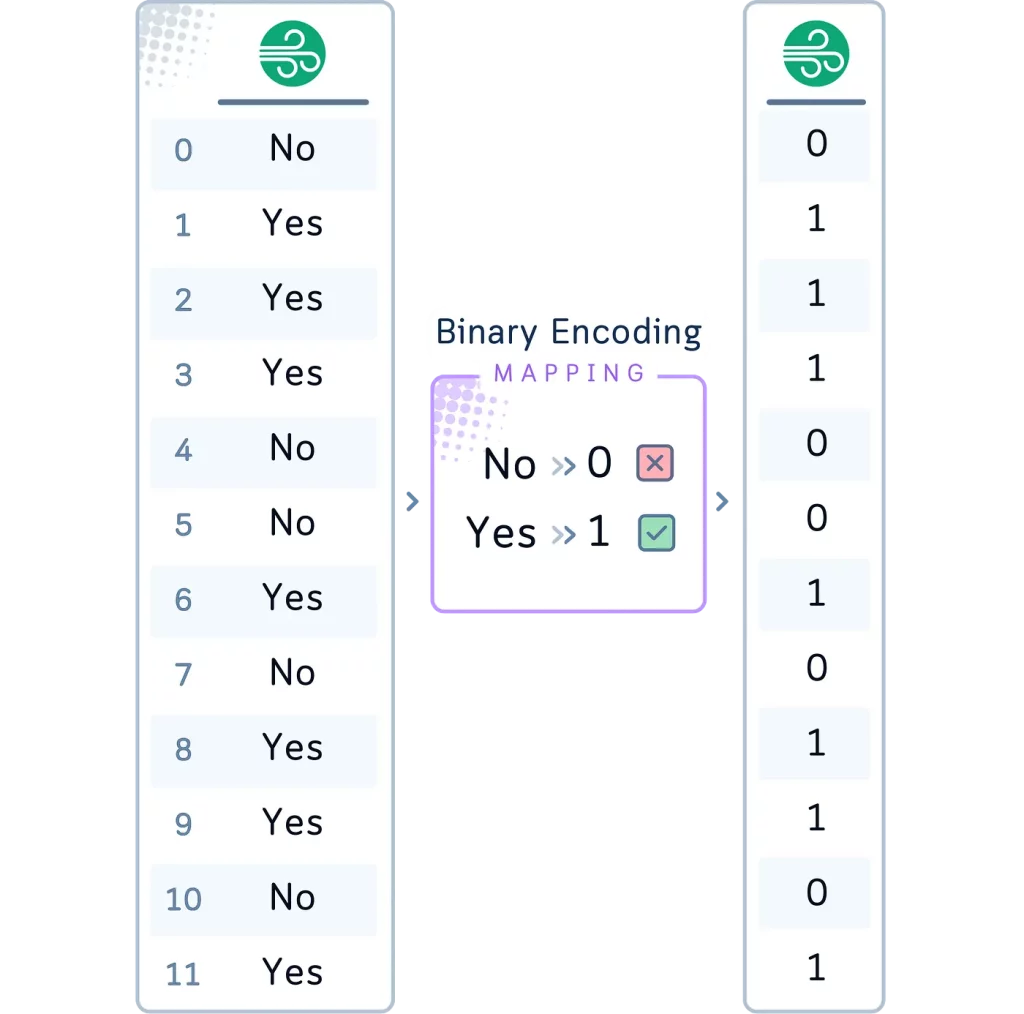
# 3. Двоичное кодирование для Wind
df['Wind_binary'] = (df['Wind'] == 'Yes').astype(int)
Метод 4: целевое кодирование
Целевое кодирование (Target Encoding) заменяет каждую категорию средним значением целевой переменной для этой категории.
Общее применение
Используется, когда существует вероятность связи между категориальной переменной и целевой переменной. Это особенно полезно для признаков с высокой кардинальностью в наборах данных с разумным количеством строк.
В данном случае
Можно применить целевое кодирование к столбцу Humidity (Влажность), используя «crowdedness» («скопление людей») в качестве целевой переменной. Каждое Dry (сухо) или Humid (влажно) в столбце Humidity будет заменено средним значением «crowdedness», наблюдаемым во влажные и сухие дни соответственно.
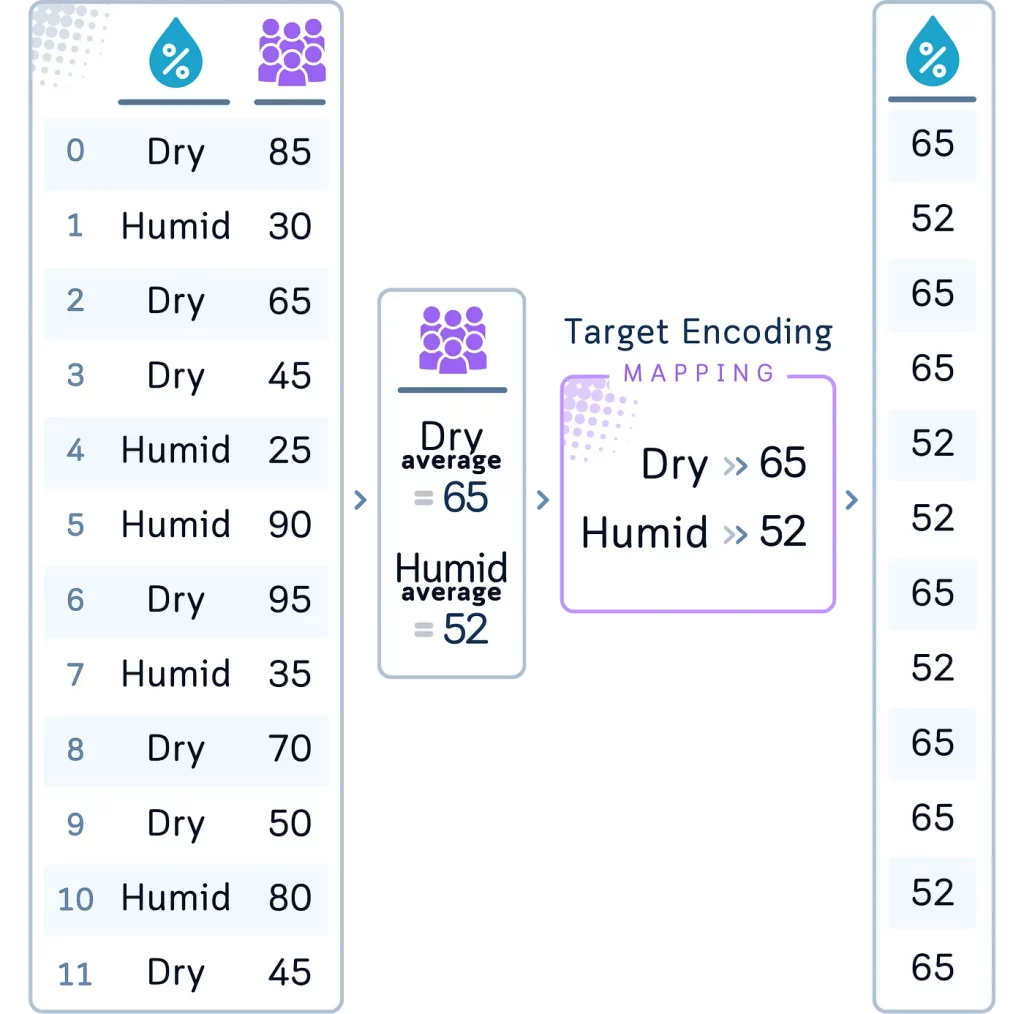
# 4. Целевое кодирование для Humidity
df['Humidity_target'] = df.groupby('Humidity')['Crowdedness'].transform('mean')
Метод 5: порядковое кодирование
Порядковое кодирование (Ordinal Encoding) распределяет упорядоченные целые числа по порядковым категориям на основе присущего им порядка.
Общее применение
Используется для порядковых переменных, где порядок категорий имеет значение, и требуется сохранить информацию об этом порядке.
В данном случае
Порядковое кодирование идеально подходит для столбца «Temperature» («Температура»). Можно присвоить целые числа для представления порядка: Low (низкая) = 1, High (высокая) = 2, Extreme (экстремальная) = 3. Это сохраняет естественный порядок категорий температуры.

# 5. Порядковое кодирование для Temperature
temp_order = {'Low': 1, 'High': 2, 'Extreme': 3}
df['Temperature_ordinal'] = df['Temperature'].map(temp_order)
Метод 6: циклическое кодирование
Циклическое кодирование/преобразование (Cyclic Encoding/Transformation) преобразует циклическую категориальную переменную в две числовые характеристики, которые сохраняют циклический характер переменной. Обычно для представления цикличности используются преобразования синуса и косинуса. Например, можно сначала сделать Month (Месяц) числовым (1-12), а затем создать две новые характеристики:
- Month_cos = cos(2 π (m — 1) / 12);
- Month_sin = sin(2 π (m — 1) / 12);
где m — число от 1 до 12, представляющее месяцы от January (января) до December (декабря).
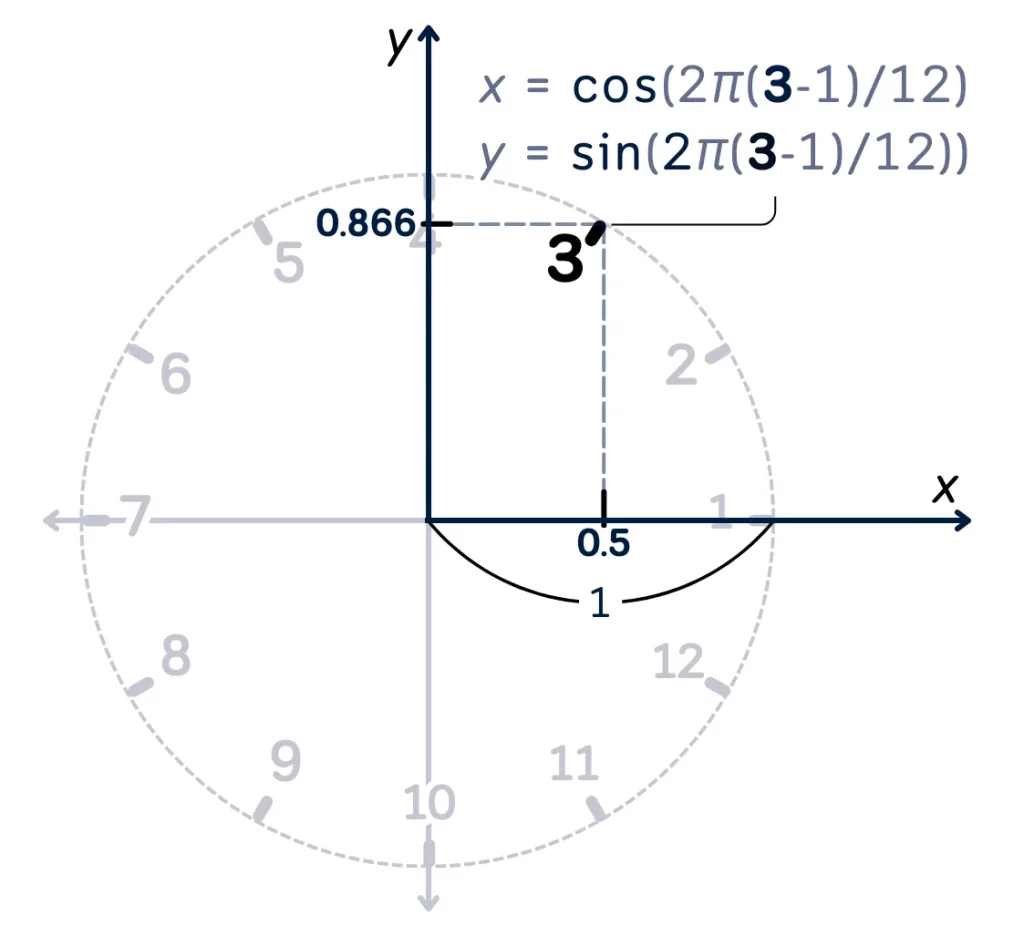
Общее применение
Используется для категориальных переменных, имеющих естественный циклический порядок, таких как дни недели, месяцы года и часы суток. Циклическое кодирование особенно полезно в тех случаях, когда важна «дистанция» между категориями и ее соблюдение ее регулярной повторяемости (например, дистанция между декабрем и январем должна быть небольшой, как и дистанция между любыми другими соседними месяцами).
В данном случае
В наборе данных по гольфу самым подходящим кандидатом для циклического кодирования будет столбец Month (Месяц). Месяцы имеют четкую циклическую закономерность, которая повторяется каждый год. Это может быть особенно полезно для набора данных по гольфу, так как позволяет выявить сезонные закономерности в активности игроков в гольф, которые могут повторяться ежегодно. Вот как можно применить циклическое кодирование:
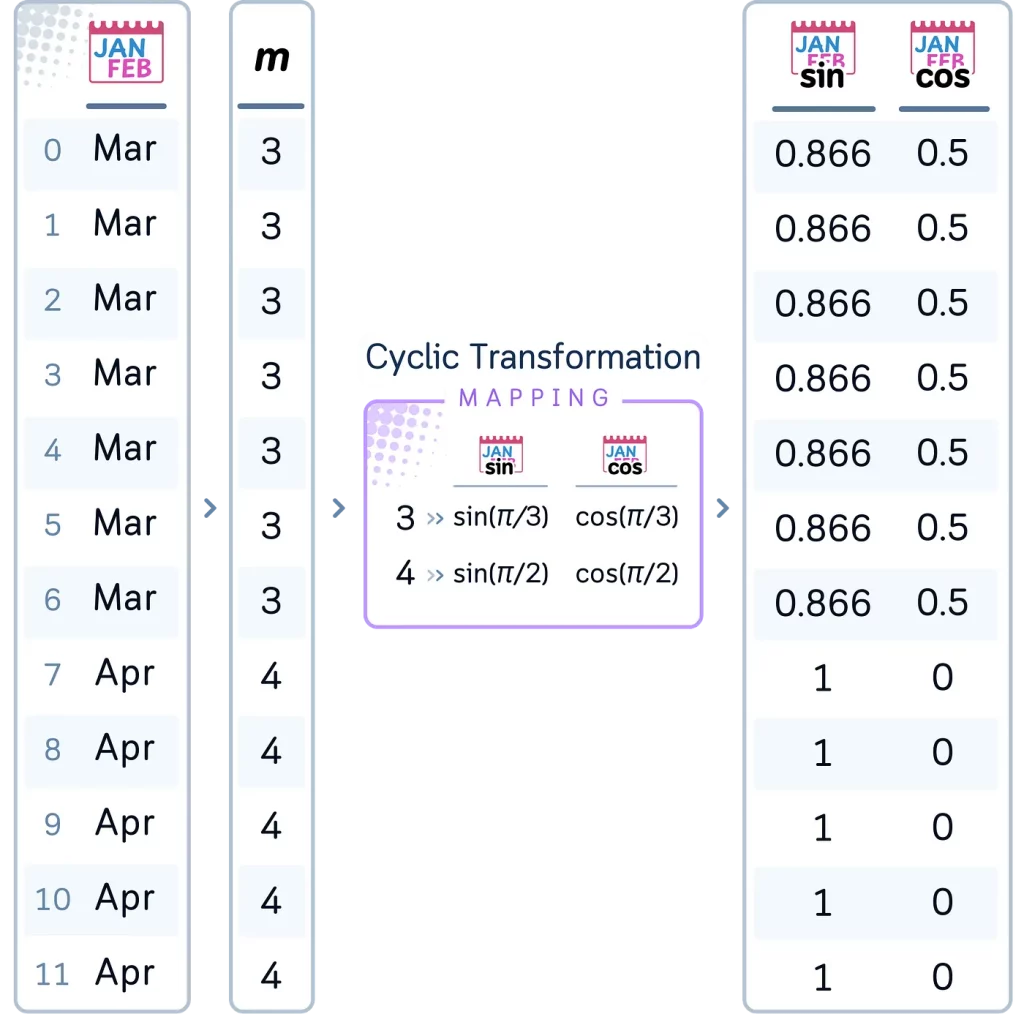
# 6. Циклическое кодирование для Month
month_order = {'Jan': 1, 'Feb': 2, 'Mar': 3, 'Apr': 4, 'May': 5, 'Jun': 6,
'Jul': 7, 'Aug': 8, 'Sep': 9, 'Oct': 10, 'Nov': 11, 'Dec': 12}
df['Month_num'] = df['Month'].map(month_order)
df['Month_sin'] = np.sin(2 * np.pi * (df['Month_num']-1) / 12)
df['Month_cos'] = np.cos(2 * np.pi * (df['Month_num']-1) / 12)
Заключение: сила трансформации (и понимания)
Итак, мы применили 6 способов кодирования категориальных данных к набору данных по гольфу. Теперь все категории преобразованы в числа!
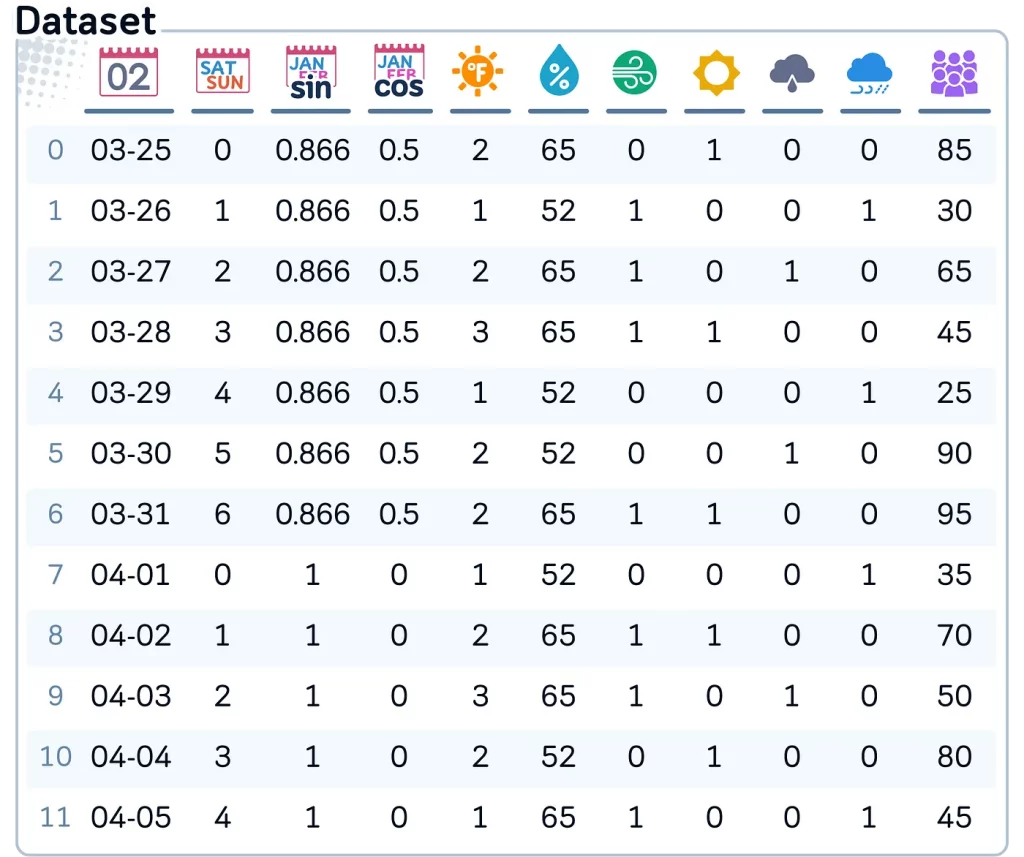
Вспомним, как каждый метод справился с данными.
- Кодирование меток (Label Encoding): превратило категории в столбце Weekday (День недели) в числа, сделав Mon (понедельник) 0, а Sun (воскресенье) 6 — просто, но потенциально может ввести модель в заблуждение.
- Прямое кодирование (One-Hot Encoding): позволило создать для столбца Outlook (Прогноз) собственные независимые друг от друга столбцы: Sunny (солнечно), Overcast (облачно) и Rainy (дождливо).
- Двоичное кодирование (Binary Encoding): сжало столбец Humidity (Влажность) в эффективный двоичный код, что позволило сэкономить место без потери информации.
- Целевое кодирование (Target Encoding): заменило категории Wind (Ветер) на среднее значение целевой переменной «crowdedness» (скопление людей), что помогло модели уловить скрытые взаимосвязи.
- Порядковое кодирование (Ordinal Encoding): обеспечило соблюдение естественного порядка категорий в столбце Temperature (Температура) — от Very Low (очень низкая) до Very High (очень высокая).
- Циклическое кодирование (Cyclic Encoding): трансформировало категории столбца Month (Месяц) в компоненты синуса и косинуса, сохраняя его цикличную природу.
В категориальном кодировании нет универсального решения. Выбор оптимального метода зависит от конкретных данных, характера категорий и требований модели машинного обучения.
Кодирование категориальных данных может показаться незначительным шагом в грандиозной схеме проекта машинного обучения, но именно эти, казалось бы, незначительные детали часто могут повлиять на производительность модели.
Основные проблемы категориального кодирования
Завершая обсуждение кодирования, выделим несколько важных моментов, о которых следует помнить.
- Потеря информации. Некоторые методы кодирования могут привести к потере информации. Например, кодирование меток может навязать непредусмотренные порядковые отношения.
- Проблема новой категории. Большинство методов кодирования терпят неудачу, когда сталкиваются с категориями в тестовых данных, которых не было во время обучения. Всегда держите в запасе стратегию работы с этими «незнакомцами».
- Барьер размерности. Такие методы, как прямое кодирование, могут значительно увеличить количество признаков (представьте, что у вас сотни различных категорий, например страны или города). Возможно, стоит выбрать те признаки, которые действительно важны для кодирования, например классифицировать редкие признаки как Others (Другие).
- Документирование. В будущем для вас самих (и ваших коллег) станет огромным подспорьем четко зафиксированные решения по кодированию. Такая прозрачность нужна для воспроизводимости и понимания любых возможных предубеждений в результатах.
Итак, кодирование — это трансформирование категориальных данных на язык, понятный машинам, с максимальным сохранением смысла. Речь идет не о поиске идеального кодирования, а о выборе метода, который наилучшим образом соответствует вашим конкретным потребностям и ограничениям. Подойдите к этому вопросу вдумчиво, чтобы заложить прочный фундамент для своих работ по машинному обучению.
Итоговый код категориального кодирования
import pandas as pd
import numpy as np
# Создание DataFrame из словаря
data = {
'Date': ['03-25', '03-26', '03-27', '03-28', '03-29', '03-30', '03-31', '04-01', '04-02', '04-03', '04-04', '04-05'],
'Weekday': ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri'],
'Month': ['Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Mar', 'Apr', 'Apr', 'Apr', 'Apr', 'Apr'],
'Temperature': ['High', 'Low', 'High', 'Extreme', 'Low', 'High', 'High', 'Low', 'High', 'Extreme', 'High', 'Low'],
'Humidity': ['Dry', 'Humid', 'Dry', 'Dry', 'Humid', 'Humid', 'Dry', 'Humid', 'Dry', 'Dry', 'Humid', 'Dry'],
'Wind': ['No', 'Yes', 'Yes', 'Yes', 'No', 'No', 'Yes', 'No', 'Yes', 'Yes', 'No', 'Yes'],
'Outlook': ['sunny', 'rainy', 'overcast', 'sunny', 'rainy', 'overcast', 'sunny', 'rainy', 'sunny', 'overcast', 'sunny', 'rainy'],
'Crowdedness': [85, 30, 65, 45, 25, 90, 95, 35, 70, 50, 80, 45]
}
df = pd.DataFrame(data)
# 1. Кодирование меток для Weekday
df['Weekday_label'] = pd.factorize(df['Weekday'])[0]
# 2. Прямое кодирование для Outlook
df = pd.get_dummies(df, columns=['Outlook'], prefix='Outlook')
# 3. Двоичное кодирование для Wind
df['Wind_binary'] = (df['Wind'] == 'Yes').astype(int)
# 4. Целевое кодирование для Humidity
df['Humidity_target'] = df.groupby('Humidity')['Crowdedness'].transform('mean')
# 5. Порядковое кодирование для Temperature
temp_order = {'Low': 1, 'High': 2, 'Extreme': 3}
df['Temperature_ordinal'] = df['Temperature'].map(temp_order)
# 6. Циклическое кодирование для Month
month_order = {'Jan': 1, 'Feb': 2, 'Mar': 3, 'Apr': 4, 'May': 5, 'Jun': 6,
'Jul': 7, 'Aug': 8, 'Sep': 9, 'Oct': 10, 'Nov': 11, 'Dec': 12}
df['Month_num'] = df['Month'].map(month_order)
df['Month_sin'] = np.sin(2 * np.pi * df['Month_num'] / 12)
df['Month_cos'] = np.cos(2 * np.pi * df['Month_num'] / 12)
# Выбор и перераспределение числовых столбцов
numerical_columns = [
'Date','Weekday_label',
'Month_sin', 'Month_cos',
'Temperature_ordinal',
'Humidity_target',
'Wind_binary',
'Outlook_sunny', 'Outlook_overcast', 'Outlook_rainy',
'Crowdedness'
]
# Отображение перераспределенных числовых столбцов
print(df[numerical_columns].round(3))
Техническая среда
При создании этой статьи использовался Python 3.7, pandas 2.1 и numpy 1.26. Хотя обсуждаемые концепции общеприменимы, конкретные реализации кода могут немного отличаться в разных версиях.
Иллюстрации
Если не указано иное, все изображения созданы автором с использованием лицензированных элементов дизайна из Canva Pro.

Читайте также:
- Базовый классификатор: наглядное руководство с примерами кода для начинающих
- Регрессор дерева решений
- Cтарая поговорка гласит: “Одна голова хорошо, а две — лучше”
Читайте нас в Telegram, VK и Дзен
Перевод статьи Samy Baladram: Encoding Categorical Data, Explained: A Visual Guide with Code Example for Beginners




