
Задумывались ли вы когда-нибудь над тем, как запрос из клиентского приложения попадает в серверный процесс? Какое волшебство совершаются в таких фреймворках для веб-серверов, как Spring Boot в Java и Express в NodeJS?
Многие инженеры не придают значения сложным скрытым перипетиям, происходящим на пути сетевого запроса. Тем самым они пренебрегают фундаментальным уровнем компетенций. Опыт работы в AWS помог мне осознать, как понимание сетевого стека позволяет объяснить, почему некоторые запросы «исчезают», так и не доходя до сервера. Каждому инженеру следует овладеть такими важнейшими понятиями, как природа сетевого сокета, путь сетевого запроса, выполнение трехстороннего TCP-квитирования, системные вызовы, передающие запросы из ядра в память приложения.
Эта статья прольет свет на процессы, лежащие в основе каждого сетевого запроса. Вы рассмотрите этапы установления клиентских соединений на веб-сервере, углубленно изучив сетевые сокеты, и проследите путь сетевого запроса от начала до конца. В результате получите глубокое представление о всех операциях сетевого стека, критически важных для каждого сетевого запроса.
Что такое сетевое соединение: выявление роли сетевых сокетов
Прежде чем углубляться в сетевые запросы, необходимо понять, как происходит сетевое взаимодействие между хостами (компьютерами). Не будем вдаваться в сложности сетевых протоколов — для данного обсуждения достаточно знать, что хосты подключаются к интернету через сетевую карту (NIC), причем каждая NIC связана с определенным IP-адресом (или несколькими IP-адресами). Чтобы два хоста могли взаимодействовать, между ними должно установиться сетевое соединение. Установление сетевого соединения на хосте происходит через сетевой сокет, который инициализируется IP-адресом источника, портом источника, IP-адресом назначения и портом назначения.
Сокет представляет собой одну конечную точку двустороннего канала связи, в то время как полное сетевое соединение включает два сокета, по одному на каждом хосте, участвующем в связи (клиент и сервер). Сокеты — это абстракция для отправки и получения данных по сети. Они инкапсулируют сложность сетевых протоколов (TCP, UDP и т.д.) и системных вызовов. Поэтому при выполнении сетевых вызовов в приложениях происходит запись и считывание данных через сокеты.
Важно понимать, что сетевое взаимодействие между хостами осуществляется через взаимодействие с сокетами. Это взаимодействие осуществляется через системные вызовы, которые представляют собой службы, предоставляемые ядром операционной системы. Основными функциями сокетов являются socket(), bind(), listen(), connect(), accept(), send() и recv(), которые будут рассмотрены ниже.
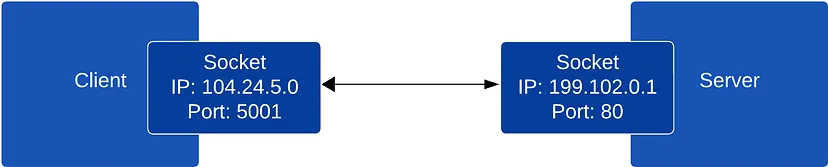
Создание, привязка и прослушивание сокетов
Серверам необходимо установить сетевое соединение с клиентами для обмена сетевыми запросами. Как уже говорилось, сетевые соединения устанавливаются с помощью сокетов. В контексте интернета эти сокеты устанавливаются через TCP/IP, поскольку HTTP работает на основе TCP. Чтобы установить эти сетевые соединения, сервер выполняет следующие системные вызовы.
socket()— запрашивает у ядра создание сокета, представляющего одну из конечных точек двустороннего канала связи (в Linux все представлено в виде дескрипторов файлов, поэтому сокет рассматривается как дескриптор).
bind()— привязывает вновь созданный сокет к определенному локальному адресу (IP) и порту.
listen()— вызываяlisten()на сокете, сервер помечает его как слушающий сокет, что позволяет ему ожидать входящих запросов на соединение.

После выполнения системного вызова listen() операционная система (ОС) создает очередь слушателей для сокета, чтобы хранить входящие запросы на соединение, которые еще не выполнили трехстороннее TCP-квитирование. На этом этапе клиенты могут попытаться инициировать соединения, создав сокет на хосте клиента (системный вызов socket()) и выполнив системный вызов connect(). Вызов connect() заставляет клиента выполнить TCP-квитирование с сервером, включающее последовательность сообщений SYN, SYN-ACK и ACK. После успешного завершения TCP-квитирования соединение ставится в очередь на принятие, ожидая обработки сервером.
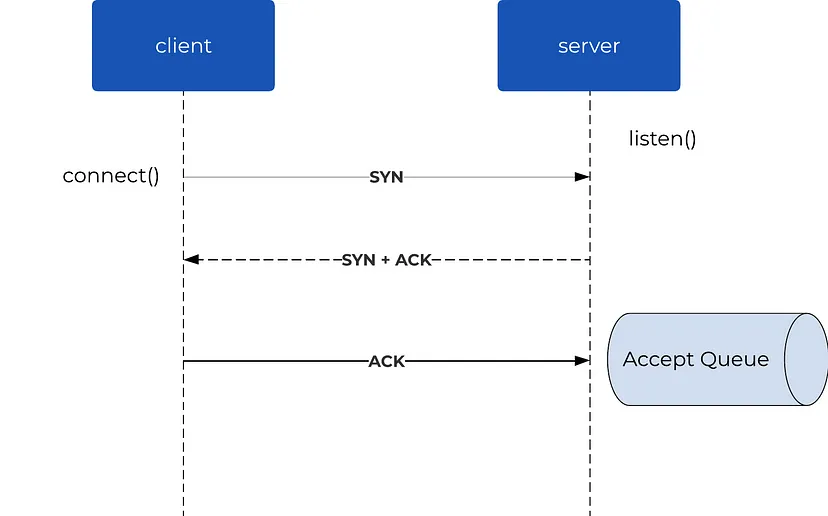
В качестве примера можно привести настройку HTTP-сервера с помощью экспресс-приложения NodeJS, когда выполняется следующий вызов:
app.listen(8000);
Этот вызов приводит к серии системных вызовов, включающих socket(), bind() и listen(), чтобы начать принимать сетевые соединения.
Принятие
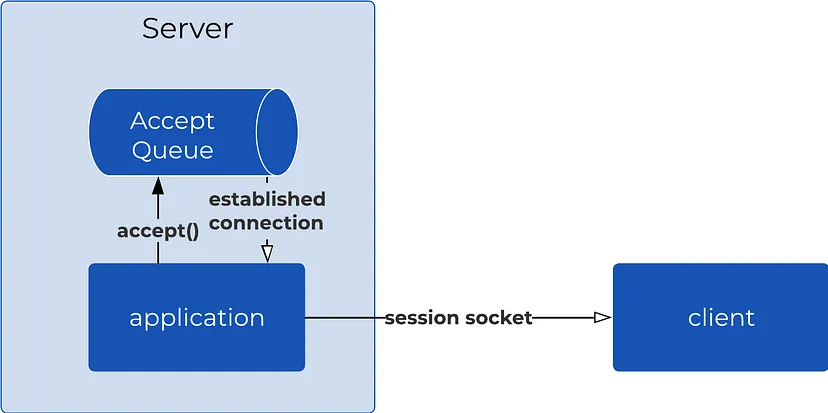
После завершения TCP-квитирования входящее клиентское соединение помещается в очередь на принятие, где ожидает подтверждения от серверного приложения. Затем серверу необходимо формализовать это соединение путем выполнения системного вызова accept(). Инициирование вызова accept() позволяет серверу извлечь ожидающее соединение из очереди принятия, а затем сгенерировать новый сокет (дескриптор), предназначенный для связи с этим конкретным клиентом.
Изначально сервер создает сокет-слушатель исключительно для принятия входящих запросов на соединение. После вызова функции accept() он выделяет отдельный дескриптор сокета для управления взаимодействием в рамках конкретной сессии «клиент-сервер».
После создания сокета сессии «клиент-сервер» обе стороны — клиент и сервер — получают возможность сетевого взаимодействия. Этот сокет становится каналом для всех последующих передач данных, обеспечивая точное направление и получение каждого сообщения, тем самым поддерживая стабильный канал связи на протяжении всей сессии.
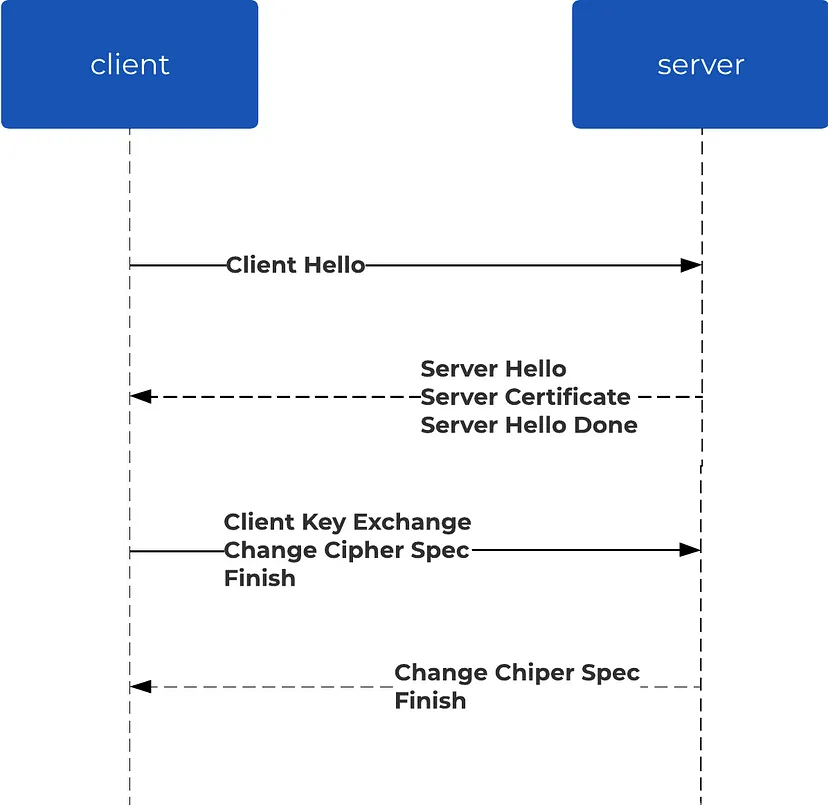
TLS-квитирование
Теперь установлено сетевое соединение между клиентом и сервером (обычно по протоколу TCP), по которому происходит обмен данными. Однако на данный момент этот канал связи остается незашифрованным. Чтобы повысить безопасность, соединение можно преобразовать в защищенное. Наиболее часто используемым протоколом для защиты соединения является TLS (transport layer security — протокол защиты транспортного уровня), который выполняется с помощью процесса, известного как TLS-квитирование. Это квитирование, осуществляемое через уже установленное TCP-соединение, включает последовательность этапов, позволяющую клиенту и серверу «договориться» о наборе шифров и обменяться сертификатами и криптографическими ключами для шифрования сообщений.
После завершения TLS-квитирования все последующие данные, передаваемые между клиентом и сервером, шифруются. Для шифрования используются ключи и алгоритмы, согласованные во время квитирования, что обеспечивает безопасность и защиту связи. Важно отметить, что шифрование и дешифрование сообщений происходит на уровне выше транспортного уровня в сетевом стеке.
Установив сокет сессии «клиент-сервер» с помощью вызова accept() и потенциально зашифровав соединение с помощью TLS, клиент и сервер могут начать обмениваться сетевыми запросами. На данный момент мы полностью рассмотрели шаги, которые предпринимает сервер для установления соединения, и можем перейти к обсуждению процесса пути сетевого запроса.
Этап считывания
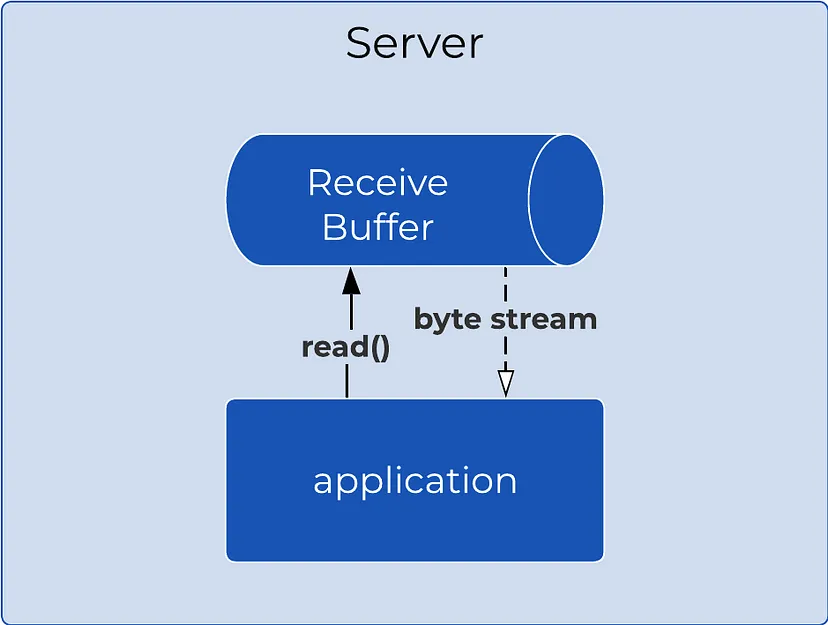
Первый этап сетевого запроса — это собственно запрос, отправленный клиентом на сервер. Отправленный от клиента сетевой запрос сохраняется в буфере на сервере, который называется приемным буфером (или буфером ядра). Этот буфер связан с сетевым сокетом сессии «клиент-сервер» на сервере.
Приемный буфер является частью памяти операционной системы и управляется ядром. Его назначение — хранить (буферизировать) данные до тех пор, пока приложение не будет готово их прочитать. Вызывая read() или recv(), приложение считывает данные из приемного буфера сокета и загружает их в память приложения (пользовательское пространство).
Приложение считывает данные в формате потока, то есть, вызывая read() или recv(), оно получает поток байтов, а не отдельный запрос. Чтобы разобраться в этом потоке байтов, нужно парсить данные, используя протокол вроде HTTP, который определяет, как интерпретировать данные и что считать отдельным запросом. Обсудим парсинг ниже, поскольку это еще один этап в жизненном цикле запроса. Однако необходимо понимать, что ему предшествует загрузка байтов сетевого запроса в память приложения посредством системных вызовов read() или recv().
Этап расшифровки
После считывания данных (байтов) в память приложения необходимо выполнить их парсинг, чтобы дифференцировать запросы и интерпретировать поток байтов в осмысленную информацию. Однако перед этим необходимо расшифровать считанные байты. Как уже говорилось ранее, TCP-соединение может быть преобразовано в защищенное с помощью TLS-квитирования (или других протоколов). Данные, считываемые из защищенного соединения, зашифрованы, поэтому сначала их нужно расшифровать.
Если соединение было зашифровано с помощью TLS, то сервер использует сессионные ключи, полученные во время TLS-квитирования, для расшифровки входящих данных. После завершения расшифровки получаем байты открытого (незашифрованного) текста, которые можно парсить.
Важно отметить, что этап расшифровки не обязательно должен выполняться на сервере, обрабатывающем запрос. Распространенным подходом является выполнение расшифровки на балансировщике нагрузки или обратном прокси с последующей передачей запроса в открытом виде на сервер. Такой подход, известный как TLS-завершение, выгоден тем, что расшифровка запроса — это операция, требующая больших затрат процессора, и передача ее обратному прокси экономит ресурсы сервера.
Этап парсинга
Теперь, когда поток байтов (данных) прочитан и расшифрован, нужно понять его, чтобы действовать в соответствии с ним. Понимание означает парсинг данных для интерпретации запроса. Именно здесь в дело вступают протоколы приложений, такие как HTTP. Без четкого протокола связи, определенного между клиентом и сервером, парсинг данных был бы затруднен.
Парсинг подразумевает выделение отдельных запросов из потока байтов, их анализ и извлечение значимой информации. В контексте HTTP-запроса этот этап включает извлечение такой информации, как HTTP-метод (GET, POST и т. д.), HTTP-заголовки, URI и данные, содержащиеся в теле запроса. Парсинг запроса необходим для того, чтобы знать, как его обрабатывать.
В современных программных фреймворках парсинг позволяет направить запрос в соответствующий контроллер, который обрабатывает HTTP-метод (GET, POST и т. д.) и URI, например /orders. Однако окончательной обработке запроса в приложении предшествует еще один этап.
Этап декодирования
Прежде чем окончательно обработать запрос, нужно его декодировать. На этапе парсинга извлекается необходимая для работы с запросом информация, например тело запроса. Однако в большинстве случаев тело запроса (полезная нагрузка) отправляется в сериализованном формате, таком как JSON или Protobuf. Поэтому необходимо его декодировать (или провести его парсинг). Как и на этапе парсинга, для выполнения декодирования требуется знать формат сериализации клиента (JSON, Protobuf и т. д.). Декодирование также может включать преобразование данных из ASCII в UTF 8 и распаковку данных, если они были сжаты перед отправкой.
Кстати, термины «декодирование» и «парсинг» иногда используются как взаимозаменяемые. Также правильно называть этот процесс «парсингом полезной нагрузки». Важнейшим результатом этого этапа является перевод тела запроса с формата wire-written (сериализованного формата) в объект на языке программирования.
Этап обработки
Последний этап на пути сетевого запроса — обработка запроса сервисом. Обычно это происходит в методах контроллера приложений, где реализуется бизнес-логика для ответа на запрос. Обработка может включать выполнение вычислений на входе, обращение к сторонним API и взаимодействие с базой данных для сохранения информации.
После обработки запроса ответ отправляется клиенту. При отправке ответа выполняются действия, обратные тем, что описаны выше: кодирование, сериализация, шифрование и запись ответа обратно клиенту.
Заключение
Теперь у вас будет более четкое представление о сложных процессах, происходящих «под капотом» процесса взаимодействия клиентов с веб-серверами.
Наше погружение в тему началось с изучения основ сетевых соединений, когда вы узнали о роли сетевых сокетов как важных конструкций, упрощающих сетевое взаимодействие. И клиенты, и серверы полагаются на эти сокеты при взаимодействии. Мы выяснили, что сервер должен создать сокет, привязать его к IP-адресу и порту и начать прослушивать соединения от клиентов. Клиент и сервер могут начать обмен данными после того, как клиент установит соединение, выполнив успешное TCP-квитирование.
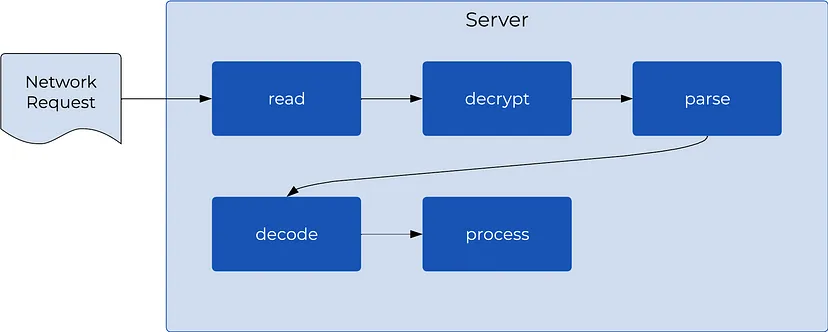
Затем мы рассмотрели путь сетевого запроса, изучив последовательность этапов процесса, выполняемого сервером: чтение из сокета, расшифровка, парсинг, декодирование и, наконец, обработка запроса. Важно понимать, что эти этапы, за исключением этапа обработки, в современных фреймворках веб-серверов происходят скрыто от разработчиков, избавляя их от излишних сложностей.
Чем дальше вы продвинетесь в программной инженерии, тем важнее для вас понимание того, как все работает «под капотом». Глубокие знания, даже если вы не будете использовать их ежедневно, докажут свою ценность, когда что-то пойдет не так. Приобретенные компетенции не только повысят ваш профессиональный уровень, но и могут сыграть решающую роль в непредвиденных ситуациях.
Читайте также:
- Шаблоны проектирования распределенных систем и не только
- Проблема IDOR: несанкционированный отзыв сессии пользователя
- Перестаньте фокусироваться на синтаксисе, если хотите стать senior-разработчиком
Читайте нас в Telegram, VK и Дзен
Перевод статьи Nadar Alpenidze: Under the Hood: Exploring How Web Servers Handle Requests





