
Представьте, что вы работаете над крупным приложением электронной коммерции, в котором для обмена сообщениями используется Kafka. Все вроде хорошо, но вот в дашборде метрик вы замечаете резкий рост числа доставок по сравнению с размещенными заказами. Команда лихорадочно ищет причину, которой после многих часов отладки оказывается не ошибка в коде, а куча дублированных сообщений в темах. Подробно рассмотрим сценарии, чреватые дублями, и различные подходы для их недопущения.
1. Дублированные сообщения на стороне отправителя
Вот служба заказов, которой публикуются сообщения в теме заказа:
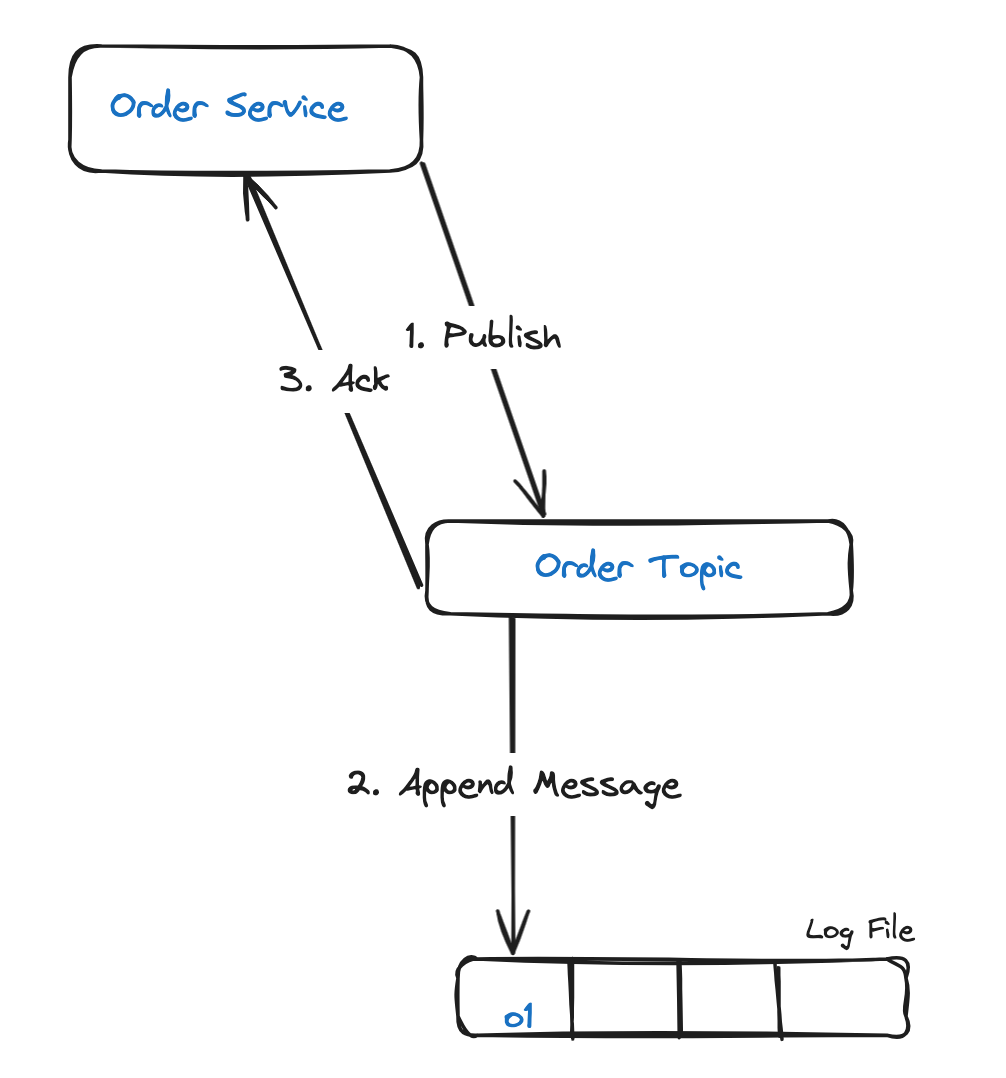
На этапе 3 подтверждение от Kafka теряется из-за временных проблем с сетью, например потери сетевого подключения. В результате отправка службой заказов сообщения повторяется до получения подтверждения, так появляются дубли:
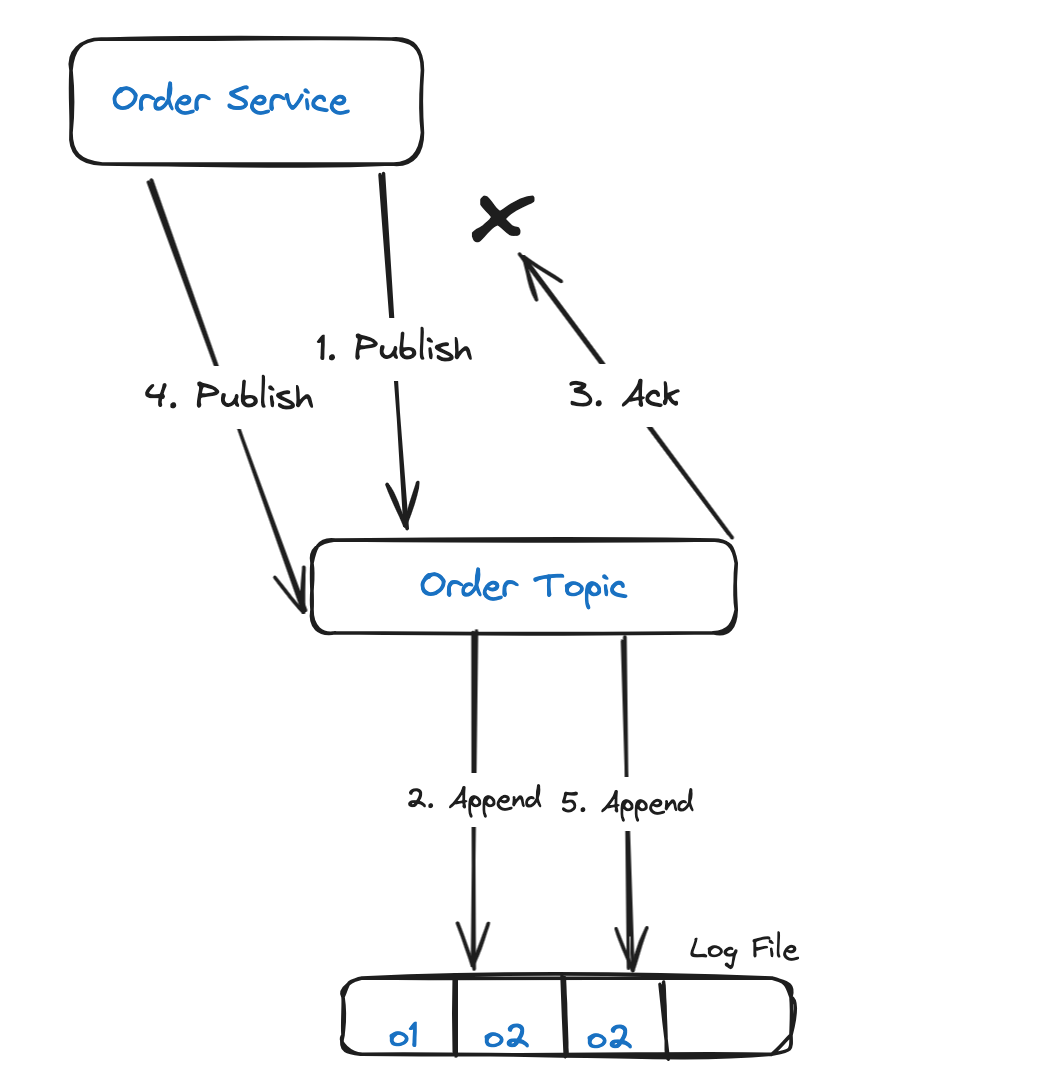
Решение: идемпотентный отправитель
Проблема решается идемподентным отправителем. Для этого службе заказов присваивается уникальный идентификатор отправителя PID, а каждому опубликованному сообщению — порядковый номер. Эта комбинация идентификатора и номера отслеживается в Kafka как уникальный идентификатор сообщения. Таким образом, когда имеющееся сообщение отправляется повторно, от Kafka возвращается подтверждение без добавления сообщения в журнал:
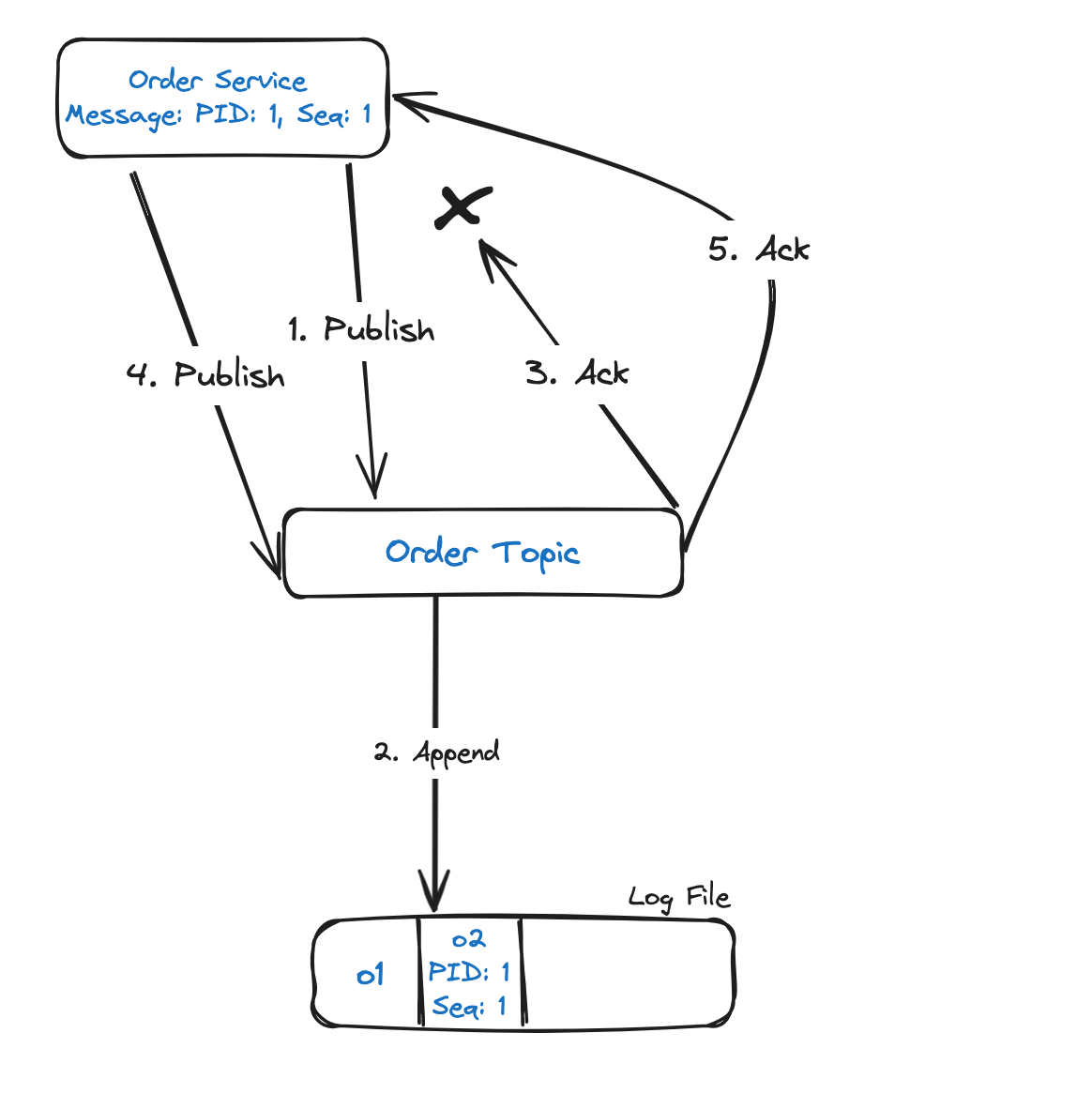
Идемпотентность включается в отправителе Kafka заданием свойству конфигурации enable.idempotence значения true , повторным отправкам retries — значения больше 0, а подтверждениям acks — all.
Если в enable.idempotence задано true, при повторяемых ошибках отправителем автоматически выполняются повторные отправки. Это ошибки временного характера, например недоступен лидер или недостаточно реплик.
Если в acks — задано all, то в Kafka, прежде чем отправлять отправителю подтверждение, лидер дожидается от разделов с минимальным количеством синхронизированных реплик подтверждения сообщения.
2. Дублированные сообщения на стороне получателя
Обратимся теперь к службе выполнения, которой:
- Считываются сообщения из темы заказов.
- Выполняется вызов POST в службу аудита.
- Создается новая запись в таблице выполнения.
- Публикуется сообщение в теме выполнения.
- В Kafka обновляется смещение.
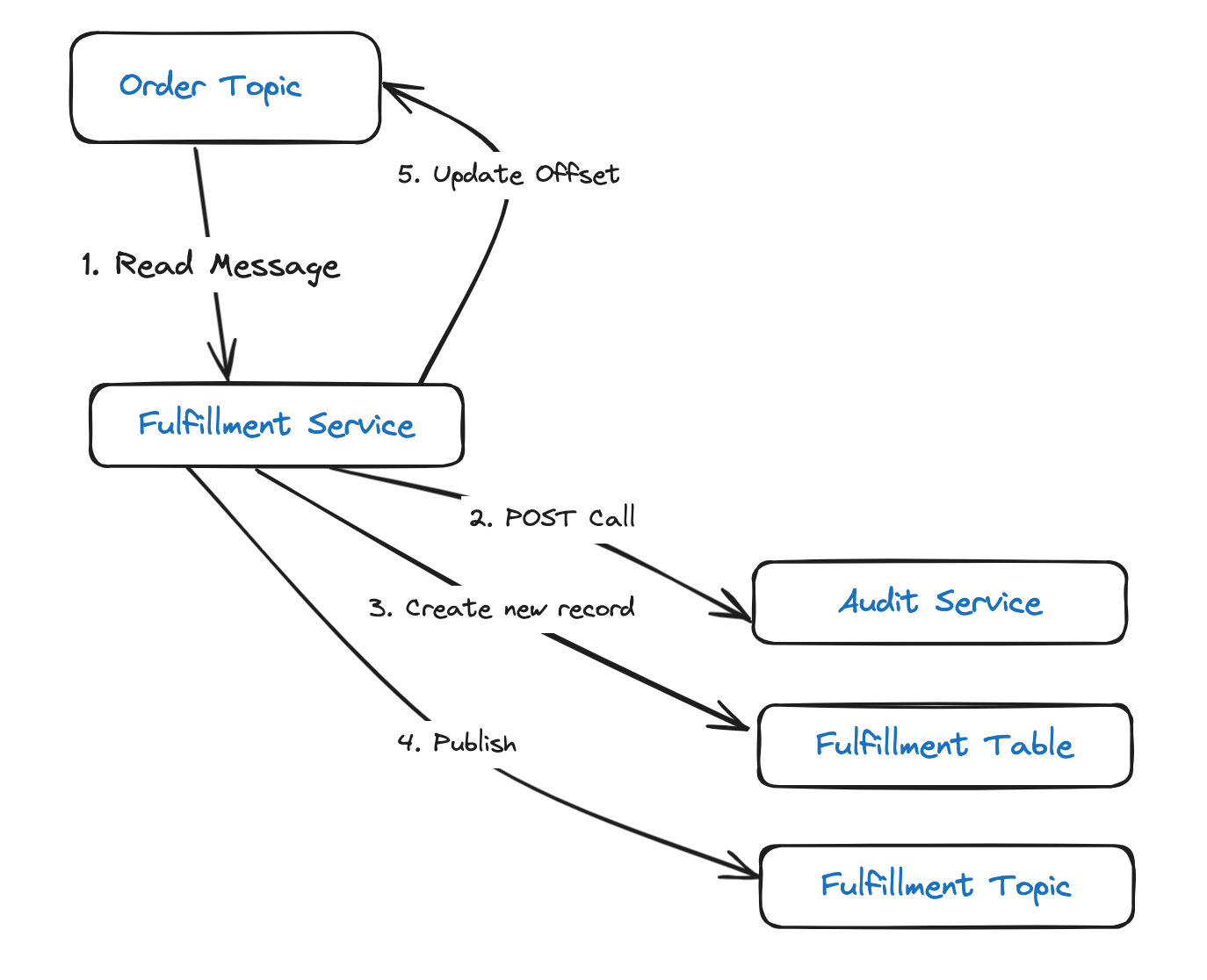
Если экземпляром, на котором запущена служба, этапы 2–5 в течение заданного интервала не обрабатываются, для Kafka эта служба мертва. Это чревато удалением экземпляра службы из группы получателей и перераспределением раздела: то же сообщение затем присваивается другому получателю в группе и обрабатывается им.
Решение: идемпотентный получатель
Чтобы избежать такого сценария, все полученные сообщения отслеживаются. Для этого каждому сообщению, созданному на стороне отправителя, то есть службы заказа, присваивается уникальный идентификатор. Они отслеживаются на стороне получателя, то есть службы выполнения, сохранением каждого идентификатора в таблице базы данных, то есть в таблице отслеживания идентификаторов сообщений. Когда получается сообщение с дублем идентификатора — выявляется поиском в таблице отслеживания идентификаторов сообщений, — смещение моментально обновляется и дальнейшая обработка пропускается:
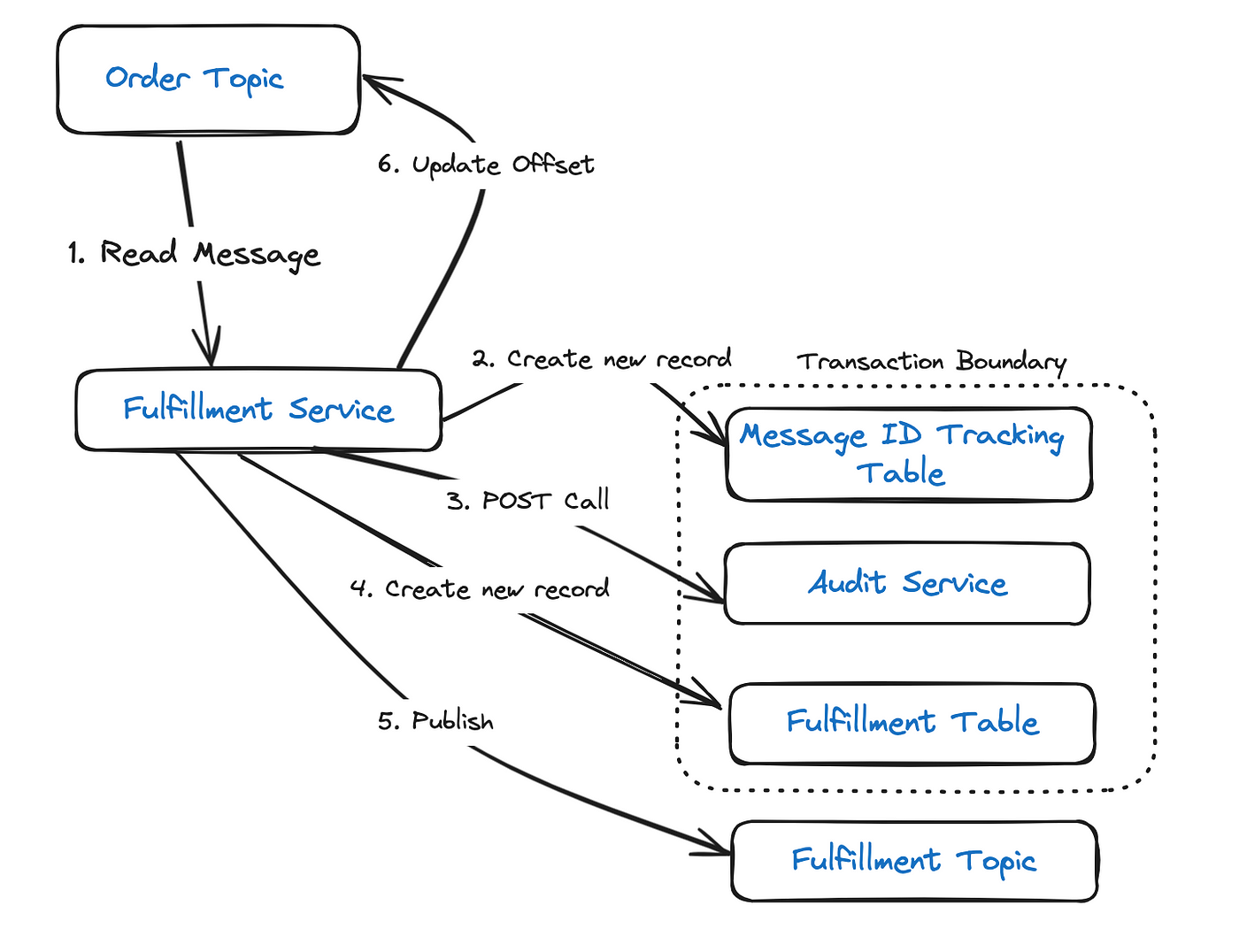
Запись вставляется в таблицы отслеживания и выполнения как транзакция базы данных. Так что в случае сбоя оба действия можно отменить.
Бывает, что транзакция не выполняется после публикации сообщения в теме выполнения. Тогда следует повторная попытка, и в теме выполнения появляется дублированное сообщение. Такой сценарий этим подходом не учитывается.
Решение: идемподентный получатель + транзакционные исходящие
Невозможно иметь распределенную транзакцию одновременно для базы данных и Kafka, где XA-транзакции не поддерживаются. Поэтому решение проблемы — фиксировать события, подлежащие опубликованию, в таблице исходящих. Записи в этой таблице включаются в ту же транзакцию БД, которой они выполняются в таблицы отслеживания и выполнения:
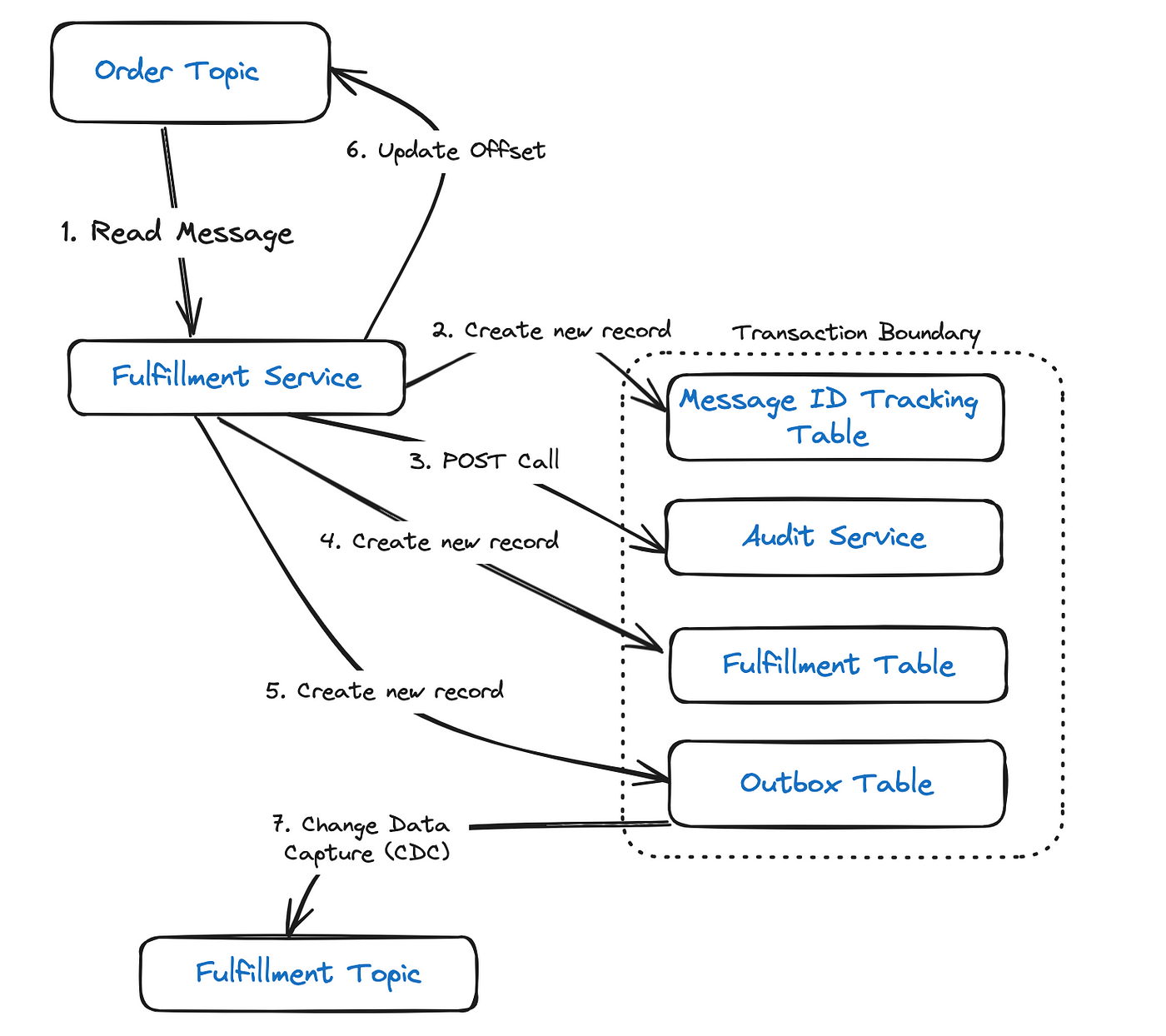
Так обеспечивается, что запись в базу данных и публикация сообщения в Kafka — это атомарное действие. С помощью инструмента отслеживания измененных данных, такого как Kafka Connect или Debezium, событие затем публикуется в теме выполнения.
Даже при таком подходе остается возможность дублирования вызовов POST: когда после выполнения вызова за сбоем транзакции следует откат, инициируются повторные попытки. Происходит это независимо от порядка выполнения вызова. Это единственное решение, где необходимо убедиться, что вызов POST — идемподентный на стороне получателя.
Заключение
В этих подходах много подвижных частей, из-за чего увеличиваются сложность и нюансы сопровождения. Разумным будет реализовывать все это инкрементно и только при наличии значимых метрик для подтверждения внедрения подходов.
Читайте также:
- Плавный переход: миграция кластера Kafka в Kubernetes
- Получение одного события разными группами получателей в Kafka с Spring Boot
- Система инженерии данных «от и до» с Kafka, Spark, Airflow, Postgres и Docker. Часть 1
Читайте нас в Telegram, VK и Дзен
Перевод статьи Vignesh Ravichandran: Handling message duplication in Kafka





