
Введение
Версия pandas 2.0 была выпущена в начале апреля и внесла множество улучшений в новый режим Copy-on-Write (CoW). Ожидается, что эта функция станет стандартной в версии pandas 3.0, выход которой запланирован на апрель 2024 года. Возвращение к прежнему режиму без CoW не планируется.
В этой серии статей я расскажу о том, как работает Copy-on-Write, чтобы помочь пользователям понять суть этого режима, покажу, как эффективно его использовать и как адаптировать к нему код. Здесь будут примеры применения механизма CoW для достижения наиболее эффективной производительности, а также пара антипаттернов, приводящих к ненужным узким местам.
Я вхожу в основную команду разработчиков pandas и до сих пор принимал активное участие в реализации и улучшении CoW. Я занимаю должность инженера-программиста в компании Coiled, работаю над проектом Dask, включая улучшение интеграции с pandas и обеспечение соответствия Dask требованиям CoW.
Как Copy-on-Write изменяет поведение pandas
Многие из вас наверняка знакомы со следующими предостережениями в pandas:
import pandas as pd
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": ["A", "C", "D"]})
Выделим grade-столбец и перезапишем первую строку с "E".
grades = df["grade"]
grades.iloc[0] = "E"
df
student_id grade
0 1 E
1 2 C
2 3 D
К сожалению, при этом также обновляется df, а не только grades, что чревато появлением трудно обнаруживаемых ошибок. CoW запрещает такое поведение и обеспечивает обновление только df. Мы также видим ложноположительное предупреждение SettingWithCopyWarning, которое здесь нам не поможет.
Рассмотрим пример ChainedIndexing, в котором ничего не происходит:
df[df["student_id"] > 2]["grades"] = "F"
df
student_id grade
0 1 A
1 2 C
2 3 D
Снова получаем сообщение SettingWithCopyWarning, но в данном примере с df ничего не происходит. Все эти проблемы сводятся к правилам копий и представлений в NumPy, которые задействуются в pandas “под капотом”. Пользователи pandas должны знать эти правила и то, как они применяются к DataFrame pandas, чтобы понимать, почему похожие паттерны кода дают разные результаты.
CoW устраняет все эти несоответствия. В режиме CoW пользователи могут обновлять только один объект за раз. Например, в первом примере df не изменится, поскольку в это время обновляется только grades, а во втором примере, где прежде ничего не происходило, будет выдана ошибка ChainedAssignmentError. Как правило, обновить два объекта одновременно не удается: каждый объект ведет себя как копия предыдущего объекта.
Таких случаев гораздо больше, но их рассмотрение не входит в нашу задачу.
Как это работает
Углубимся в механизм Copy-on-Write и остановимся на некоторых фактах, которые полезно знать. Это основная часть статьи, и она будет носить достаточно технический характер.
Copy-on-Write предусматривает, что любой DataFrame или Series, полученный из другого каким-либо образом, всегда ведет себя как копия. Это означает, что невозможно изменить более одного объекта одной операцией. Например, в первом примере будет изменен только grades.
Защитным подходом, гарантирующим это, было бы копирование DataFrame и его данных в каждой операции, что позволило бы полностью избежать представлений в pandas. Это обеспечило бы семантику CoW, но в то же время привело бы к существенному снижению производительности, поэтому такой вариант оказался неприемлемым.
Теперь рассмотрим механизм, который будет следить за тем, чтобы два объекта не обновлялись посредством одной операции, и за тем, чтобы данные не копировались без необходимости. Самое интересное в такой реализации — это вторая часть.
Чтобы избежать копий, которые не являются абсолютно необходимыми, нужно точно знать, когда сделать копию. Потенциальные копии необходимы только в том случае, если мы пытаемся изменить значения одного объекта pandas, не копируя его данные. Если данные этого объекта совместно используются с другим объектом pandas, то необходимо сделать копию. Это означает, что нам нужно отслеживать, ссылается ли один массив NumPy на два DataFrame (строго говоря, мы должны знать, ссылается ли один массив NumPy на два объекта pandas, но для простоты будем использовать термин DataFrame).
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": [1, 2, 3]})
df2 = df[:]
Здесь оператор создает df DataFrame и представление этого DataFrame df2. Представление означает, что оба DataFrame связаны с одним и тем же базовым массивом NumPy. С точки зрения CoW, df должен знать, что df2 тоже ссылается на тот же массив NumPy. Более того, df2 также должен знать, что df ссылается на тот же массив NumPy. Если оба объекта знают, что на тот же массив NumPy ссылается другой DataFrame, то в случае изменения одного из них можно сделать копию, например:
df.iloc[0, 0] = 100
Здесь df изменяется in place (на месте). df знает, что есть другой объект, который ссылается на те же данные, поэтому он запускает копирование. Он не знает, какой объект ссылается на те же данные, он знает только, что существует другой объект.
Рассмотрим, как можно добиться такого результата. Создадим внутренний класс BlockValuesRefs, который используется для хранения этой информации. Он указывает на все DataFrames, которые ссылаются на данный массив NumPy.
Существует три различных типа операций, которые могут создавать DataFrame.
- DataFrame создается из внешних данных, например через
pd.DataFrame(...)или через любой метод ввода/вывода. - DataFrame создается с помощью операции pandas, которая запускает копию исходных данных, например
dropnaсоздает копию практически во всех случаях. - DataFrame создается с помощью операции pandas, которая не запускает копирование исходных данных, например
df2 = df.reset_index().
Первые два случая просты. При создании DataFrame массивы NumPy, которые с ним связаны, подключаются к только что созданному объекту BlockValuesRefs. На эти массивы ссылается только новый объект, поэтому нет необходимости следить за другими объектами. Объект создает weakref, указывающий на Block, который оборачивает массив NumPy, и хранит эту ссылку внутри.
Функция weakref создает ссылку на любой объект Python. Она не сохраняет этот объект, когда он выходит из области видимости.
import weakref
class Dummy:
def __init__(self, a):
self.a = a
In[1]: obj = Dummy(1)
In[2]: ref = weakref.ref(obj)
In[3]: ref()
Out[3]: <__main__.Dummy object at 0x108187d60>
In[4]: obj = Dummy(2)
В данном примере создается объект Dummy и слабая ссылка на этот объект. В дальнейшем мы присваиваем этой переменной другой объект, поскольку исходный объект выходит из области видимости и собирается в мусор. Слабая ссылка не мешает этому процессу. Если разрешить слабую ссылку, то вместо исходного объекта она будет указывать на
None.
In[5]: ref()
Out[5]: None
Это обеспечивает несохранение массивов, которые в противном случае были бы собраны в мусор.
Посмотрим, как организованы эти объекты:
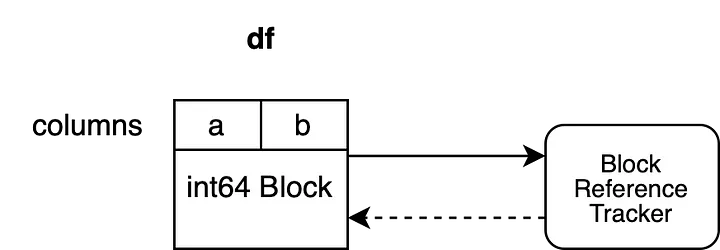
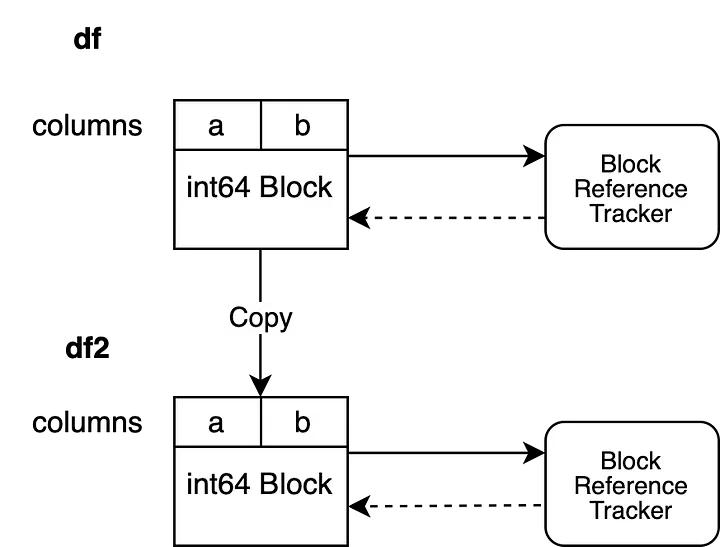
В примере два столбца "a" и "b" имеют dtype "int64". Они связаны с одним Block, в котором хранятся данные для обоих столбцов. Block содержит жесткую ссылку на объект отслеживания ссылок, что обеспечивает его существование до тех пор, пока Block не будет собран в мусор. Объект отслеживания ссылок содержит слабую ссылку на Block. Это позволяет объекту отслеживать жизненный цикл данного Block, но не предотвращает сборку в мусор. Объект отслеживания ссылок еще не имеет слабой ссылки на какой-либо другой Block.
Это простые сценарии. Мы знаем, что ни один другой объект pandas не использует тот же массив NumPy, поэтому можем просто инстанцировать новый объект отслеживания ссылок.
Третий случай более сложный. Новый объект просматривает те же данные, что и исходный. Это означает, что оба объекта указывают на одну и ту же память. Операция создаст новый Block, который будет ссылаться на тот же массив NumPy (это называется неглубокой копией). Теперь необходимо зарегистрировать этот новый Block в механизме отслеживания ссылок. Мы зарегистрируем новый Block в объекте отслеживания ссылок, который связан со старым объектом.
df2 = df.reset_index(drop=True)
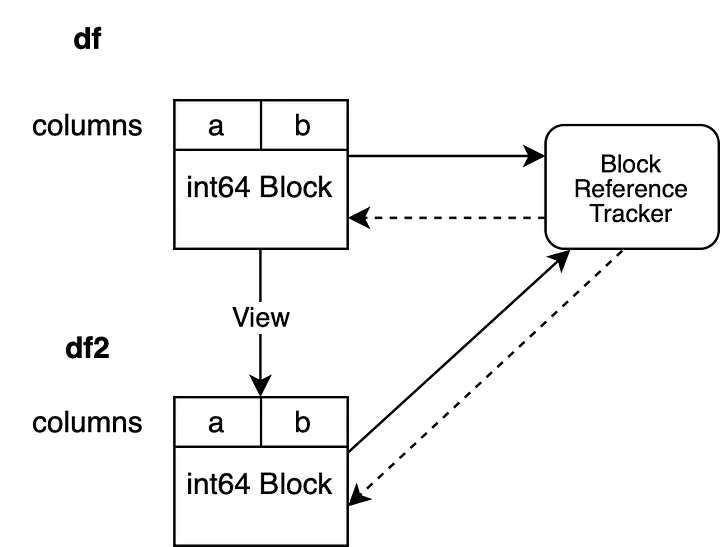
Теперь BlockValuesRefs указывают на Block, связанный с исходным df, и на вновь созданный Block, связанный с df2. Таким образом мы всегда будем знать обо всех DataFrames, которые указывают на одну и ту же память.
Теперь можно спросить у объекта отслеживания ссылок, сколько Block’ов, указывающих на один и тот же массив NumPy, являются “живыми”. Объект отслеживания ссылок оценивает слабые ссылки и сообщает, что на одни и те же данные ссылается более одного объекта. Это позволяет внутренне запустить копирование, если один из них будет изменен на месте.
df2.iloc[0, 0] = 100
Block в df2 копируется с помощью глубокого копирования, создавая новый Block, имеющий собственные данные и объект отслеживания ссылок. Исходный Block, связанный с df2, теперь может быть собран в мусор, и это значит, что массивы, связанные с df и df2, не будут иметь общей памяти.
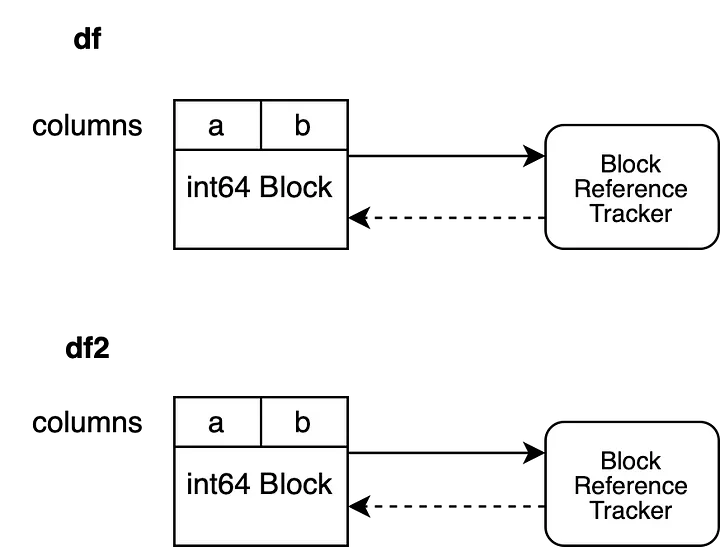
Рассмотрим другой сценарий.
df = None
df2.iloc[0, 0] = 100
df инвалидируется до того, как мы изменяем df2. Следовательно, weakref (слабая ссылка) объекта отслеживания ссылок, указывающая на блок, связанный с df, принимает значение None. Это позволяет изменить df2, не запуская копирование.
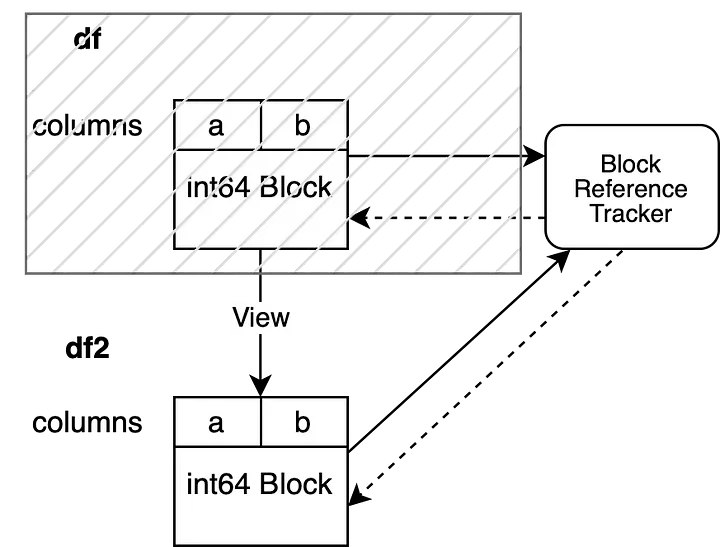
Объект отслеживания ссылок указывает только на один DataFrame, что позволяет выполнять операцию на месте, не запуская копирование.
Приведенная выше операция reset_index создает представление. Механизм немного упрощается, если у нас есть операция, которая запускает копирование внутренне.
df2 = df.copy()
При этом сразу же создается новый объект отслеживания ссылок для DataFrame df2.
Заключение
Мы исследовали работу механизма отслеживания Copy-on-Write при запуске копирования. Он максимально откладывает копирование в pandas, что существенно отличается от поведения без применения CoW. Механизм отслеживания ссылок учитывает все DataFrame, совместно использующие память, что обеспечивает более последовательный процесс в pandas.
В следующей части будут описаны приемы, которые используются для повышения эффективности этого механизма.
Читайте также:
- 6 способов оптимизировать рабочий процесс в Pandas
- Pandas 2.0.0 — геймчейнджер в работе дата-сайентистов?
- 4 альтернативы Pandas: ускоренное выполнение анализа данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Patrick Hoefler: Deep Dive into pandas Copy-on-Write Mode: Part I





