
Благодаря своему продвинутому и гибкому функционалу, библиотека Pandas стала незаменимым инструментом для дата-сайентистов и дата-аналитиков.
Согласно PyPI, Pandas скачивают более 3 миллионов раз ежедневно. Конечно, подобная статистика не дает точного представления о количестве пользователей. Тем не менее она подчеркивает популярность библиотеки.
Хотя многие уже ознакомились с ее основными возможностями, есть еще много скрытых, о которых вы, вероятно, не знаете. Рассмотрим 6 интересных подходов в Pandas, которые помогут повысить эффективность анализа данных.
#1. Отображение графиков в столбце DataFrame
Jupyter — это IDE на веб-основе. Поэтому при выводе DataFrame он отображается с использованием HTML и CSS. Это позволяет форматировать вывод так же, как и любую другую веб-страницу.
Одним из интересных способов такого форматирования является вставка встроенных графиков, которые появляются в столбце DataFrame. Их также называют “спарклайнами” (“sparklines”). В итоге мы получаем нечто подобное:
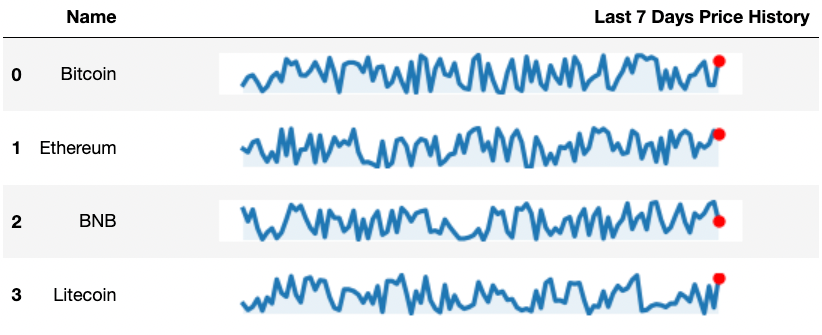
Как это создать? Смотрите код ниже.
Сначала выполним импорт:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from base64 import b64encode
from io import BytesIO
from IPython.display import HTML
%matplotlib inlineТеперь создадим выдуманный набор данных:
n = 100
data = [
('Bitcoin', 40000*np.random.rand(n).round(2)),
('Ethereum', 2000*np.random.rand(n).round(2)),
('BNB', 500*np.random.rand(n).round(2)),
('Litecoin', 150*np.random.rand(n).round(2)),
]
df = pd.DataFrame(data, columns=['Name', 'Price History'])
df.head() Name Price History
0 Bitcoin [24800.0, 12400.0, 14800.0, 24800.0, 20800.0, ...
1 Ethereum [1900.0, 380.0, 420.0, 1760.0, 800.0, 620.0, 1...
2 BNB [120.0, 170.0, 255.0, 255.0, 395.0, 150.0, 180...
3 Litecoin [126.0, 109.5, 94.5, 49.5, 81.0, 129.0, 66.0, ...В соответствии с четырьмя строками у нас есть список случайно сгенерированных историй цен. Теперь наша цель — добавить линейный график в каждую строку. Таким образом, мы можем создать функцию и использовать метод apply().
Как упоминалось выше, Jupyter отображает DataFrame с помощью HTML. Если мы придумаем способ, с помощью которого сможем предоставить HTML в качестве значения ячейки, ссылающейся на изображение, Jupyter сможет это отрисовать и отобразить соответствующий линейный график.
Вот код, который мы для этого используем:
def create_line(data, **kwags):
# Преобразование данных в список
data = list(data)
# Создание объекта фигуры и оси с заданным размером и аргументами ключевых слов
fig, ax = plt.subplots(1, 1, figsize=(3, 0.25), **kwags)
# Построение графика из данных
ax.plot(data)
# Удаление границ в графике
for k,v in ax.spines.items():
v.set_visible(False)
# Удаление делений у осей x и y
ax.set_xticks([])
ax.set_yticks([])
# Создание красной точки в последней точке данных
plt.plot(len(data) - 1, data[len(data) - 1], 'r.')
# Заполнение области под графиком с помощью alpha=0.1
ax.fill_between(range(len(data)), data, len(data)*[min(data)], alpha=0.1)
# Закрытие графика, чтобы он не отображался
plt.close(fig)
# Сохранение графика как изображения в формате png и получение его бинарных данных
img = BytesIO()
fig.savefig(img, format='png')
encoded = b64encode(img.getvalue()).decode('utf-8')
# Возвращение закодированных данных изображения в виде тега изображения HTML
return '<img src="data:image/png;base64,{}"/>'.format(encoded)
Хотя часть построения довольно очевидна, сосредоточимся на том, для чего предназначены последние четыре строки кода (не включая комментарии).
Цель состоит в том, чтобы преобразовать график в изображение, которое может быть отображено на веб-странице.
В первой строке создается новый объект img. BytesIO — это класс в модуле io, который создает буфер байтов в памяти.
Вторая строка сохраняет сгенерированный matplotlib график в объект img как PNG-изображение, используя метод savefig фигурного объекта fig.
Третья строка кодирует содержимое объекта img в виде строки base64 с помощью функции b64encode из модуля base64. Полученная строка base64 затем декодируется в строку Unicode с помощью метода decode с кодировкой utf-8.
Последняя строка возвращает HTML-тег <img> с атрибутом source, установленным в base64-кодированную строку изображения. При отображении этой строки на веб-странице будет показано изображение, сгенерированное matplotlib.
Теперь создаем строку, вызывая метод на каждой строке DataFrame.
df['Price History Line'] = df['Price History'].apply(create_line)
HTML(df.drop(columns = ["Price History"]).to_html(escape=False))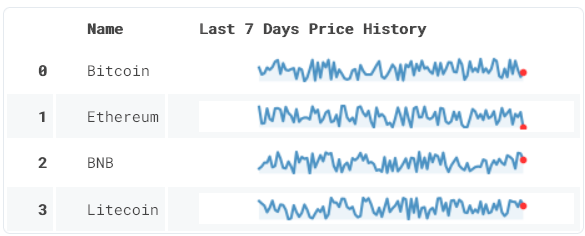
Спарклайны — отличный инструмент для быстрой передачи тенденций и закономерностей в данных. Они могут быть особенно полезны, когда необходимо отобразить много информации на небольшом пространстве.
#2. Написание pandas-flavor
Если вызвать существующий метод в DataFrame Pandas, скажем df.rename(), очевидно, что метод rename() определяется в классе DataFrame.
Но что, если надо присоединить к объекту DataFrame пользовательский метод, скажем, df.my_method()? Такое вполне возможно.
К счастью, Pandas — это библиотека с широким спектром возможностей настройки и множеством способов расширения функциональности для удовлетворения пользовательских потребностей.
Один из популярных подходов — использование библиотеки pandas-flavor. Она позволяет определять и присоединять пользовательские методы Pandas к объекту DataFrame.
Установить ее можно следующим образом:
!pip install pandas_flavorТеперь напишем пользовательский метод в файле my_pandas.py.
# my_pandas.py
import pandas as pd
import pandas_flavor as pf
@pf.register_dataframe_method
def add_row(df, row):
df.loc[len(df)] = rowДопустим, у вас есть следующий DataFrame:
df = pd.DataFrame([["Mercury", 1],
["Venus", 2]],
columns = ["Planet", "Position"])Импортируем файл пользовательского метода my_pandas.py, и он присоединит новый метод к объекту DataFrame:
import my_pandas
new_row = ["Earth", 3]
df.add_row(new_row)
print(df) Planet Position
0 Mercury 1
1 Venus 2
2 Earth 3Библиотека pandas-flavor очень полезна для оптимизации рабочего процесса Pandas. С ее помощью можно создавать функции, адаптированные к конкретному случаю использования, и делать анализ данных более эффективным и интуитивно понятным.
#3. Создание DataFrame из списка объектов класса данных (DataClass)
DataFrame Pandas часто создается из списка Python, словаря, путем чтения файлов и т. д. А знаете ли вы, что можно также создать DataFrame из списка объектов DataClass?
Предположим, у вас есть следующий класс данных Point:
from dataclasses import dataclass
@dataclass
class Point:
x_loc: int
y_loc: intСоздадим несколько объектов из этого класса.
points = [Point(1, 2),
Point(4, 5),
Point(3, 7)]Если передадим этот список объектов класса данных в метод pd.DataFrame, получим на выходе DataFrame:
pd.DataFrame(points) x_loc y_loc
0 1 2
1 4 5
2 3 7Этот подход может пригодиться при работе с классами данных, поскольку он обеспечивает прямой способ создания DataFrame Pandas из коллекции экземпляров.
#4. Отображение индикатора состояния при применении функции с помощью Apply()
Во время применения метода apply() по отношению к DataFrame, мы не видим хода выполнения процесса и предполагаемого оставшегося времени.
Однако это может быть важно при работе с большими наборами данных и сложными операциями. Если такой функции нет, трудно определить, сколько еще времени потребуется для завершения работы.
Кроме того, индикатор выполнения может облегчить принятие решения о том, ожидать ли завершения операции или прервать ее и попробовать другой подход.
Чтобы решить эту проблему, вместо метода apply() можно использовать progress_apply() из tqdm.
Сначала интегрируйте его с Pandas следующим образом:
from tqdm.notebook import tqdm
tqdm.pandas()Теперь при использовании df.progress_apply() получим:
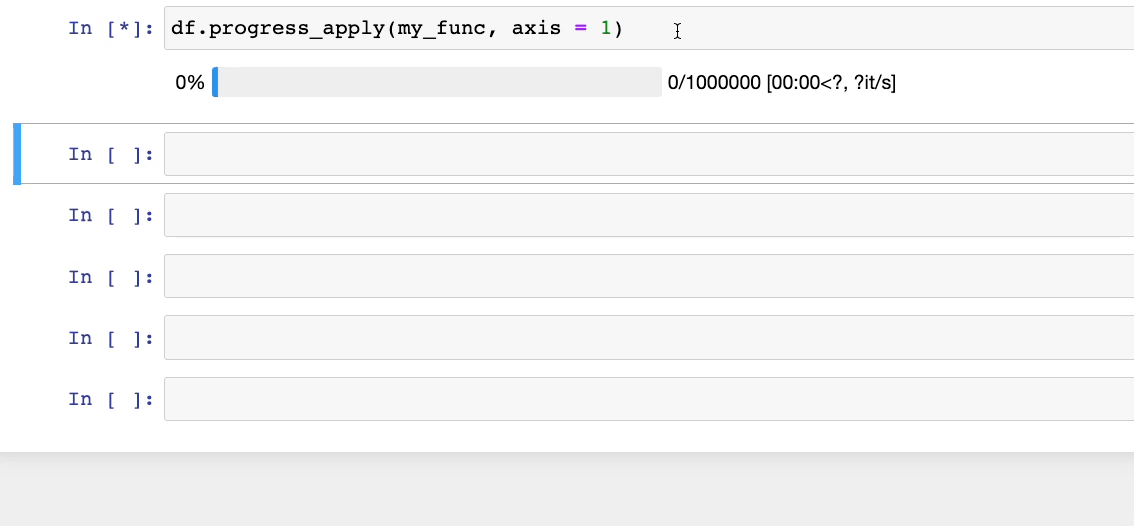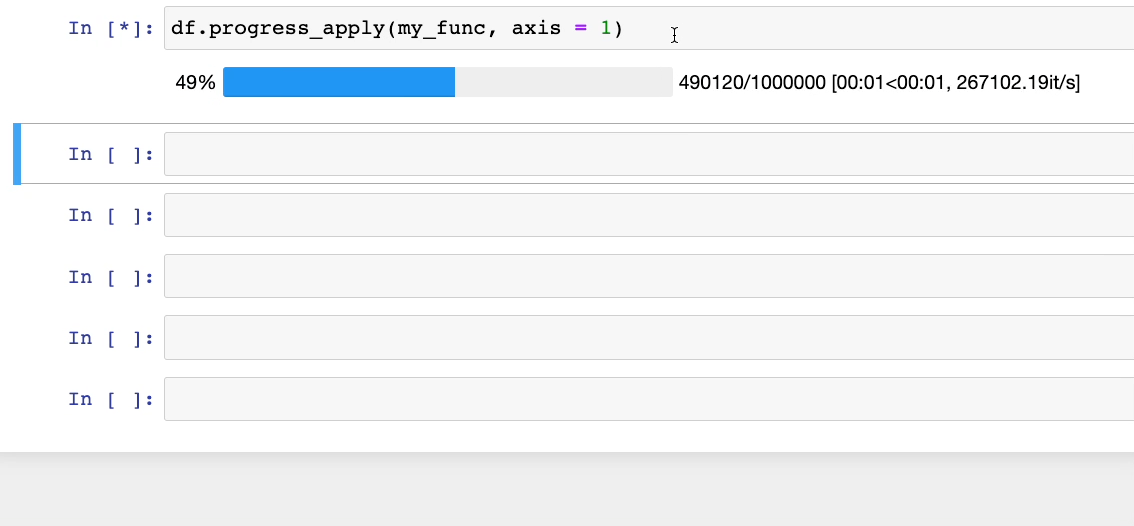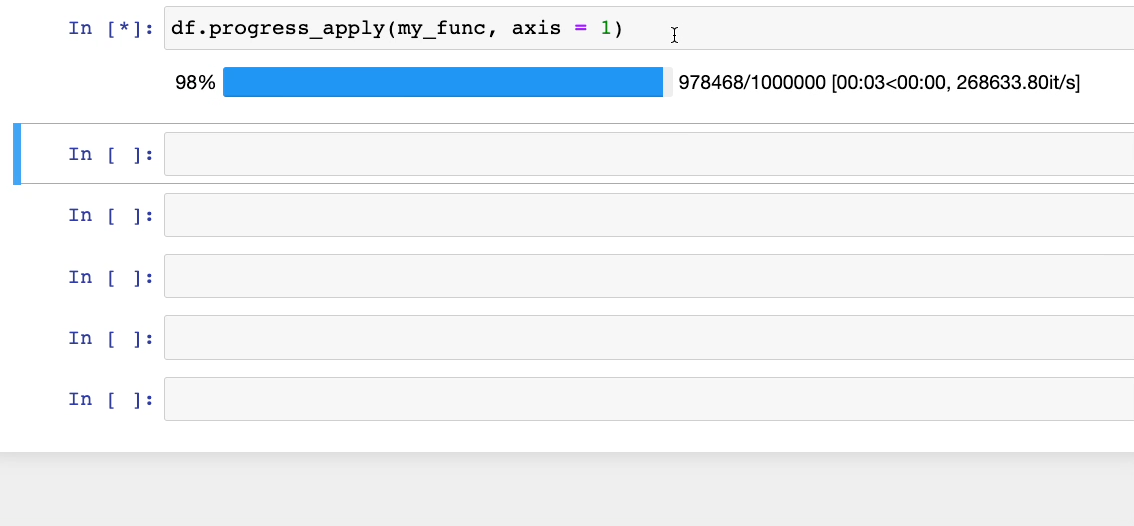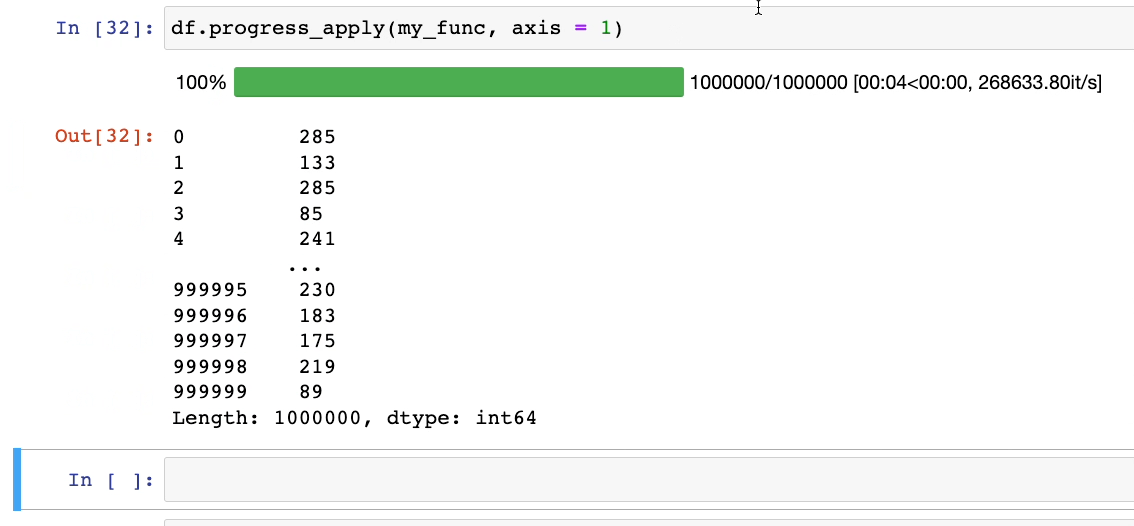
#5. Добавление подписей в DataFrame
При представлении данных в DataFrame добавление подписей к таблицам может обеспечить дополнительный контекст и сделать данные более понятными. Благодаря этому вам не нужно будет добавлять ячейки с разметкой в ноутбук Jupyter.
С помощью API стилизации в Pandas к DataFrame можно добавить подписи. Рассмотрим это на примере.
Допустим, у нас есть следующий DataFrame:
df = pd.DataFrame([['Roy', 25, 50000],
['Bob', 30, 60000],
['Joe', 35, 70000]],
columns = ["Names", "Age", "Salary"]) Names Age Salary
0 Roy 25 50000
1 Bob 30 60000
2 Joe 35 70000Вызываем метод set_caption() на аксессоре style DataFrame:
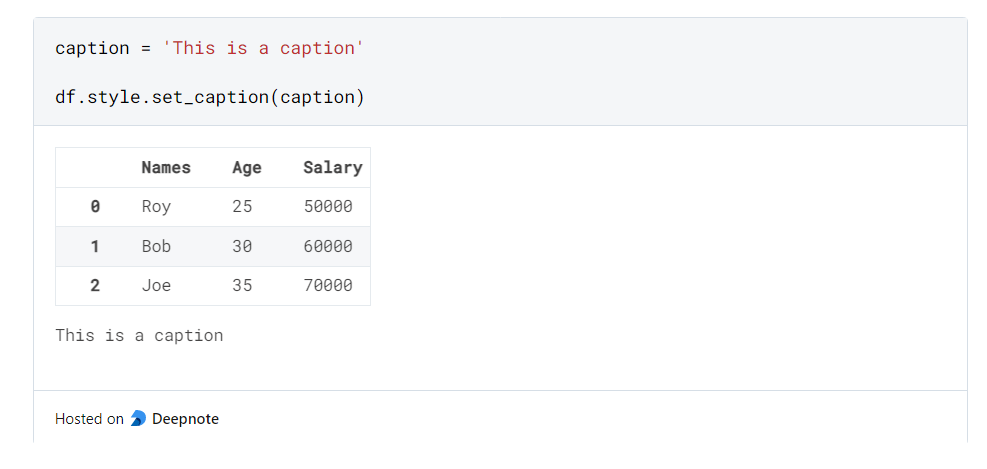
Теперь, как показано выше, DataFrame отображается с подписью.
Добавление подписей позволяет кратко описать DataFrame, его назначение и любую другую важную информацию, которая поможет пользователям быстрее и легче понять данные.
#6. Форматирование предварительного просмотра DataFrame
При выводе DataFrame выглядит как набор необработанных чисел (или строк).
Возьмем для примера следующий датафрейм:
df Name Height Weight Age Saving
0 Alice 168 63 27 1000
1 Bob 175 75 34 1200
2 Charlie 182 91 42 1100В этом случае столбцы данных обозначают какую-то присущую им величину, которую необходимо знать читателю. Но это четко не отражено в данных.
С помощью API стилизации отформатируем вывод предварительного просмотра DataFrame, как показано ниже:
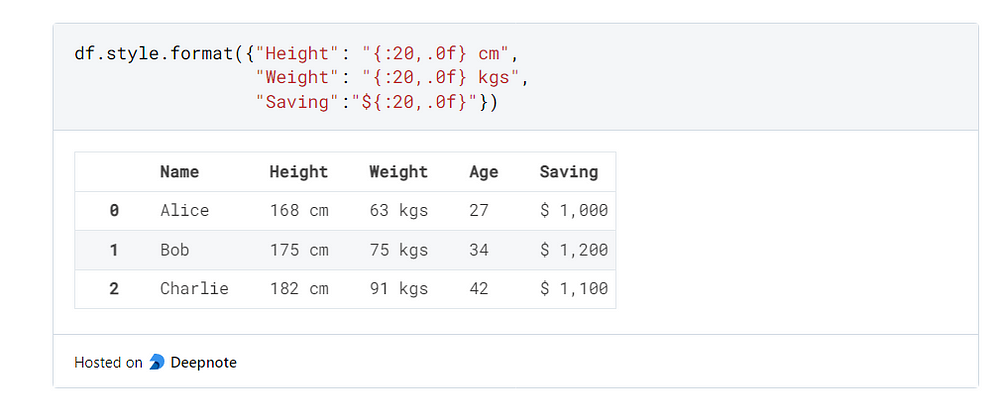
Теперь гораздо нагляднее представлено, что означают отдельные значения, чего не хватало в предварительном просмотре по умолчанию.
Кроме того, вы можете изучить пакет PrettyPandas с открытым исходным кодом, который расширяет класс styler многими другими интересными утилитами.
Читайте также:
- Пакет Lambda-слоев AWS для Python
- Переход с Pandas на Polars: 7 простых шагов
- Топ-10 вопросов о Pandas на StackOverflow
Читайте нас в Telegram, VK и Дзен
Перевод статьи Avi Chawla: 6 Things That You Probably Didn’t Know You Could Do With Pandas





