
ChatGPT помогает автоматизировать различные задачи. Если вы пользовались этим чат-ботом в течение какого-то времени, то, скорее всего, заметили, что он может давать неправильные ответы и обладает ограниченным или нулевым контекстом по некоторым нишевым темам. Возникает вопрос: как устранить этот пробел и снабдить ChatGPT большим объемом пользовательских данных?
Огромное количество знаний распространяется через различные платформы, с которыми мы взаимодействуем ежедневно, например рабочие чаты, соцсети и email-рассылки. Чтобы уследить за всеми этими источниками информации, потребуется полный рабочий день.
Разве не было бы здорово, если бы вы могли сами выбирать источники данных и с легкостью передавать эту информацию собственному ChatGPT?
Подача данных через создание промптов
Рассмотрим проблемы, которые возникают при расширении ChatGPT вручную. Традиционный подход заключается в использовании инженерии промптов (prompt engineering).
Реализовать это довольно просто, поскольку ChatGPT учитывает контекст. Для начала нужно вступить во взаимодействие с ChatGPT, предложив ему исходный контент документа перед фактическими вопросами.
Я буду задавать тебе вопросы на основе следующего контента:
- Начало контента -
Ваш очень длинный текст для создания контекста ChatGPT
- Конец контента -
Проблема заключается в том, что модель имеет ограниченный контекст: GPT-3 может принять всего 4096 токенов. Кроме того, при таком подходе вы вскоре зайдете в тупик, так как довольно утомительно постоянно добавлять контент вручную.
Представьте, что ChatGPT нужно передать сотни PDF-документов. Вскоре вы столкнетесь с проблемой пейволла (ограничения доступа к контенту веб-страницы до внесения оплаты). Возможно, вы сейчас подумали о GPT-4 — преемнике GPT-3? Он был запущен 14 марта 2023 года и может обрабатывать до 25 000 слов (примерно в 8 раз больше, чем GPT-3 обрабатывает изображений) и справляется с обработкой более специфических инструкций, чем GPT-3.5. При этом остается все та же фундаментальная проблема ограничения ввода данных. Как же обойти упомянутые ограничения? В этом поможет библиотека Python под названием LlamaIndex.
Расширение ChatGPT с помощью LlamaIndex (GPT Index)
Проект LlamaIndex, также известный как GPT Index, предоставляет центральный интерфейс для связи больших языковых машин (LLM) с внешними данными. С помощью LlamaIndex можно создать нечто, похожее на изображение ниже:
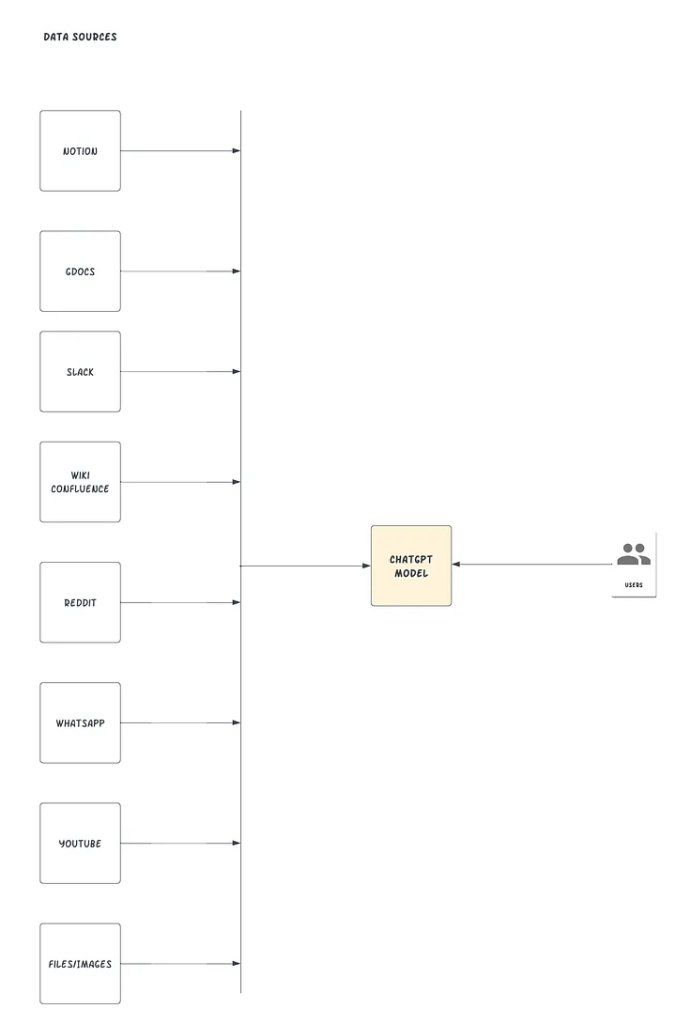
LlamaIndex соединяет существующие источники и типы данных с доступными коннекторами данных (такими как API, PDF, docs, SQL и т. д.). Он позволяет использовать LLM, предлагая индексы для структурированных и неструктурированных данных. Эти индексы облегчают контекстное обучение, удаляя типичные шаблоны и болевые точки и сохраняя контекст в доступной форме для быстрой вставки.
Работа с операционными ограничениями (4096 токенов для GPT-3 Davinci и 8000 токенов для GPT-4) при значительном увеличении контекста становится более доступной и решает проблему разделения текста, предоставляя пользователям возможность взаимодействовать с индексом. LlamaIndex также упрощает процесс извлечения релевантных частей из документов и подачи их в промпт.
Как добавить пользовательский источник данных
В этом разделе будем использовать GPT “text-davinci-003” и LlamaIndex для создания чат-бота с вопросами и ответами на основе уже существующих документов.
Предварительные условия
Убедитесь, что у вас есть доступ к следующему.
- Python ≥ 3.7 на компьютере.
- API-ключ OpenAI, который можно найти на сайте OpenAI. Вы можете использовать свою учетную запись Gmail для единоразового входа.
- Несколько документов Word, загруженных в Google Docs. LlamaIndex поддерживает множество различных источников данных. В этом руководстве будет использовать Google Docs.
Как это работает
- Создание индекса данных документа с помощью LlamaIndex.
- Использование естественного языка для поиска в индексе.
- Извлечение LlamaIndex нужных фрагментов и передача их в промпт GPT. LlamaIndex преобразует исходные данные документа в удобный для запросов векторный индекс. Он будет использовать этот индекс для поиска наиболее подходящих разделов в зависимости от того, насколько точно совпадают запрос и данные. Затем информация будет загружена в промпт, который будет отправлен в GPT, чтобы он имел необходимую информацию для ответа на вопрос.
- Обращение к ChatGPT с вопросом, сформулированным с учетом подачи информации в контексте.
Создайте новую папку для Python-проекта (можно назвать ее mychatbot), предпочтительно используя виртуальную среду или conda-среду.
Сначала установите библиотеки зависимостей. Вот как это сделать:
pip install openai
pip install llama-index
pip install google-auth-oauthlib
Затем импортируйте библиотеки в Python и настройте API-ключ OpenAI в новом файле main.py.
# Импорт необходимых пакетов
import os
import pickle
from google.auth.transport.requests import Request
from google_auth_oauthlib.flow import InstalledAppFlow
from llama_index import GPTSimpleVectorIndex, download_loader
os.environ['OPENAI_API_KEY'] = 'SET-YOUR-OPEN-AI-API-KEY'
В приведенном выше фрагменте переменная среды установлена явно для наглядности, поскольку пакет LlamaIndex неявно требует доступа к OpenAI. В обычной производственной среде можно поместить ключи в переменные среды, хранилище или любой другой сервис управления учетными цифровыми идентификационными данными, к которому может получить доступ ваша инфраструктура.
Создайте функцию, которая поможет авторизоваться в Google-аккаунте, чтобы открыть Google Docs.
def authorize_gdocs():
google_oauth2_scopes = [
"https://www.googleapis.com/auth/documents.readonly"
]
cred = None
if os.path.exists("token.pickle"):
with open("token.pickle", 'rb') as token:
cred = pickle.load(token)
if not cred or not cred.valid:
if cred and cred.expired and cred.refresh_token:
cred.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file("credentials.json", google_oauth2_scopes)
cred = flow.run_local_server(port=0)
with open("token.pickle", 'wb') as token:
pickle.dump(cred, token)
Чтобы подключить API Google Docs и получить учетные данные в Google Console, выполните следующие шаги.
- Перейдите на сайт Google Cloud Console.
- Создайте новый проект, если вы еще этого не сделали. Нажмите на выпадающее меню “Select a project” (“Выбрать проект”) в верхней навигационной панели и выберите “New Project” (“Новый проект”). Следуйте подсказкам, чтобы дать проекту название и выбрать организацию, с которой вы хотите его связать.
- После создания проекта выберите его из выпадающего меню в верхней навигационной панели.
- Перейдите в раздел “APIs & Services” (“API и службы”) в меню слева и нажмите на кнопку “+ ENABLE APIS AND SERVICES” (“+ Подключить API и службы”) в верхней части страницы.
- Найдите в строке поиска “Google Docs API” и выберите его в списке результатов.
- Нажмите кнопку “Enable” (“Подключить”), чтобы активировать API для проекта.
- Кликните на меню экрана согласия OAuth, создайте и дайте приложению имя, например “mychatbot”, затем введите email поддержки, сохраните и добавьте области действия.
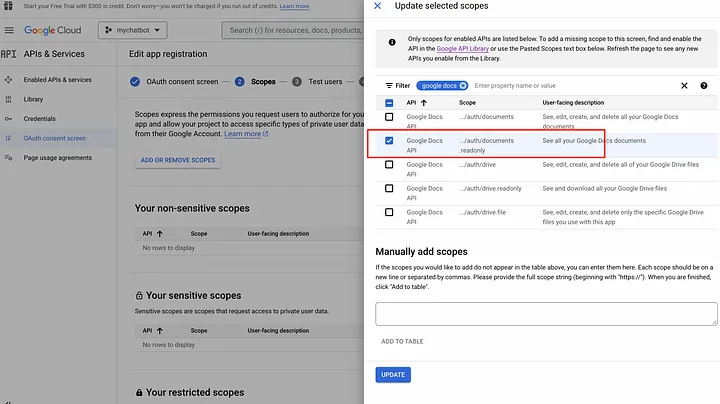
Добавьте также тестовых пользователей, поскольку создаваемое Google-приложение еще не одобрено. Это может быть ваш собственный адрес электронной почты.
Затем настройте учетные данные для проекта, чтобы использовать API. Для этого перейдите в раздел “Credentials” (“Учетные данные”) в левом меню и нажмите “Create Credentials” (“Создать учетные данные”). Выберите “OAuth client ID” (“Клиентский ID OAuth”) и следуйте подсказкам по настройке учетных данных.
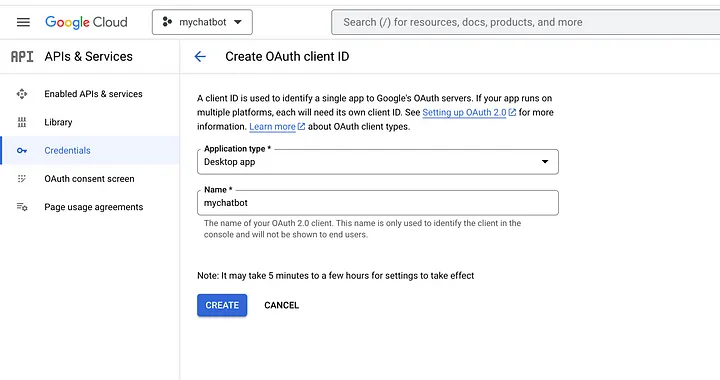
После настройки учетных данных загрузите JSON-файл и сохраните его в корне приложения, как показано ниже:
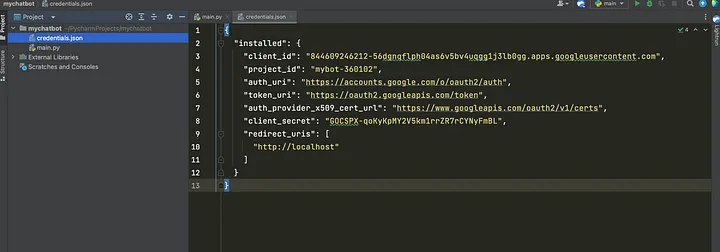
После настройки учетных данных можно получить доступ к API Google Docs из проекта Python.
Перейдите к Google Docs, откройте несколько документов и получите уникальный идентификатор, который можно увидеть в URL-строке браузера, как показано ниже:
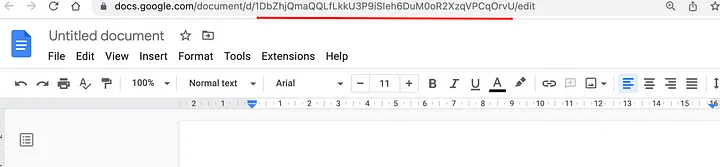
Скопируйте идентификаторы gdoc и вставьте их в код ниже. У вас может быть N-ное количество gdoc, которые вы можете индексировать, чтобы ChatGPT имел контекстный доступ к вашей пользовательской базе знаний. Для загрузки документов будем использовать плагин GoogleDocsReader из библиотеки LlamaIndex.
# функция для авторизации или загрузки последних учетных данных
authorize_gdocs()
# инициализируйте LlamaIndex google doc reader
GoogleDocsReader = download_loader('GoogleDocsReader')
# список документов google, которые нужно проиндексировать
gdoc_ids = ['1ofZ96nWEZYCJsteRfqik_xNQTGFHtnc-7cYrf0dMPKQ']
loader = GoogleDocsReader()
# загрузка gdocs и их индексация
documents = loader.load_data(document_ids=gdoc_ids)
index = GPTSimpleVectorIndex(documents)
LlamaIndex обладает множеством коннекторов данных, охватывающих такие сервисы, как Notion, Obsidian, Reddit, Slack и т. д. Сокращенный список доступных коннекторов данных можно найти здесь.
Чтобы сохранять и загружать индекс “на лету”, можно использовать следующие вызовы функций. Это ускорит процесс выборки из предварительно сохраненных индексов вместо того, чтобы делать вызовы API к внешним источникам.
# Сохраните индекс в файле index.json
index.save_to_disk('index.json')
# Загрузите индекс из сохраненного файла index.json
index = GPTSimpleVectorIndex.load_from_disk('index.json')
Запросить индекс и получить ответ позволит следующий код. Код может быть легко расширен до REST API, который подключается к пользовательскому интерфейсу, где вы можете взаимодействовать с пользовательскими источниками данных через интерфейс GPT.
# Запрос индекса
while True:
prompt = input("Type prompt...")
response = index.query(prompt)
print(response)
Итак, у нас есть Google-документ с подробной информацией обо мне, которая доступна при открытом поиске в Google.
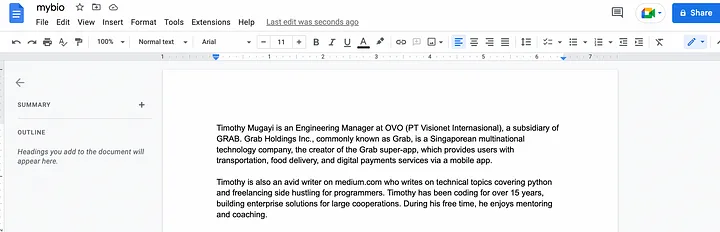
Сначала будем взаимодействовать непосредственно с ванильным ChatGPT, чтобы посмотреть, какой вывод он генерирует без внедрения пользовательского источника данных.
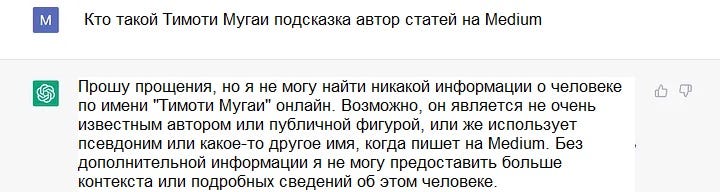
Признаться, я несколько разочарован! Попробуем еще раз.
INFO:google_auth_oauthlib.flow:"GET /?state=oz9XY8CE3LaLLsTxIz4sDgrHha4fEJ&code=4/0AWtgzh4LlIfmCMEa0t36dse_xoS0fXFeEWKHFiouzTvz4Qwr7T2Pj6anb-GiZ__Wg-hBBg&scope=https://www.googleapis.com/auth/documents.readonly HTTP/1.1" 200 65
INFO:googleapiclient.discovery_cache:file_cache is only supported with oauth2client<4.0.0
INFO:root:> [build_index_from_documents] Total LLM token usage: 0 tokens
INFO:root:> [build_index_from_documents] Total embedding token usage: 175 tokens
Type prompt...кто такой тимоти мугаи подсказка он автор статей на medium
INFO:root:> [query] Total LLM token usage: 300 tokens
INFO:root:> [query] Total embedding token usage: 14 tokens
Тимоти Мугаи - руководитель инженерного отдела в OVO (PT Visionet Internasional), дочерней компании GRAB. Он также является постоянным автором на сайте medium.com, который пишет на технические темы, охватывающие python и фриланс для программистов. Тимоти программирует уже более 15 лет, создавая корпоративные решения для крупных коопераций. В свободное время он увлекается наставничеством и коучингом.
last_token_usage=300
Type prompt...
Type prompt...Учитывая, что ты знаешь, кто такой Тимоти Мугаи, напиши о нем интересное представление.
Тимоти Мугаи - опытный и успешный профессионал с богатыми знаниями в области инженерии, программирования и наставничества. В настоящее время он является руководителем инженерного отдела в компании OVO, дочерней компании GRAB, и уже более 15 лет занимается программированием, создавая корпоративные решения для крупных коопераций. В свободное время Тимоти любит писать на технические темы, такие как Python и фриланс, подрабатывая программистом на сайте medium.com, а также заниматься наставничеством и коучингом. Благодаря своему впечатляющему опыту и знаниям Тимоти является ценным активом для любой организации.
last_token_usage=330
Теперь он может выводить ответы, используя новый пользовательский источник данных, точно выдавая результат.
А мы можем пойти еще дальше.
Type prompt...Напиши сопроводительное письмо для Тимоти Мугаи для проекта upwork python по созданию пользовательского бота ChatGPT с доступом к внешним источникам данных
INFO:root:> [query] Total LLM token usage: 436 tokens
INFO:root:> [query] Total embedding token usage: 30 tokens
Уважаемый [Менеджер по найму],
Я пишу, чтобы подать заявку на участие в проекте Python по созданию пользовательского бота ChatGPT с доступом к внешним источникам данных. Имея более чем 15-летний опыт программирования и создания корпоративных решений для крупных корпораций, я уверен, что являюсь идеальным кандидатом на эту должность.
В настоящее время я работаю руководителем инженерного отдела в OVO (PT Visionet Internasional), дочерней компании GRAB. У меня большой опыт работы с Python, я пишу на технические темы, охватывающие Python и фриланс-подработку для программистов, на сайте medium.com. Я также являюсь убежденным наставником и коучем и считаю, что мой опыт и набор навыков делают меня идеальным кандидатом для этого проекта.
Уверен, что смогу предоставить высококачественный продукт, отвечающий требованиям проекта. Я также готов обсудить проект и ответить на любые ваши вопросы.
Спасибо за ваше время и внимание.
С уважением,
Тимоти Мугаи
last_token_usage=436
Type prompt...
LlamaIndex внутренне примет промпт, выполнит поиск в индексе соответствующих фрагментов, а затем передаст промпт и соответствующие фрагменты в модель ChatGPT. Приведенные выше процедуры демонстрируют первое фундаментальное использование LlamaIndex и GPT для ответов на вопросы. Тем не менее вы можете сделать гораздо больше. Вы ограничены только пределами вашей креативности при настройке LlamaIndex на применение другой LLM, использование другого типа индекса для различных действий или программное обновление старых индексов.
Вот пример изменения модели LLM в явном виде. На этот раз используем другой пакет Python под названием langchain, поставляемый вместе с LlamaIndex.
from langchain import OpenAI
from llama_index import LLMPredictor, GPTSimpleVectorIndex, PromptHelper
...
# определение другой LLM в явном виде
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003"))
# определение конфигурации промпта
# установка максимального размера ввода
max_input_size = 4096
# настройка количества токенов на выходе
num_output = 256
# настройка максимального оверлапа блока
max_chunk_overlap = 20
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
index = GPTSimpleVectorIndex(
documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper
Мониторить бесплатные и платные OpenAI-кредиты можно на дашборде OpenAI.
При создании индекса, вставке в индекс и запросе к индексу используются токены. Поэтому при создании пользовательских ботов важно обеспечить вывод данных об использовании токенов в целях мониторинга.
last_token_usage = index.llm_predictor.last_token_usage
print(f"last_token_usage={last_token_usage}")
Итоги
Расширение ChatGPT с помощью LlamaIndex позволит создать специализированного чат-бота ChatGPT, способного выводить сведения на основе данных из ваших документов. Это обеспечивает более продвинутый опыт и открывает возможность для создания чат-бота, способного общаться в разговорном стиле и пригодного для выполнения реальных бизнес-кейсов, таких как поддержка клиентов и даже классификация спама.
Читайте также:
- Как создать чат-бот на основе данных CSV с LangChain и OpenAI
- 8 инструментов для предпринимателей, похожих на ChatGPT
- Как сделать интеллектуальное приложение вопросов и ответов базы знаний с GPT-3 и Ruby
Читайте нас в Telegram, VK и Дзен
Перевод статьи Timothy Mugayi: How to build your own Custom ChatGPT bot with Custom Knowledge Base
![[SwiftUI] @AppStorage: управление UserDefaults с помощью ViewModel](https://nuancesprog.ru/wp-content/uploads/2025/02/SwiftUI-pattern-324x235.png "[SwiftUI] @AppStorage: управление UserDefaults с помощью ViewModel")




