
В крупном кластере K8s, где более 50 рабочих узлов или они расположены в разных зонах или регионах, поды рабочих нагрузок распределяются по разным узлам, зонам или даже регионам.
Это положительно сказывается на использовании рабочими нагрузками кластера и высокой доступности:
Распределение подов в кластере — непростая задача, которая контролируется с помощью их сходства (affinity) и антисходства (anti-affinity). Но этим функционалом K8s разрешается лишь часть вариантов распределения подов.
Равномерно распределять поды по кластеру для эффективного использования его ресурсов и высокой доступности призван планировочный плагин PodTopologySpread, первый стабильный релиз которого появился в K8s версии v1.19.
Поле topologySpreadConstraints
В этом поле домен(-ы) топологии, в котором(-ых) находится каждый рабочий узел, идентифицируется(-ются) метками узлов. Чтобы указать kube-scheduler, как размещать каждый входящий под относительно уже имеющихся в кластере, определяется одна или несколько записей topologySpreadConstraints.
Когда подом определяется более одного topologySpreadConstraint, эти ограничения объединяются посредством логической операции AND: в kube-scheduler ведется поиск узла для входящего пода, удовлетворяющего всем настроенным ограничениям.
Шаблон topologySpreadConstraints таков:
---
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Настраиваются ограничения на распространение топологии
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # дополнительно; в бета с версии v1.25
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # дополнительно; в альфа с версии v1.25
nodeAffinityPolicy: [Honor|Ignore] # дополнительно; в альфа с версии v1.25
nodeTaintsPolicy: [Honor|Ignore] # дополнительно; в альфа с версии v1.25
### другие поля пода находятся здесь
maxSkew
Этим полем описывается степень неравномерного распределения подов, число указывается больше нуля.
Если задать whenUnsatisfiable: DoNotSchedule, в maxSkew определится максимально допустимая разница между числом подходящих подов в целевой топологии и глобальным минимумом (минимальным их числом в доступном домене или нулем, если доступных доменов меньше, чем MinDomains).
Например, в кластере с тремя зонами значение MaxSkew равно 1, и поды с тем же labelSelector распределяются как 1/1/0: us-east-1a/us-east-1b/us-east-1c. Если значение MaxSkew равно 1, входящий под планируется только в us-east-1c, а распределение становится 1/1/1. Планирование его в us-east-1a или в us-east-1b приведёт к «перекосу» MaxSkew (1) с ActualSkew (2-0) в пользу us-east-1a или us-east-1b . Если MaxSkew равно 2, входящий под планируется в любую зону.
При whenUnsatisfiable=ScheduleAnyway приоритет топологий, которые ограничению удовлетворяют, повышается. Это обязательное поле. Значение по умолчанию равно 1, а 0 недопустимо.
minDomains
Это минимальное число доступных доменов, необязательное поле. Домен — конкретный экземпляр топологии. Доступным называют домен, узлы которого соответствуют селектору узлов. Это поле в бета и включено по умолчанию в K8s версии v1.25.
topologyKey
Это ключ меток узлов. Считается, что узлы, имеющие метку с этим ключом и идентичными значениями, находятся в одной топологии. Каждый экземпляр топологии (то есть пара <ключ, значение>) называется доменом.
В каждый домен планировщиком помещается сбалансированное число подов. Доступным определяется домен, узлы которого соответствуют требованиям nodeAffinityPolicy и nodeTaintsPolicy.
В шаблоне пода выше определяются topologySpreadConstraints:
maxSkew: 1
topologyKey: topology.kubernetes.io/zone
Если у рабочих узлов имеется метка topology.kubernetes.io/zone=us-east-1a/b/c/d.
Внимание: в K8s версии
v1.21из-за бага имеет место некорректная реакция автомасштабировщика кластера на новую меткуtopology.kubernetes.io/zone, поэтому потребуется использоватьfailure-domain.beta.kubernetes.io/zone.
whenUnsatisfiable
В этом поле указывается, как быть с подом, не соответствующим ограничению на распространение.
DoNotScheduleзадается по умолчанию: планировщиком под не планируется.ScheduleAnyway: планировщиком под планируется, а приоритет минимизирующих «перекос» узлов повышается.
labelSelector
Это поле для поиска подов, подходящих данному селектору меток. Путем подсчета этих подов определяется их число в соответствующем домене топологии.
matchLabelKeys
Это список ключей меток подов для выбора тех подов, по которым высчитывается распределение. Ключи используются для поиска значений в метках подов.
Чтобы отобрать группу имеющихся подов, по которым высчитывается распределение для входящего пода, с этими метками «ключ — значение» и labelSelector проводятся логические операции AND.
Ключи, которых нет в метках подов, в расчет не принимаются. Если список пустой или со значением null, сопоставление выполняется только с labelSelector.
С matchLabelKeys обновлять pod.spec между различными версиями не нужно: контроллеру или оператору достаточно задать разные значения одному и тому же ключу меток для этих версий. Значения на основе matchLabelKeys принимаются планировщиком автоматически.
Например, при работе с Deployment, чтобы различать разные версии в одном развертывании, используется автоматически добавляемая контроллером Deployment метка с ключом pod-template-hash:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
matchLabelKeys:
- app
- pod-template-hash
Внимание: поле matchLabelKeys добавлено в альфа в версии 1.25. Чтобы его использовать, подключите feature gate MatchLabelKeysInPodTopologySpread.
nodeAffinityPolicy
В этом поле указывается, как быть с nodeAffinity/nodeSelector подов при вычислении «перекоса» их распределения в топологии. Возможны два варианта.
- Honor: в вычисления включаются только узлы, соответствующие nodeAffinity/nodeSelector.
- Ignore: nodeAffinity/nodeSelector игнорируются. В вычисления включаются все узлы.
Если это значение null, поведение эквивалентно политике Honor.
Это поле уровня альфа в версии v1.25.
nodeTaintsPolicy
В этом поле указывается, как быть с запретами на размещение подов в узлах при вычислении «перекоса» их распределения в топологии. Аналогично nodeAffinityPolicy имеются два варианта.
- Honor: включаются узлы без запретов на размещение подов, а также запрещенные узлы, для которых у входящего пода имеется допуск.
- Ignore: запреты на размещение подов в узлах игнорируются. Включаются все узлы. Если это значение null, поведение эквивалентно политике Ignore.
Это поле уровня альфа в версии v1.25.
Демо топологии подов
В 4-хузловом кластере три пода с метками foo: bar расположены в узлах node1, node2 и node3 соответственно:
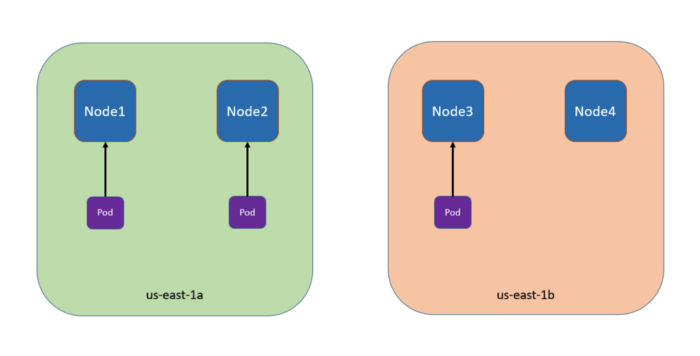
Чтобы запланировать 4-й под в node4 в us-east-1b, настроим его так:
kind: Pod
apiVersion: v1
metadata:
name: myapp
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
containers:
- name: nginx
image: nginx:1.21.1
topologyKey: zone означает, что равномерное распределение применяется только к узлам с меткой zone: <any value>. Узлы, не имеющие метку zone, пропускаются.
Поле whenUnsatisfiable: DoNotSchedule сообщает, что нужно оставить входящий под в ожидании, если планировщик не находит способ удовлетворить ограничение.
Читайте также:
- Kubernetes: установка MicroK8s на локальном компьютере за 5 минут
- Kubernetes: преимущества простых кластеров
- Введение в конвейерную обработку данных с использованием бессерверной архитектуры
Читайте нас в Telegram, VK и Дзен
Перевод статьи Tony: K8s — Pod Topology





