
Представьте, что вам нужно проанализировать данные об элементах, которые клиенты видят в списке веб-приложения. Это могут быть результаты поиска, товары для продажи, наиболее релевантные сообщения в ленте новостей и список новых звонков в службу поддержки клиентов — для аналитиков они все одинаковы.
Такие данные могут быть использованы аналитиками для оценки CTR (показателя кликабельности) при разработке тех или иных рекомендательных алгоритмов, позволяющих определить наблюдаемость различных позиций в списке (например, 1-я по сравнению с 10-й).
В современном стеке данных такой тип данных легко собрать.
1. Фронтенд или мобильное приложение покажет пользователю список и одновременно отправит в аналитику событие, содержащее следующий JSON:

2. “Отправить в аналитику” означает отправить на конечную точку API. Это позволит доставить JSON в конвейер доставки данных (на основе Kafka и более современных инструментов, таких как Airbyte и Fivetran).
3. Конвейер доставки данных будет добавлять каждый входящий JSON в целевую таблицу в современной аналитической базе данных Snowflake. Назовем эту таблицу RAW_Events.
4. Вот и все!
Преимущество современного стека данных в том, что вам не нужно думать о масштабируемости конвейера доставки данных, объемах данных в целевой базе данных и о преобразовании входящих данных.
Как аналитик может работать с такими данными? Современные аналитические базы данных, такие как Snowflake, работают напрямую с JSON и требуют от аналитиков знания только SQL.
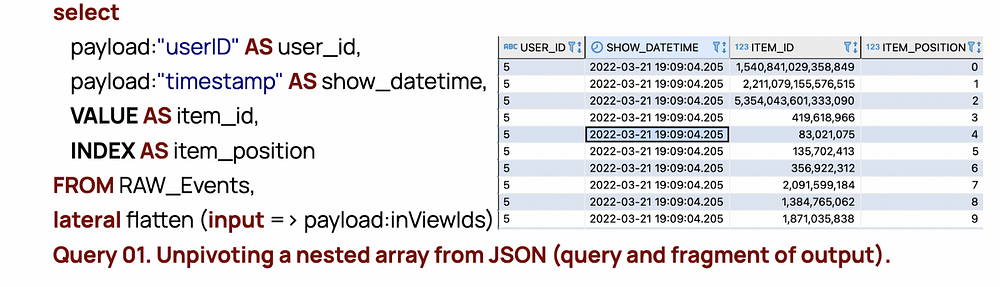
Вернемся к примеру с событием:

Это означает, что пользователь с идентификатором 3299223 открыл приложение (время открытия — ‘2022–04–21 12:31:55 UTC’) и просмотрел список из шести элементов, где 1037287139 — первый, 1727228887 — второй и 1665899805 — последний. Элементы хранятся в виде массива. Позиция в массиве соответствует позиции на экране.
Такой подход к хранению данных нарушает первую нормальную форму. В прошлом аналитики не могли работать с такими данными (JSON, массивы в одном поле), используя только SQL. Но теперь можно легко “разворачивать” такой массив.
Представьте, что аналитики хотят посмотреть, сколько пользователей сегодня видели элемент 1037287139 на первой позиции. Как это сделать?

В мире современного стека данных запрос, подобный приведенному выше, будет работать, даже если таблица Events содержит сотни миллиардов событий, до 10 000 новых событий в секунду.
Но вернемся к изначальному вопросу: почему стоит заботиться о моделировании, если все так прекрасно?
Запрос 2 отвечает на этот вопрос. Его синтаксис сложен. Чтобы получить необходимые данные, требуется прочитать буквально все JSON из таблицы Raw_Events, распаковать их, развернуть и выполнить вычисление, даже если ответ равен 42, а таблица RAW_Events на самом деле содержит сотни миллиардов JSON. Такой запрос может быть долгим и затратным, особенно в современном стеке данных, инструменты которого по сути предусматривают решение проблем производительности посредством вливания большего количества денег.
Представьте, что аналитик намерен продолжить исследование. Допустим, он хочет оценить среднее положение элементов в списке, в отношении которых в данный момент были активированы дополнительные услуги.
Чтобы решить эту проблему, запрос 1 должен быть объединен с другими таблицами (если они есть в системе). Такой JOIN не только сложен в написании для аналитиков, но и ему потребуется обработка всех JSON из таблицы RAW_Events снова и снова, чтобы получить результат запроса.
Приведенный пример дает представление о ситуациях, когда может понадобиться моделирование данных даже в мире современного стека данных. Вот эти ситуации:
- данные достаточно большие;
- запросы к данным достаточно часты;
- количество аналитиков ограничено;
- необходимо, чтобы все аналитики выполняли одну и ту же операцию одинаково эффективно, не выдавая противоречивых результатов.
Рассмотрим следующий этап моделирования данных:

Таблица Events будет содержать все данные из RAW_Events, уже распакованные и отсортированные. Ее можно инкрементально заполнять новыми входящими событиями ежедневно и ежечасно, что делает такие операции чрезвычайно быстрыми и дешевыми.
Аналитикам, желающим узнать, сколько пользователей сегодня видели элемент 1037287139 на первом месте, нужно сделать следующий запрос:

И вот разница между запросом 2 и запросом 4, отвечающими на один и тот же вопрос:
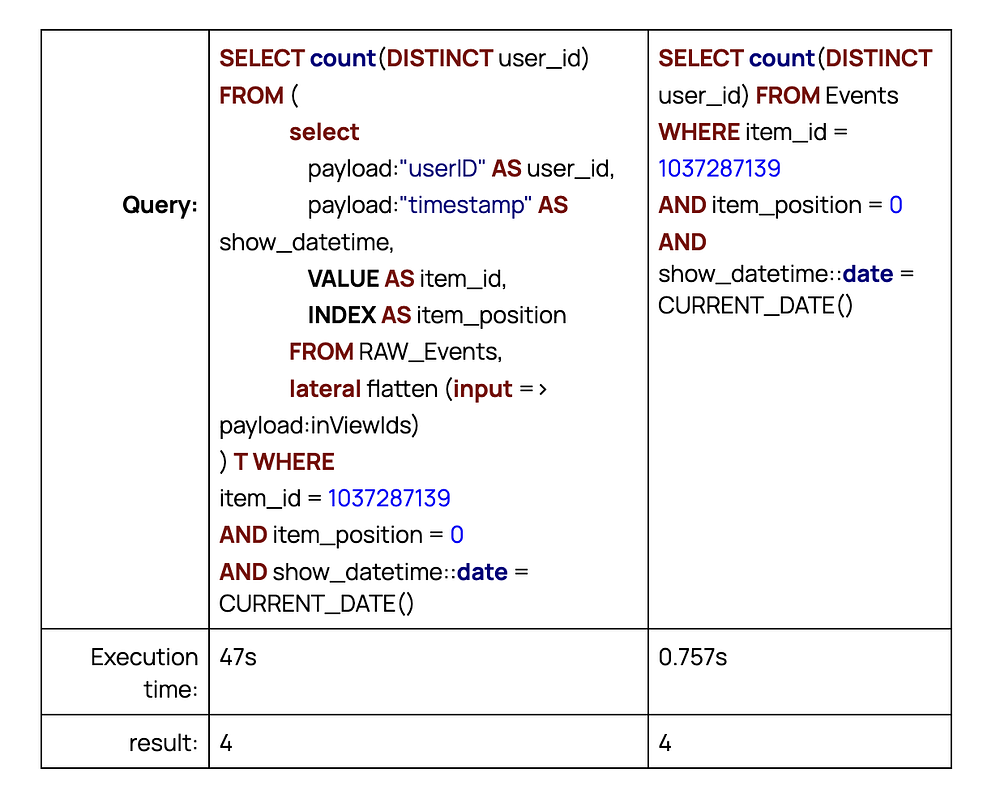
Описанный выше эксперимент был проведен с таблицей RAW_Events, содержащей примерно 20 млн файлов JSON.
Оба запроса выполнялись на одном кластере Snowflake размером X-Small. Даже для такой маленькой выборочной задачи разница огромна.
Реальные аналитические задачи требуют анализа миллиардов JSON, что заставляет каждый запрос обрабатывать как минимум в 1000 раз больше данных и тратить соответственно больше времени и/или денег.
Как видно из примера выше, однократный запуск запроса 2 (медленный, 47 с) вполне приемлем. Однако если немногим аналитикам нужно выполнять такие запросы несколько раз в день, они, скорее всего, предпочтут запрос 4 как более простой и быстрый.
Подведем итоги. 10-20 лет назад вряд ли можно было представить, что аналитик может использовать запросы типа 1 или 2 для анализа сотен миллионов строк без предварительной подготовки данных инженером по данным или специалистом по моделированию данных. Современный стек данных предоставляет аналитику возможность самостоятельно исследовать данные. Подготовка данных и моделирование данных могут повысить производительность (запросы 3 и 4), но не принципиально.
Читайте также:
- 8 структур данных, которые должен знать каждый дата-сайентист
- Топ-5 браузерных расширений для специалистов по анализу данных
- Двоичные деревья: управляемый подход к поиску значений
Читайте нас в Telegram, VK и Дзен
Перевод статьи Nikolay Golov: Data modeling in the world of the Modern Data Stack 2.0





