
Кто-то из нас ходит по бакалейным магазинам со стандартным списком продуктов и запасается только тем, что запланировал заранее; другим же сложно удержаться от того, чтобы не купить что-нибудь еще. Независимо от того, к какому типу людей вы относитесь, продавцы всегда придумают сотни различных способов, чтобы заставить вас потратить как можно больше денег.
Помните тот момент, когда у вас возникает мысль: “Ооо, а ведь мне это тоже может понадобиться”? На это и полагаются розничные торговцы, увеличивая таким образом объем своих продаж. Ход их рассуждений прост:
Люди, которые покупают это, скорее всего, захотят купить и то.
Если вы покупаете хлеб, то с большой вероятностью купите и масло, поэтому опытный менеджер по ассортименту знает точно, что скидка на хлеб подтолкнет и продажи масла.
Стратегии, основанные на данных
Крупные розничные компании опираются на детальный анализ рыночной корзины для выявления ассоциаций между товарами. Используя эту ценную информацию, они могут применять различные стратегии для повышения своих доходов:
- Ассоциированные товары размещают рядом, чтобы побудить покупателей одного продукта к приобретению другого.
- Скидки могут применяться только к одному из ассоциированных товаров.

Поиск ассоциативных правил
Но как именно проводится анализ рыночной корзины?
Специалисты по исследованию данных могут проводить анализ рыночной корзины путем применения поиска ассоциативных правил (Association Rule Mining). Это основанный на правилах метод машинного обучения, который помогает выявить значимые корреляции между различными продуктами в соответствии с их встречаемостью в наборе данных.
Одним из основных недостатков этого метода является то, что он состоит из различных формул и параметров, и это может затруднить его применение людьми, не имеющими опыта в области добычи данных. Поэтому, прежде чем делиться своими результатами с заинтересованными сторонами, убедитесь, что они хорошо понимают, о чем идет речь.

Иллюстрация базовых концепций
Ниже я продемонстрирую на простых примерах три основные концепции, используемые при поиске ассоциативных правил. Это поможет вам понять процесс добычи нужных данных.
Предположим, вы открыли свой кафетерий. Как вы будете использовать навыки интеллектуального анализа данных, чтобы понять, какие из продуктов в вашем меню связаны между собой?
Всего у нас есть шесть транзакций с различными покупками, которые наблюдаются в вашем кафетерии:

Мы можем использовать три основных показателя, которые применяются в обучении ассоциативным правилам, а именно: Поддержку (Support), Доверие (Confidence) и Подъем (Lift).
Поддержка (Support)
Поддержка — это простая базовая вероятность того, что событие произойдет. Она измеряется долей транзакций, в которых появляется набор элементов. Говоря иначе, Support(A) — это количество транзакций, включающих A, деленное на общее количество транзакций.
Если проанализировать приведенную выше таблицу транзакций, то поддержка для печенья составляет 3 из 6. То есть, из 6 транзакций покупки, содержащие печенье, произошли 3 раза (это составляет 50%).

Поддержка может быть реализована для нескольких продуктов одновременно. Поддержка для печенья и торта составляет 2 из 6.

2. Доверие (Confidence)
Доверие к последующему событию при наличии предшествующего события можно описать с помощью условной вероятности. Проще говоря, это вероятность наступления события А при условии, что событие В уже произошло.
Этот принцип можно использовать для описания вероятности покупки товара, когда другой товар уже находится в корзине. Показатель доверия измеряется путем деления доли транзакций с товарами X и Y на долю транзакций с товаром Y.
Исходя из приведенной выше таблицы транзакций, доверие {cookie -> cake} ({печенье -> торт}) может быть сформулировано так, как показано ниже:

Условную вероятность также можно записать следующим образом:
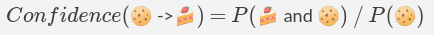
Наконец, мы приходим к решению — 2 из 3. Мы бы могли понять принцип доверия на интуитивном уровне, если рассмотрели бы только транзакции с 1-й по 3-ю. Из 3 случаев покупок печенья, 2 раза его покупали вместе с тортом!
3. Подъем (Lift)
Подъем — это отношение наблюдаемого к ожидаемому (сокращенно н/о). Показателем подъема измеряют вероятность того, что товар будет куплен при покупке другого товара, при этом учитывается популярность обоих товаров. Его можно рассчитать, разделив вероятность того, что оба товара окажутся вместе, на произведение вероятностей того, что оба товара окажутся вместе, как если бы между ними не было связи.

Значение Lift, равное 1, говорит о том, что оба элемента фактически независимы и никак не связаны между собой. Любое значение Lift, превышающее 1, показывает, что связь существует. Чем выше значение, тем выше степень связи.
Если мы снова взглянем на таблицу, то увидим, что подъем {cookies -> cake} равен 2, следовательно, между печеньями и тортами существует связь.
Теперь, когда мы освоили основные концепции, рассмотрим алгоритм, способный генерировать наборы элементов из транзакционных данных; именно он используется для расчета правил ассоциации.
Алгоритм Apriori
Обзор
Алгоритм Apriori — один из самых популярных алгоритмов, используемых в обучении правилам ассоциаций на реляционных базах данных. Он определяет элементы в наборе данных и далее расширяет их на все большие и большие наборы элементов.
Однако алгоритм Apriori расширяется только в том случае, если наборы элементов являются частыми, то есть если существует вероятность того, что набор элементов превышает определенный заранее установленный порог.

Если говорить более формально, то алгоритм Apriori предполагает следующее.
Вероятность того, что набор элементов не является частым, возможна в двух случаях:
- P(I) < минимального порога поддержки, где I — любой непустой набор элементов.
- Любое подмножество в наборе элементов имеет значение меньше минимальной поддержки.
Вторая характеристика определяется как свойство антимонотонности. Вот удачный пример: если вероятность покупки бургера ниже минимальной поддержки, то вероятность покупки бургера и картофеля фри также будет ниже минимальной поддержки.
Шаги алгоритма Apriori
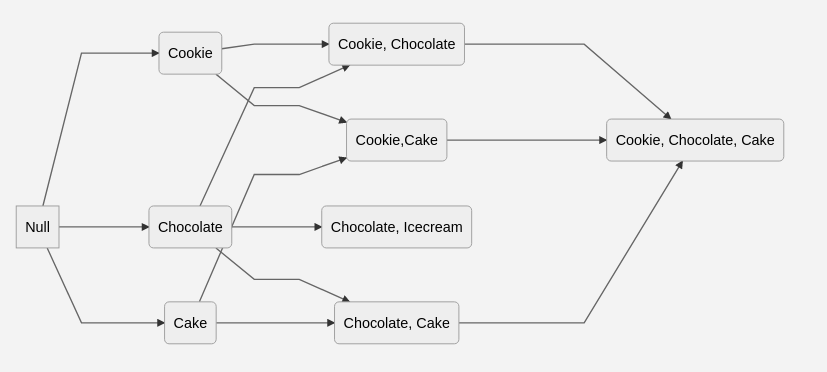
Приведенная ниже диаграмма иллюстрирует то, как алгоритм Apriori начинает построение с наименьшего набора элементов и далее продвигается вперед.
- Алгоритм начинает с генерации набора элементов с помощью шага Join Step, то есть генерации набора элементов (K+1) из наборов элементов K. Например, на первой итерации алгоритм генерирует Cookie (печенье), Chocolate (шоколад) и Cake (торт).
- Сразу после этого алгоритм переходит к шагу обрезки, то есть удаляет любой набор элементов-кандидатов, который не удовлетворяет требованию минимальной поддержки. Например, алгоритм удалит Cake, если Support(Cake) будет ниже заданного минимального значения Support.
Алгоритм повторяет оба шага до тех пор, пока не останется ни одной возможности расширения.
Обратите внимание: эта диаграмма не является полной версией приведенной выше таблицы транзакций. Она служит в качестве иллюстрации, помогающей нарисовать общую картину процесса.
Реализация кода
Для реализации анализа рыночной корзины с помощью алгоритма Apriori мы будем использовать набор данных Groceries с сайта Kaggle. Датасет был опубликован Хиралом Дедхиа в 2020 году с лицензией General Public License, версия 2.
Набор данных содержит 38765 строк заказов на покупку в продуктовых магазинах.

Импорт и чтение данных
Прежде всего, импортируем необходимые модули и прочитаем наборы данных, которые мы загрузили с Kaggle.
Код:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
from mlxtend.preprocessing import TransactionEncoder
from mpl_toolkits.mplot3d import Axes3D
import networkx as nx
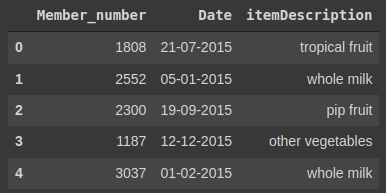
basket = pd.read_csv("Groceries_dataset.csv")
display(basket.head())
Результат:
Группировка по транзакциям
- Набор данных записывает покупки отдельных товаров в строку. Нам необходимо сгруппировать эти покупки по корзинам товаров.
- После этого с помощью TransactionEncoder мы закодируем транзакции в формат, подходящий для функции Apriori.
Код:
basket.itemDescription = basket.itemDescription.transform(lambda x: [x])
basket = basket.groupby(['Member_number','Date']).sum()['itemDescription'].reset_index(drop=True)
encoder = TransactionEncoder()
transactions = pd.DataFrame(encoder.fit(basket).transform(basket), columns=encoder.columns_)
display(transactions.head())
Результат:
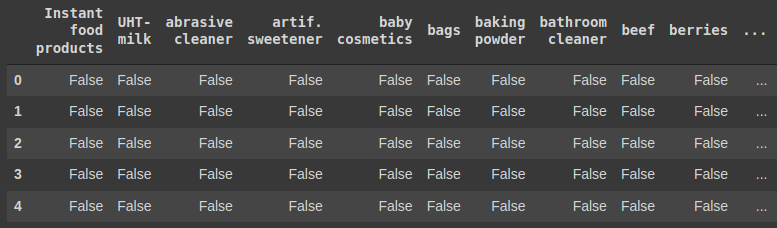
Примечание: датафрейм записывает каждую строку как транзакцию, а товары, которые были куплены в ходе транзакции, будут записаны как True.
Apriori и правила ассоциаций
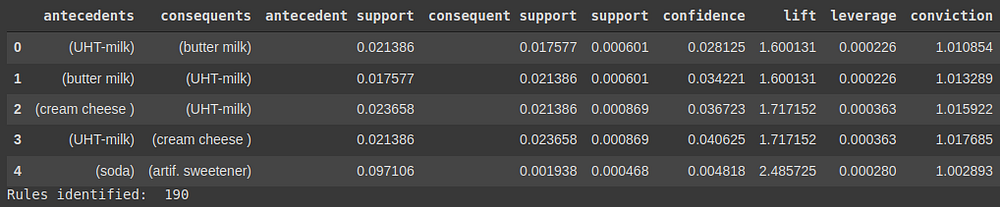
Алгоритм Apriori будет использоваться для генерации частых наборов элементов. Мы зададим минимальную поддержку в размере 6 из общего числа транзакций. Генерируются правила ассоциаций, и мы отфильтровываем значения Lift > 1,5.
Код:
frequent_itemsets = apriori(transactions, min_support= 6/len(basket), use_colnames=True, max_len = 2)
rules = association_rules(frequent_itemsets, metric="lift", min_threshold = 1.5)
display(rules.head())
print("Rules identified: ", len(rules))
Результат:
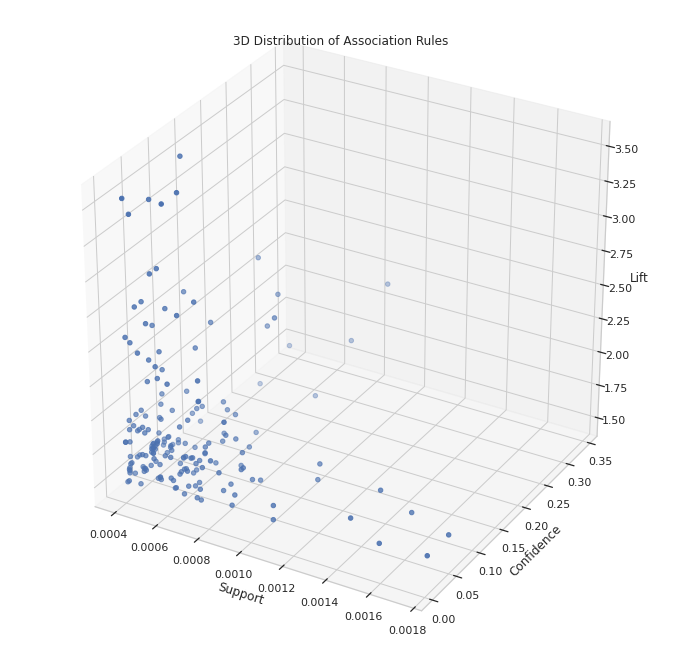
Визуализации
Чтобы визуализировать правила ассоциаций, мы можем изобразить их в виде трехмерной точечной диаграммы. Правила, расположенные ближе к правому верхнему углу, являются наиболее значимыми для дальнейшего изучения.
Код:
sns.set(style = "whitegrid")
fig = plt.figure(figsize=(12, 12))
ax = fig.add_subplot(projection = '3d')
x = rules['support']
y = rules['confidence']
z = rules['lift']
ax.set_xlabel("Support")
ax.set_ylabel("Confidence")
ax.set_zlabel("Lift")
ax.scatter(x, y, z)
ax.set_title("3D Distribution of Association Rules")
plt.show()
Результат:
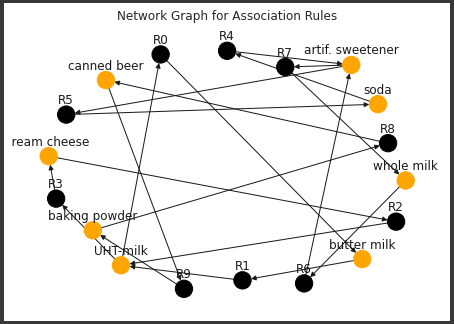
Другой тип визуализации, позволяющий рассмотреть взаимосвязь между продуктами, — это сетевой граф. Давайте определим функцию для построения сетевого графа, в которой можно указать, сколько правил мы хотим показать.
Код:
def draw_network(rules, rules_to_show):
# Ориентированный граф от NetworkX
network = nx.DiGraph()
# Перебор количества правил для отображения
for i in range(rules_to_show):
# Добавление узла правила
network.add_nodes_from(["R"+str(i)])
for antecedents in rules.iloc[i]['antecedents']:
# Добавление узла-предшественника и ссылки на правило
network.add_nodes_from([antecedents])
network.add_edge(antecedents, "R"+str(i), weight = 2)
for consequents in rules.iloc[i]['consequents']
# Добавление узла-последователя и ссылки на правило
network.add_nodes_from([consequents])
network.add_edge("R"+str(i), consequents, weight = 2)
color_map=[]
# Для каждого узла, если это правило, цвет черный, в противном случае - оранжевый.
for node in network:
if re.compile("^[R]\d+$").fullmatch(node) != None:
color_map.append('black')
else:
color_map.append('orange')
# Расположение узлов с помощью spring layout
pos = nx.spring_layout(network, k=16, scale=1)
# Построение сетевого графа
nx.draw(network, pos, node_color = color_map, font_size=8)
# Сдвиг расположения текста вверх
for p in pos:
pos[p][1] += 0.12
nx.draw_networkx_labels(network, pos)
plt.title("Network Graph for Association Rules")
plt.show()
draw_network(rules, 10)
Результат:
Применение алгоритма в бизнесе
Допустим, владельцы магазина закупили слишком много цельного молока и теперь беспокоятся, что товар пропадет, если его не удастся вовремя распродать. Что еще хуже, рентабельность продаж цельного молока настолько низка, что они не могут позволить себе промо-скидку, не потеряв при этом большую часть прибыли.

Один из возможных способов решения проблемы — выяснить, какие продукты стимулируют продажи цельного молока, и предложить скидки на эти товары.
Код:
milk_rules = rules[rules['consequents'].astype(str).str.contains('whole milk')]
milk_rules = milk_rules.sort_values(by=['lift'],ascending = [False]).reset_index(drop = True)
display(milk_rules.head())
Результат:

Например, мы можем установить промо-скидку на бренди, размягчитель, консервированные фрукты, сироп и искусственный подсластитель. Некоторые ассоциации могут показаться контринтуитивными, но правила гласят, что эти продукты действительно стимулируют продажи цельного молока.
Резюме
Применяя алгоритм Apriori и анализируя ассоциативные связи, предприятия могут вывести десятки стратегий, основанных на данных, для повышения доходов и прибыли. Правила ассоциаций имеют решающее значение для анализа покупательского поведения в процессе поиска данных. Некоторые из наиболее важных стратегий розничной торговли, такие как анализ клиентов, анализ рыночной корзины и кластеризация продуктов, способны дать ценные сведения в тандеме с анализом правил ассоциаций.
Спасибо вам за то, что дочитали статью до конца. Надеюсь, она была вам полезна!
Читайте также:
- Как выжать максимум из предобученных языковых моделей с GroupBERT
- Как работает алгоритм YouTube?
- Графы и пути — алгоритм Дейкстры
Читайте нас в Telegram, VK и Дзен
Перевод статьи Yenwee Lim, Data Mining: Market Basket Analysis with Apriori Algorithm





