
Машинное обучение (МО) сейчас в тренде, поэтому неудивительно, что все компании хотят использовать его для улучшения своих продуктов или услуг. Мы наблюдаем растущий спрос на инженеров в сфере машинного обучения, и такой спрос привлекает внимание специалистов. Однако многим МО может показаться слишком сложным, особенно тем, у кого мало опыта работы с кодом или данными.
Одна из вероятных причин страха перед МО заключается в том, что для настройки компьютера, позволяющей разрабатывать модели МО, требуется много усилий. В этой статье я хотел бы рассказать о Google Colab. Это бесплатный инструмент (правда, с возможностью платного обновления) для обучения и построения моделей МО. Он не требует никаких дополнительных настроек — он уже готов к использованию. Единственное требование — наличие учетной записи Google. Если у вас ее нет, вам нужно будет зарегистрироваться в системе, чтобы иметь возможность следовать этому руководству.
Я предполагаю, что вы один из тех, кто не слишком много знает о МО, но очень хочет узнать о нем больше. Не имеет значения, насколько хорошо вы владеете Python. Я буду объяснять основные шаги простым языком, насколько это возможно.
Итак, давайте приступим. Если вы хотите посмотреть исходный код, вы можете получить доступ к блокноту по ссылке.
Шаг 1. Создание блокнота в Colab
В Colab вы будете работать с блокнотами (*.ipynb) так же, как и с документами (*.docx) в Microsoft Word. Итак, первый шаг к использованию Colab — это создание нового блокнота. Для этого перейдите по ссылке: https://colab.research.google.com/.
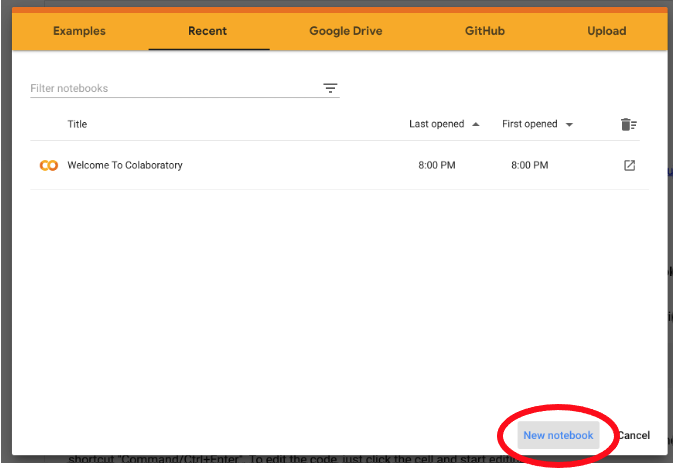
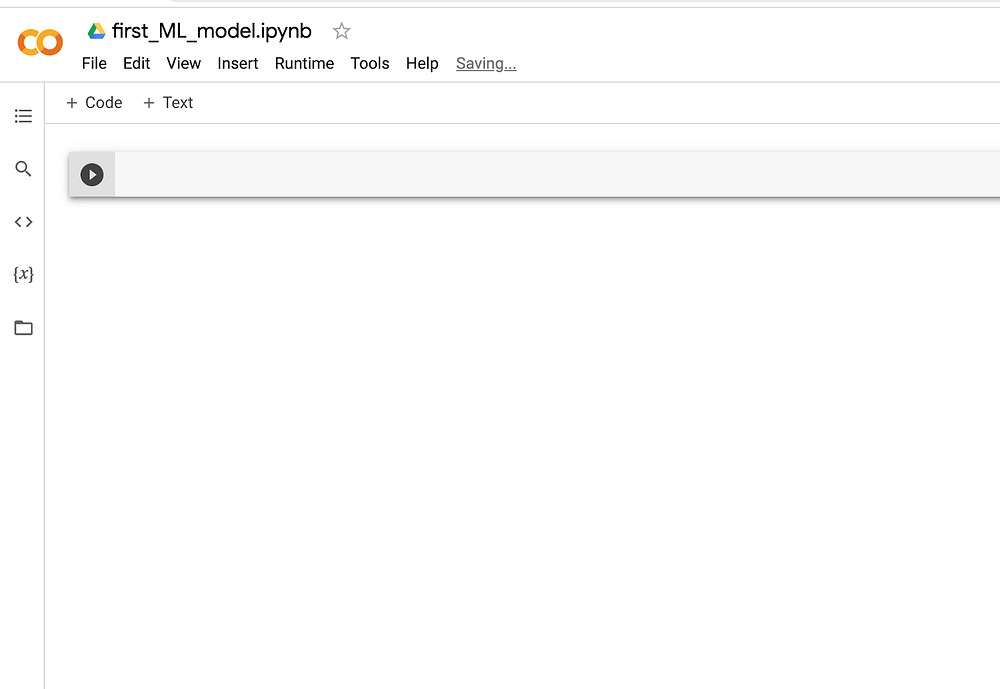
После того, как вы нажмете кнопку “New notebook”, Colab создаст новый блокнот с именем по умолчанию Untitled1.ipynb. В рамках данного туториала назовем его first_ml_model.ipynb.
Шаг 2. Импорт зависимостей
Когда мы строим нашу модель, нам нужны библиотеки кода, разработанные опытными специалистами по машинному обучению. По сути, эти библиотеки служат набором инструментов и предоставляют заранее определенные функциональные возможности для обработки данных и построения модели МО. В рамках нашего туториала мы остановимся на двух основных библиотеках:
- scikit-learn: библиотека МО, состоящая из множества функций обработки данных и алгоритмов МО (например, регрессии, классификации и кластеризации). Эта библиотека также известна под названием “sklearn”. Мы будем использовать sklearn для ссылок.
- pandas: библиотека данных, которая в основном ориентирована на предварительную обработку данных типа электронных таблиц перед построением моделей МО.
В блокноте Google Colab каждая рабочая единица называется ячейкой. Для выполнения наших задач по построению модели МО мы будем использовать серию ячеек. В каждой ячейке мы выполняем определенную задачу. Чтобы добавить ячейку, достаточно нажать кнопку + Codeвверху, как показано ниже. Вы можете оставить примечания к коду, нажав + Text.

После создания кода и запуска следующей ячейки можно импортировать необходимые библиотеки.

Примечание: если вы хотите настроить компьютер под МО, вам нужно установить все эти зависимости в дополнение к настройке Python.
Шаг 3. Рабочий набор данных
Будем использовать набор данных по качеству красного вина. Дополнительную информацию об этом наборе данных можно найти на kaggle.com, популярном сайте, посвященном вопросам дата-сайенс и МО, где проводятся конкурсы по исследованию данных. Вы также можете найти информацию о наборах данных на сайте UCI, который является ведущим репозиторием данных МО.
Датасет wine часто используется в качестве примера для демонстрации моделей МО, поэтому он доступен в sklearn. Обратите внимание: набор данных в sklearn был изменен. Так он может лучше выполнять свою роль пробного набора данных, предназначенного для тренировки и обучения МО. Данные показаны ниже.

На скриншоте выше показаны свойства данных. В МО мы используем “свойства” для изучения факторов, которые могут быть важны для правильного прогнозирования. Как видите, есть 12 свойств, и они потенциально важны для качества красного вина (например, алкоголь и яблочная кислота).
Одна конкретная модель МО занимается классификацией. Каждая запись данных имеет метку, показывающую ее класс, а классы всех записей называются “целью” набора данных. В наборе данных по красному вину есть три класса для меток, и мы можем проверить эти метки, как показано ниже:
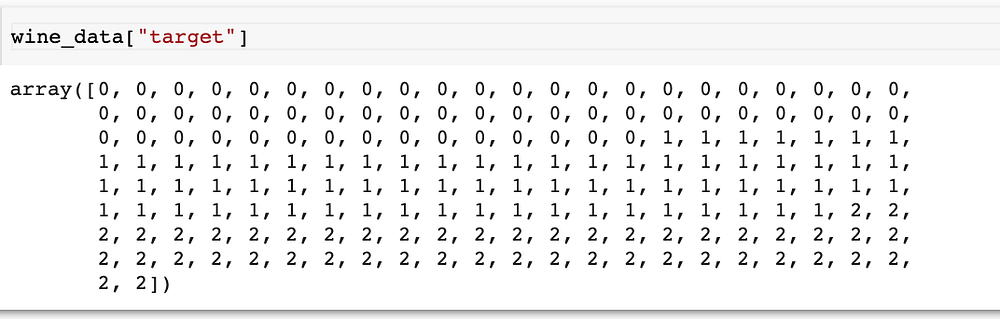
Обратите внимание: в типичном конвейере нам обычно приходится тратить массу времени на подготовку набора данных. Некоторые распространенные виды подготовки включают следующее:
- выявление и удаление/исправление выбросов;
- обработку недостающих данных;
- прямое перепечатывание кода(необходимое для некоторых моделей);
- снижение размерности;
- выбор свойств;
- масштабирование и многое другое.
Поскольку наш набор данных является пробным, он уже очищен в sklearn и нам не нужно тратить время на всю эту подготовку.
Шаг 4. Обучение модели
Следующий шаг — обучение модели МО. Вы можете задать вопрос: а в чем смысл такого обучения? В каждом отдельном случае преследуется своя цель. Общий смысл обучения модели МО заключается в том, чтобы она могла делать точные прогнозы относительно явлений, которые ей незнакомы. Способ создания такой модели называется обучением: существующие данные используются для того, чтобы на их основе модель могла давать правильные прогнозы.
Есть множество различных путей построения моделей МО:
- метод K-ближайших соседей;
- SVC;
- метод случайного леса (random forest);
- градиентный бустинг и другие.
Воспользуемся моделью, которая доступна в sklearn — классификатором случайного леса.
Поскольку у нас есть только один набор данных для проверки производительности модели, мы разделим его на две части. Одна будет предназначена для обучения, а другая — для тестирования. Мы можем просто использовать метод train_test_split, как показано ниже. Набор данных для обучения содержит 142 записи, а тестовый — 36 записей, примерно в соотношении 4:1 (обратите внимание: test_size=0.2означает, что для тестирования используется 20% (с округлением при необходимости) исходного набора данных).

Самое приятное в sklearn то, что он делает за нас тяжелую работу. Sklearn создает множество классификаторов, предварительно настроенных так, что мы можем использовать их с помощью всего нескольких строк кода. На скриншоте ниже показано создание классификатора случайного леса. По сути, он задает нам рамки, в которые мы должны поместить наши данные для построения модели.

С помощью classifier.fit мы обучаем модель и создаем для нее параметры. Подготовленная таким образом модель пригодна для предоставления прогнозов в будущем.
Шаг 5. Прогнозирование
Теперь мы можем проверить обученную модель sklearn на тестовом наборе данных, который мы создали ранее. Как показано ниже, мы получили точность предсказания 97,2%. Следует сказать, что достижение такого высокого уровня в пробном наборе данных не является чем-то из ряда вон выходящим, но в реальных проектах такой показатель считается очень высоким.

Если вы хотите более детально разобраться в составлении прогноза нашей моделью, можете запустить следующий код и получить более полный отчет о работе модели.
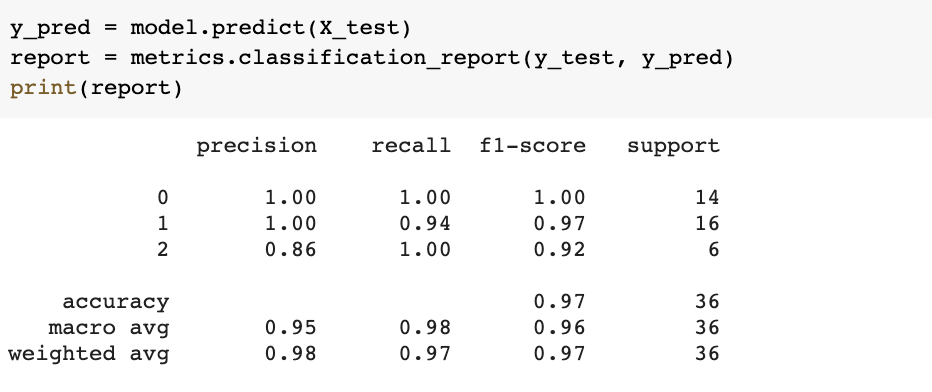
Вы, наверное, заметили, что здесь есть несколько незнакомых вам метрик, таких как precision и recall. Вы можете найти обсуждение этих терминов и моделей классификации здесь:
An Introduction to the ROC-AUC in Classification Tasks | by Yong Cui | Towards Data Science
Заключение
В этой статье я использовал Google Colab в качестве редактора кода, чтобы показать вам, как построить модель МО для прогнозирования на основе тестового набора данных. Возможно, это даже был не поверхностный обзор всех основных концепций МО. Однако, думаю, мне удалось убедить вас в том, что Google Colab — простой в использовании инструмент, требующий минимальных настроек для того, чтобы вы могли начать исследовать основные принципы работы МО.
Когда вы овладеете Google Colab, Python, нужной терминологией и базовыми концепциями, связанными с МО, вы сможете приступить к изучению других IDE Python, таких как PyCharm; это позволит вам приобрести ценный опыт работы с более продвинутыми моделями МО.
Читайте также:
- Как импортировать наборы данных Kaggle в Google Colab?
- Управление файлами в Google Colab
- Различные модели машинного обучения
Читайте нас в Telegram, VK и Дзен
Перевод статьи Yong Cui, Build Your First Machine Learning Model With Zero Configuration
 с использованием PyCaret: основные принципы")




