
Введение
Машинное обучение (МО) — это одна из областей искусственного интеллекта и информатики, которая с помощью данных и алгоритмов имитирует то, как обучается человек, постепенно улучшая точность.
Мы живем в эпоху данных, где все вокруг нас подключено к источнику данных и записывается в цифровом формате. Например, современный электронный мир обладает огромным количеством различных видов данных из таких сфер, как интернет вещей (IoT), кибербезопасность, умный город, бизнес, смартфоны, социальные сети, здравоохранение, COVID-19 и многих других.
Машинное обучение — область исследований, которая влияет и продолжит влиять на наши жизни так же сильно, как и другие технологии. Методы его работы зависят как от самой задачи, так и от используемых для ее решения алгоритмов.
Однако, по своей сути, модель машинного обучения является компьютерной программой, которая просматривает информацию и определяет паттерны (закономерности), а затем использует эти знания для лучшего выполнения поставленной задачи.
Любое задание, которое полагается на набор данных или правил, может быть автоматизировано с помощью машинного обучения, даже такие сложные задачи, как ответ на звонки клиентов и просмотр резюме. В МО применяется четыре основных модели: обучение с учителем, автоматическое обучение, обучение с частичным привлечением учителя и стимулированное обучение (обучение с подкреплением).
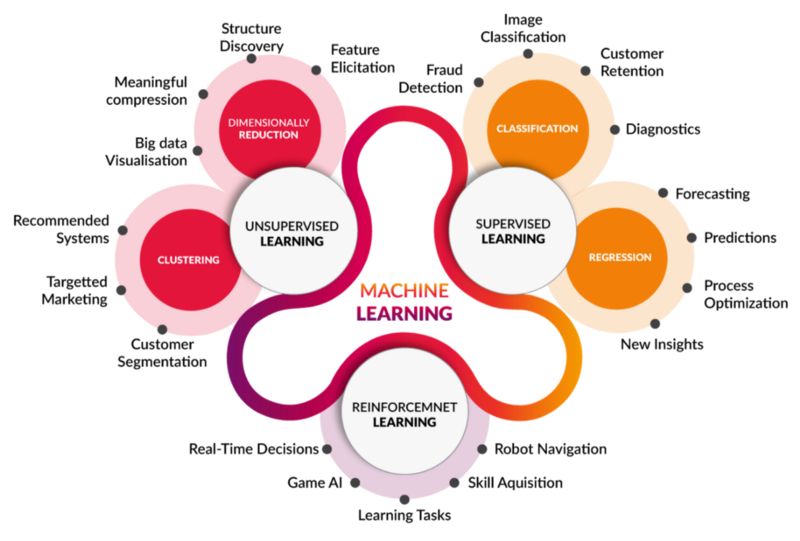
Различные модели с практическими объяснениями
При обучении с учителем (контролируемое обучение) компьютер снабжается набором размеченных данных, что позволяет ему обучаться тому, как выполнять задание, поставленное человеком. Это наименее сложная модель, так как она пытается воссоздать человеческое обучение. Важно помнить, что все алгоритмы контролируемого обучения являются, по сути, сложными алгоритмами, относящимися к категории либо классификационных, либо регрессионных моделей.
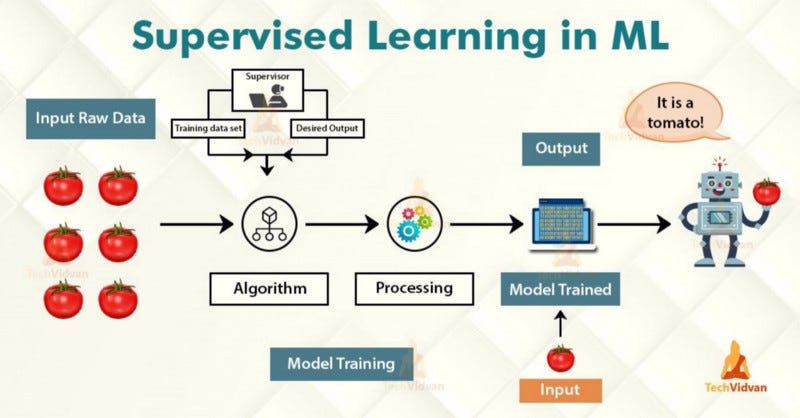
- Классификационные модели основаны на поиске функции, которая помогает разделять набор данных на классы, опираясь на различные параметры. В этом случае компьютерная программа обучается на заранее подготовленном наборе данных и впоследствии на основе выученных параметров относит рассматриваемые данные к разным классам.
- Регрессионные модели. Регрессия — процесс нахождения взаимосвязей между зависимыми и независимыми переменными. Она помогает в прогнозировании непрерывных переменных, таких как тенденции рынка, цены на недвижимость и т. д.
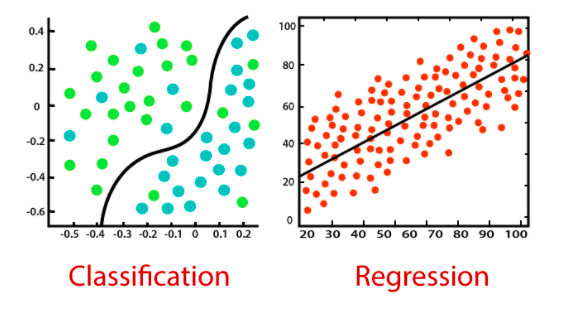
В реальной жизни есть несколько довольно практичных применений алгоритмов контролируемого обучения:
- классификация текстов;
- распознавание лиц;
- распознавание подписей;
- поиск клиентов;
- обнаружение спама;
- прогнозирование погоды.
При автоматическом (неконтролируемом) обучении компьютер снабжается неразмеченными данными и извлекает из них ранее неизвестные закономерности/знания. Машину необходимо запрограммировать для самостоятельного обучения. Компьютер должен понимать и представлять информацию как из структурированных, так и неструктурированных данных.
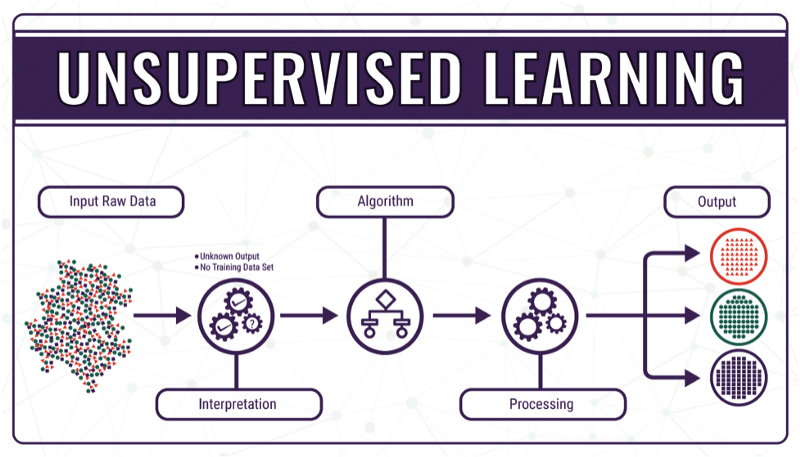
Ниже представлены категории неконтролируемого обучения.
- Кластеризация — один из основных методов обучения без учителя. Он предполагает организацию неразмеченных данных в схожие группы, называемые кластерами. Таким образом, кластер — это совокупность похожих элементов данных.
- Обнаружение отклонений — метод определения редких элементов, событий или наблюдений, которые значительно отличаются от основной массы данных.
На практике алгоритмы неконтролируемого обучения могут применяться для:
- обнаружения мошенничества;
- обнаружения вредоносного ПО;
- определения ошибок при вводе данных;
- проведения точного анализа корзины и т. д.
При обучении с частичным привлечением учителя (полуавтоматическом) компьютер снабжается набором частично размеченных данных, которые в ходе выполнения задачи интерпретируются с помощью размеченных.
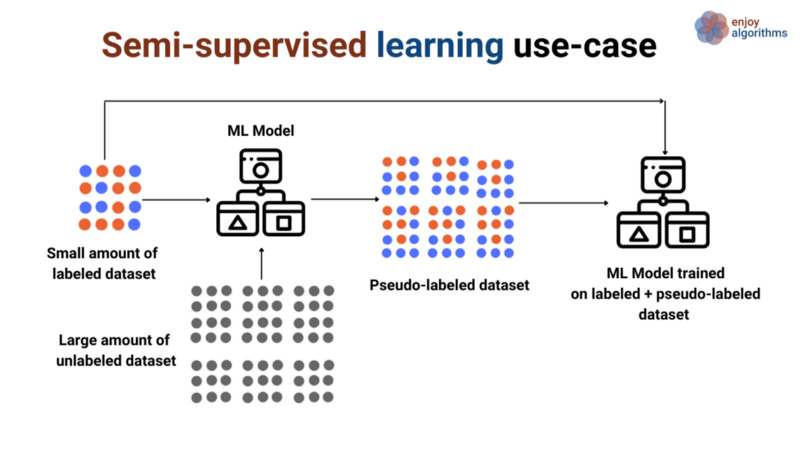
Практическое применение полуавтоматического обучения:
- анализ речи;
- классификация интернет-контента;
- классификация последовательности белка.
При обучение с подкреплением компьютер наблюдает за средой и использует получаемые данные для определения идеального поведения, которое минимизирует риск и/или максимизирует награду. Это итеративный подход, который требует определенного сигнала, помогающего компьютеру выбрать лучшее действие.
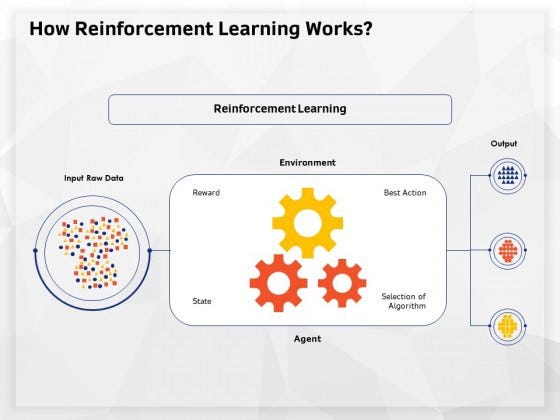
Существует три типа стимулированного обучения.
- Q-обучение — самый важный алгоритм стимулированного обучения, который вычисляет подкрепление для состояний и действий.
- Итерация по стратегиям — вычисляет подкрепление, следуя двум шагам, то есть за оценкой метода идет его усовершенствование. В этом алгоритме стимулированного обучения существует агент и домен с состояниями и действиями.
- Итерация по значениям — вычисляет подкрепление для состояний и действий с помощью сигнала, определенного функцией подкрепления.
Примеры обучения с подкреплением из реальной жизни:
- автоматизированное охлаждение центра обработки данных с помощью Deep RL;
- система персонализированных рекомендаций товаров;
- система рекламных рекомендаций;
- персонализированные рекомендации видео;
- индивидуальные действия в видеоиграх;
- персонализированный ответ чатбота;
- покупка/продажа акций с помощью ИИ.
Читайте также:
- Машинное обучение без данных
- Машинное обучение. С чего начать? Часть 2
- Будущее графических дизайнеров в эпоху машинного обучения
Читайте нас в Telegram, VK и Дзен
Перевод статьи Deepika Yadav: DIFFERENT MACHINE LEARNING MODELS




