
Streamlit — эффективный и оперативный инструмент для анализа текста. С ним можно провести реферирование текста, частеречную разметку и распознавание именованных объектов.
Введение в анализ текста
Текстовая аналитика — это автоматизированный процесс перевода больших объемов неструктурированного текста в количественные данные для выявления идей, тенденций и закономерностей. В сочетании с инструментами визуализации данных этот метод позволяет компаниям понять историю, стоящую за цифрами, и принимать более эффективные решения. Это технология искусственного интеллекта, которая использует обработку естественного языка для преобразования неструктурированного текста в документах и базах данных в нормализованные структурированные данные, пригодные для анализа или управления алгоритмами машинного обучения.
Зачем нужно автоматизировать процесс анализа текста
Каждый, кто занимается обработкой естественного языка, знает: анализ текста — самый важный шаг перед принятием любого решения в машинном обучении. Зачастую написание всего кода может занять много времени. Вот почему так важно иметь возможность ускорить этот процесс.
Создание приложения для автоматического анализа текста имеет существенные преимущества:
- избавляет от выполнения конвейерной обработки для визуализации данных, предшествующей моделированию;
- сокращает время между исследовательским анализом данных и построением модели.
Вот почему я решил создать приложение для автоматического анализа текста с использованием Streamlit.
Приложение для анализа текста
В моем приложении есть множество инструментов для визуализации и анализа данных. Важным его аспектом является пользовательский интерфейс. Он предлагает несколько инструментов на выбор, используя выпадающий слева список.
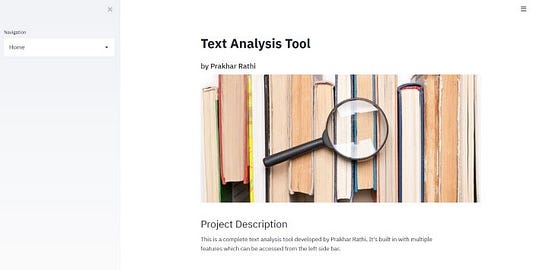
Вы можете найти код приложения здесь.
Требования
Для запуска этого приложения понадобится ряд библиотек. Они перечислены здесь.
Инструменты, к которым можно получить доступ из приложения
В это приложение встроено множество инструментов. Вы можете разместить их все в раскрывающемся списке, подобном этому:
import streamlit as st
# Опции боковой панели
option = st.sidebar.selectbox('Navigation',
["Главная",
"Классификатор спама по Email",
"Анализ тональности высказываний по ключевым словам",
"Облако тегов",
"N-граммный анализ",
"Частеречный анализ",
"Распознавание именованных объектов",
"Реферирование текса"])
st.set_option('deprecation.showfileUploaderEncoding', False)1. Генератор облака тегов ☁️
Генерация облака тегов — метод визуализации данных, который является неотъемлемым аспектом текстовой аналитики. Это представление текста, в котором отображаются слова разных размеров в зависимости от того, как часто они появляются в определенном корпусе. Слова с более высокой частотой употребления выделены более крупным шрифтом. Они выделяются на фоне слов с более низкими показателями частотности. Необходимым условием для выполнения этой задачи является набор функций очистки и обработки текста.
Я интегрировал эти функции как часть инструмента, который запускается, как только текст добавляется в приложение. Кроме этого, я добавил функцию маскировки. Она определяет форму вывода облака тегов на основе изображения, предоставленного генератору.
if option == 'Home':
st.write(
"""
## Описание проекта
Это завершенный инструмент анализа текста, разработанный Пракхаром Рати. Он встроен с множеством функций, к которым можно получить доступ
с левой боковой панели.
"""
)
# Функция облака тегов
elif option == "Word Cloud":
st.header("Generate Word Cloud")
st.subheader("Generate a word cloud from text containing the most popular words in the text.")
# Запросить текст или текстовый файл
st.header('Enter text or upload file')
text = st.text_area('Type Something', height=400)
# Загрузить изображение маски
mask = st.file_uploader('Use Image Mask', type = ['jpg'])
# Добавить функцию кнопки
if st.button("Generate Wordcloud"):
# Создать облако тегов
st.write(len(text))
nlp.create_wordcloud(text, mask) # created in a custom module imported as nlp
st.pyplot()Функция create_wordcloud была создана в другом файле, ее можно найти здесь.
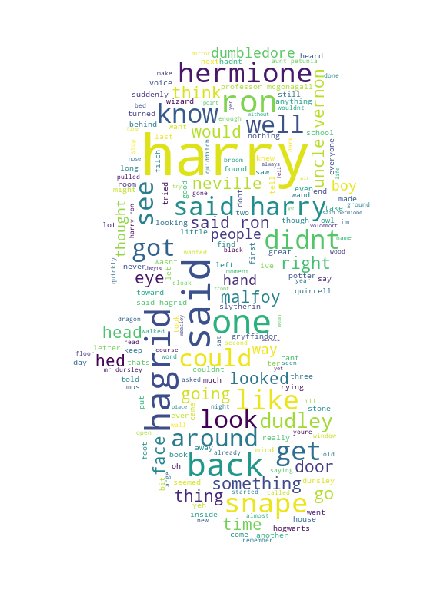
2. N-граммный анализ
N-грамма — это непрерывная группа N последовательных элементов из заданного образца текста или речи. Элементы могут быть фонемами, слогами, буквами, словами или парами оснований в зависимости от типа приложения. N-граммные группы обычно собираются из текстового или речевого корпуса.
В этом анализе я пытаюсь определить наиболее часто встречающиеся N-граммные группы. В то время как облако тегов фокусируется на отдельных словах, N-граммный анализ может выделить несколько фраз вместо одной. Он используется для анализа стиля письма человека, чтобы увидеть, как часто он повторяет те или иные речевые конструкции и какие закономерности встречаются в его письме.
N-граммный анализ реализован аналогично генератору облака тегов, поэтому я не буду повторяться (код можно найти здесь, а выходные данные здесь).
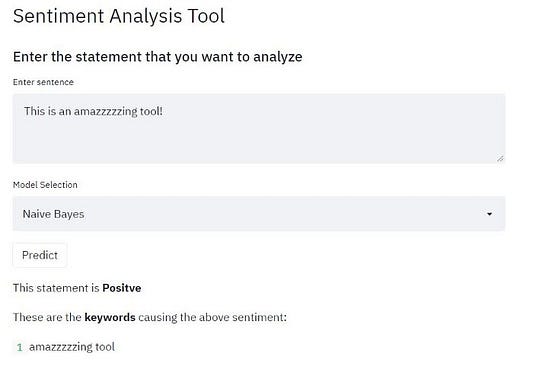
3. Анализ тональности высказываний по ключевым словам
Эта задача состоит из двух частей. Первая заключается в извлечении эмоции, которая выявляет тон высказывания — положительный или отрицательный. Второй этап: определение ключевого слова, которое вызывает эту эмоцию. Выделение ключевых слов происходит на основе анализа их вклада в итоговое значение выражения.
Набор данных. Сначала модели были обучены на большом корпусе, что сделало их более надежными и обобщенными. Данные были собраны с помощью скрейпинг-программы, которую я создал для извлечения отзывов пользователей магазина Google Play. Путем скрейпинга собрал примерно 12 500 отзывов. Реализацию скрейпинг-программы можно найти в папке Notebooks под названием sentiment_analysis_data_collection.ipynb.
Код для выполнения анализа тональности высказываний можно найти здесь.
5. Текстовое реферирование
Учитывая большой объем данных, нам необходимо обобщить их в краткой сводке. Она должна охватывать ключевые моменты и максимально точно передавать смысл исходного документа. Я создал инструмент текстового реферирования, который извлекает слова, фразы и предложения из исходной сводки, выбирая наиболее важные предложения в данном тексте.
Существуют различные методы оценки наиболее важных предложений в большом тексте. Количество предложений рассчитывается с использованием коэффициента сжатия.
Количество предложений = η * Общее количество предложений,
где η — коэффициент сжатия, выражающийся числами от 0 до 1. Я применял различные типы алгоритма текстового ранжирования, который строит граф на основе текста. В графе каждое предложение рассматривается как вершина, а каждая вершина связана с другой вершиной. Эти вершины голосуют за другую вершину. Важность каждой вершины определяется большим количеством голосов.
Алгоритмы, которые я использовал, можно найти в папкеText_Summarization.ipynb. Код для реферирования в Streamlit ищите здесь.
6. Частеречная разметка
В традиционной грамматике часть речи — это категория слов, которая обладает одинаковыми грамматическими свойствами и схожим синтаксическим поведением. Знание частей речи полезно, поскольку дает представление не только о конкретном слове, но и о его соседях. В зависимости от того, с какой частью речи мы имеем дело — существительным или глаголом, — можно определить его вероятное лексическое окружение.
Действие по присвоению словам меток частей речи в корпусе известно как частеречная разметка. Я выполнял ее на основе набора тегов Penn-Treebank. Это набор из 45 тегов, который использовался для частеречной разметки многих корпусов.
Реализацию можно найти в папке text_analysis.ipynb. Результаты в приложении представлены ниже.

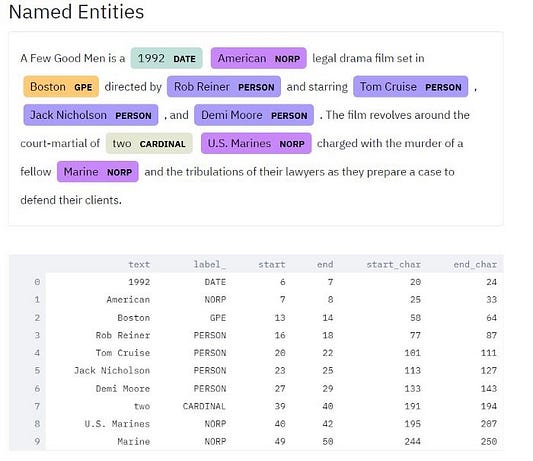
7. Распознавание именованных объектов
Распознавание именованных объектов (NER) является очень важным аспектом извлечения информации, которая в дальнейшем используется в графах знаний, чат-ботах и многих других реализациях. Задача включает в себя классификацию текста по заранее определенным категориям, таким как:
- имена людей;
- организации;
- локации;
- временные выражения;
- количества;
- денежные ценности и т. д.
Для этого я использую библиотеку SpaCy, которая выполняет аннотацию именованных объектов. Я добавил в приложение поле выбора, в котором можно выделить, какие именованные сущности нужно отображать.
Модель распознавания именованных сущностей SpaCy была обучена на корпусе OntoNotes5. Как только пользователь вводит предложение, оно разбивается на лексемы, тегируется и затем добавляется в функцию NER, которая помогает в выборе и визуализации различных объектов. Результат можно увидеть ниже.
Код как для частеречной разметки, так и для распознавания именованных объектов можно найти здесь.
Цель этой статьи не в том, чтобы предоставить вам весь код приложения. Оно довольно объемно и многоаспектно. Вы можете свободно исследовать репозиторий и возможности Streamlit самостоятельно. Статья предназначена для ознакомления со Streamlit как инструментом текстового анализа, который можно успешно использовать в МО.
Читайте также:
- Streamlit для создания интерактивных веб-приложений: начало
- Реализация архитектуры с сохранением состояния в Streamlit
- Быстрая сборка и развертывание дашборда со Streamlit
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Prakhar Rathi: Automated Text Analysis using Streamlit





