
Streamlit
Streamlit прошел долгий путь становления с момента своего создания в октябре 2019 года. Он не только предоставил разработчикам ПО новые возможности, но и обеспечил большую свободу при создании и развертывании приложений в облачной среде. Однако с появлением новых инструментов открываются и новые перспективы развития, и пока команда Streamlit неустанно работает, стараясь удовлетворить запросы о дополнительных функциональных возможностях, сами разработчики способны восполнить их недостаток за счет оригинальных решений.
На данный момент в Streamlit отсутствует возможность реализации для приложений программируемого состояния. В его текущей версии нет внутреннего состояния, которое могло бы сохранять такие постоянно меняющиеся данные, как пользовательский ввод, датафреймы и определяемые в виджетах значения. Учитывая, что Streamlit изначально перезапускает весь скрипт, когда пользователь нажимает на кнопку или переключается между страницами при выполнении действия, приложение сбрасывает все входные данные и датафреймы. Для одних приложений это обстоятельство особой роли не играет, но для других может стать неблагоприятным фактором, нарушающим их работу. Если вы собираете приложение с последовательной логикой, используя инкрементную стратегию разработки, то отсутствие архитектуры, сохраняющей состояние, сделает Streamlit непригодным для ваших целей. И пока основатели фреймворка выполняют свое обещание в ближайшем будущем выпустить версию с сохранением состояния, мы попробуем самостоятельно решить эту проблему, используя такую базу данных с открытым исходным кодом, как PostgreSQL.
PostgreSQL
PostgreSQL, сокращенно Postgres, является свободной реляционной системой управления БД, которую благодаря простоте использования и широкому спектру возможностей чаще всего выбирает большинство разработчиков. Формально она является структурированной, но при этом также обладает способностью хранить неструктурированные данные, такие как массивы и бинарные объекты, что позволяет использовать ее в открытых проектах. Более того, ее графический пользовательский интерфейс настолько понятный и простой, что вы очень быстро его освоите.
В нашей реализации архитектуры с сохранением состояния локальный сервер Postgres будет использоваться для хранения переменных состояния, таких как пользовательский ввод и датафреймы, создаваемых в приложении Streamlit. Для начала загрузите и установите Postgres через эту ссылку. В процессе установки вам предложат придумать имя пользователя и пароль и указать локальный порт TCP для получения данных с сервера БД. Номер порта по умолчанию — 5432, его можно оставить неизменным. Завершив установку, авторизуйтесь на вашем сервере, запустив приложение pgAdmin 4, которое откроет портал сервера в браузере, как показано ниже:
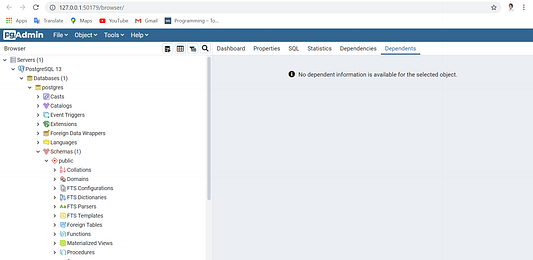
По умолчанию на левой боковой панели появится БД с именем Postgres. Если этого не произошло, кликните по Databases и выберите Create для создания новой БД.
Реализация
Итак, подготовительный процесс завершен, пора переходить к Python для запланированной реализации. Помимо Pandas и Streamlit, потребуется загрузить ряд пакетов.
Psycopg2
Этот пакет позволит подключиться к базе данных Postgres. Загрузите его, используя следующую команду в Anaconda Prompt.
pip install psycopg2
Sqlalchemy
Sqlalchemy используется для создания SQL-запросов, причем весьма упрощает написание сложных. Если вы передаете строки запросов в качестве параметров (без конкатенации), то он способен противостоять атакам внедрения SQL-кода, что гарантирует безопасность запросов. Для загрузки пакета используйте следующую команду:
pip install sqlalchemy
Дополнительно потребуется импорт метода с именем get_report_ctx из библиотеки Streamlit. Эта функция создает уникальный ID сеанса при каждом запуске и обновлении приложения. Данный идентификатор будет ассоциирован с каждой из актуальных переменных состояния, гарантируя извлечение из Postgres только верных.
Далее импортируйте в скрипт Python следующие пакеты:
import streamlit as st
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
from streamlit.report_thread import get_report_ctxСначала создадим функцию, извлекающую ID сеанса нашего экземпляра приложения. Обратите внимание, что ID обновляется одновременно с самим приложением, т. е. при нажатии F5. Поскольку он будет использоваться как имя таблицы, хранящей переменные состояния, то необходимо придерживаться соглашения об именовании, согласно которому имена должны начинаться с нижних подчеркиваний или букв (но не чисел), не содержать тире и включать не более 64 символов.
def get_session_id():
session_id = get_report_ctx().session_id
session_id = session_id.replace('-','_')
session_id = '_id_' + session_id
return session_idДалее нам предстоит создать 4 функции для считывания и записи состояний пользовательского ввода и датафреймов из Streamlit в Postgres следующим образом:
def write_state(column,value,engine,session_id):
engine.execute("UPDATE %s SET %s='%s'" %(session_id,column,value))
def write_state_df(df,engine,session_id):
df.to_sql('%s' % (session_id),engine,index=False,if_exists='replace',chunksize=1000)
def read_state(column,engine,session_id):
state_var = engine.execute("SELECT %s FROM %s" % (column,session_id))
state_var = state_var.first()[0]
return state_var
def read_state_df(engine,session_id):
try:
df = pd.read_sql_table(session_id,con=engine)
except:
df = pd.DataFrame([])
return dfТеперь создадим главную функцию нашего двухстраничного приложения Streamlit. Прежде всего настраиваем клиент PostgreSQL, используя строку подключения, содержащую имя пользователя, пароль и имя БД. Обратите внимание, что для большей безопасности лучше сохранить учетные данные в конфигурационном файле и затем активировать их в качестве параметров в коде. После этого нам потребуется ID сеанса, который будет выглядеть примерно так:
_id_bd3d996d_d887_4ce6_b27d_6b5a85778e60
Вслед за этим, используя текущий ID сеанса, создадим таблицу, состоящую из одного столбца ‘size’ (размер) с типом данных ‘text’ (текст). Необходимо убедиться, что каждый раз при обновлении переменной состояния она перезаписывается поверх предыдущего состояния. Для этого запросим длину таблицы, и если она равняется 0, то вставим новую строку с состоянием. В противном случае просто обновим имеющуюся строку, если предыдущее состояние из текущего ID сеанса уже существует.
Наконец, через st.selectbox на боковой панели, создадим 2 страницы, между которыми можно переключаться. Первая из них содержит текст ‘Hello world’, а вторая — виджет для текстового ввода с целью создания разреженной матрицы соответствующего размера, устанавливаемого пользователем. Состояние текстового ввода и созданного датафрейма сохраняется в нашей базе данных Postgres и каждый раз при перезапуске скрипта запрашивается самим Streamlit. Если скрипт найдет существующее состояние в рамках того же ID сеанса, он соответствующим образом обновит текстовый ввод и датафрейм.
if __name__ == '__main__':
#Создание клиента PostgreSQL
engine = create_engine('postgresql://<username>:<password>@localhost:5432/<database name>')
#Получение ID сеанса
session_id = get_session_id()
#Создание таблиц состояния сеанса
engine.execute("CREATE TABLE IF NOT EXISTS %s (size text)" % (session_id))
len_table = engine.execute("SELECT COUNT(*) FROM %s" % (session_id));
len_table = len_table.first()[0]
if len_table == 0:
engine.execute("INSERT INTO %s (size) VALUES ('1')" % (session_id));
#Создание страниц
page = st.sidebar.selectbox('Select page:',('Page One','Page Two'))
if page == 'Page One':
st.write('Hello world')
elif page == 'Page Two':
size = st.text_input('Matrix size',read_state('size',engine,session_id))
write_state('size',size,engine,session_id)
size = int(read_state('size',engine,session_id))
if st.button('Click'):
data = [[0 for (size) in range((size))] for y in range((size))]
df = pd.DataFrame(data)
write_state_df(df,engine,session_id + '_df')
if read_state_df(engine,session_id + '_df').empty is False:
df = read_state_df(engine,session_id + '_df')
st.write(df)Результаты
Привычное выполнение приложения с реализацией без сохранения состояния сбрасывает текстовый ввод и датафрейм при каждом переключении страниц, как показано ниже:
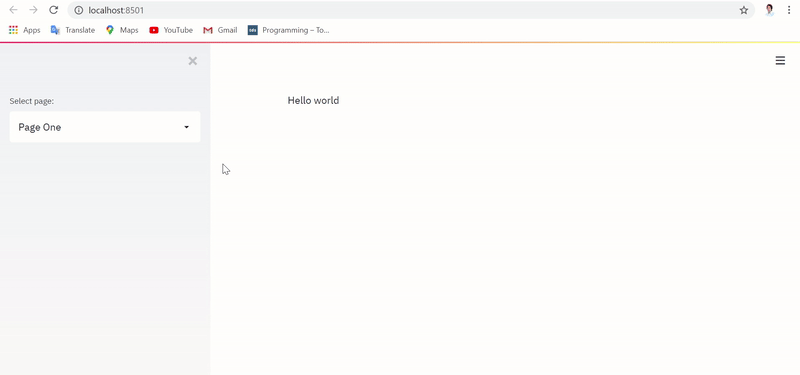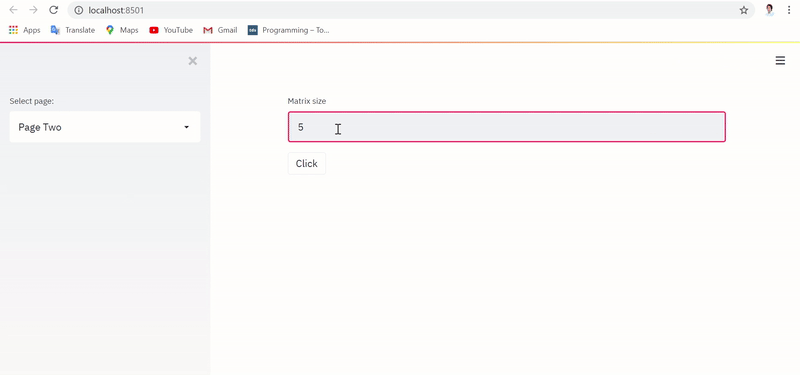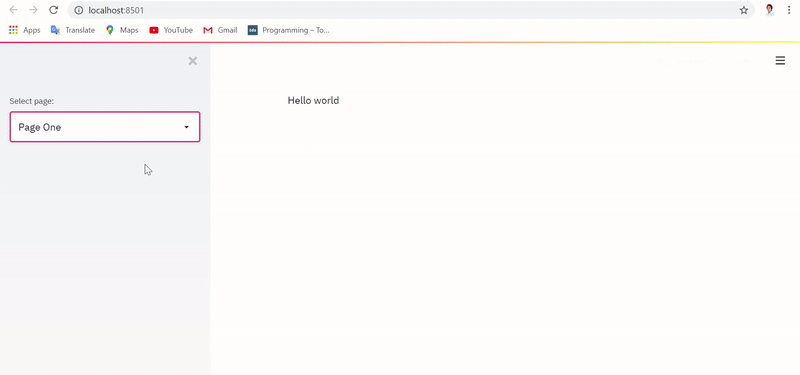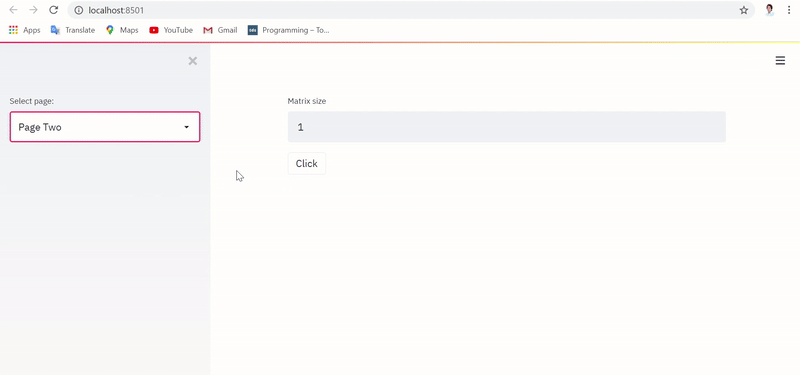
Однако при выполнении приложения с реализацией, фиксирующей состояние, текстовый ввод и датафрейм сохраняются и извлекаются даже при переключении между страницами, в чем можно убедиться ниже:
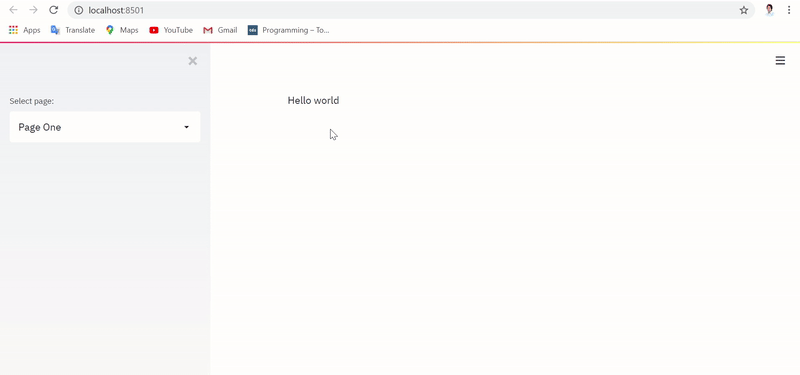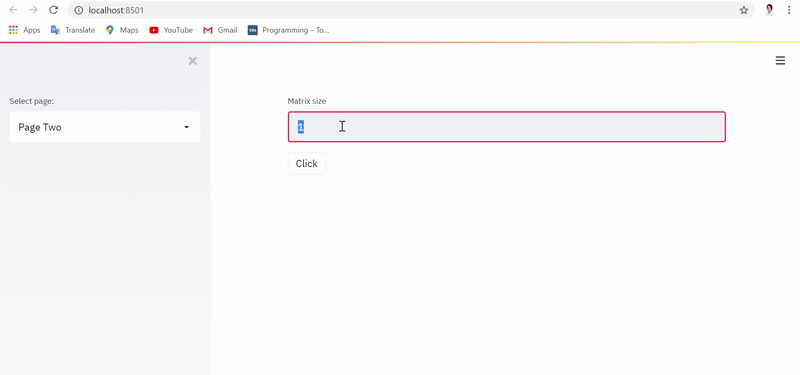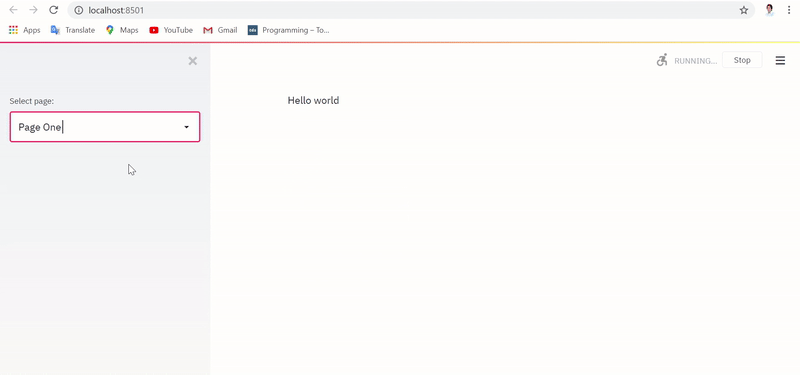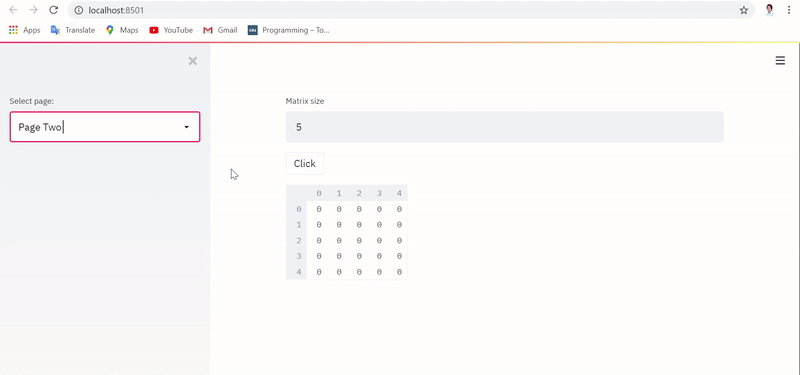
При этом БД Postgres обновляется в режиме реального времени с учетом сохраненных переменной состояния и датафрейма, как показано ниже:
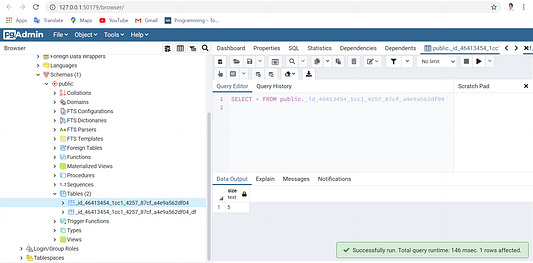
Состояние любой переменной можно сохранить и считать с помощью следующих команд:
write_state('column name', value, connection string, session ID)
read_state('column name', connection string, session ID)Подобным образом сохраняется и считывается любой датафрейм. Для этих целей используются следующие команды:
write_state_df(dataframe, connection string, session ID)
read_state_df(connection string, session ID)Заключение
Рассмотренный метод можно расширить и на другие виджеты, а также использовать его для сохранения бинарных файлов, создаваемых или загружаемых в Streamlit. Кроме того, если вдруг потребуется отследить пользовательский ввод или зафиксировать время каждого действия, то можно подумать о дальнейшей доработке метода для получения таких функциональных возможностей. Однако имейте в виду, что не у всех виджетов в Streamlit есть значения, которые можно сохранить, например функция st.button служит только как триггер события и не имеет связанного с ней значения, которое можно было бы сохранить.
Читайте также:
- Настоящие беспилотные такси выезжают на улицы города
- Алгоритм Рабина-Карпа с полиномиальным хешем и модульной арифметикой
- Что нужно знать, чтобы начать заниматься квантовыми вычислениями
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи M Khorasani: Implementing a stateful architecture with Streamlit





