
Мы живем в золотой век Data-ориентированных организаций. Алгоритмы! Большие Данные! У вас вероятно, даже есть Data Scientist в штате или два! Но …
Если ваши Data-специалисты тратят большую часть своего времени на простую арифметику сложных бизнес-концепций, то вы слишком щедро называете это Data Science . Это просто бизнес-аналитика. Так чем занимается ваша команда?
Честно говоря, скорее всего что-то среднее. Различие не имеет значения. Академическая строгость бесполезна, если она не влияет на результаты бизнеса. С другой стороны, важно то, что многое из того, что они делают, вероятно, не имеет научной или деловой ценности. И это, не связано с их компетентностью в сложной математике. Знаете, кто на самом деле не дает им раскрыться?

Это Вы. Руководитель рабочей группы. Человек с кое-как сформулированным планом. Опирающийся на случайно выбранные цифры, которые только вводят в заблуждение. «Да, но это не про меня!» Вот как Вы выглядите со своим дашбордом:
Окей, я перегибаю с этими отсылками на поп-культуру. Дело в том, что вы, вероятно, недооценили, как трудно использовать данные, не совершая катастрофических аналитических ошибок.
Как инженер с плохим продукт-менеджером, ваша команда будет настроена на провал, до тех пор, пока Вы, владелец бизнеса не настроите их на успех. Не будь мошенником, будь настоящим «человеком чисел».
8 довольно простых интуитивных стратегий, которые помогут избежать самых опасных ошибок.
Рассказ о Зомби-эксперименте
Нашу первую стратегию объясню в формате истории:
1) А стоит ли вообще делать анализ
Это кажется очевидным, но по моему опыту, это наиболее частая ошибка. Она подкрадывается незаметно. Со мной такое бывало, я покажу вам, как её распознать. Это правдивая история о том, как я все испортил, и почему.

В качестве администратора CRM, я помогал масштабировать группу поддержки, которая должна, была обрабатывать более 22 000 потоков через нашу CRM в течение 3 лет. При закрытии кейса агенты отмечали его тэгами. Суть в том, что по крайней мере один тег был необходим. Менеджеры создали эту необходимость, особо не беспокоясь по поводу операционных затрат. И я написал код для реализации этого в нашей CRM. К черту операционные затраты. Мы будем Data-ориентированной организацией.
Каковы были операционные затраты? За три года люди пометили тегами примерно 22 000 таких потоков. По скромным расчетам, чтобы поставить тег в кейсе нужно 5 секунд, (вероятно, требовалось больше) следовательно, процесс занял примерно 30 часов ввода данных. Это может показаться не так много, но представьте, что кто-то сидит и занимается этим в течение целой недели, только созданием этих данных. Мы сделали это, а что менеджеры почерпнули из этой дорогостоящей попытки?
Никто никогда не проверял этот отчет. Откуда мне знать? Если бы они сделали это, хотя бы раз, они увидели бы довольно типичный шаблон данных:
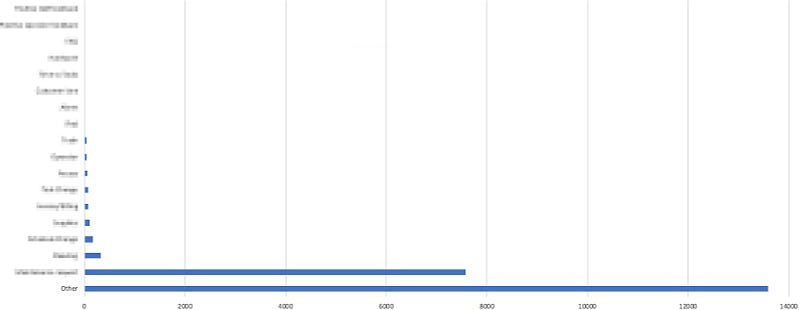
Наша главная проблема в …
… ‘Other’ (Другое).
Если быть честными, разговоры трудно разделить на категории! А если не очень, то наши агенты не увидели суть. Но давайте пойдем еще дальше. Представим себе систему идеальных меток, свободную от путаницы и апатии агентов.
Проще всего просто исключить тег ‘Other’. Что мы видим в оставшемся списке? То, что наша вторая по частоте разновидность проблемы все ещеполностью затмевает все остальные. Вам не важно знать, что это было. Но для нас это была очевидная, дурацкая проблема, над которой уже работала большая часть компании. Ничего такого о чём мы ещё не знали.
Итак, давайте продолжим читать таблицу. После наших первых двух бесполезных тегов, на которые приходилось 90% данных, возможно, мы могли бы найти что-то ценное в длинном хвосте. В этом хвосте было 5 или около того в основном неудивительных тегов, которые периодически возникали. А остальные теги (например, проблемы с нашим мобильным приложением) были довольно редкими. Все то что агент мог бы рассказать нам и так. Если бы цифры были более равномерно распределены, возможно, мы могли бы тщательно изучить их рейтинг (например, если бы проблемы с мобильными приложениями были выше, чем ожидалось). Но данные были настолько скомканы, что были бесполезны.
Зачастую данные, в реальности гораздо менее интересны, чем результаты, которые вы себе представляете
Сбор данных был пустой тратой сил. Не только 30 часов, которые коллектив потратил на теги. Но и весь умственный труд, связанные с этим процессом™. Обучение агентов. Изменение таксономии. Обработка данных. Упущенная выгода.
Часто «работа с цифрами» не стоит потраченного времени, особенно если его требуется много. Итак, на что же я должен был обратить внимание с самого начала, чтобы заметить это?
Очевидно, я стремился «Обучать» исходя из анализа и сдавался, если учить нечему. Но, помимо этого, была еще более важная стратегия, которую мы упустили: не было никакой «Задачи», которую мы намеревались решить.
Как оператор, я абсолютно ненавижу процесс без цели
Больше данных лучше, чем меньше данных*, но данные часто обходятся дороже, чем вы думаете. Легкомысленно делегируя обработку данных (зачастую вашей Data-команде или младшим сотрудникам) вы ступаете на опасную территорию. Всегда:
1 Ставьте Задачу, которую вы намерены решить.
2 Усилия, потраченные на «Обучение», должны быть соразмерны задаче.
Подведем итоги в рамках этой истории:
Задача: её нет. Мы не делали этот анализ, чтобы решить конкретную задачу или запланированные на будущее задачи. Надежды получить пользу так и не оправдались.
Метод: поставить тег в каждый клиентский кейс с MECE таксономией
Вывод: «Нет. Мы не искали его. Если бы искали, мы бы узнали только очевидные вещи. Мы могли бы узнать больше от агентов».

Проблема: очевидно, проблема с этим примером заключалась в том, что у нас не было задачи найти решение или сделать какие-то выводы.
*Всегда ли больше данных лучше, чем меньше? Может ли анализ быть испорчен до того, как data-специалисты даже прикоснутся к нему? Даже с четкими целями, найти решения, талантливые математики могут потерпеть неудачу. Вот семь других примеров (в таком же формате историй), на которые следует обратить внимание:
Во второй части продолжим разбирать рабочие примеры из жизни Data Scientist’а, о неправильно подобранных методах и заблуждениях в выводах. Еще 7 советов которые помогут избегать ошибок и выдавать более точные результаты исследований.
Перевод статьи Michael Muse: 8 Ways To Set Up A Data Team for Success





