
Недавно мне потребовалось постоянно где-то хранить большие графовые данные, и я занялся поисками распределённой графовой базы данных с открытым исходным кодом. Главным требованием было обеспечение как можно большего контроля над системой хранения и индексирования данных, лежащей в основе такой базы данных.
Я наткнулся на JanusGraph, проект графовой базы данных под Linux Foundation, построенный на Apache TinkerPop, с языком запросов Gremlin. Помимо этого проекта, Tinkerpop обеспечивает функционирование и множества других графовых баз данных, таких как neo4j, Amazon Neptune, DataStax, Azure Cosmos DB и т. д. Я отдал предпочтение JanusGraph из-за применяемой здесь технологии plug-and-play. Тут можно заменить внутреннее хранилище, такое как Cassandra, HBase, BerkeleyDB, ScyllaDB или Google Cloud Bigtable, и ПО для индексирования, например Elasticsearch, Solr или Lucene. Не могу судить о всех графовых базах данных и о том, как JanusGraph показывает себя в сравнении с другими решениями. Моей целью было понять, как работает технология, лежащая в основе этой БД, а уж потом можно будет замахнуться и на другие.
По причине такой настраиваемости графовой базы данных JanusGraph её изучение может показаться вначале, по крайней мере для новичков, сложноватым. Чтобы развеять все страхи, я и решил написать эту статью, в которой постарался вкратце изложить свой опыт и провести вас через все этапы, необходимые для развёртывания JanusGraph на удалённом сервере, выполнения запросов и визуализации набора данных.
Настройка на стороне сервера
Развёртывание JanusGraph на сервере состоит из следующих этапов.
Настраиваем сервер. Мой выбор пал на дешёвую виртуальную машину от одного из облачных провайдеров (25 ГБ SSD + 1024 МБ оперативной памяти с Ubuntu 18.04). JanusGraph по умолчанию работает на порте 8182, поэтому я сделал для этого порта открытый доступ. Для простоты (внимание: не самый безопасный способ) я делаю это через iptables:
iptables -A INPUT -p tcp -m tcp --dport 8182 -j ACCEPT
Записываем IP-адрес сервера как ${SERVER_IP_ADDRESS}. Это можно сделать, выполнив следующую команду:
ifconfig
Добавляем и запускаем janusgraph в docker. JanusGraph обеспечивает контейнеризованную реализацию своей системы. Здесь по умолчанию в качестве хранилища используется BerkeleyDB, а в качестве индекса — Lucene. Приведённый ниже код извлечёт последний образ janusgraph из репозитория docker:
docker run -it -p 8182:8182 janusgraph/janusgraph
Копируем набор данных графа в контейнер docker. JanusGraph работает с несколькими форматами данных, один из которых называется graphml. С точки зрения внутреннего устройства, они фактически представляют собой матрицу или список смежности. Для нашего эксперимента будем использовать набор данных маршрутов между аэропортами из этого руководства по Gremlin с сайта kelvinlawrence.net. Набор данных air-routes.graphml можно загрузить отсюда. Нужно скопировать данные graphml в контейнер janusgraph (/opt/janusgraph/data/), чтобы потом их можно было загрузить в JanusGraph командами от клиента. ${JANUSGRAPH_DOCKER_ID} можно получить, запустив docker ps:
docker cp ${YOUR_CUSTOM_LOCATION}/air-routes.graphml ${JANUSGRAPH_DOCKER_ID}:/opt/janusgraph/data/.
Настройки на стороне клиента
Для подключения к серверу будем использовать три метода: консоль gremlin, gremlin python и graphexp.
Консоль gremlin
Загрузим набор данных в JanusGraph с помощью специальной консоли gremlin из версии JanusGraph с Tinkerpop.
Загружаем и извлекаем последнюю версию JanusGraph. Файл можно взять отсюда.
Создаём файл remote.yaml для настройки удалённого подключения gremlin. Будем обозначать этот файл как ${REMOTE_YAML_LOC}/remote.yaml.
hosts: [${SERVER_IP_ADDRESS}]
port: 8182
serializer: { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV3d0, config: { serializeResultToString: true }}Запускаем консоль gremlin:
${janusgraph_latest_release}/bin/gremlin.sh
И вот что мы делаем в консоли.
Сначала подключаемся к удалённому серверу JanusGraph. Почему? Потому что данные находятся на сервере, а эта клиентская консоль gremlin будет использоваться исключительно для направления на него всех запросов:
:remote connect tinkerpop.server
${REMOTE_YAML_LOC}/remote.yaml session
:remote consoleЗатем загружаем данные air-routes.graphml в JanusGraph. Будем использовать API под названием graph.io из JanusGraph.
graph.io(graphml()).readGraph(‘/opt/janusgraph/data/air-routes.graphml’)
Gremlin Python
Теперь давайте отправим запрос в граф с помощью Python. Суть в том, что мы можем получить какие-то подграфы и проанализировать их в дальнейшем, задействовав имеющиеся библиотеки Python, такие как networkx, в нашей локальной клиентской памяти. Если вы хотите работать со всем исходным графом, например запустить PageRank, не стоит загружать весь граф в локальную клиентскую память. Выберите GraphComputer API из TinkerPop, где можно запускать алгоритмы OLAP через VertexProgram. Подробнее об этом смотрите здесь.
Устанавливаем gremlin-python с помощью pip.
pip install gremlinpython
Устанавливаем соединение с JanusGraph удалённого сервера. Загружаем объект обхода графа g. Делаем это в консоли Python:
from gremlin_python.process.anonymous_traversal import traversal
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
g = traversal().withRemote(DriverRemoteConnection('ws://${SERVER_IP_ADDRESS}:8182/gremlin','g'))Выполняем запросы. Например, нужно получить список аэропортов. В этом случае можно выполнить следующий запрос gremlin:
g.V().hasLabel(‘airport’).valueMap().toList()
Какие ещё запросы можно выполнять, узнайте в Gremlin API. Почему там? Потому как в основе JanusGraph лежит Gremlin. Соответственно, всю информацию о нём можно найти в документации последнего.
Graphexp
Существует несколько сторонних библиотек, созданных для подключения к JanusGraph. С graphexp работать очень просто. Загрузить её можно из этого репозитория github.
git clone https://github.com/bricaud/graphexp
Запускаем graphexp. Просто открываем graphexp.html из браузера.
Выполняем запрос, вводя адрес и порт удалённого сервера. В этом примере отправляется запрос в эго-сеть аэропорта Чанги в Сингапуре:
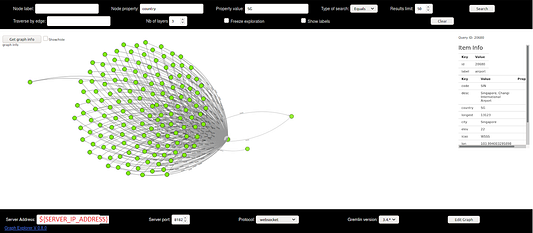
Вот и всё! Теперь у вас есть работающая графовая база данных на удалённом сервере, в которую можно отправлять запросы из любого клиентского компьютера.
Полезные ссылки:
Дополнительное замечания
В некоторых случаях может понадобиться хранить в базе данных несколько независимых графов. Для этого, прежде чем её развёртывать, придётся изменить конфигурационный файл janusgraph yaml. Этапы почти идентичны настройкам сервера gremlin, ведь в основе JanusGraph — сервер gremlin. Этапов фактически всего два (этот пример даётся для TinkerGraph в сервере gremlin).
Во-первых, редактируем файл yaml сервера gremlin. В моём случае надо было создать два графа, поэтому в файле yaml к настройкам графов были добавлены graphA и graphB. Каждый граф определяется в файле свойств properties в conf/:
graphs: {
graphA: conf/tinkergraph-empty.properties,
graphB: conf/tinkergraph-empty.properties
}Во-вторых, обновляем исходный groovy-скрипт. Здесь, в общем-то, нам надо загрузить graphA и graphB. И кроме того, для каждого из них надо создать объекты обхода графа:
...
org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerFactory.generateModern(graphA)
org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerFactory.generateModern(graphB)
...
globals << [
gA : graphA.traversal().
withStrategies(ReferenceElementStrategy.instance()),
gB : graphB.traversal().
withStrategies(ReferenceElementStrategy.instance())
]
...Ещё одна полезная особенность JanusGraph, характерная для любых баз данных, — это управление схемами. Впрочем, эта тема выходит за рамки нашей статьи.
Читайте также:
- Менеджеры контекста в Python - выходим за пределы «with open() file»
- Реализация архитектуры с сохранением состояния в Streamlit
- Алгоритм Рабина-Карпа с полиномиальным хешем и модульной арифметикой
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Edward Elson Kosasih: Simple Deployment of a Graph Database: JanusGraph





