
Часть 1, Часть 2
Система импорта Python
Мы видели много преимуществ системы импорта Python и способов их использования. В этой статье мы приподнимем завесу над тем, что происходит при импорте модулей и пакетов.
Как и многое в Python, систему импорта можно настраивать. Мы увидим несколько способов изменения системы импорта, в том числе автоматическую загрузку недостающих пакетов из PyPI и импорт файлов данных, как если бы они были модулями.
Импорт содержимого модулей
Система импорта Python подробно описана в официальной документации. Вот что происходит на высоком уровне при импорте модуля (или пакета). Модуль:
- Ищется.
- Загружается.
- Привязывается к пространству имён.
Для обычных импортов, выполняемых с помощью оператора import, все три пункта происходят автоматически. А вот при использовании importlib автоматически срабатывают только первые два. Привязывать модуль к переменной или пространству имён придётся самостоятельно.
Например, следующие способы импортирования и переименования math.pi примерно эквивалентны:
>>> from math import pi as PI
>>> PI
3.141592653589793
>>> import importlib
>>> _tmp = importlib.import_module("math")
>>> PI = _tmp.pi
>>> del _tmp
>>> PI
3.141592653589793Конечно, в обычном коде вы бы отдали предпочтение первому.
Следует отметить, что даже если из модуля импортируется только один атрибут, то загружается и выполняется весь модуль. Остальное содержимое модуля просто не привязано к текущему пространству имён. Чтобы доказать это, обратимся к кэшу модулей:
>>> from math import pi
>>> pi
3.141592653589793
>>> import sys
>>> sys.modules["math"].cos(pi)
-1.0sys.modules — это и есть кэш модулей. Он содержит ссылки на все импортированные модули.
Кэш модулей играет очень важную роль в системе импорта Python. Именно здесь, в sys.modules, прежде чем где-либо ещё, Python ищет модули при выполнении импорта. Если модуль уже доступен, то он не загружается снова.
Это не только отличная оптимизация, но и необходимость. Если бы модули при каждом импортировании загружались заново, то в некоторых ситуациях могли бы возникнуть несоответствия (например, когда имеющийся исходный код меняется во время выполнения скрипта).
Вспомните путь импорта, который вы рассматривали ранее, в первой статье. Фактически он сообщает Python, где искать модули. Но если Python находит модуль в кэше модулей, то он не станет утруждать себя поиском пути импорта для этого модуля.
Пример: синглтоны в качестве модулей
В объектно-ориентированном программировании синглтон — это класс, имеющий не более одного экземпляра. И хотя мы можем реализовать синглтоны в Python, большинство случаев хорошего использования синглтонов связано с модулями. Мы можем доверить кэшу модулей инстанцирование класса только один раз.
В качестве примера вернемся к демографическим данным Организации Объединенных Наций, которые мы уже рассматривали ранее, в первой статье. Следующий модуль определяет класс, обёртывающий данные о населении:
# population.py
import csv
from importlib import resources
import matplotlib.pyplot as plt
class _Population:
def __init__(self):
"""Read the population file""" (Считывает файл с демографическими данными)
self.data = {}
self.variant = "Medium"
print(f"Reading population data for {self.variant} scenario")
with resources.open_text(
"data", "WPP2019_TotalPopulationBySex.csv"
) as fid:
rows = csv.DictReader(fid)
# Считывание данных, отбор данных по заданному варианту
for row in rows:
if int(row["LocID"]) >= 900 or row["Variant"] != self.variant:
continue
country = self.data.setdefault(row["Location"], {})
population = float(row["PopTotal"]) * 1000
country[int(row["Time"])] = round(population)
def get_country(self, country):
"""Get population data for one country""" (Получает демографические данные для одной страны)
data = self.data[country]
years, population = zip(*data.items())
return years, population
def plot_country(self, country):
"""Plot data for one country, population in millions""" (Данные для одной страны изображаются на графике, население в миллионах)
years, population = self.get_country(country)
plt.plot(years, [p / 1e6 for p in population], label=country)
def order_countries(self, year):
"""Sort countries by population in decreasing order""" (Сортирует страны по населению в порядке убывания)
countries = {c: self.data[c][year] for c in self.data}
return sorted(countries, key=lambda c: countries[c], reverse=True)
# Инстанцирование синглтона
data = _Population()Чтение данных с диска занимает некоторое время. Мы не ожидаем, что файл данных изменится, поэтому инстанцируем класс при загрузке модуля. Название класса начинается с подчеркивания для указания на то, что его не следует использовать.
Мы можем задействовать синглтон population.data для создания диаграммы Matplotlib, иллюстрирующей демографический прогноз для стран с наибольшей численностью населения:
>>> import matplotlib.pyplot as plt
>>> import population
Reading population data for Medium scenario
>>> # Выберите пять стран с наибольшей численностью населения в 2050 году
>>> for country in population.data.order_countries(2050)[:5]:
... population.data.plot_country(country)
...
>>> plt.legend()
>>> plt.xlabel("Year")
>>> plt.ylabel("Population [Millions]")
>>> plt.title("UN Population Projections")
>>> plt.show()Создаётся такой график:
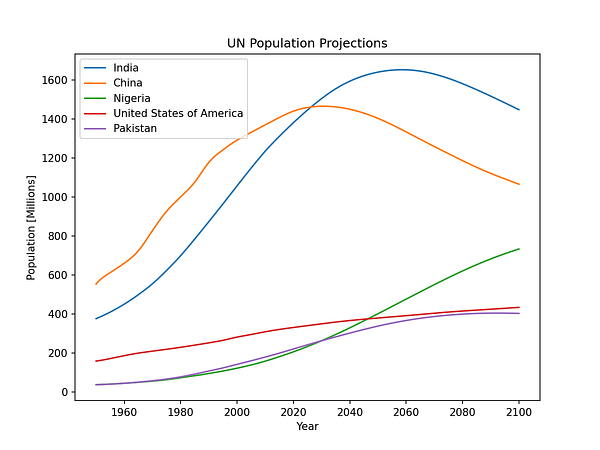
Обратите внимание, что загрузка данных во время импорта — это своего рода антипаттерн. В идеале желательно, чтобы импорт был максимально свободен от побочных эффектов. Лучшим подходом была бы ленивая загрузка данных, т.е. загружать их по мере необходимости. Это может получаться довольно элегантно, если мы задействуем свойства. Пример того, как это делается, можете увидеть ниже.
Ленивая реализация population сохраняет демографические данные в ._data в момент, когда они впервые считываются. Свойство .data работает с этим кэшированием данных:
# population.py
import csv
from importlib import resources
class _Population:
def __init__(self):
"""Prepare to read the population file""" (Подготовка к считыванию файла с демографическими данными)
self._data = {}
self.variant = "Medium"
@property
def data(self):
"""Read data from disk""" (Считывает данные с диска)
if self._data: # Данные уже считаны, возвращает их прямо
return self._data
# Считывает данные и сохраняет их в self._data
print(f"Reading population data for {self.variant} scenario")
with resources.open_text(
"data", "WPP2019_TotalPopulationBySex.csv"
) as fid:
rows = csv.DictReader(fid)
# Считывание данных, отбор данных по заданному варианту
for row in rows:
if int(row["LocID"]) >= 900 or row["Variant"] != self.variant:
continue
country = self._data.setdefault(row["Location"], {})
population = float(row["PopTotal"]) * 1000
country[int(row["Time"])] = round(population)
return self._data
def get_country(self, country):
"""Get population data for one country"""
country = self.data[country]
years, population = zip(*country.items())
return years, population
def plot_country(self, country):
"""Plot data for one country, population in millions"""
years, population = self.get_country(country)
plt.plot(years, [p / 1e6 for p in population], label=country)
def order_countries(self, year):
"""Sort countries by population in decreasing order"""
countries = {c: self.data[c][year] for c in self.data}
return sorted(countries, key=lambda c: countries[c], reverse=True)
# Инстанцирование синглтона
data = _Population()Повторная загрузка модулей
Кэш модулей может быть несколько неудобным, когда вы работаете в интерактивном интерпретаторе. Не так просто перезагрузить модуль после его изменения. Рассмотрим, например, следующий модуль:
# number.py
answer = 24Вернувшись в консоль, импортируем обновленный модуль, чтобы увидеть, что получилось после исправления ошибки:
>>> import number
>>> number.answer
24Почему ответ всё тот же: 24? Кэш модулей делает свою (теперь доставляющую некоторые неудобства) работу: Python уже импортировал ранее number, поэтому он не видит причин загружать этот модуль снова, даже если в него только что внесли изменения.
Самое простое решение здесь — выйти из консоли Python и перезапустить её. Это заставит Python очистить свой кэш модулей:
# number.py
answer = 42Однако перезапуск интерпретатора не всегда возможен. Вероятно, виной тому более сложная сессия, на настройку которой может уйти много времени. В этом случае для перезагрузки модуля можно использовать importlib.reload():
>>> import number
>>> number.answer
24
>>> # Обновляем number.py в редакторе
>>> import importlib
>>> importlib.reload(number)
<module 'number' from 'number.py'>
>>> number.answer
42Обратите внимание, что объекта модуля требует reload(), а не строка типа import_module(). Кроме того, у reload() есть кое-какие нюансы. В частности: переменные, ссылающиеся на объекты внутри модуля, не привязываются повторно к новым объектам при перезагрузке этого модуля. С подробностями можно ознакомиться в документации.
Средства поиска и загрузчики
Мы уже видели, что создание модулей с теми же именами, что и стандартные библиотеки, может приводить к проблемам. Например, если у нас в пути импорта Python есть файл с именем math.py, мы не сможем импортировать math из стандартной библиотеки.
Но это не всегда так. Создадим файл с именем time.py и таким содержимым:
# time.py
print("Now's the time!")Затем откроем интерпретатор Python и импортируем этот новый модуль:
>>> import time>>> #
>>> time.ctime()
'Mon Jun 15 14:26:12 2020'
>>> time.tzname
('CET', 'CEST')Но тут что-то странное случилось. Похоже, Python не импортировал наш новый модуль time. Вместо него был импортирован модуль time из стандартной библиотеки. Почему стандартные библиотечные модули ведут себя непоследовательно? Ответить на этот вопрос мы сможем, внимательно рассмотрев модули:
>>> import math
>>> math
<module 'math' from '.../python/lib/python3.8/lib-dynload/math.cpython.so'>
>>> import time
>>> time
<module 'time' (built-in)>Модуль math импортируется из файла, а вот time — это уже встроенный модуль. Кажется, встроенные модули не затеняются локальными.
Примечание: встроенные модули компилируются в интерпретатор Python. Это в основном базовые модули, такие как builtins, sys и time. Какие именно модули встроенные, зависит от интерпретатора Python. Их имена можно найти в sys.builtin_module_names.
Давайте ещё больше углубимся в систему импорта Python, а заодно разберёмся, почему встроенные модули не затеняются локальными. Импортирование модуля проходит в три этапа:
- Python проверяет, доступен ли модуль в кэше модулей. Если
sys.modulesприсутствует имя этого модуля, то это значит, что модуль уже доступен и процесс импорта завершается. - Python начинает искать модуль с помощью средств поиска. Средство поиска ищет модуль, используя заданную стратегию. Стандартные средства поиска могут импортировать встроенные модули, замороженные модули и модули, находящиеся в пути импорта.
- Python загружает модуль с помощью загрузчика. Какой именно загрузчик используется в Python? Это определяется средством поиска, которое находит модуль. Загрузчик указывается в module spec.
Вы можете расширить систему импорта Python, внедрив своё собственное средство поиска и при необходимости — собственный загрузчик. Позже мы увидим пример использования такого средства поиска. А пока что научимся делать базовые (и совсем простенькие) персональные настройки системы импорта.
sys.meta_path управляет тем, какие средства поиска вызываются в процессе импорта:
>>> import sys
>>> sys.meta_path
[<class '_frozen_importlib.BuiltinImporter'>,
<class '_frozen_importlib.FrozenImporter'>,
<class '_frozen_importlib_external.PathFinder'>]Стоит обратить внимание на два обстоятельства. Во-первых, здесь даётся ответ на поставленный ранее вопрос: встроенные модули не затеняются локальными модулями, потому что встроенное средство поиска вызывается до средства поиска пути импорта, которое находит локальные модули. Во-вторых, есть возможность настроить sys.meta_path так, как вам нужно.
Внесём немного неразберихи в наш сеанс работы в Python. Для этого удалим все средства поиска:
>>> import sys
>>> sys.meta_path.clear()
>>> sys.meta_path
[]
>>> import math
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'math'
>>> import importlib # Автоматически импортирован при запуске, находится всё ещё в кэше модуля
>>> importlib
<module 'importlib' from '.../python/lib/python3.8/importlib/__init__.py'>Средств поиска не осталось, поэтому Python не может найти или импортировать новые модули. Но у Python остаётся возможность импортировать те модули, которые уже находятся в кэше модулей. Он заглядывает туда, прежде чем вызывать средства поиска.
В приведённом выше примере importlib был загружен уже до того, как мы убрали средства поиска. Теперь сделаем наш сеанс работы в Python полностью непригодным. Для этого очистим также и кэш модуля sys.modules.
Далее приведём более полезный пример. Напишем средство поиска, которое выведет на консоль сообщение, идентифицирующее импортируемый модуль. В этом примере показано, как добавить собственное средство поиска, пусть и фактически без попыток найти модуль:
# debug_importer.py
import sys
class DebugFinder:
@classmethod
def find_spec(cls, name, path, target=None):
print(f"Importing {name!r}")
return None
sys.meta_path.insert(0, DebugFinder)Все средства поиска должны реализовывать метод класса .find_spec(), пытающийся найти данный модуль. Есть три способа завершения метода .find_spec():
- С возвращением
None, если он не знает, как найти и загрузить модуль. - С возвращением module spec, указывающим на то, как загрузить модуль.
- С выдачей ошибки
ModuleNotFoundError, указывающей на то, что модуль не может быть импортирован.
DebugFinder выводит на консоль сообщение, а затем явным образом возвращает None, фактически оставляя импорт модуля другим средствам поиска.
Обратите внимание: Python неявно возвращает None из любой функции или метода (не указывая return), поэтому строчку 9 можно опустить. Но в данном случае мы включаем return None, давая понять, что DebugFinder не находит модуль.
Вставив DebugFinder первым в список средств поиска, получаем рабочий список всех импортируемых модулей:
>>> import debug_importer
>>> import csv
Importing 'csv'
Importing 're'
Importing 'enum'
Importing 'sre_compile'
Importing '_sre'
Importing 'sre_parse'
Importing 'sre_constants'
Importing 'copyreg'
Importing '_csv'Например, можем видеть, что импорт csv запускает импорт нескольких других модулей, от которых csv зависит. Обратите внимание, что параметр python -v интерпретатора Python даёт ту же информацию и много других данных.
Или вот ещё пример: скажем, у нас задача избавить мир от регулярных выражений. (Но к чему такая категоричность? Регулярные выражения — это здорово!). Мы можем реализовать средство поиска, которое запрещает модуль регулярных выражений re:
# ban_importer.py
import sys
BANNED_MODULES = {"re"}
class BanFinder:
@classmethod
def find_spec(cls, name, path, target=None):
if name in BANNED_MODULES:
raise ModuleNotFoundError(f"{name!r} is banned")
sys.meta_path.insert(0, BanFinder)Появление ModuleNotFoundError гарантирует, что ни одно из средств поиска, идущих далее в списке средств поиска, выполнено не будет. Тем самым обеспечивается неиспользование регулярных выражений в Python:
>>> import ban_importer
>>> import csv
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../python/lib/python3.8/csv.py", line 6, in <module>
import re
File "ban_importer.py", line 11, in find_spec
raise ModuleNotFoundError(f"{name!r} is banned")
ModuleNotFoundError: 're' is bannedДаже если мы импортируем только csv, этот модуль попутно импортирует и re, поэтому возникает ошибка.
Пример: автоматическая установка из PyPI
Система импорта Python уже достаточно мощная и удобная, поэтому куда проще внести в неё сумятицу, чем дополнить чем-то полезным. Однако следующий пример в определенных ситуациях может пригодиться.
Каталог пакетов Python Package Index (PyPI) — это универсальный каталог программного обеспечения для поиска сторонних модулей и пакетов. Кроме того, это место, откуда pip загружает пакеты.
Вы, возможно, уже видели инструкции с примерами по использованию python -m pip install для установки сторонних модулей и пакетов. Разве не здорово было бы, если бы Python автоматически устанавливал за вас недостающие модули?
Предупреждение: в большинстве случаев было бы совсем не здорово, если бы Python устанавливал модули автоматически. Например, в большинстве производственных настроек надо сохранять контроль над средой. Кроме того, в документации рекомендуется воздерживаться от такого использования pip.
Во избежание ошибок при установке модулей в Python следует экспериментировать с этим кодом только в тех средах, которые не жалко будет удалить или переустановить.
Следующее средство поиска пытается установить модули с помощью pip:
# pip_importer.py
from importlib import util
import subprocess
import sys
class PipFinder:
@classmethod
def find_spec(cls, name, path, target=None):
print(f"Module {name!r} not installed. Attempting to pip install")
cmd = f"{sys.executable} -m pip install {name}"
try:
subprocess.run(cmd.split(), check=True)
except subprocess.CalledProcessError:
return None
return util.find_spec(name)
sys.meta_path.append(PipFinder)Это средство поиска немного сложнее тех, что мы видели ранее. Поставив его последним в списке средств поиска, вы будете знать, что при вызове PipFinder этого модуля не будет в вашем компьютере. Поэтому работа метода .find_spec() — просто выполнить pip install. Если установка выполнится, будет создан и возвращен module spec.
Попробуйте сами использовать библиотеку parse, не устанавливая её:
>>> import pip_importer
>>> import parse
Module 'parse' not installed. Attempting to pip install
Collecting parse
Downloading parse-1.15.0.tar.gz (29 kB)
Building wheels for collected packages: parse
Building wheel for parse (setup.py) ... done
Successfully built parse
Installing collected packages: parse
Successfully installed parse-1.15.0
>>> pattern = "my name is {name}"
>>> parse.parse(pattern, "My name is Geir Arne")
<Result () {'name': 'Geir Arne'}>Обычно import parse не приводит к появлению ошибки ModuleNotFoundError, но в этом случае устанавливается и импортируется parse.
Хотя PipFinder вроде бы работает, с этим подходом связаны некоторые трудности. Основная проблема в том, что имя импорта модуля не всегда соответствует его имени в PyPI. Например, Real Python feed reader называется realpython-reader в PyPI, а имя импорта у него — reader.
Применение PipFinder для импорта и установки reader приводит к установке неправильного пакета:
>>> import pip_importer
>>> import reader
Module 'reader' not installed. Attempting to pip install
Collecting reader
Downloading reader-1.2-py3-none-any.whl (68 kB)
...Это может иметь катастрофические последствия для вашего проекта.
Автоматическая установка может быть очень полезна при запуске Python в облаке с более ограниченным контролем над средой. Например, когда вы запускаете инструменты типа Jupyter notebook в Google Colaboratory. Среда Colab notebook отлично подходит для совместного просмотра данных.
Типичная среда notebook идёт с кучей установленных пакетов для обработки и анализа данных, таких как NumPy, Pandas и Matplotlib, а с помощью pip можно добавлять новые пакеты. Кроме того, можно активировать автоматическую установку:
pip_importer недоступен локально на сервере Colab, поэтому код копируется в первую ячейку notebook.
Пример: импорт файлов данных
Последний пример в этой части составлен по мотивам замечательной статьи Алексея Билогура Import Almost Anything in Python: An Intro to Module Loaders and Finders (eng). Мы уже видели, как использовать importlib.resources для импорта файлов данных. Здесь же мы реализуем пользовательский загрузчик, который может импортировать CSV-файл напрямую.
Ранее у нас был огромный CSV-файл с демографическими данными. Сделаем пример пользовательского загрузчика более управляемым с помощью файла меньшего размера employees.csv:
name,department,birthday month
John Smith,Accounting,November
Erica Meyers,IT,MarchПервая строка представляет собой заголовок с названиями для трёх полей, а следующие две строки содержат информацию о сотрудниках. Ещё больше о работе с CSV-файлами можно узнать в статье Reading and Writing CSV Files in Python (eng).
Наша цель в этой части статьи — написать средство поиска и загрузчик, позволяющие импортировать CSV-файл напрямую, так чтобы можно было написать такой код:
>>> import csv_importer
>>> import employees
>>> employees.name
('John Smith', 'Erica Meyers')
>>> for row in employees.data:
... print(row["department"])
...
Accounting
IT
>>> for name, month in zip(employees.name, employees.birthday_month):
... print(f"{name} is born in {month}")
...
John Smith is born in November
Erica Meyers is born in March
>>> employees.__file__
'employees.csv'Средство поиска должно будет находить и распознавать CSV-файлы. А загрузчик — импортировать данные в формате CSV. Средства поиска и соответствующие им загрузчики зачастую можно реализовать в одном общем классе. Именно такой подход мы здесь и применим:
# csv_importer.py
import csv
import pathlib
import re
import sys
from importlib.machinery import ModuleSpec
class CsvImporter():
def __init__(self, csv_path):
"""Store path to CSV file""" (Сохраняем путь к CSV-файлу)
self.csv_path = csv_path
@classmethod
def find_spec(cls, name, path, target=None):
"""Look for CSV file""" (Ищем CSV-файл)
package, _, module_name = name.rpartition(".")
csv_file_name = f"{module_name}.csv"
directories = sys.path if path is None else path
for directory in directories:
csv_path = pathlib.Path(directory) / csv_file_name
if csv_path.exists():
return ModuleSpec(name, cls(csv_path))
def create_module(self, spec):
"""Returning None uses the standard machinery for creating modules""" (Возвращение None использует стандартный механизм для создания модулей)
return None
def exec_module(self, module):
"""Executing the module means reading the CSV file""" (Выполнение модуля означает чтение CSV-файла)
# Считываем данные CSV и сохраняем их в виде списка строк
with self.csv_path.open() as fid:
rows = csv.DictReader(fid)
data = list(rows)
fieldnames = tuple(_identifier(f) for f in rows.fieldnames)
# Создаём словарь со всеми полями
values = zip(*(row.values() for row in data))
fields = dict(zip(fieldnames, values))
# Добавляем данные в модуль
module.__dict__.update(fields)
module.__dict__["data"] = data
module.__dict__["fieldnames"] = fieldnames
module.__file__ = str(self.csv_path)
def __repr__(self):
"""Nice representation of the class""" (Хорошее представление класса)
return f"{self.__class__.__name__}({str(self.csv_path)!r})"
def _identifier(var_str):
"""Create a valid identifier from a string
См. https://stackoverflow.com/a/3305731
""" (Создаём допустимый идентификатор из строки)
return re.sub(r"\W|^(?=\d)", "_", var_str)
# Добавляем импортёр CSV в конец списка поиска
sys.meta_path.append(CsvImporter)В этом примере довольно много кода! К счастью, большая часть работы сделана в .find_spec() и .exec_module(). Рассмотрим их подробнее.
Мы уже видели, что .find_spec() отвечает за поиск модуля. В этом случае мы ищем CSV-файлы, поэтому создаём имя файла с расширением .csv. name содержит полное имя импортируемого модуля. Например, если у нас from data import employees, то именем name будет data.employees. В этом случае имя файла будет employees.csv.
Для импорта верхнего уровня path (путь) будет None. В этом случае мы ищем CSV-файл в полном пути импорта, который будет включать текущий рабочий каталог. Если импортируется CSV-файл внутри пакета, path примет значение пути или путей этого пакета. При нахождении соответствующего CSV-файла обратно будет возвращён module spec. Этот module spec указывает Python на CsvImporter для загрузки модуля.
Данные в формате CSV загружаются через .exec_module(). Для парсинга файла можно использовать csv.DictReader из стандартной библиотеки. В Python для многих вещей, в том числе и модулей, есть возможность создавать словари. Добавляя данные в формате CSV в module.__dict__, мы делаем их доступными в качестве атрибутов модуля.
Например, добавив fieldnames (имена полей) в словарь модуля в строке 44, можно увидеть имена полей в CSV-файле:
>>> employees.fieldnames
('name', 'department', 'birthday_month')Вообще-то имена полей CSV могут содержать пробелы и другие символы, которые не могут использоваться в именах атрибутов Python. Прежде чем попасть в модуль в качестве атрибутов, имена полей очищаются при помощи регулярного выражения. Это делается в _identifier(), начиная со строки 51.
В качестве примера можно взять имя поля birthday_month. Если обратиться к исходному CSV-файлу, то увидим, что в заголовке birthday month вместо подчеркивания стоит пробел.
Подключив к системе импорта Python этот CsvImporter, вот так просто получаем довольно много функциональности. Кэш модулей, например, позаботится о том, чтобы файл данных загружался только один раз.
Импорт: полезные советы
В завершение статьи покажем несколько хитрых приёмов, помогающих справиться с определёнными ситуациями, которые время от времени возникают. Увидим, как быть с недостающими пакетами, циклическим импортом и даже пакетами, хранящимися в ZIP-файлах.
Пакеты в разных версиях Python
Иногда приходится иметь дело с пакетами, имена которых отличаются в разных версиях Python. Мы уже видели, как importlib.resources были доступны только начиная с Python 3.7. В более ранних версиях Python приходится устанавливать importlib_resources.
Пока различные версии пакета совместимы, мы можем просто переименовывать пакет с помощью as:
try:
from importlib import resources
except ImportError:
import importlib_resources as resourcesВ остальной части кода можно ссылаться на resources и не задумываться о том, что там у нас — importlib.resources или importlib_resources.
Чтобы определиться с версией, обычно проще всего использовать конструкцию try...except. Другой вариант — свериться с версией интерпретатора Python. Однако это может быть чревато увеличением затрат на сопровождение кода, в случае если возникнет необходимость обновить номера версий.
Предыдущий пример можно переписать следующим образом:
import sys
if sys.version_info >= (3, 7):
from importlib import resources
else:
import importlib_resources as resourcesТо есть на Python 3.7 и более новых версиях будем применять importlib.resources, а на более старых версиях Python будем возвращаться к importlib_resources. Смотрите проект flake8-2020 с хорошими и перспективными рекомендациями о том, как проверить, какая версия Python работает.
Недостающие пакеты: используем альтернативу
Следующий сценарий применения тесно связан с предыдущим примером. Предположим, у нас есть совместимая повторная реализация пакета. Повторная реализация лучше оптимизирована, поэтому желательно использовать её, если она доступна. Но исходный пакет ещё более доступен и к тому же обеспечивает приемлемую производительность.
Один из примеров — quicktions, оптимизированная версия fractions из стандартной библиотеки. Мы можем работать с этими параметрами так же, как делали это с разными именами пакетов чуть ранее:
try:
from quicktions import Fraction
except ImportError:
from fractions import FractionБудет использован quicktions, если он доступен. В противном случае — fractions.
Похожий пример — пакет UltraJSON, сверхбыстрый кодер и декодер JSON, который может заменить json из стандартной библиотеки:
try:
import ujson as json
except ImportError:
import jsonПереименовываем ujson в json и не задумываемся о том, какой именно пакет импортирован.
Недостающие пакеты: используем имитированную реализацию
Третий пример, похожий на два предыдущих, — добавление пакета с необязательным для приложения, но приятным функционалом. Здесь опять же добавляем к импорту try...except. Дополнительную сложность представляет замена опционального пакета, если он недоступен.
Конкретизируем пример: будем использовать Colorama для добавления цветного текста в консоль. Colorama в основном состоит из специальных строковых констант, которые добавляют цвет при выводе на печать:
>>> import colorama
>>> colorama.init(autoreset=True)
>>> from colorama import Back, Fore
>>> Fore.RED
'\x1b[31m'
>>> print(f"{Fore.RED}Hello Color!")
Hello Color!
>>> print(f"{Back.RED}Hello Color!")
Hello Color!К сожалению, цвет не отображается в приведенном выше примере. В терминале он будет выглядеть примерно так:
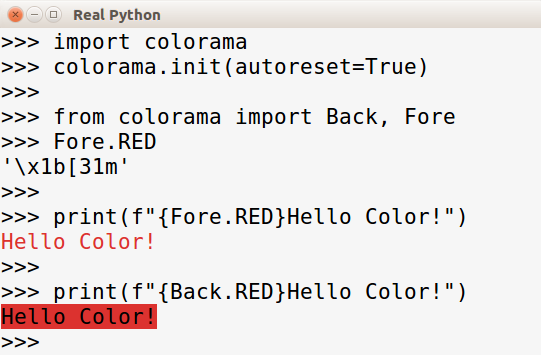
Прежде чем начинать использовать цвета Colorama, вызываем colorama.init(). Установка autoreset на True приводит к тому, что цветовые директивы будут автоматически сброшены в конце строки. Такая настройка пригодится, в случае если вам нужно выделить в цвете только одну строку.
Если же вы захотите вывести всё, например в синем цвете, то установите autoreset на False и добавьте Fore.BLUE к началу скрипта. Доступны следующие цвета:
>>> from colorama import Fore
>>> sorted(c for c in dir(Fore) if not c.startswith("_"))
['BLACK', 'BLUE', 'CYAN', 'GREEN', 'LIGHTBLACK_EX', 'LIGHTBLUE_EX',
'LIGHTCYAN_EX', 'LIGHTGREEN_EX', 'LIGHTMAGENTA_EX', 'LIGHTRED_EX',
'LIGHTWHITE_EX', 'LIGHTYELLOW_EX', 'MAGENTA', 'RED', 'RESET',
'WHITE', 'YELLOW']Также есть возможность выбрать стиль текста с помощью colorama.Style. Доступны DIM (тусклый), NORMAL (нормальный) и BRIGHT (яркий).
И наконец, есть colorama.Cursor с кодом для управления положением курсора. Можно использовать для отображения хода выполнения или статуса запущенного скрипта. В следующем примере показывается обратный отсчет от 10:
# countdown.py
import colorama
from colorama import Cursor, Fore
import time
colorama.init(autoreset=True)
countdown = [f"{Fore.BLUE}{n}" for n in range(10, 0, -1)]
countdown.append(f"{Fore.RED}Lift off!")
print(f"{Fore.GREEN}Countdown starting:\n")
for count in countdown:
time.sleep(1)
print(f"{Cursor.UP(1)}{count} ")Обратите внимание: счётчик остается на месте, обратный отсчёт не показывается на отдельных строках, как происходит обычно:
Вернёмся к нашей задаче. Для многих приложений добавление цвета в консольный вывод — это круто, но не так чтобы очень необходимо. Чтобы не добавлять приложению очередную зависимость, надо использовать Colorama только в том случае, если последняя есть на компьютере, и не ломать приложение, если её нет.
Для этого можно попробовать тестирование и использование моков. Мок может заменить другой объект, позволяя контролировать его поведение. Вот наивная попытка сымитировать Colorama:
>>> from unittest.mock import Mock
>>> colorama = Mock()
>>> colorama.init(autoreset=True)
<Mock name='mock.init()' id='139887544431728'>
>>> Fore = Mock()
>>> Fore.RED
<Mock name='mock.RED' id='139887542331320'>
>>> print(f"{Fore.RED}Hello Color!")
<Mock name='mock.RED' id='139887542331320'>Hello Color!Но она не совсем работает, потому что Fore.RED представлен строкой, которая вносит сумятицу в вывод. В то время как нужно создать объект, который всегда выводит на экран пустую строку.
Можно изменить возвращаемое значение .__str__() в Mock-объектах. Но в этом случае удобнее написать свой мок:
# optional_color.py
try:
from colorama import init, Back, Cursor, Fore, Style
except ImportError:
from collections import UserString
class ColoramaMock(UserString):
def __call__(self, *args, **kwargs):
return self
def __getattr__(self, key):
return self
init = ColoramaMock("")
Back = Cursor = Fore = Style = ColoramaMock("")ColoramaMock("") — это пустая строка, которая при вызове также возвращает пустую строку. Это фактически даёт нам повторную реализацию Colorama, только без цветов.
И последняя особенность: .__getattr__() возвращает сам себя, так что все цвета, стили, а также перемещения курсора, являющиеся атрибутами в Back, Fore, Style и Cursor, тоже имитируются.
Модуль optional_color служит упрощённой заменой Colorama, поэтому мы можем обновить пример с обратным отсчётом с помощью поиска и замены:
# countdown.py
import optional_color
from optional_color import Cursor, Fore
import time
optional_color.init(autoreset=True)
countdown = [f"{Fore.BLUE}{n}" for n in range(10, 0, -1)]
countdown.append(f"{Fore.RED}Lift off!")
print(f"{Fore.GREEN}Countdown starting:\n")
for count in countdown:
time.sleep(1)
print(f"{Cursor.UP(1)}{count} ")Если запустить этот скрипт на компьютере без Colorama, он всё равно будет работать, разве что выглядеть может не так изящно:
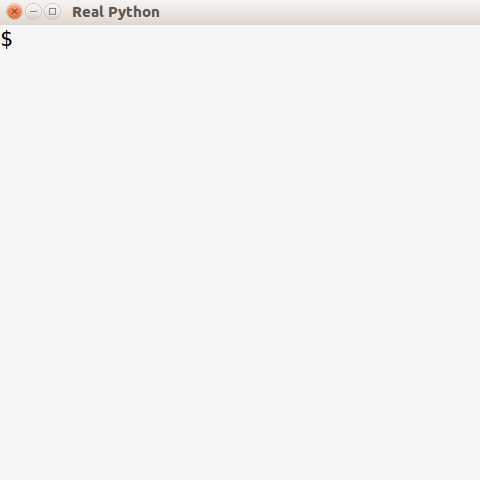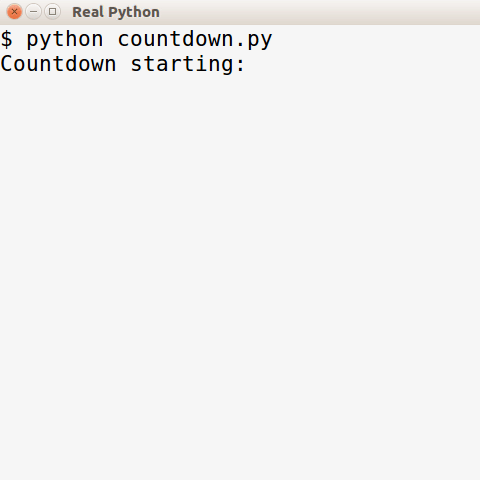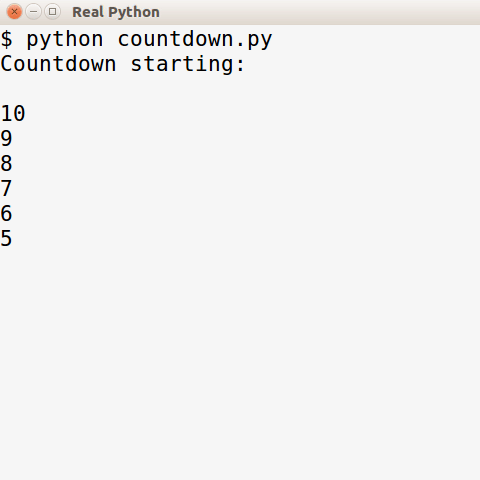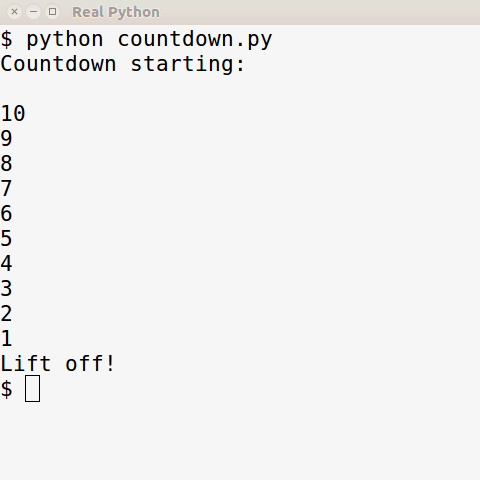
А с установленной Colorama результаты будут такими же, что мы видели раньше.
Импорт скриптов в качестве модулей
Отличие скриптов от библиотечных модулей состоит в том, что скрипты обычно что-то делают, библиотеки же обеспечивают функциональность. И скрипты, и библиотеки находятся внутри обычных файлов Python, и с точки зрения Python между ними нет никакой разницы.
Разница в том, как файл должен использоваться: выполняться с помощью python file.py или импортироваться с помощью import file внутри другого скрипта?
Когда у вас есть модуль, который работает как скрипт и библиотека, можно попробовать выполнить рефакторинг этого модуля на два разных файла.
Один из примеров этого есть в стандартной библиотеке — пакет json. Обычно он используется как библиотека, но в нём есть скрипт, который может придать файлам JSON более привлекательный вид. Представьте, что у вас есть такой файл colors.json:
{"colors": [{"color": "blue", "category": "hue", "type": "primary",
"code": {"rgba": [0,0,255,1], "hex": "#00F"}}, {"color": "yellow",
"category": "hue", "type": "primary", "code": {"rgba": [255,255,0,1],
"hex": "#FF0"}}]}JSON часто читаются только машинами, поэтому многие файлы JSON не форматируются в виде, удобном для восприятия человеком. Так что файлы JSON, состоящие из одной очень длинной строки текста, — явление распространенное.
json.tool — это скрипт, который использует библиотеку json для форматирования JSON в более удобной для восприятия человеком форме:
$ python -m json.tool colors.json --sort-keys
{
"colors": [
{
"category": "hue",
"code": {
"hex": "#00F",
"rgba": [
0,
0,
255,
1
]
},
"color": "blue",
"type": "primary"
},
{
"category": "hue",
"code": {
"hex": "#FF0",
"rgba": [
255,
255,
0,
1
]
},
"color": "yellow",
"type": "primary"
}
]
}Теперь структура JSON-файла становится гораздо менее сложной для понимания. Ключи можно отсортировать в алфавитном порядке. Для этого есть опция --sort-keys.
Разделение скриптов и библиотек — это хорошая практика. Тем не менее в Python есть идиома, благодаря которой можно обращаться с модулем как скриптом и библиотекой одновременно. Как мы уже видели ранее, значение специальной переменной модуля __name__ устанавливается во время выполнения в зависимости от того, импортируется ли модуль или выполняется как скрипт.
Давайте проверим это! Создадим следующий файл:
# name.py
print(__name__)При запуске этого файла увидим, что __name__ имеет специальное значение __main__:
$ python name.py
__main__Но при импорте этого модуля значением __name__ будет имя модуля:
>>> import name
nameЭто поведение используется в следующем шаблоне:
def main():
...
if __name__ == "__main__":
main()Возьмём пример побольше. Оставаться вечно молодыми нам поможет следующий скрипт, в котором любой «старый» возраст (25 года или больше) будет заменяться на 24 года:
# feel_young.py
def make_young(text):
words = [replace_by_age(w) for w in text.split()]
return " ".join(words)
def replace_by_age(word, new_age=24, age_range=(25, 120)):
if word.isdigit() and int(word) in range(*age_range):
return str(new_age)
return word
if __name__ == "__main__":
text = input("Tell me something: ")
print(make_young(text))Можно запустить это как скрипт, и он в интерактивном режиме будет делать вводимый вами возраст меньше:
$ python feel_young.py
Tell me something: Forever young - Bob is 79 years old
Forever young - Bob is 24 years oldМожно использовать этот модуль и в качестве импортируемой библиотеки. Проверка условия if в строке 12 исключает какие-либо побочные эффекты при импорте библиотеки. Определены только функции make_young() и replace_by_age(). Вы можете, например, использовать эту библиотеку вот так:
>>> from feel_young import make_young
>>> headline = "Twice As Many 100-Year-Olds"
>>> make_young(headline)
'Twice As Many 24-Year-Olds'Не будь защиты проверки условия if, импорт запустил бы интерактивный input(), после чего использовать feel_young в качестве библиотеки стало бы очень сложно.
Запуск скриптов Python из ZIP-файлов
Немного неясной представляется способность Python запускать скрипты, упакованные в ZIP-файлы. Её главное преимущество в возможности распространять весь пакет одним файлом.
Однако для этого нужно, чтобы Python был установлен на компьютере. Если хотите распространять свое приложение Python как автономный исполняемый файл, смотрите статью Using PyInstaller to Easily Distribute Python Applications (eng).
Если дать интерпретатору Python ZIP-файл, то он будет искать файл с именем __main__.py внутри ZIP-архива, извлечёт его и запустит. Проиллюстрируем это на простом примере, создадим следующий файл __main__.py:
# __main__.py
print(f"Hello from {__file__}")При его запуске появится такое приветственное сообщение:
$ python __main__.py
Hello from __main__.pyТеперь добавим его в ZIP-архив. Это можно сделать в командной строке:
$ zip hello.zip __main__.py
adding: __main__.py (stored 0%)А в Windows для этого можно использовать метод «укажи и щелкни». Выберите файл в «Проводнике», затем нажмите на нём правой кнопкой мыши и выберите Send to (Отправить) → Compressed (zipped) folder (Сжатая (заархивированная) папка).
__main__ — название не слишком информативное, поэтому мы назвали ZIP-файл hello.zip. Теперь можно прямо вызвать его с Python:
$ python hello.zip
Hello from hello.zip/__main__.pyНаш скрипт знает, что он находится внутри hello.zip. Более того, корневой каталог нашего ZIP-файла добавляется в путь импорта Python, так что скрипты могут импортировать другие модули внутри одного и того же ZIP-файла.
Вспомним наш пример с созданием викторины, основанной на демографических данных. Можно распространять всё это приложение одним ZIP-файлом. importlib.resources позаботится о том, чтобы файл данных был извлечён из ZIP-архива, когда это потребуется.
Приложение состоит из следующих файлов:
population_quiz/
│
├── data/
│ ├── __init__.py
│ └── WPP2019_TotalPopulationBySex.csv
│
└── population_quiz.pyИх можно добавить в ZIP-файл так же, как мы это сделали раньше. Но в Python есть инструмент под названием zipapp, который упрощает процесс упаковывания приложений в ZIP-архивы. Используется он следующим образом:
$ python -m zipapp population_quiz -m population_quiz:mainЧто делает эта команда: создает точку входа и упаковывает приложение.
Не будем забывать, что нам нужен файл __main__.py как точка входа в ZIP-архив. Если мы снабдим параметр -m информацией о том, как должно запускаться наше приложение, то zipapp создаст для нас этот файл. В этом примере сгенерированный __main__.py выглядит примерно так:
# -*- coding: utf-8 -*-
import population_quiz
population_quiz.main()Этот __main__.py упаковывается вместе с содержимым каталога population_quiz в ZIP-архив с именем population_quiz.pyz. Суффикс .pyz указывает на то, что это файл Python, который помещён в ZIP-архив.
Примечание: по умолчанию zipapp никаких файлов не сжимает. Он лишь упаковывает их в один файл. zipapp может сжать файлы, для этого надо добавить параметр -c.
Однако эта функция доступна только в Python 3.7 и более поздних версиях. Ещё больше узнать о zipapp можно в официальной документации.
В Windows .pyz-файлы уже должны регистрироваться как файлы Python. На Mac и Linux вы можете с помощью zipapp создать исполняемые файлы, задействовав параметр -p интерпретатора и указав, какой интерпретатор использовать:
$ python -m zipapp population_quiz -m population_quiz:main \
> -p "/usr/bin/env python"Параметр -p добавляет последовательность символов (#!), которая сообщает операционной системе, как запускать файл. Кроме того, он делает .pyz-файл исполняемым, так что теперь можно запустить файл, просто введя его имя:
$ ./population_quiz.pyz
Считывание данных по численности населения на 2020 год, средний сценарий
Вопрос 1:
1. Восточный Тимор
2. Вьетнам
3. Бермудские острова
Какая страна имеет наибольшую численность населения?Вопрос1:Восточный Тимор
1.Вьетнам
2.Бермудские острова
3.
Какая страна имеет наибольшую численность населения?
Обратите внимание на ./ перед именем файла. Это типичный приём, используемый на Mac и Linux для запуска исполняемых файлов в текущем каталоге. Если вы перемещаете файл в каталог по своему PATH или используете Windows, то имя файла должно быть только таким: population_quiz.pyz.
Замечание: на Python 3.6 и более поздних версиях предыдущая команда завершится с сообщением о том, что ресурс демографических данных в каталоге data найти не удалось. Это связано с ограничением в zipimport.
Решение: добавить к population_quiz.pyz абсолютный путь. На Mac и Linux это можно сделать с помощью такого приёма:
$ `pwd`/population_quiz.pyzКоманда pwd расширяется до пути к текущему каталогу.
В завершение этой часть статьи рассмотрим, как importlib.resources помогают открывать файл данных. Ранее мы уже использовали для этого следующий код:
from importlib import resources
with resources.open_text("data", "WPP2019_TotalPopulationBySex.csv") as fid:
...Более распространенный способ открытия файлов данных — обнаруживать их с помощью атрибута модуля __file__:
import pathlib
DATA_DIR = pathlib.Path(__file__).parent / "data"
with open(DATA_DIR / "WPP2019_TotalPopulationBySex.csv") as fid:
...Такой подход обычно хорошо работает. Но даёт сбой, когда приложение упаковывается в ZIP-файл:
$ python population_quiz.pyz
Reading population data for 2020, Medium scenario
Traceback (most recent call last):
...
NotADirectoryError: 'population_quiz.pyz/data/WPP2019_TotalPopulationBySex.csv'Файл данных внутри ZIP-архива, поэтому open() не может его открыть. importlib.resources решает эту проблему: извлекает данные во временный файл и потом открывает его.
Циклический импорт
Циклический импорт происходит, когда имеются два или больше модулей, импортирующих друг друга. Конкретизируем: представьте, что модуль yin использует import yang, а модуль yang аналогично импортирует yin.
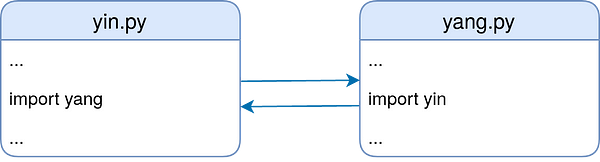
В системе импорта Python предусмотрены определённые возможности для работы с циклами импорта. Например, следующий код — хотя и не очень полезный — работает нормально:
# yin.py
print(f"Hello from yin")
import yang
print(f"Goodbye from yin")
# yang.py
print(f"Hello from yang")
import yin
print(f"Goodbye from yang")При попытке в интерактивном интерпретаторе импортировать yin вместе с ним импортируется и yang:
>>> import yin
Hello from yin
Hello from yang
Goodbye from yang
Goodbye from yinОбратите внимание: yang импортируется внутри импорта yin, а именно в операторе import yang в исходном коде yin. При этом не происходит бесконечной рекурсии. Не даёт ей случиться наш старый друг, кэш модулей.
Когда мы вводим import yin, ссылка на yin добавляется в кэш модулей ещё до загрузки yin. Когда потом yang пытается импортировать yin, он просто использует эту ссылку в кэше модулей.
Проделайте сами нечто подобное или что-то более толковое с модулями. Если вы в своих модулях определяете атрибуты и функции, всё это по-прежнему работает:
# yin.py
print(f"Hello from yin")
import yang
number = 42
def combine():
return number + yang.number
print(f"Goodbye from yin")
# yang.py
print(f"Hello from yang")
import yin
number = 24
def combine():
return number + yin.number
print(f"Goodbye from yang")Импорт yin работает так же, как и раньше:
>>> import yin
Hello from yin
Hello from yang
Goodbye from yang
Goodbye from yinПроблемы с рекурсивным импортом начинают возникать, когда вы фактически используете другой модуль во время импорта, вместо того чтобы просто определять функции, которые впоследствии будут использовать другой модуль. Добавим одну строчку к yang.py:
# yin.py
print(f"Hello from yin")
import yang
number = 42
def combine():
return number + yang.number
print(f"Goodbye from yin")
# yang.py
print(f"Hello from yang")
import yin
number = 24
def combine():
return number + yin.number
print(f"yin and yang combined is {combine()}")
print(f"Goodbye from yang")И тут импорт приводит Python в замешательство:
>>> import yin
Hello from yin
Hello from yang
Traceback (most recent call last):
...
File ".../yang.py", line 8, in combine
return number + yin.number
AttributeError: module 'yin' has no attribute 'number'Появление сообщения об ошибке может показаться на первый взгляд немного странным. Возвращаясь к исходному коду, мы можем убедиться, что number определяется в модуле yin.
Проблема в том, что number не определяется в yin в тот момент, когда импортируется yang. Поэтому yin.number используется вызовом combine().
Кроме этой проблемы, никаких сложностей при импортировании yang не возникнет:
>>> import yang
Hello from yang
Hello from yin
Goodbye from yin
yin and yang combined is 66
Goodbye from yangК тому времени, когда yang вызывает combine(), yin полностью импортируется, а yin.number благополучно определяется. И последний приём: из-за того кэша модулей, который мы видели ранее, import yin может сработать, если сначала будут выполнены другие импорты:
>>> import yang
Hello from yang
Hello from yin
Goodbye from yin
yin and yang combined is 66
Goodbye from yang
>>> yin
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'yin' is not defined
>>> import yin
>>> yin.combine()
66Так как же нам избежать путаницы и не увязнуть в циклическом импорте? Наличие как минимум двух модулей, импортирующих друг друга, часто свидетельствует о том, что можно улучшить структуру модулей.
Часто решить проблему циклического импорта проще всего до момента его реализации. Если вы видите циклы в своих упрощённых структурах, присмотритесь повнимательнее и попробуйте разорвать эти циклы.
Тем не менее бывает целесообразно оставить цикл импорта. Как мы уже видели, это не проблема, пока модули определяют только атрибуты, функции, классы и так далее. Второй совет (тоже хорошая структурная практика) — предохранять модули от побочных эффектов во время импорта.
Если уж вам так нужны модули с циклами импорта и побочными эффектами, есть ещё один выход: выполняйте импорт локально внутри функций.
Обратите внимание: в следующем коде import yang выполняется внутри combine(). Из этого следует, что yang доступен только внутри функции combine(). А главное — импорт не выполняется до тех пор, пока вы не вызовете combine() после того, как yin будет полностью импортирован:
# yin.py
print(f"Hello from yin")
number = 42
def combine():
import yang
return number + yang.number
print(f"Goodbye from yin")
# yang.py
print(f"Hello from yang")
import yin
number = 24
def combine():
return number + yin.number
print(f"yin and yang combined is {combine()}")
print(f"Goodbye from yang")Теперь нет никаких проблем при импортировании и использовании yin:
>>> import yin
Hello from yin
Goodbye from yin
>>> yin.combine()
Hello from yang
yin and yang combined is 66
Goodbye from yang
66Посмотрите: yang фактически не импортируется, пока не вызывается combine(). Другой взгляд на циклический импорт представлен в работе Fredrik Lundh’s classic note (eng).
Профиль импорта
Одна из проблем при импорте нескольких модулей и пакетов состоит в том, что это увеличивает время запуска скрипта. В зависимости от приложения она может быть критичной или некритичной.
С момента выхода Python 3.7 у нас появился быстрый способ узнать, сколько времени занимает импорт пакетов и модулей. Python 3.7 поддерживает параметр командной строки -X importtime, благодаря которому замеряется и выводится на экран время, уходящее на импортирование каждого модуля:
$ python -X importtime -c "import datetime"
import time: self [us] | cumulative | imported package
...
import time: 87 | 87 | time
import time: 180 | 180 | math
import time: 234 | 234 | _datetime
import time: 820 | 1320 | datetimeВ столбце cumulative показано совокупное время импорта (в микросекундах) каждого пакета. Можно прочитать этот список следующим образом: Python потратил 1320 микросекунд, чтобы полностью импортировать datetime, в том числе выполнить импорт time, math, а также реализации C _datetime.
Столбец self показывает время, затраченное на импорт только данного модуля, исключая любой рекурсивный импорт. Как видите, на импорт time потребовалось 87 микросекунд, на импорт math ушло 180, а на _datetime было затрачено 234. Импорт самого datetime занял 820 микросекунд. Совокупное время в итоге составило 1320 микросекунд (с учётом погрешности округления).
Взгляните на пример countdown.py с Colorama, который был приведён чуть выше в этой статье:
$ python3.7 -X importtime countdown.py
import time: self [us] | cumulative | imported package
...
import time: 644 | 7368 | colorama.ansitowin32
import time: 310 | 11969 | colorama.initialise
import time: 333 | 12301 | colorama
import time: 297 | 12598 | optional_color
import time: 119 | 119 | timeВ этом примере импортирование optional_color заняло почти 0,013 секунды. Большая часть этого времени была потрачена на импорт Colorama и её зависимостей. В столбце self показано время импорта без учета вложенного импорта.
Для контраста рассмотрим пример с синглтоном численности населения из первой части статьи. Загружать приходится большой файл данных, поэтому его импорт происходит очень медленно. Проверим это, запустив import population в качестве скрипта с параметром -c:
$ python3.7 -X importtime -c "import population"
import time: self [us] | cumulative | imported package
...
import time: 4933 | 322111 | matplotlib.pyplot
import time: 1474 | 1474 | typing
import time: 420 | 1894 | importlib.resources
Reading population data for Medium scenario
import time: 1593774 | 1921024 | populationЗдесь импорт population занимает почти 2 секунды, из которых около 1,6 секунды тратятся в самом модуле, в основном на загрузку файла данных.
-X importtime — это отличный инструмент для оптимизации импорта. Если вам нужен более общий мониторинг и оптимизация кода, ознакомьтесь со статьёй Python Timer Functions: Three Ways to Monitor Your Code (eng).
Заключение
В этой статье мы познакомились с системой импорта Python. Как и многое другое, что есть в Python, она довольно проста в использовании для выполнения базовых задач, таких как импорт модулей и пакетов. В то же время система импорта достаточно сложная, гибкая и расширяемая. Мы с вами узнали ряд приёмов и особенностей, связанных с импортом, которые можно использовать в своём собственном коде.
Из этой статьи мы узнали, как:
- создавать пакеты пространства имён;
- импортировать ресурсы и файлы данных;
- определять, что импортировать динамически во время выполнения;
- расширять систему импорта Python;
- работать с разными версиями пакетов.
На протяжении всей статьи мы видели много ссылок на дополнительную информацию. Наиболее авторитетным источником по системе импорта Python является официальная документация:
- Система импорта (eng).
- Пакет
importlib(eng). - PEP 420: пакеты неявных пространств имён (eng).
- Импортирование модулей (eng).
Теперь мы можем применять на практике полученные знания об импорте Python, следуя примерам этой статьи. Нажмите на ссылку ниже, чтобы перейти к исходному коду:
Получить исходный код: Нажмите здесь и получите исходный код, используемый для изучения системы импорта Python в этой статье.
Читайте также:
- Продвинутый Python: 9 важнейших аспектов при определении классов
- Как автоматизировать электронную почту с помощью Python
- 5 достойных альтернатив спискам в Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Geir Arne Hjelle: Python import: Advanced Techniques and Tips (вторая часть)





