
Зачем
Разработчик нанимается небольшим городом населением в сто тысяч. Задача состоит в том, чтобы преобразовать бумажную телефонную книгу в цифровой вариант. У мэра города есть одно требование для проекта: цифровая ? телефонная книга должна иметь возможность ? находить номера телефонов на ⚡ молниеносных скоростях.
Вариант A:
Один логический подход для поиска номеров телефонов начнётся с начала телефонной книги. Затем произойдёт проверка страницы на содержание желаемого номера телефона. Если номер на странице не найден, то страница пролистывается и попытка повторяется. Попытки будут продолжаться до тех пор, пока желаемый номер не будет найден.
Этот подход работает, но также требует посещения всех страниц от начала книги и до нужного номера телефона. В информатике это будет сопоставимо с размещением телефонных номеров в связанном списке и поиском от главы списка. Представьте себе, если желаемый номер телефона находится в середине телефонной книги города. Это означает, что для поиска нужного номера страницу пролистают пятьдесят тысяч раз, и никто на самом деле не делает это с реальной или цифровой телефонной книгой.
Вариант Б:
Что же делается обычно? Обычно мы открываем телефонную книгу где-то рядом с серединой и спрашиваем себя: «желаемый номер меньше или больше, чем номер телефона на этой странице?» Если желаемый номер меньше, несколько страниц пролистывается влево. Если желаемый номер больше, несколько страниц пролистывается вправо, а затем снова проверяется. На каждой итерации поиск становится значительно уже. В информатике этот метод был бы сопоставим с размещением телефонных номеров в двоичном дереве и поиском из корня дерева.
Обычно, при использовании двоичного дерева, из ста тысяч телефонных номеров можно найти желаемый примерно за шестнадцать шагов. Вот почемудвоичное дерево обеспечивает управляемый подход к поиску значений.
Что
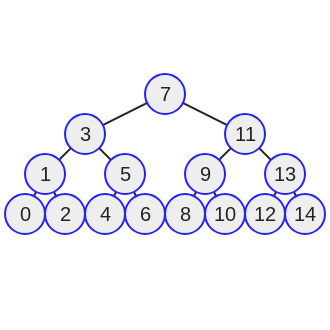
Двоичное дерево представляет собой набор объектов, которые соединены с помощью левого и правого указателей. Каждое соединение, будь то слева или справа, основывается на двоичном сравнении.

Если в дереве нет узлов, входящий узел становится корнем дерева. В приведенном выше примере корнем является десятка. Теперь обратите внимание на узел слева от корня — пять. Пять — меньше десяти. Идём на один уровень ниже. Обратите внимание на узел справа от пяти — семь. Семь больше пяти, но также семь меньше десяти. Семь была размещена слева от десяти и справа от пяти. Это двоичное размещение создает очень специфическое подмножество. Давайте подробнее рассмотрим, что именно делает бинарное дерево.
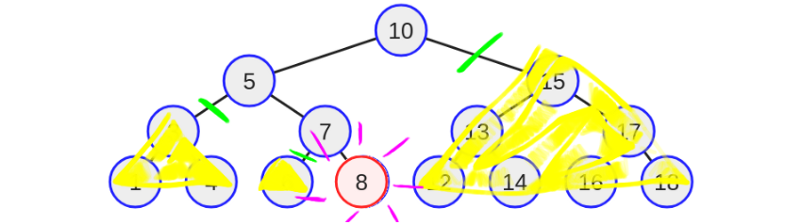
Допустим, инженер искал значение восемь в дереве ниже.
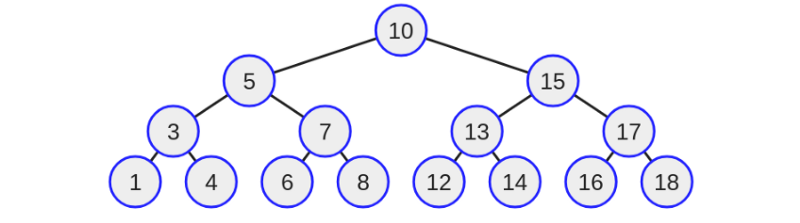
Код инженера сначала бы сравнил желаемое значение — восемь с корневым значением — десять. Восемь меньше десяти, поэтому программа будет переходить влево. Другими словами, значение восьмерки никогда не будет в правом поддереве. Зная, что восемь никогда не будет в правом поддереве, инженер сможет исключить половину вероятностей.
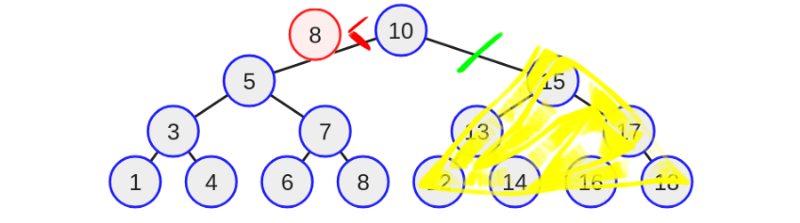
На следующей итерации восемь будут сравниваться со значением пять, но так как восемь больше пяти, то в этот раз программа перейдёт вправо. Другими словами, теперь значение восьмерки никогда не будет в левом поддереве. После этого второго перехода инженер снова исключает половину дерева. Смотрите ниже.
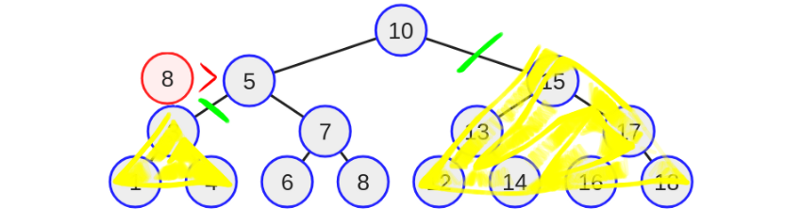
На третьей итерации восемь сравнивается со значением — семь. Поскольку восемь больше семи, алгоритм снова перейдёт вправо, и еще раз половина оставшихся вероятностей исключается.
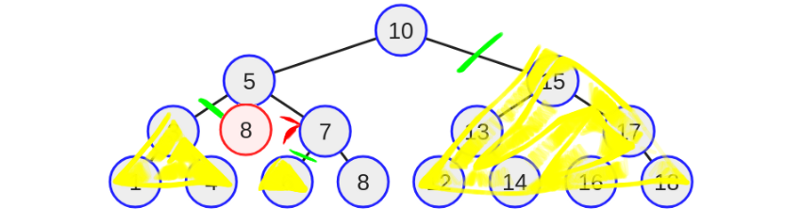
Теперь восьмёрка находится на уровне третьего листа. Значение — восемь сравнивается со значением узла и, наконец, находит эквивалентное значение. Теперь алгоритм достиг нужного узла.
Создайте двоичное дерево, используя это веб-приложение.
Как
Теперь давайте построим двоичное дерево ?. Затем мы проверим это дерево и посчитаем, как ⌛ много времени нужно коду для того, чтобы найти необходимое значение в ста тысячах узлов дерева.
Начнем со структуры узлов.
В структуре узлов имеется переменная с целым числом val, которое хранит значение с номером телефона. Далее структура определяет два указателя слева и справа для значений, которые меньше или больше, чем данный узел. Наконец, объявляется конструктор, который будет заниматься передачей значений к узлу. Обратите внимание, что конструктор также инициализирует левый (left) и правый (right) указатели нулями.
node structure:
struct node {
int val;
node* left;
node* right;
node(int v_) : val(v_), left(NULL), right(NULL) {};
};
Теперь давайте представим макет для класса BinaryTree.
Приватная часть класса содержит: структуру узла, указатель узла на корень (root) и перегруженную функцию вывода.
Публичный раздел класса содержит: функции для добавления узлов, поиска узлов, вывода узлов и конструктора классов.
Обратите внимание, что функция публичного вывода не принимает параметры, в отличие от приватной функции вывода.
Класс BinaryTree (макет):
class BinaryTree {
private:
struct node {
...
};
node* root;
void print(node* temp) {
...
}
public:
void addNode(int v_) {
...
}
int findNodeCount(int v_) {
...
}
void print() {
...
}
BinaryTree() { ... }
};
Теперь давайте сосредоточимся на функции добавления узла, используя итеративный подход.
Сначала код проверяет, есть ли root. Если его нет, то создаётся новый узел, который присваивается к root. В ином случае начинается проход по дереву с указателем узла walker.
Следующим шагом будет проверка: входящее значение меньше или больше значения walker? Если значение меньше, то что-то произойдет на левой ветке. Если значение больше, что-то произойдет на правой ветви.
Что именно происходит, если значение меньше? Сначала мы проверим, указывает ли walker left на другой узел или указывает на null. Если walker leftуказывает на другой узел, происходит обновление walker до значения walker left и процесс повторяется. В противном случае walker left указывает на null, а это означает, что алгоритм достиг конца дерева. Достижение конечной части дерева также означает, что пришло время добавить новый узел для walker left.
Такой же шаблон применяется к правой ветви, но теперь входящее значение должно быть больше, чем значение walker. Сначала мы проверяем указывает ли walker right на другой узел или указывает на null. Если walker rightуказывает на другой узел, происходит обновление walker для указывания на walker right и начинается новая итерация. В ином случае walker rightуказывает на null, а это значит, что алгоритм готов добавить новый узел в нижней части дерева, поэтому происходит установка нового узла вwalker right.
Вдобавок, каждый раз, когда новый узел присоединяется к дереву, мы будем устанавливать указатель узла walker в значение null, чтобы индицировать конец цикла while и в этом же ходу покинуть функцию добавления узла.
addNode function:
void addNode(int v_) {
if(!root)
root = new node(v_);
else {
node* walker = root;
while(walker) {
if(v_ < walker->val) {
if(walker->left)
walker = walker->left;
else {
walker->left = new node(v_);
walker = NULL;
}
}
else {
if(walker->right)
walker = walker->right;
else {
walker->right = new node(v_);
walker = NULL;
}
}
}
}
}
Отлично, перейдём к функции подсчёта количества узлов.
Эта функция считает сколько итераций алгоритм предпримет, чтобы найти любой желаемый узел в дереве.
Начните с объявления переменной count для подсчета каждой итерации. Затем установите значение для указателя узла walker = root. В то время как узел wlaker ищет дерево. Теперь проверьте, совпадают ли значение ходока (walker) и требуемое входное значение. Если совпадают, значит номер найден и пора вернуть значение счётчика. В ином случае пусть троичный оператор определит следующий ход walker’а и счетчик инкрементов.
Наконец, если ходок доходит до конца, то значение walker становится null. Это означает, что желаемый узел не находится в дереве, поэтому возвращаемое значение отрицательно.
findNodeCount function:
int findNodeCount(int v_) {
int count = 0;
node* walker = root;
while(walker) {
if(v_ == walker->val)
return count;
walker = (v_ < walker->val) ? walker->left : walker->right;
count++;
}
return -1;
}
Публичный метод вывода вызывает приватный метод вывода. Это делается для того, чтобы приватный метод вывода мог рекурсивно сканировать дерево. Этот метод известен как упорядоченный перебор.
public print function:
void print() {
cout<<"Printing binary tree:"<<endl<<"[ ";
print(root);
cout<<"]"<<endl;
}
public print function
void print(node* temp) {
if(temp->left)
print(temp->left);
cout<<temp->val<<" ";
if(temp->right)
print(temp->right);
}
Наконец, конструктор для инициализации root значением null.
class constructor:
BinaryTree() { root = NULL; }
Теперь разместите сто тысяч узлов в двоичном древе и протестируйте возможности дерева.
Тестирование включает в себя следующее: добавьте в двоичное дерево сто тысяч случайных телефонных номеров, выберите для поиска случайный номер, выведите дерево, а затем найдите случайно выбранный номер.
Собираем всё вместе
#include <iostream>
#include <stdlib.h>
#include <time.h>
using namespace std;
class BinaryTree {
private:
struct node {
int val;
node* left;
node* right;
node(int v_) : val(v_), left(NULL), right(NULL) {};
};
node* root;
void print(node* temp) {
if(temp->left)
print(temp->left);
cout<<temp->val<<" ";
if(temp->right)
print(temp->right);
}
public:
void addNode(int v_) {
if(!root)
root = new node(v_);
else {
node* walker = root;
while(walker) {
if(v_ < walker->val) {
if(walker->left)
walker = walker->left;
else {
walker->left = new node(v_);
walker = NULL;
}
}
else {
if(walker->right)
walker = walker->right;
else {
walker->right = new node(v_);
walker = NULL;
}
}
}
}
}
int findNodeCount(int v_) {
int count = 0;
node* walker = root;
while(walker) {
if(v_ == walker->val)
return count;
walker = (v_ < walker->val) ? walker->left : walker->right;
count++;
}
return -1;
}
void print() {
cout<<"Printing binary tree:"<<endl<<"[ ";
print(root);
cout<<"]"<<endl;
}
BinaryTree() { root = NULL; }
};
int main() {
srand(time(NULL));
int randomNumberToFind;
int randomPlacement = rand()%100000;
BinaryTree bt;
for(int i=0;i<100000;i++) {
int randomNumber = 202*10000000+(rand()%900 + 100)*1000+rand()%9000+1000;
if(i == randomPlacement)
randomNumberToFind = randomNumber;
bt.addNode(randomNumber);
}
bt.print();
cout<<endl<<"Looking for "<<randomNumberToFind<<"..."<<endl;
cout<<"Found after "<<bt.findNodeCount(randomNumberToFind)<<" traversals."<<endl;
return 0;
}
- Скопируйте код в текстовый редактор и сохраните как
main.cpp - Скомпилируйте из командной строки,
g++ main.cpp -std=c++11 -o bt.exe - Затем выполните код из командной строки
./bt.exe
После компиляции и выполняя исходного кода программа сгенерирует двоичное дерево ? и выведет количество обходов, необходимых для поиска узла.

Код
Просмотреть C++ код вы можете здесь.
Создайте двоичное дерево, используя это веб-приложение.
Перевод статьи David Pynes: Binary trees: a manageable approach to finding values





