
Вы когда-нибудь задумывались о том, как работает знаменитая программа «Hello World!»? Давайте подробно разберём ассемблерный код и увидим, что происходит, так сказать, за кадром при выполнении программы «Hello World!» на C. Первым делом обнаруживается процесс динамического связывания для таких функций, как printf.
Программа «Hello World!» выглядит следующим образом:
#include <stdio.h>
int main() {
printf("Hello World!\n");
return 0;
}Наш компилятор превратил этот исходный код на C в ассемблерный код, который представляет собой инструкции, преобразуемые в двоичный код, который машина сможет понять и выполнить. Каждая из инструкций находится в адресе памяти. Память программы обычно выглядит примерно так:
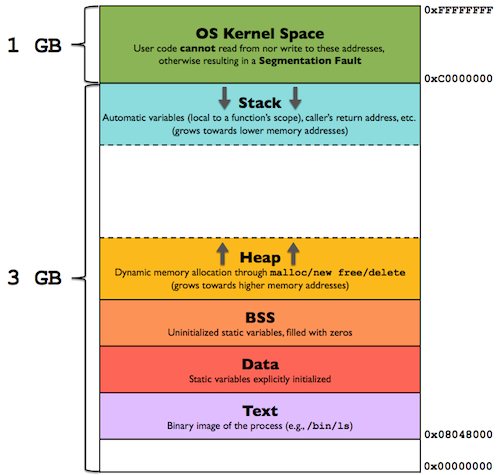
Инструкции программы, как правило, включаются в сегмент памяти .text. Мы можем в этом убедиться на примере нашей программы, запустив info files в GDB. Программа info files показывает нам различные разделы в диапазонах адресов памяти:

Мы видим, что в сегменте .text находятся адресные пространства между 0x0000555555555060 — 0x00005555555551e5, и что наша первая инструкция (0x555555555149 на рисунке 2) действительно так же находится в сегменте .text. А теперь пройдёмся по ассемблерному коду.
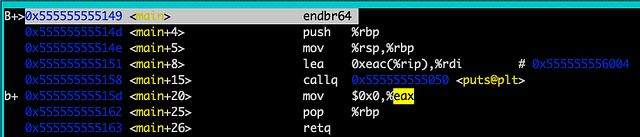
Подготовка к вызову функции
Сначала нам нужно подготовить стековый фрейм, чтобы вызвать функцию printf. Первые две инструкции (push и mov, endbr64 — обычно это noop-инструкция) используются для подготовки нового стекового фрейма к выполнению, так как мы вызываем функцию. Нам нужно сохранить имеющийся %rbp (регистр-указатель базы), который указывает на нижнюю часть (говоря об адресе памяти) текущего стекового фрейма. Сделать это можно, добавив его в стек. Сейчас в этих адресах памяти ничего нет, так как это первая функция.
Затем мы делаем новое значение %rbp равным %rsp, оно указывает на вершину стека. Теперь %rbp имеет верное значение для нового стекового фрейма. Наконец, мы должны загрузить аргумент в регистр %rdi, куда всегда загружается первый аргумент (это похоже на оптимизацию во время компиляции: обычно аргументы добавляются в стек, а затем выталкиваются в регистры после вызова функции). Инструкция lea 0xeac(%rip), %rdi в адресе 0x555555555151 на рисунке 2, по сути, сообщает процессору, что нужно загрузить то, что находится в адресе 0xeac + %rip (возвращение указателя инструкций; это указывает на инструкцию, которая будет выполняться следующей) в %rdi (регистр индекса данных, этот регистр часто используется для хранения первого аргумента в функциях). Скобки обычно указывают на операцию сложения: 0xeac + %rip = 0x555555556004. В нашем случае 0x555555556004 должно быть указателем на строку «Hello World!», которая находится в разделе .rodata, так как это аргумент для нашей функции printf. Выполняя x 0x555555556004 и info files в GDB, убеждаемся, что это действительно так:


Одно здесь может быть вам непонятно: почему при попытке выяснить, где находится строка с «Hello World!», в инструкциях используется относительный адрес счётчика команд вместо абсолютного? Главным образом из-за того, что фрагмент со всей памятью программы может быть перемещён на разные адреса памяти, и программа всё равно будет работать, так как она не использует абсолютные адреса.
Функция
Теперь, когда мы подготовили вызов функции, нам нужно вызвать саму функцию. Здесь надо обратить внимание на то, что printf относится к стандартной библиотеке C, которая часто является динамически подключаемой. Следующим этапом (как показано на рисунке 2) будет вызов функции в адресе 0x555555555050. Так как эта функция динамически подключаемая, можно ожидать этот адрес в разделе .plt. Заметьте, что этот адрес абсолютный, а абсолютные адреса лишают нас удовольствия перемещать программу в памяти. Однако этот адрес немного отличается, так как он определяется во время выполнения, а не во время компиляции.
Напомним, что раздел .plt представляет собой таблицу связывания процедур. Можно считать её набором функций (хотя в ней нет инструкций для функций, тем не менее с её помощью можно определить фактические адреса функций). Эта таблица предназначена для того, чтобы разные программы могли использовать один и тот же раздел .text для общих библиотек, делая данные в этом сегменте доступными только для чтения. Благодаря этому разделу мы можем перезаписывать смещения памяти в разделе .plt вместо того, чтобы менять инструкции общих библиотек. Делая инструкции в общих библиотеках доступными только для чтения, мы можем совместно использовать их в разных процессах. .plt служит уровнем косвенной адресации для переноса проблемы адресации с сегмента .text в раздел .plt. Точкой входа для функций в общих библиотеках всегда будет .plt.
Мы можем проверить это, снова запустив info files (см. рисунок 1) и посмотрев, в каком разделе находится этот адрес. Он находится в разделе .plt.sec (.plt.sec используется вместо .plt, когда включена технология IBT — indirect branch tracking, но это не так важно). Вы спросите: «А как же компилятор узнал, что ему надо направиться по этому адресу?». Функции находятся в заданном месте в .plt.sec, так как количество инструкций на функцию постоянно. Единственное, что должно волновать компилятор: в каком смещении будет находиться функция. Функция у нас только одна, поэтому она всегда будет в первом смещении от начала .plt.sec. Если бы функций было больше, то было бы отображение символа в смещение в .plt.sec, в которое компилятор помещал функцию при выполнении отображения адресов для общих библиотек. Откуда компилятору знать, где находится раздел .plt.sec? Компилятор сам решает, в какие адреса памяти помещать код, и место для раздела, соответственно, выбирает он же!
И здесь снова у вас может возникнуть вопрос: почему пользовательский интерфейс GDB показывает puts@plt вместо printf@plt? А всё просто: это оптимизация во время компиляции. Так как наша функция printf не использует строки форматирования, компилятор предпочитает puts.

Перейдя в .plt.sec, мы видим три инструкции. endbr64 — это фактически noop-инструкция, bnd jumpq *0x2fbd(%rip) и nopl — тоже, по сути, noop-инструкции. Рассмотрим подробнее bnd jumpq *0x2fbd(%rip). На bnd не обращаем внимания (это директива включения в Intel MPX, но является noop, если не поддерживается аппаратными средствами), jumpq *0x2fbd(%rip) выполняет переход указателя инструкций на адрес в 0x2fbd + %rip (звёздочки, как и в C, разыменовывают всё, что находится по указанному адресу). В нашем случае это 0x555555558018. Следует ожидать, что 0x555555558018 будет в глобальной таблице смещений (см. рисунок 1, адрес находится в разделе .got) и адрес в этом месте должен быть адресом функции в разделе .plt. Давайте посмотрим, что находится по этому адресу:

Судя по рисунку 1, этот адрес внутри раздела .plt. Чтобы понять, зачем нам раздел .got и раздел .plt (два слоя косвенности), прочтите эту статью (eng).
Давайте посмотрим, что происходит в 0x555555555030 внутри .plt.

Этот раздел сначала добавляет 0x0 в стек (указатель функции; не забывайте, что есть отображение функции в смещение и что это первая функция), а затем происходит переход к первому разделу в .plt, который начинается, как мы знаем, в 0x555555555020. Это известный адрес, потому что каждый раз, когда мы впервые вызываем динамически подключаемую функцию из .plt, нам нужно перейти к первому «элементу» в .plt и вызвать библиотеку ld-linker.so. Эта запись (первая запись) в .plt особая: она поможет нам найти фактический адрес функции, а также вернуть в исходное положение индекс глобальной таблицы смещений для этой функции, указывающий на фактическое начало функции, а не на .plt. И в следующий раз, когда мы вызовем функцию, она проследует из .plt.sec прямиком к фактическому адресу функции, минуя глобальную таблицу смещений. Мы можем проверить это, снова вызвав printf после первого вызова. Это так называемое «связывание по запросу».

Эта часть кода должна привести нас к компоновщику для динамического связывания функции. Так и происходит! Мы оказываемся в функции внутри /lib64/ld-linux-x86–64.so.2. Неплохо было бы проверить, используется ли адрес 0x7ffff7fe7ae0 совместно разными процессами, ведь это общая библиотека.
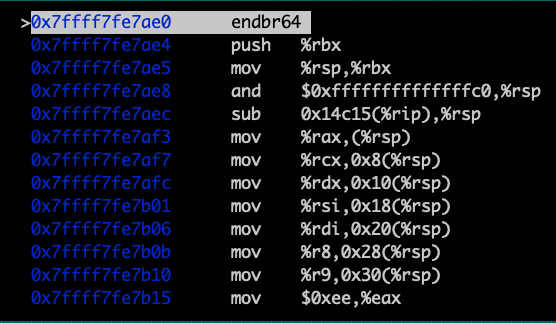
Пробежавшись по функции, запускаемой в коде компоновщика, мы обнаружим, что он приводит нас к функции puts в общей библиотеке!
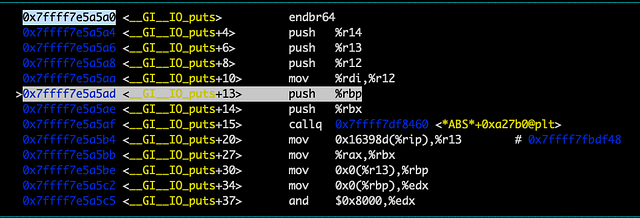
Кроме того, надо проверить, что запись в глобальной таблице смещений возвращена в исходное положение и указывает на 0x7ffff7e5a5a0, первую инструкцию в функции puts.

Так и есть! Теперь в следующий раз при попытке вызвать puts мы сразу перейдем к функции, минуя .plt. Нам также надо убедиться, что после всего этого мы вернёмся обратно в main. info frame показывает, что сохраненный %rip находится в 0x55555555515d, в адресе следующей инструкции main, на которой мы остановились.
Пропуская всё, что относится к функции puts, мы снова добираемся до функции main.
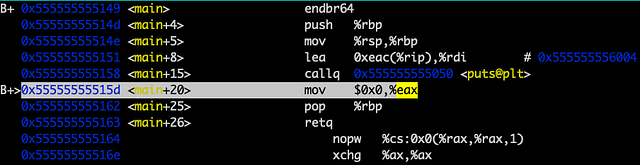
Инструкция mov помещает возвращаемое значение в регистр %eax. Прежнее значение %rbp удалено (pop) из стека и помещено в регистр %rbp. Инструкция retq удаляет старый сохранённый %rip и помещает его в регистр %rip. Следующая инструкция запустит очистку по окончании main. Вот как работает знаменитая программа «Hello World!».
Ссылки и дополнительные материалы:
- https://eli.thegreenplace.net/2011/08/25/load-time-relocation-of-shared-libraries/;
- https://www.technovelty.org/linux/plt-and-got-the-key-to-code-sharing-and-dynamic-libraries.html;
- https://www.akkadia.org/drepper/dsohowto.pdf.
Читайте также:
- Как настроить Visual Studio Code для C, C++, Java, Python
- Расширение Python с помощью C
- Использование методов расширения в C# для элегантного и плавного кода
Перевод статьи Kunal Desai: How does “Hello World!” Actually Work?





