
Искусственный интеллект существенно развился на своём пути сокращения разрыва между возможностями людей и машин. Разработчики наравне с энтузиастами работают над великим множеством аспектов в этой области, ставя целью в конечном счёте добиться удивительных результатов. Одним из таких актуальных и серьёзных аспектов является машинное зрение.
Задача этого направления научить машины смотреть на мир так же, как это делают люди, аналогичным образом воспринимать его и даже использовать знания для решения разных задач, таких как распознавание изображений и видеоряда, анализ и классификация этих изображений, воссоздание медиа-материала, системы рекомендаций, обработка естественного языка и прочего. С течением времени достижения в области машинного зрения с глубоким обучением совершенствовались в основном при помощи конкретного алгоритма — свёрточных нейронных сетей.
Введение
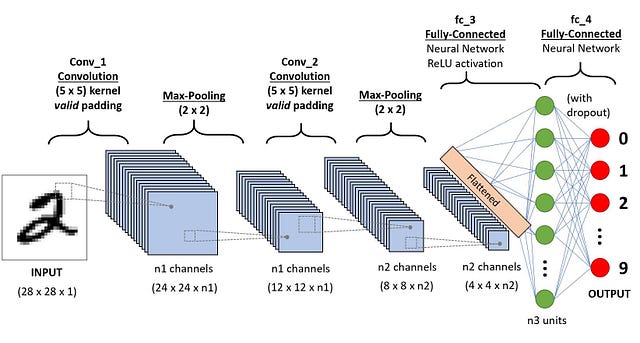
Свёрточная нейросеть (ConvNet/CNN) является алгоритмом глубокого обучения, способным получать в качестве ввода изображение, присваивать степень важности (обучаемые веса и смещения) различным его аспектам/объектам и отличать одно от другого. В то время как в примитивных методах фильтры разрабатываются вручную, при достаточном уровне обучения ConvNets способны самостоятельно изучать эти фильтры/характеристики.
Архитектура ConvNet аналогична шаблону связей нейронов человеческого мозга, а за её основу взята организация его зрительной зоны. Отдельные нейроны отвечают на стимулы только в ограниченной области зрительного поля, называемого рецептивным. Такие поля накладываются друг на друга, образуя коллекцию, покрывающую всю область видимости.
Почему ConvNets, а не нейросети с прямой связью?
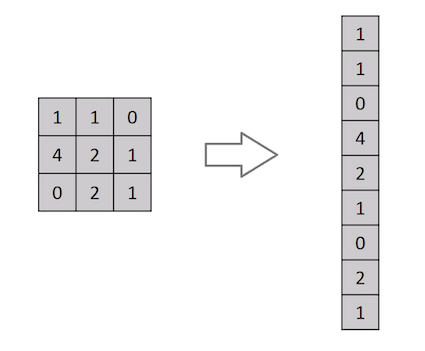
Изображение — это не что иное, как матрица значений пикселей. Так почему бы просто не сделать его плоским (например, матрицу изображения 3х3 в вектор 9х1) и передать в многослойный персептрон для классификации? На самом деле не стоит.
В случаях простейших двоичных изображений метод может продемонстрировать средний показатель точности выполнения прогнозирования классов, но, когда дело дойдёт до сложных изображений, повсюду имеющих пиксельные зависимости, точность снизится до минимума или вообще в ноль.
ConvNet способен успешно фиксировать пространственные и временные зависимости на изображении, применяя соответствующие фильтры. Эта архитектура лучше справляется с сопоставлением набора данных благодаря переиспользуемости весов и снижению числа задействованных параметров. Другими словами, сеть может быть обучена лучше понимать сложность изображения.
Вводное изображение
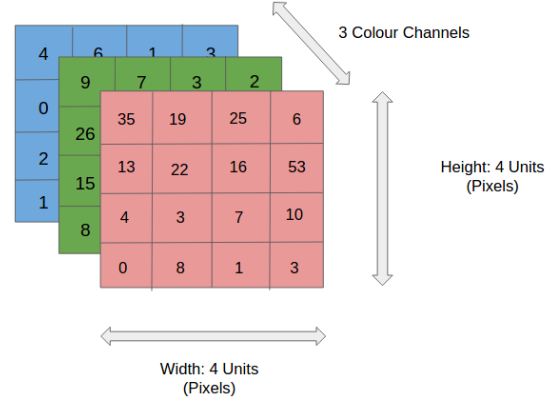
Здесь мы видим RGB-изображение, разделённое на его три цветовых плана: красный, зелёный и синий. Существует множество подобных цветовых схем, в которых могут быть представлены изображения: Grayscale, RGB, HSV, CMYK и т.д.
Вы можете представить, насколько возрастает вычислительная нагрузка, когда изображения достигают размеров, к примеру 8K (7680×4320). Роль ConvNet заключается в уменьшении изображений в более легкую для обработки форму без потери критических для построения хорошего прогноза признаков. Это важно при проектировке архитектуры, которая будет хороша не только в обучении признаков, но также окажется масштабируемой до массивных наборов данных.
Свёрточный слой — ядро
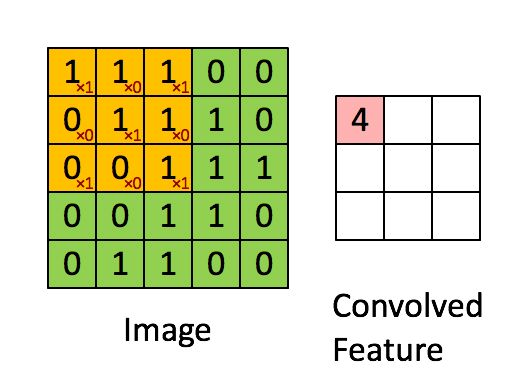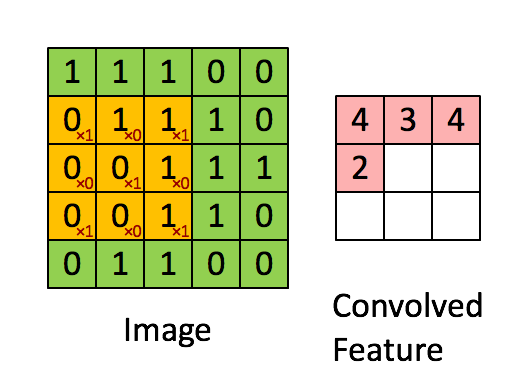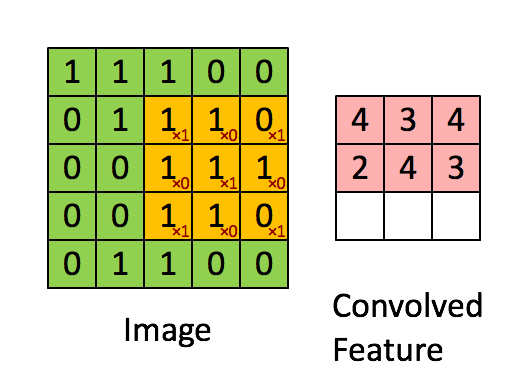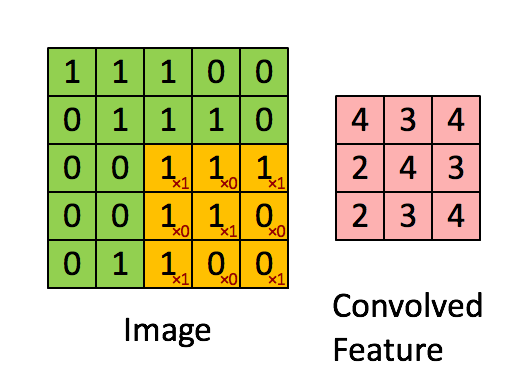
Размеры изображения = 5 (высота) х 5 (ширина) х 1 (число каналов, например RGB).
В приведённом выше примере зелёный участок напоминает наше вводное изображение I с размером 5х5х1. Элемент, задействованный в выполнении операции свёртывания в первой части свёрточного слоя, называется ядро/фильтр K и представлен жёлтым цветом. Мы выбрали K в качестве матрицы 3х3х1.
Kernel/Filter, K =
1 0 1
0 1 0
1 0 1Ядро смещается 9 раз, поскольку величина шага составляет 1 (без шага), при этом каждый раз выполняя операцию матричного умножения между K и частью изображения P, охватываемой ядром.
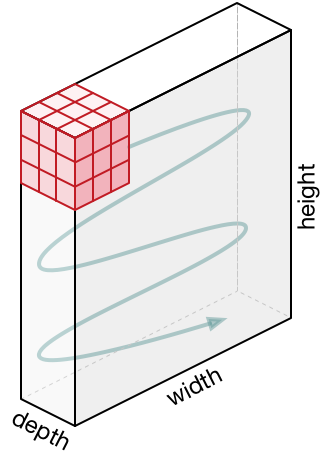
Фильтр перемещается вправо на конкретное значение шага до тех пор, пока не проанализирует всю ширину. Далее, продолжая движение, он перепрыгивает к началу изображения (влево), одновременно смещаясь на то же значение шага вниз, и продолжает описанный процесс, пока не пройдется по всему изображению.
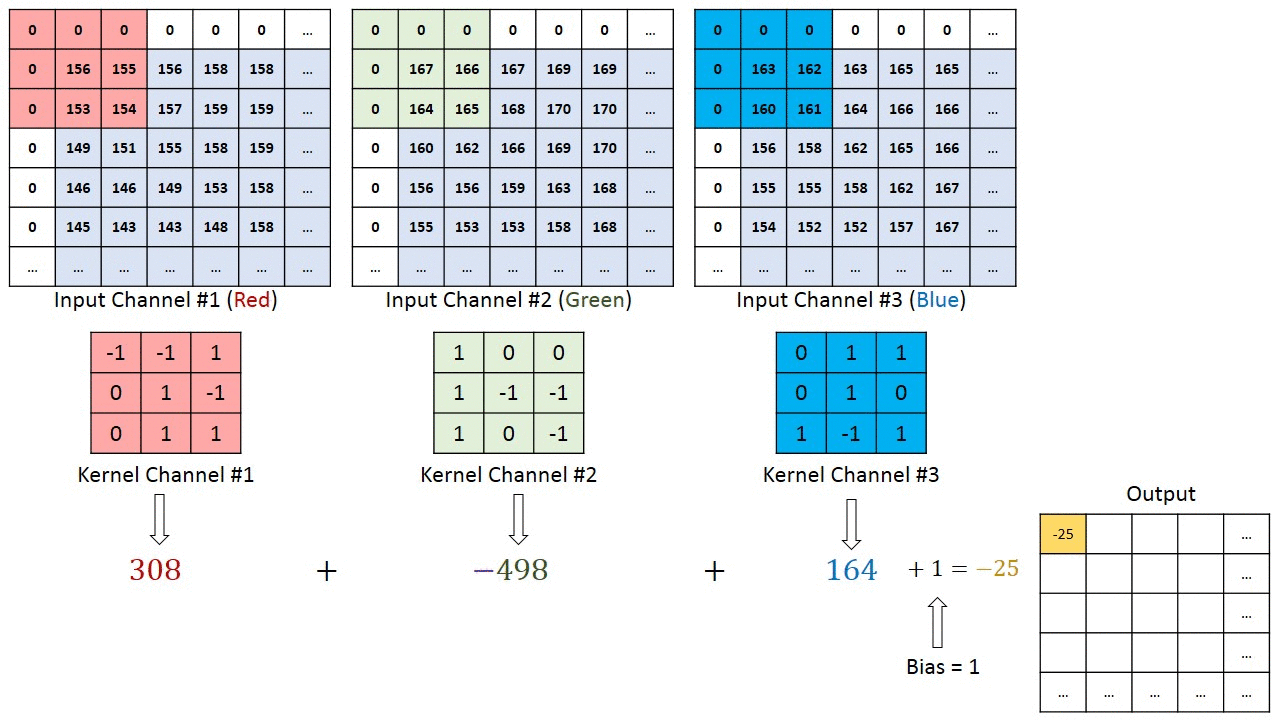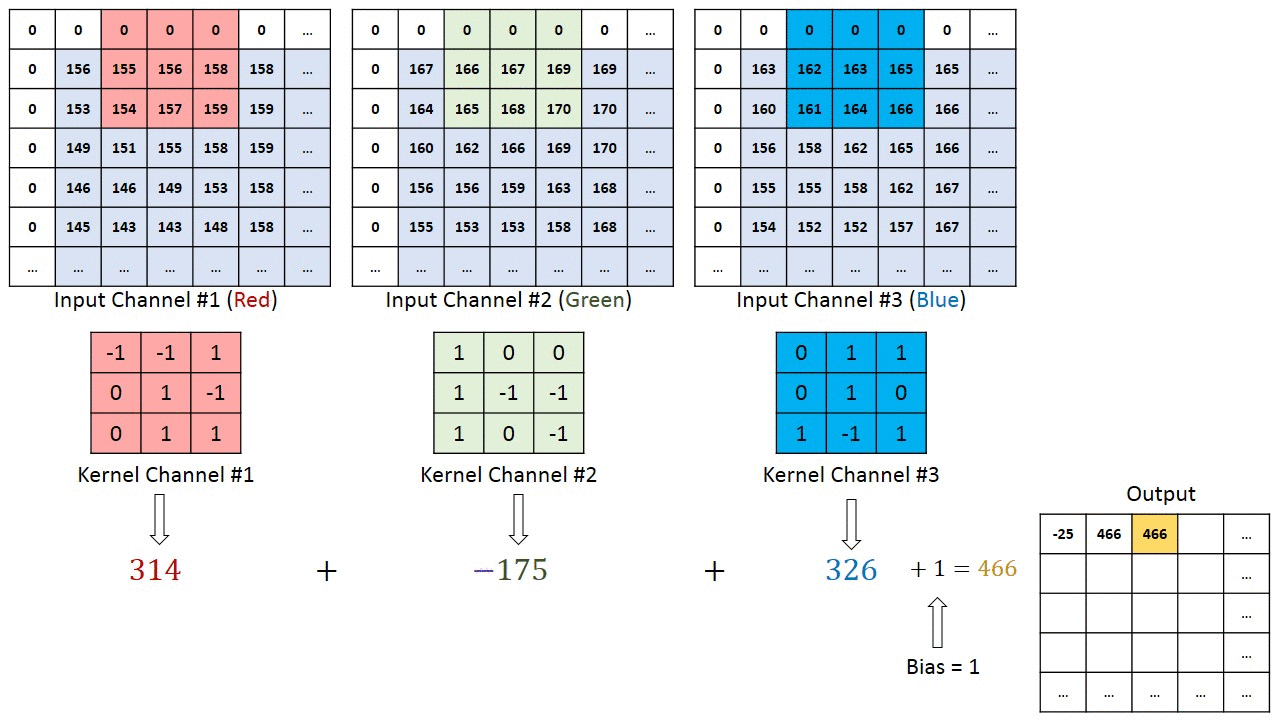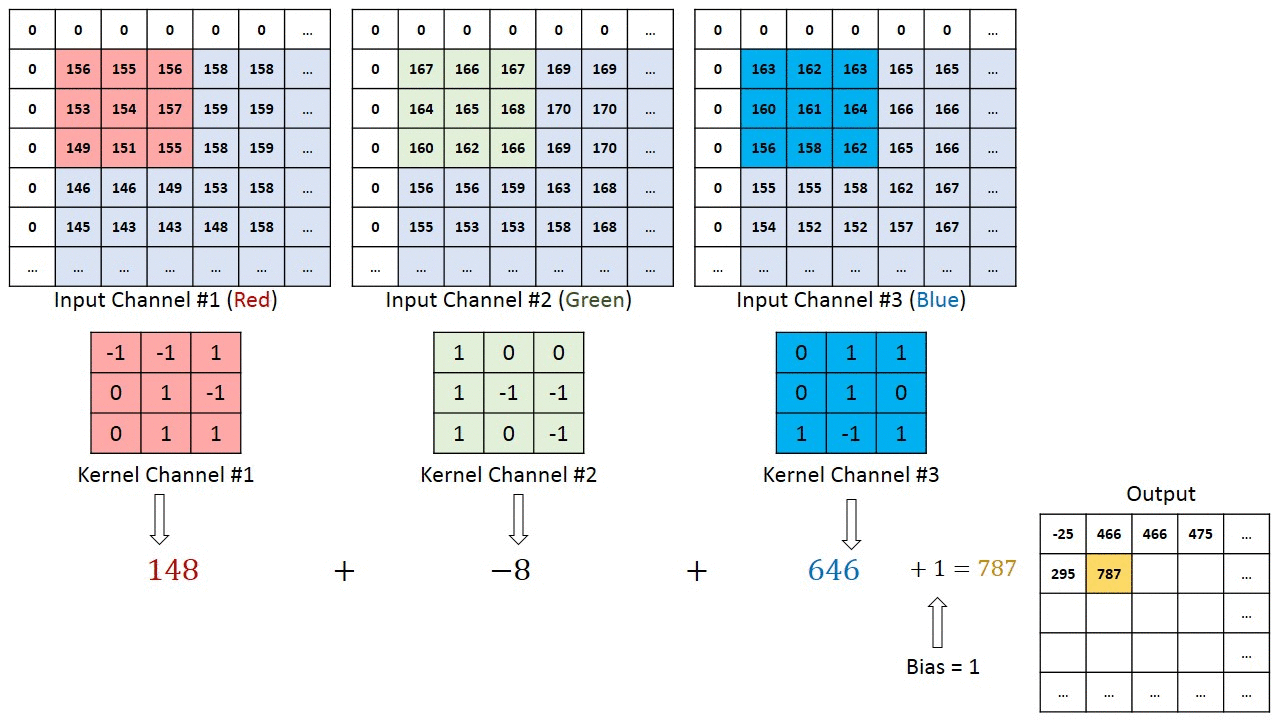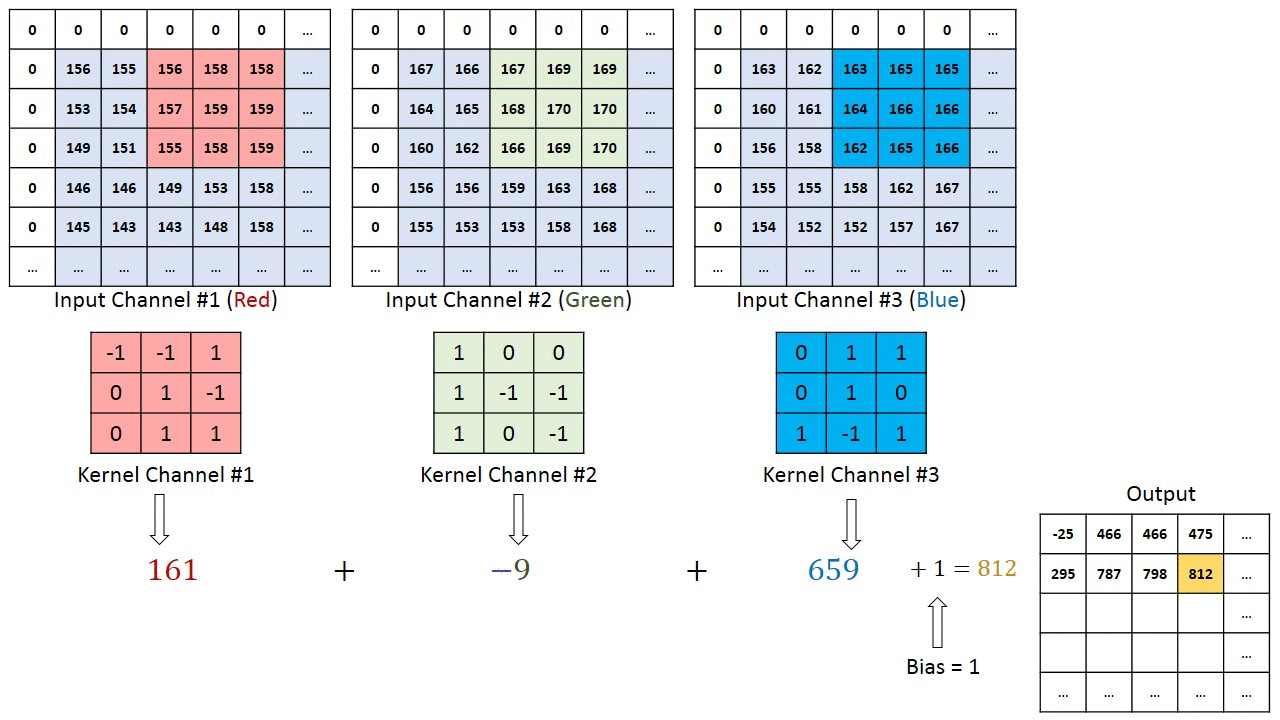
В случаях изображений с несколькими каналами (например, RGB) ядро имеет ту же глубину, что и вводное изображение. Матричное умножение выполняется между стеком Kn и In ([K1, I1]); [K2, I2]; [K3, I3]), при этом все результаты суммируются со значением смещения, чтобы предоставить нам сжатый вывод свёрточного признака, имеющий глубину одного канала.
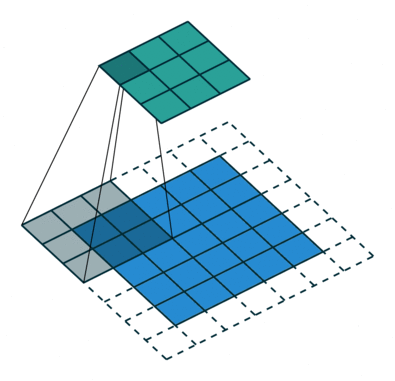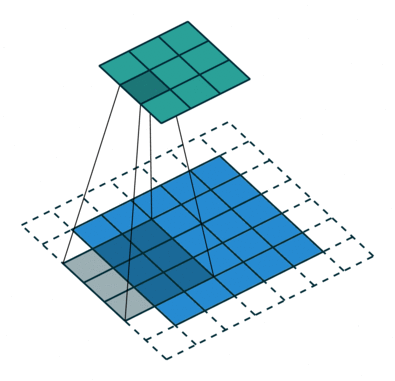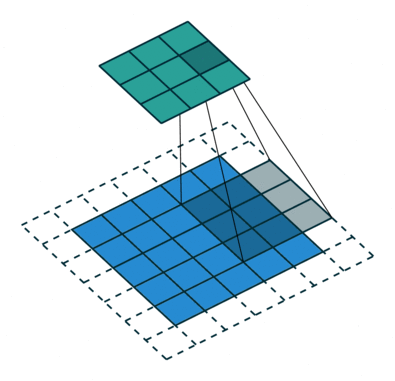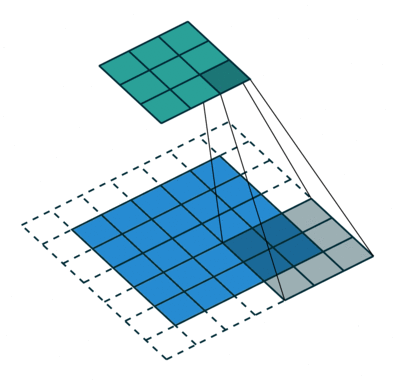
Задача операции свёртывания состоит в извлечении из вводного изображения высокоуровневых признаков, например краёв. ConvNet не должны быть ограничены только свёрточным слоем. Условно первый ConvLayer отвечает за фиксацию низкоуровневых признаков, таких как цвет, градиентная ориентация и т.п. При добавлении дополнительных слоёв архитектура также адаптируется и к признакам верхнего уровня, предоставляя сеть, имеющую полноценное понимание изображений в наборе данных, аналогичное человеческому.
В данной операции могут быть два вида результатов — в одном свёрнутый признак уменьшен в размерности по отношению к вводу, а во втором размерность либо увеличена, либо остаётся такой же. В первом случае применяется заполнение Valid (действительного/без заполнения), а во втором — заполнение Same (одинакового/с заполнением нулями).
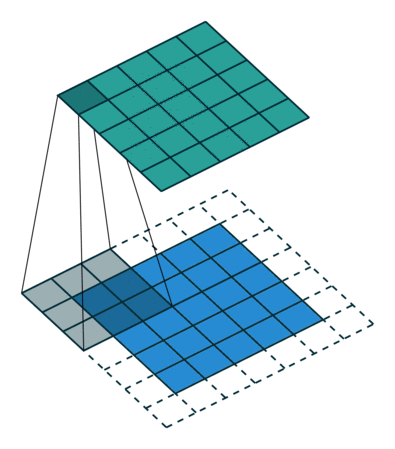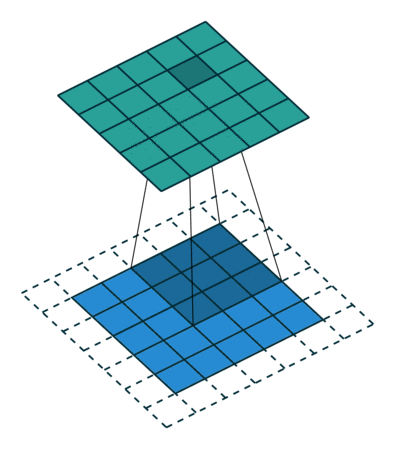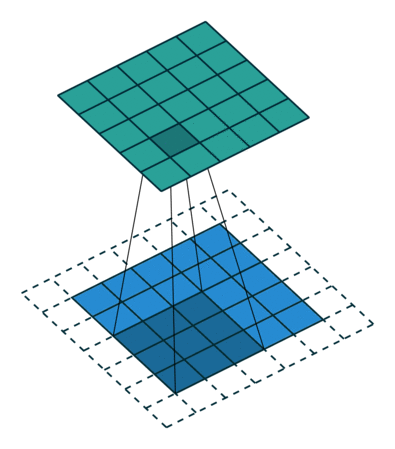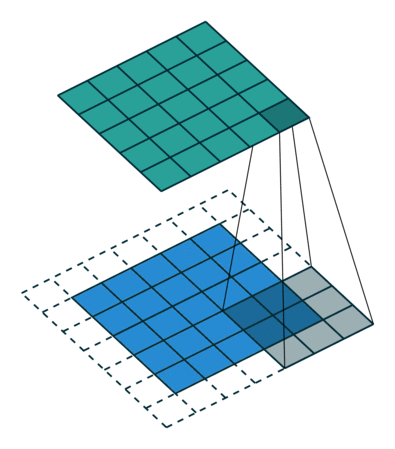
Когда мы аугментируем изображение 5х5х1 в изображение 6х6х1, а затем применяем к нему ядро 3х3х1, то выясняем, что свёрнутая матрица имеет те же размеры 5х5х1. Отсюда и происходит выражение одинаковое (Same) заполнение.
И наоборот, если мы выполняем ту же операцию без заполнения, то получаем матрицу, имеющую размеры самого ядра (3х3х1), то есть действительное (Valid) заполнение.
В приведённом ниже репозитории представлено много подобных GIF, которые помогут вам лучше понять принцип совместной работы заполнения и величины шага для достижения нужных результатов. vdumoulin/conv_arithmetic
A technical report on convolution arithmetic in the context of deep learning. The code and the images of this tutorial…github.com
Слой подвыборки
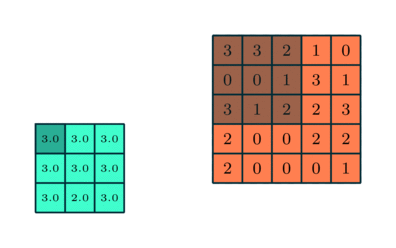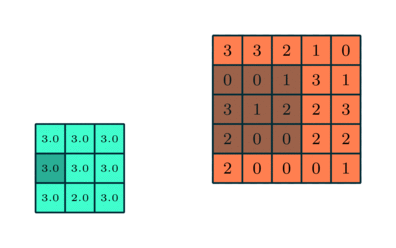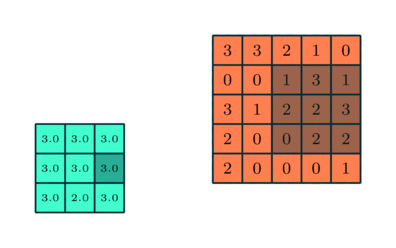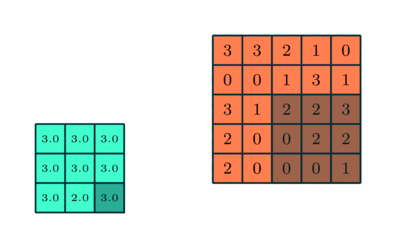
Аналогично свёрточному слою, слой подвыборки отвечает за уменьшение пространственного размера свёрнутого признака. Это делается в целях снижения вычислительной мощности, необходимой для обработки данных, а такжеиспользуется для извлечения доминантных признаков, инвариантных во вращении и позиционировании, что помогает поддерживать процесс эффективного обучения модели.
Существует два вида подвыборки: максимальная и средняя. Первая возвращает максимальное значение из охваченной ядром части изображения. Средняя подвыборка возвращает среднее значение из всех, находящихся в охваченной ядром части.
Максимальная подвыборка также выступает в роли шумоподавителя. Она исключает все шумные активации и параллельно с уменьшением размерности, уменьшает шумность. С другой стороны, средняя подвыборка просто выполняет уменьшение размерности как механизм шумоподавления. Таким образом, можно сказать, что максимальная подвыборка справляется существенно лучше, чем средняя.
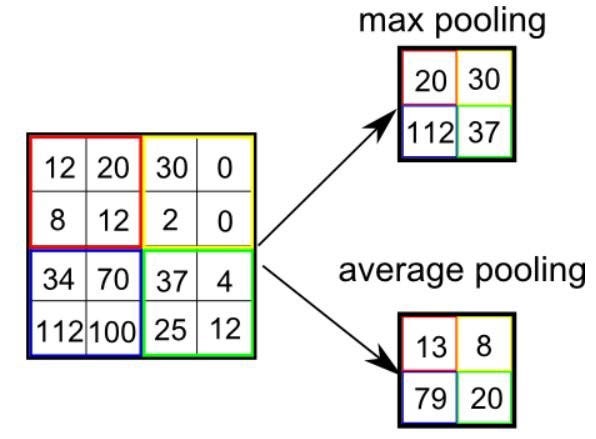
Свёрточный слой и слой подвыборки вместе формируют i-й слой свёрточной нейросети. В зависимости от сложности изображений число таких слоёв может быть увеличено в целях фиксирования низкоуровневых деталей, но ценой этого будет повышение необходимой вычислительной мощности.
Пройдя весь описанный выше процесс, мы успешно обучили модель понимать признаки. Далее мы займёмся уплощением итогового вывода и затем предоставим его стандартной нейросети для классификации.
Классификация — полносвязный слой (FC Layer)
Добавление полносвязного слоя, как правило, является дешёвым способом изучения нелинейных комбинаций высокоуровневых признаков, представленных на выходе свёрточного слоя. Полносвязный слой изучает нелинейную функцию в этом пространстве.
Теперь, когда мы преобразовали вводное изображение в подходящую для нашего многослойного персептрона форму, мы разгладим изображение в вектор-столбец. Уплощённый вывод предоставляется нейросети с прямой связью, и к каждой итерации обучения применяется обратное распространение. Спустя серию интервалов, модель станет способна различать доминирующие и определённые низкоуровневые признаки изображений, а также классифицировать их, используя технику классификации Softmax.
Существуют разные архитектуры CNN, послужившие ключом при создании алгоритмов, которые обеспечивают и продолжат обеспечивать работу ИИ в обозримом будущем. Некоторые из них я перечислил ниже:
- LeNet;
- AlexNet;
- VGGNet;
- GoogLeNet;
- ResNet;
- ZFNet.
Проект на GitHub: распознавание рукописных цифр при помощи набора данных MNIST и TensorFlow.ss-is-master-chief/MNIST-Digit.Recognizer-CNNs
Implementation of CNN to recognize hand written digits (MNIST) running for 10 epochs. Accuracy: 98.99% …github.com
Читайте также:
- Рекуррентная нейронная сеть с головы до ног
- Нейронная сеть с нуля при помощи numpy
- Пишем нейронную сеть, предсказывающую рак груди, за пять минут
Перевод статьи Sumit Saha: A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way.





