
Зачем я пишу эту статью?
Документация Elasticsearch не показалась достаточно хорошо организованной и способной пригодиться новичку. В итоге я прыгал по различным статьям и видео в попытках изучить основные понятия. Я задумал написать эту статью, чтобы хоть немного помочь другим. Здесь собрано все, над чем я поломал голову, изучая Elasticsearch.
Что такое Elastisearch?
Поисковая и аналитическая система с открытым исходным кодом, написанная на Java и построенная на Apache Lucene.
Сразу уточню некоторые моменты:
- Что такое поисковая система: это некий код, который помогает нам эффективно находить что-либо.
- Что такое Apache Lucene: это сердце и мозги Elasticsearch. Именно Apache Lucene делает Elasticsearch эффективной поисковой системой.
Зачем Apache Lucene в Elasticsearch?
На мой взгляд, это самая интересная часть Elasticsearch. Давайте сначала разберемся, как работает любая разновидность поисковой системы.
Цель поисковой системы: найти наиболее релевантные документы, содержащие ваши поисковые запросы.
Шаг 1 (веб-сканер): поисковая система должна узнать о существовании документа.
Давайте представим, что у нас есть три документа, и мы каким-то образом поместили их в нашу поисковую систему.
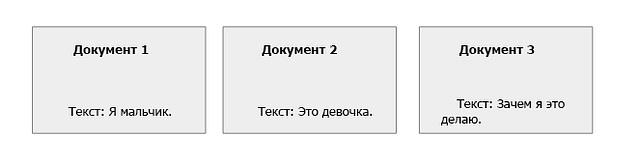
Шаг 2 (инвертированный индекс): индексируем документ для его просмотра.
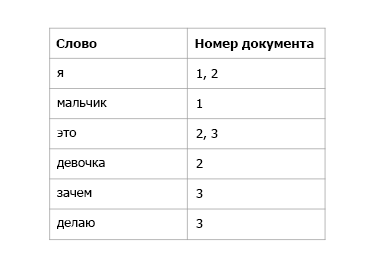
Здесь мы сопоставили каждое слово с номером документа, где оно содержится.
Шаг 3 (оценка): определите, насколько релевантен тот или иной документ. Этот шаг варьируется в зависимости от различных алгоритмов, но в основе его лежит метод простого распределения баллов.
Шаг 4 (поиск): извлечение документов по степени релевантности.
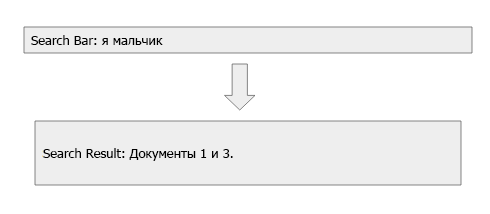
Lucene эффективно выполняет шаги 2, 3 и 4 и, таким образом, играет ключевую роль в работе Elasticsearch.
Все это прекрасно, но у меня в реляционной СУБД есть запрос “select”. Зачем мне Elasticsearch?
С большим количеством нормализации и огромными объемами данных, реляционные СУБД, как правило, принимают на себя удар во время поиска. Хотя они обеспечивают всей системе надежность и структуру, они просто неэффективны при поиске на больших данных. Кроме того, они не выполняют пословный поиск так, как это делает Elasticsearch (то есть с поддержкой инвертированного индекса).
Означает ли это, что мне просто нужно сделать Elasticsearch своей базой данных, и всё?
Было бы здорово, будь это так, но нет. Elasticsearch существует для того, чтобы дополнять ваши базы данных. Он (на сегодняшний день) не может заменить всех возможностей вашей СУБД.
Индекс против Типа в Elasticsearch. Взаимозаменяемы они или нет?
Это мой любимый вопрос. Вы можете найти приведенную ниже аналогию со структурой реляционной СУБД по всему интернету:
- MySQL => Базы данных => Таблицы => Строки/Столбцы;
- ElasticSearch => Индексы => Типы => Документы со свойствами.
НО ЭТО НЕПРАВИЛЬНО.
Сайт Elasticsearch очень хорошо объясняет разницу в приведенном ниже посте: https://www.elastic.co/blog/index-vs-type
Параметры запроса (Query params) или тело запроса (Request Body)?
Elasticsearch предоставил конечные точки REST API для выполнения операций поиска. Этот API принимает аргументы поиска как в качестве URL-параметров, так и в теле запроса.
Примечание: более приемлемым является использование тела запроса.
Что такое логический запрос?
Простой запрос, который сопоставляет документы путем объединения нескольких запросов с использованием логических операторов, таких как AND и OR.

Что такое фильтр запросов и в чем его отличие?
Когда мы говорим об Elasticsearch, в дело всегда вступает коэффициент релевантности. Коэффициент релевантности — это строго положительное число с плавающей точкой, которое показывает, насколько хорошо каждый документ удовлетворяет критериям поиска. Этот коэффициент изменяется в зависимости от самого высокого из присвоенных баллов, следовательно, чем выше коэффициент, тем выше релевантность документа относительно критериев поиска.
Однако фильтр и запрос — это две разные концепции, которые вы должны понимать, прежде чем приступать к составлению запроса.
Вообще говоря, контекст фильтра — это выбор “да/нет”, когда каждый документ либо соответствует запросу, либо не соответствует. Хорошим примером будет WHERE в SQL, за которым следуют некоторые условия. Запросы SQL всегда возвращают вам строки, которые строго соответствуют критериям. Не бывает так, чтобы SQL-запрос возвратил неоднозначный результат.
Фильтры автоматически кэшируются и не влияют на подсчет коэффициента релевантности.
Со своей стороны, контекст запроса в Elastisearch показывает, насколько хорошо каждый документ соответствует вашим требованиям. Для этого запрос использует анализатор и ищет наилучшие совпадения.
Правило большого пальца будет заключаться в том, чтобы использовать фильтры для:
- “да/нет” поиска;
- поиска по точным значениям (числовым, диапазону или ключевому слову).
Используйте запросы для:
- неоднозначных результатов (одни документы подходят больше других);
- полнотекстового поиска.
Если только вам не нужна оценка релевантности или полнотекстовый поиск, всегда старайтесь использовать фильтры. Фильтры стоят “дешевле”.
Кроме того, Elasticsearch будет автоматически кэшировать результаты фильтров.
Читайте также:
- 8 базовых понятий статистики для науки о данных
- Как искусственный интеллект меняет финансовый сектор?
- Моделирование экспоненциального роста
Перевод статьи Aditya Aggarwal: Common Questions on Elasticsearch





