
В предыдущем материале мы остановились на теме корреляции из раздела “Статистические вычисления в языке R”. Переходим к ковариации.
Ковариация
Ковариация была придумана для того, чтобы у нас была информация об отношениях между переменными.
covariance <- cov(A, B)
print(covariance)Стандартизация и нормализация датасета
Часто нам нужно нормализовать данные, например, методом min-max или рассчитать z-оценку с помощью механизма стандартизации.
Стандартизация данных — это получение датасета с нулевым значением среднего арифметического и стандартным отклонением, которое равно единице. Для этого нужно вычесть среднее арифметическое значение из каждого наблюдаемого и затем поделить то, что получилось, на стандартное отклонение.
Мы можем пользоваться функцией масштабирования. Раз нам нужно вычесть среднее арифметическое значение из каждого наблюдаемого, а затем присвоить его центральному параметру значение “True” (истинно).
Если мы хотим стандартизировать данные, тогда нам нужно установить параметр ихмасштабирования в значение True.
normal_A <- scale(A, center=TRUE, scale = FALSE)
print(normal_A)
standard_A <- scale(A, center=TRUE, scale = TRUE)
print(standard_A)Регрессионная теория
Теория регрессии набирает популярность в сфере решений для машинного обучения из-за своей простоты и понятности. В сущности, регрессионные модели также помогают нам понять, какие отношения есть между разными переменными.
Обычно коэффициенты вычисляются для одной и более переменных. Эти переменные являются регрессорами. Их применяют, чтобы оценить и предсказать другую, зависимую переменную. Её ещё называют переменной отклика.
Данные для регрессоров собираются в процессе сэмплирования и нужны, чтобы спрогнозировать результат:
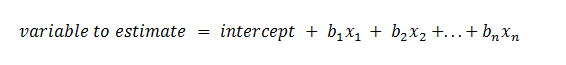
- bn — коэффициенты, нужные для оценки линейных моделей.
- xn — независимые переменные. Мы будем собирать данные для них и передавать в модель.
В качестве примера давайте предположим, что у нас есть собранный датасет с данными о температуре и мы собираемся предсказывать количество осадков. Можем взять линейную модель, такую как показано ниже:
Temperature <- c(1,2,5,6.4,6.7,7,7,7,8,9,3,4,1.5,0,10,5.1,2.4,3.4, 4.5, 6.7)
Rainfall <- c(4,4.1,0,1.4,2,1,6.7,7,5,5,8,9,3,2,2.5,0,10,5.1,4.3,5.7)
model <- lm(Rainfall~Temperature)Примечание: если брали несколько переменных, чтобы спрогнозировать сочетание влажности и температуры для предсказания количества осадков, то мы можем использовать функцию lm() и записать следующую формулу:
Temperature <- c(1,2,5,6.4,6.7,7,7,7,8,9,3,4,1.5,0,10,5.1,2.4,3.4, 4.5, 6.7)
Rainfall <- c(4,4.1,0,1.4,2,1,6.7,7,5,5,8,9,3,2,2.5,0,10,5.1,4.3,5.7)
Humidity <- c(4,4.1,0,1.4,2,1,6.7,7,5,5,8,9,3,2,2.5,0,10,5.1,4.3,5.7)
model <- lm(Rainfall~Temperature+Humidity)Теперь можем вывести результаты по модели.
R сообщит нам об остатках, коэффициентах, их стандартной ошибке отклонения, t-критерии Стьюдента, F-критериии Фишера и так далее:
print(summary(model))
В результате это даст нам следующую статистику:
Call (вызов):
lm(formula = Rainfall ~ Temperature)
#Для этой функции нужны осадки и температура.
Residuals (остатки):
Min 1Q Median 3Q Max
-4.2883 -2.2512 -0.2897 1.8661 5.4124
Coefficients (коэффициенты):
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.8639 1.3744 3.539 0.00235 **
Temperature -0.1151 0.2423 -0.475 0.64040
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.933 on 18 degrees of freedom
Multiple R-squared: 0.01239, Adjusted R-squared: -0.04248
F-statistic: 0.2258 on 1 and 18 DF, p-value: 0.6404Для примера выше количество осадков равно -0,1151, а температура +4,8639.
Если мы хотим использовать модель для оценки нового значения, то можем брать функцию predict(), в которой первый параметр — это модель, а второй — значение температуры, для которого мы хотим предсказать количество осадков:
temperature_value <- data.frame(Temperature = 170)
rainfall_value <- predict(model,temperature_value)
print(rainfall_value)Байесовская модель
Этот подход даёт возможность представлять неизвестные. Цель в том, чтобы ввести данные для оценки неизвестных параметров.
В рамках примера давайте допустим, что мы собираемся определить, насколько будут цениться завтра акции компании. Давайте также учтём, что мы применяем переменную торгов компании для оценки биржевой стоимости.
В таком примере биржевая цена неизвестна и мы будем применять значения торгов компании, чтобы вычислить стоимость акций.
Мы можем собрать примеры продаж из прошлой истории и биржевых оценок, а затем применить их, чтобы найти соотношение между двумя переменными. В реальном проекте мы бы добавили больше переменных для точной оценки биржевой стоимости.
Ключевые концепции для понимания этой задачи — это условная вероятность и теорема Байеса.
В сущности, мы пытаемся применить априорную вероятность стоимости акций, чтобы спрогнозировать ее апостериорную вероятность при помощи данных о правдоподобии и константы нормализации.
install.packages("BAS")
library(BAS)
StockPrice <- c(1,2,5,6.4,6.7,7,7,7,8,9,3,4,1.5,0,10,5.1,2.4,3.4, 4.5, 6.7)
Sales <- c(4,4.1,0,1.4,2,1,6.7,7,5,5,8,9,3,2,2.5,0,10,5.1,4.3,5.7)
model <- bas.lm(StockPrice~Sales)
print(summary(model))Обратите внимание, что мы установили пакет BAS и затем пользовались BAS-библиотекой. Результаты этого смотрите ниже:
P(B != 0 | Y) model 1 model 2
Intercept 1.00000000 1.0000 1.00000000
Temperature 0.08358294 0.0000 1.00000000
BF NA 1.0000 0.09120622
PostProbs NA 0.9164 0.08360000
R2 NA 0.0000 0.01240000
dim NA 1.0000 2.00000000
logmarg NA 0.0000 -2.39463218Генерация случайных чисел
Чтобы сгенерировать случайные числа в границах диапазона, пользуйтесь функцией runif. Она выведет 100 случайных чисел от 0,1 до 10,0.
random_number <- runif(100, 0.1, 10.0)
print(random_number)Также мы можем использовать функцию sample() для того, чтобы сгенерировать элементы и числа с замещением или без него.
Распределение Пуассона
Мы можем пользоваться распределением Пуассона и применять обобщенную линейную модель из семейства моделей Пауссона:
output <-glm(formula = Temperature ~ Rainfall+Humidity,
family = poisson)
print(summary(output))Вот какие результаты будут на выходе:
Deviance Residuals (отклонение):
Min 1Q Median 3Q Max
-3.2343 -0.8547 -0.1792 0.8487 1.8781
Coefficients: (1 not defined because of singularities)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.69807 0.17939 9.466 <2e-16 ***
Rainfall -0.02179 0.03612 -0.603 0.546
Humidity NA NA NA NA
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 35.460 on 19 degrees of freedom
Residual deviance: 35.093 on 18 degrees of freedom
AIC: Inf
Number of Fisher Scoring iterations: 5Нормальное распределение
Есть несколько путей сгенерировать данные с нормальным распределением. Самый распространённый — вызвать функцию rnorm с размером выборки, средним арифметическим значением и стандартным отклонением:
y <- rnorm(100, 0, 1)
Прямая подстановка
Прямая подстановка — общий процесс, который используется для решения системы линейных уравнений: Lx = y
В этом примере L — нижняя треугольная матрица коэффициентов L с ненулевыми диагональными элементами.
Есть две функции, которые помогают нам с прямой и обратной подстановкой.
В R есть функция forwardsolve(A,b) — для прямой подстановки нижнего треугольника A и backsolve(A,b) — для обратной подстановки верхнего треугольника A.
Если конкретнее, то вот они:
backsolve(r, x, k = ncol(r), upper.tri = TRUE,
transpose = FALSE)
forwardsolve(l, x, k = ncol(l), upper.tri = FALSE,
transpose = FALSE)r: верхняя треугольная матрица: R x = b
l: нижняя треугольная матрица: L x = b
Обе эти треугольные матрицы дают нам коэффициенты, которые мы пытаемся вычислить.
x: это матрица, столбцы которой дают нам правые стороны уравнений.
k: это количество столбцов r и строчек x, которые нам надо использовать.
Если значение upper.tri — TRUE (истинно), значит используйте верхний треугольник r.
Если transpose — True, значит пытаемся решить r’ * y = x для y.
Вывод будет такого же типа, как x, следовательно, если x — это вектор, тогда и на выходе будет вектор, а иначе, если x — это матрица, то и на выходе будет матрица.
T-критерий Стъюдента
T-критерий Стъюдента можно рассчитать при помощи функции t.test().
В качестве примера, критерий с одним сэмплом в языке R можно запустить при помощи t.test(y, mu = 0), где y — это переменная, которую мы хотим проверить, а mu — это среднее арифметическое значение, как было определено в нулевой гипотезе:
Humidity <- c(4,4.1,0,1.4,2,1,6.7,7,5,5,8,9,3,2,2.5,0,10,5.1,4.3,5.7)t.test(Humidity, mu = 5)
Код выше проверяет, меньше ли значение влажности, чем среднее арифметическое (5). Это и есть нулевая гипотеза.
И вот какие результаты:
Критерий Стьюдента с одним сэмплом
данные: влажность
t = -1,1052, df = 19, p-значение = 0,2829
альтернативная гипотеза: истинное среднее арифметическое не равно 5-ти
95% доверительного интервала:
2,945439 5.634561
оценки сэмпла:
среднее арифметическое значение x
4,29
18. Графики и диаграммы в R
В этом разделе я объясняю, насколько просто в языке R строить графики.
График распределения X-Y
Я сгенерировал следующие данные:
x<-runif(200, 0.1, 10.0)
y<-runif(200, 0.15, 20.0)
print(x)
print(y)Сниппет такого кода выведет график:
plot(x, y, main='Line Chart')
Коррелограмма
install.packages('ggcorrplot')
library(ggcorrplot)
x<-runif(200, 0.1, 10.0)
y<-runif(200, 0.15, 20.0)
z<-runif(200, 0.15, 20.0)
data <- data.frame(x,y,z)
corr <- round(cor(data), 1)
ggcorrplot(corr)
Гистограмма
x<-runif(200, 0.1, 10.0)
hist(x)
19. Объектно-ориентированное программирование в R
В этом разделе мы выясним всё о концепции объектно-ориентированного программирования в языке R. Важно понимать, как создавать объекты в R — это поможет вам реализовывать масштабируемые комплексные приложения простыми способами.
Самая важная идея для понимания — это то, что в языке программирования R всё является объектом.
И функция тоже объект. Я говорил об этом в соответствующем разделе. Следовательно, мы должны определить функцию, чтобы создать объекты. Ключевое — установить атрибут класса в объекте.
R поддерживает концепции ООП, например наследование. Класс может быть вектором.
Есть несколько способов создать класс в R. Я продемонстрирую самый простой, который связан с созданием классов типа S3. В него также входит создание списка свойств.
Перед тем как я объясню, как создать вполне полноценный класс, давайте пройдёмся по шагам в упрощенном варианте:
- Первый шаг — это создать именованный список, где у каждого элемента есть имя. Имя каждого элемента — это свойство класса. Для примера, вот как мы можем создать класс “Human” (человек) в R:
farhad <- list(firstname="Farhad", lastname="Malik")
class(farhad) <- append(class(farhad), "Human")- Мы создали экземпляр класса “Human” со следующими свойствами: значение имени — Farhad, а фамилии — Malik.
- Чтобы вывести свойство имени для экземпляра объекта Human, мы можем сделать так:
print(farhad$firstname)
- А теперь давайте перейдём к другой важной концепции. Как нам создать экземпляр метода для объекта?
Ключ к решению: использовать команду UseMethod.
Эта команда “говорит” системе R искать функцию. У объекта может быть множество классов, команда UseMethod использует класс экземпляра, чтобы определить, какой метод выполнять.
Давайте создадим функцию GetName, которая возвращает строку с именем и фамилией после конкатенации:
#Так вы создаёте новую общую функцию.
GetName <- function(instance)
{
UseMethod("GetName", instance)
}
#Так вы добавляете к функции ее тело.
GetName.Human <- function(instance)
{
return(paste(instance$firstname,instance$lastname))
}GetName(farhad)Чтобы контейнировать это, создадим класс Human со свойствами имени и фамилии. Это всё будет внутри функции GetName(), которая будет возвращать нам имя и фамилию.
Подсказка: создайте функцию, которая возвращает список и передает свойства в виде аргументов в функцию. А потом воспользуйтесь командой UseMethod, чтобы создать методы.
Human <- function(firstname, lastname)
{
instance <- list(firstname=firstname, lastname=lastname)
class(instance) <- append(class(instance), "Human")
return(instance)
}
GetName <- function(instance)
{
UseMethod("GetName", instance)
}
GetName.Human <- function(instance)
{
return(paste(instance$firstname,instance$lastname))
}
farhad <- Human(firstname="farhad", lastname="malik")
print(farhad)
name <- GetName(farhad)
print(name)Результат работы этого кода:
> print(farhad)
$firstname
[1] "Farhad"
$lastname
[1] "Malik"
attr(,"class")
[1] "list" "Human"
>
>
> name <- GetName(farhad)
> print(name)
[1] "Farhad Malik"Что, если мы хотим создать новый класс OfficeWorker (офисный сотрудник), который наследует свойства класса Human и даёт другую функциональность методу GetName()?
Вот как мы это сделаем:
Human <- function(firstname, lastname)
{
instance <- list(firstname=firstname, lastname=lastname)
class(instance) <- append(class(instance), "Human")
return(instance)
}OfficeWorker <- function(firstname, lastname)
{
me <- Human(firstname, lastname)
# Добавляем класс
class(me) <- append(class(me),"OfficeWorker")
return(me)
}Если мы создаём экземпляр для офисного работника и выводим его, то получим следующее:
worker = OfficeWorker(firstname="some first name", lastname="some last name")
print(worker)
> print(worker)
$firstname
[1] "some first name"
$lastname
[1] "some last name"
attr(,"class")
[1] "list" "Human" "OfficeWorker"Заметьте, что классы экземпляра — это список, Human и OfficeWorker.
Чтобы создать другую функцию для офисного работника, мы можем переопределить её:
GetName <- function(instance)
{
UseMethod("GetName", instance)
}
GetName.Human <- function(instance)
{
return(paste(instance$firstname,instance$lastname))
}
GetName.OfficeWorker <- function(instance)
{
return(paste("Office Worker",instance$firstname,instance$lastname))В результате работы этого кода получаем:
> GetName(worker)
[1] "some first name some last name"20. Как установить внешние пакеты R
Это до безобразия простая процедура. Серьёзно.
Всё, что нужно сделать, напечатать следующую команду (в кавычках подставьте название нужного вам пакета):
install.packages("name of package")
Чтобы установить много пакетов сразу, можем передать вектор для команды install.packages:
install.packages(c("package1","package2"))
Для примера: CARAT — один из самых популярных пакетов для машинного обучения.
В R-Studio пакеты устанавливать ну очень просто. Чтобы установить CARAT, выберите вкладку Packages справа внизу и затем нажмите кнопку установки.
Введите “carat” и нажмите Install.
Появится диалоговое окошко с процессом установки пакета:
Когда пакет установился, вы увидим его в командной строке:
The downloaded binary packages are in
C:\Users\AppData\Local\Temp\Rtmp8q8kcY\downloaded_packagesЧтобы удалить пакет, напечатайте:
remove.packages("package name")
21. Знаменитые библиотеки языка R
Кроме тех библиотек, которые мы уже упоминали в статье вместе со встроенными функциями, есть большое множество еще и других полезных пакетов, которые я советую:
- Prophet: для прогнозирования, науки о данных и аналитических проектов.
- Plotly: для графиков.
- Janitor: для очистки данных.
- Caret: для классификации и регрессионного обучения.
- Mlr: для проектов машинного обучения.
- Lubridate: для данных во времени.
- Ggpolot2: для визуализации.
- Dplyr: для манипуляций с данными и их очистки.
- Forcats: при работе с категорийными данными.
- Dplyr: для манипуляций с данными.
Резюмируем
Вот, что мы узнали про язык R:
- Что такое R?
- Как установить R?
- Где писать код на R?
- Что такое R-скрипт и R-пакет?
- Какие типы данных есть в R?
- Как декларировать переменные и их область действия в R?
- Как писать комментарии?
- Что такое векторы?
- Что такое матрица?
- Что собой представляют списки?
- Что такое датафреймы?
- Различные логические операции в R.
- Функции в R.
- Циклы в R.
- Считывание и запись внешних данных в R.
- Как производить статистические вычисления в R.
- Построение графиков и диаграмм в R.
- Объектно-ориентированное программирование в R.
- Как установить внешние библиотеки R.
- Знаменитые библиотеки R.
Я рассказал о языке программирования R, начиная с основ именно в таком формате, чтобы вам было проще его понять. И снова подчёркиваю, что ключ к продвижению в программировании — постоянная практика: чем больше, тем лучше.
Упорства и успехов!
Читайте также:
- Анализ текста средствами языка программирования R
- Новое в Android 11
- Кто на свете всех сильнее - Java, Go и Rust в сравнении
Перевод статьи Farhad Malik: R — Statistical Programming Language


 на Go. С Python в люльке")


