
Когда лучше избегать логических аргументов?
Логические значения — это первый тип данных, который изучает любой программист. А почему бы и нет? Они являются самыми простыми из всего множества типов с двумя состояниями: “истинным” и “ложным”.
Использование логических значений-флагов для управления машинами состояний заманчиво. Но по мере развития кода они могут легко привести к проблемам сложности кода, читаемости и масштабируемости.
Как правило, аргументы флага разделяют логику функции, заставляя её делать более одной вещи на основе значения. Это может привести к запутанным реализациям в бизнес-логике. Ваша кодовая база может легко стать такой:
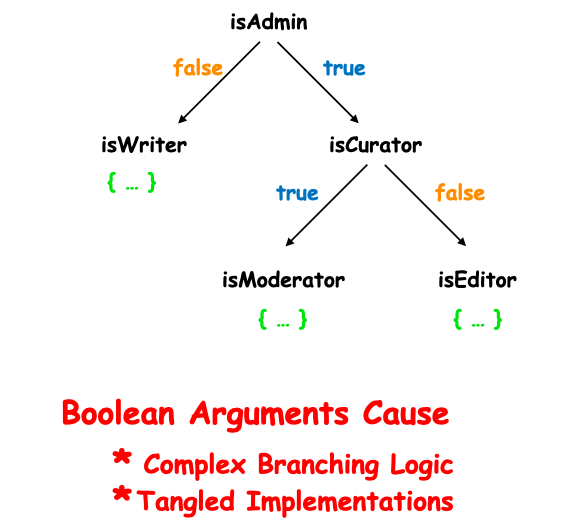
Предыстория
Позвольте рассказать вам историю, подчёркивающую слабые стороны булевых аргументов в автоматах состояний и аргументах функций. Группа программистов однажды создавала модуль, который управляет состоянием пользователя. Один из программистов настаивал на использовании логических значений, поскольку соответствующее требование имело только два состояния: “онлайн” и “оффлайн”. Несмотря на то, что большинство не полностью согласилось с этим предложением, все приняли его: оно выглядело быстрым, лёгким и простым. В конце концов по коду начали расползаться функции, подобные приведенной ниже:
func setUserState(isUserOnline : Bool)
Вскоре к команде присоединился новый разработчик и задался вопросом, что на самом деле означает такой код:
setUserState(true) // Новичок смотрел на это
Разработчики предлагали лучшее название функции (setUserOnline), и это выглядело нормально на первый взгляд, но всё стало кошмаром, когда появилось новое требование, а именно, состояние пользователя: BLOCKED. У них было несколько возможных способов включить в код новое состояние. Давайте рассмотрим их, посмотрим, как они влияют на код и как, наконец, преодолеть эту проблему.
Проблема трёх состояний
Булевы значения обычно представляют два состояния. Но в некоторых языках, например Java, с помощью объекта Boolean мы можем использовать null для присвоения третьего состояния. Так что в нашем контексте, BLOCKED будет привязано к null. Хотя это может показаться приспособлением к новому состоянию пользователя без необходимости в дополнительных булевых переменных, всё может закончиться NullPointerExceptions. Более того, в другой ситуации может быть сложно отличить false от null. Например, булевое свойство game.isPlaying, когда оно true, ясно указывает, что игра происходит прямо сейчас. Но что происходит, когда оно false или null? Означает ли false, что игра приостановлена или остановлена совсем?
Как видите, false не содержит достаточно информации, чтобы мы могли легко определить и вспомнить состояние, с которым связано значение. Три значения только усложняет логику. Кроме того, что произойдёт, когда нас просят включить в код состояние EXPIRED? Очевидно, что мы не можем продолжать применять этот подход, поскольку сейчас у нас четыре состояния. Итак, давайте посмотрим на другой подход.
Несколько логических значений приводят к скрытым зависимостям
В конечном итоге разработчики расширили сигнатуру предыдущей функции, включив для новых состояний два булевых параметра:
func setUserState(
isUserOnline : Bool,
isUserBlocked : Bool,
isUserExpired : Bool)То, что выглядит как простое расширение для выполнения бизнес-требований, против воли вводит скрытые зависимости и множество новых комбинаций в код.
Созданы две скрытые зависимости: isUserOnline — isUserExpired и isUserOnline — isUserBlocked. Это вынуждает явно управлять дополнительными условиями, чтобы избежать конфликтных состояний. Например, заблокированный/истекший пользователь не может находиться в сети. Вот пример двух конфликтующих состояний, с которыми теперь нужно поработать:
#Условие 1: isUserOnline: false и isUserExpired: true
#Условие 2: isUserOnline: false и isUserBlocked: trueПо мере добавления новых состояний функции могут легко превратиться в длинный список параметров. Все становится неустойчивым, так как вы в конечном итоге получите много && , || и другую сложную ветвящуюся логику для обработки взаимоисключающих и зависимых булевых значений.
У логических значений проблемы типобезопасности и читаемости
При использовании нескольких логических значений есть высокая вероятность их смешивания. Вы можете в конечном итоге передать неправильное значение (возможно, из другого объекта), и компилятор даже не будет жаловаться. Это может быть кошмаром при рефакторинге и проверке кода, так как вам нужно будет написать много модульных тестов, чтобы обнаружить такие проблемы. Кроме того, легко потерять нить: что на самом деле означает “false” или “true” для булевой переменной? Понимание вызовов функций, наполненных логическими значениями, только усложняется:
setUserState(true, false, false)
Можно утверждать, что многие языки программирования сегодня поддерживают именованные аргументы, улучшающие читабельность функций. Но опять же, вы можете случайно передать обратное нужному, неправильное логическое значение. Тогда сигнатура функции всё равно будет совпадать. Группа разработчиков из этой истории могла бы избежать этих неприятностей, если бы они использовали перечисления вместо логических значений.
Предпочитайте перечисления, избегайте логических значений
Перечисление — это тип данных, состоящий из набора именованных значений, которые можно использовать типобезопасным способом. Хотя это может выглядеть не так просто, как логическое значение, использование перечисления или другого определяемого пользователем типа помогает нам избежать сложных операторов if с несколькими ветвями.
enum UserStates {
case active
case inactive
case blocked
case expired
}Давайте посмотрим на преимущества, которые перечисление дает при управлении конечными состояниями и сигнатурами функций.
1. Перечисления чёткие и наглядные
Перечисления позволяют обозначить все состояния. Так создаётся самодокументируемый код. Кроме того, перечисления чётко указывают на то, что значения являются взаимоисключающими, тем самым снимая проблемы конфликта состояний. Передача перечислений в качестве параметров в функциях гораздо понятнее и помогает избежать загадочных логических значений. Просто сравните эти две строки:
setUserState(true, false, false)
// Приведенная ниже версия лаконична и ясна: setUserState(UserStates.active)2. Перечисления облегчают масштабирование и рефакторинг
Проще расширить набор значений в перечислениях, потому что, в отличие от логического значения, число возможных комбинаций состояний не удваивается с каждой новой переменной. Кроме того, многие компиляторы достаточно умны, чтобы указать изменения, которые вам нужно сделать для приспособления нового типа перечисления. Например, Swift вызовет ошибку. В то же время в других языках легко найти все типы, присутствующие в перечислении. Расширение уже существующего перечисления новым типом требует минимальных усилий потому, что тип данных остаётся прежним. Это сильно упрощает рефакторинг.
3. Перечисления типобезопасны
С перечислениями вы не можете присвоить какое-либо значение, кроме указанных, потому что перечисления типобезопасны. Это делает невозможным случайный обмен значениями или передачу недопустимого состояния: компилятор обнаружит его. Не все языки имеют встроенную поддержку перечисления, и в таких случаях можно создавать пользовательские типы. Например, в JavaScript мы можем обойти эту проблему “заморозив” константы в объекте:
const UserState = {
ACTIVE: 1,
INACTIVE: 2,
BLOCKED: 3,
EXPIRED: 4
};
Object.freeze(UserState);Заключительные мысли
Помните, что булевы неплохи. Совершенно нормально использовать их в аргументах функции, если вы уверены, что состояния двоичные и взаимоисключающие, или когда имя метода уже описывает его, например так: setEnabled (true). Но чаще всего требования меняются, добавляются новые состояния. Двухэлементное перечисление стоит усилий и является более безопасной ставкой, чем булевы флаги. Перечисления помогают защитить ваш код в будущем и устраняют необходимость отслеживать логические поля. Булевы символы — самые простые, но их легко использовать неправильно. Или, скорее, злоупотребить ими.
Это всё на сегодня. Спасибо за чтение!
Читайте также:
- Стоит ли разработчику изучать VIM в 2020 году?
- Возвращаемся к SOLID
- ПО без тестирования - что самолет без крыльев
Перевод статьи Anupam Chugh: Don’t Use Boolean Arguments, Use Enums





