
Она навсегда изменит вашу жизнь
Вы загрузили данные в DataFrame и уже готовы провести предварительный анализ…, но сначала придется создать кое-какие дополнительные функции. Как правило, вы обращаете свой взор на apply. Apply — это очень удобная функция, которой легко пользоваться на всех строках данных. И вот вы прописали все необходимое, запустили код и…
Ждете
Оказывается, что на обработку каждой строки большого набора данных уходит много времени. Как хорошо, что есть простое решение для экономии этого времени.
Swifter
Swifter — это библиотека, которая «применяет любую функцию к DataFrame или Series в Pandas самым быстрым из всех возможных способом». Чтобы лучше понять, как она работает, поговорим о нескольких ключевых аспектах.
Векторизация
В данном случае под векторизацией следует понимать использование NumPy для выражения действий над целыми массивами, а не их элементами.
Допустим, у вас есть два массива:
array_1 = np.array([1,2,3,4,5])
array_2 = np.array([6,7,8,9,10])
Теперь вы хотите создать новый массив, который просуммировал бы оба этих массива и выдал следующий результат:
result = [7,9,11,13,15]
Просуммировать оба массива можно через цикл for в Python, однако он выполняется слишком медленно. NumPy, напротив, позволяет выполнять действия напрямую с массивами, благодаря чему выполняется намного быстрее (особенно при больших массивах).
result = array_1 + array_2
Основная мысль: векторизацией надо пользоваться везде, где только можно.
Параллельная обработка
Почти все компьютеры имеют несколько процессоров. То есть вы можете легко ускорить код чего-либо, задействовав все. А поскольку apply — это всего лишь применение функции к каждой строке в DataFrame, то ее можно легко распараллелить. Вы можете просто разделить DataFrame на несколько фрагментов, загрузить каждый из них в свой процессор, а затем снова объединить их в единый фрейм данных.
Магия
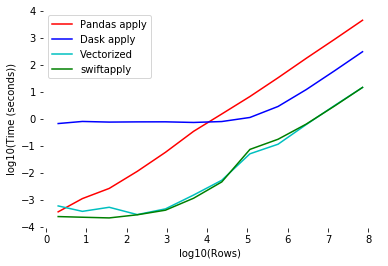
Что делает Swifter:
1. Проверяет, можно ли векторизовать вашу функцию. Если да, то просто использует векторизованные вычисления.
2. Если векторизация невозможна, то выбирает подходящую альтернативу: параллельная обработка через Dask или apply из vanilla Pandas (использует только одно ядро). Затратность параллельной обработки существенно тормозит весь процесс, особенно для небольших наборов данных.
Все это наглядно представлено на графике выше. Как видите, в подавляющем большинстве случаев векторизация является идеальным решением для любого объема данных. Если же она недоступна, то самой «быстрой» альтернативой для небольших объемов данных станет vanilla Pandas. При объемных данных присмотритесь к параллельной обработке.
Вы видите, что Swifter автоматически проставляет самый подходящий вариант в строке swiftapply.
«А как же пользоваться этим чудом?» — спросите вы. Очень просто!
import pandas as pd
import swifter
df.swifter.apply(lambda x: x.sum() - x.min())Просто добавьте вызов Swifter перед apply (см. выше). Одно это слово «разгонит» вашу Pandas до небывалой скорости.
Таким образом, вы сможете меньше следить за ходом выполнения кода и больше заниматься наукой, и ваша жизнь уже не будет прежней.

Читайте также:
- Простое руководство по аргументам командной строки Python
- Логи в Python. Настройка и централизация
- Полное руководство по встроенным структурам данных Python
Перевод статьи Tyler Folkman: One Word of Code to Stop Using Pandas So Slowly




