
Простое руководство по изучению многопоточности, конкурентности и параллелизма в C++
Вначале, когда ещё только состоялось моё знакомство с многопоточностью в C++, многое было мне непонятным и сбивало с толку. Сложность программы расцветала буйным цветом (именно так: подобно прекрасному цветку), конкурентность и параллелизм с их недетерминированным поведением меня просто убивали, и всё было как в тумане. Так что мне легко понять всех приступающих к изучению этих понятий. Спешу избавить вас от мучений и предлагаю вашему вниманию это простое руководство по изучению конкурентности, параллелизма и многопоточности в C++ (в конце данной статьи расписан план, в соответствии с которым мы будем двигаться дальше).
А пока освежим в памяти основные понятия и попробуем на вкус код, выполняемый в многопоточной среде.
1. Что такое поток?
В любом процессе создаётся уникальный поток выполнения, который называется основным потоком. Он может с помощью операционной системы запускать или порождать другие потоки, которые делят то же адресное пространство родительского процесса (сегмент кода, сегмент данных, а также другие ресурсы операционной системы, такие как открытые файлы и сигналы). С другой стороны, у каждого потока есть свой идентификатор потока, стек, набор регистров и счётчик команд. По сути, поток представляет собой легковесный процесс, в котором переключение между потоками происходит быстрее, а взаимодействие между процессами — легче.
2. Что такое конкурентность/параллелизм
Планировщик распределяет процессорное время между разными потоками. Это называется аппаратным параллелизмом или аппаратной конкурентностью (пока что считаем здесь параллелизм и конкурентность синонимами): когда несколько потоков выполняются на разных ядрах параллельно, причём каждый занимается конкретной задачей программы.
→ Примечание: чтобы определить количество задач, которые реально можно выполнять в многопоточном режиме на том или ином компьютере, используется функция std::thread::hardware_concurrency(). Если число потоков будет превышать этот лимит, может начаться настоящая чехарда с переключением задач (когда слишком частые переключения между задачами — много раз в секунду — создают лишь иллюзию многопоточности).
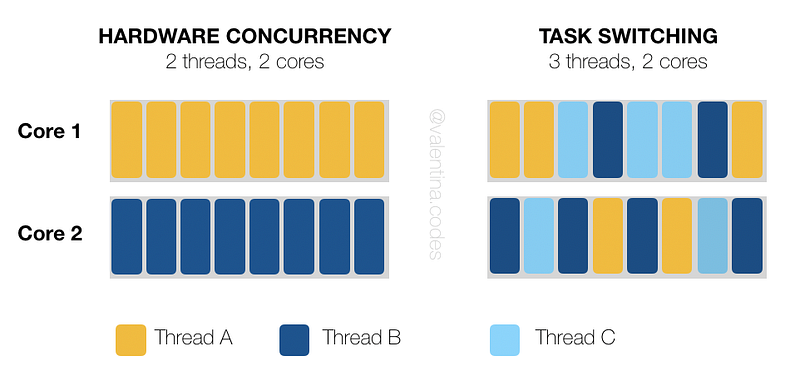
3. Основные операции с потоками с помощью std::thread
- Заголовочный файл|
#include <thread> - Запуск потока|
std::thread t(callable_object, arg1, arg2, ..)Создаёт новый поток выполнения, ассоциируемый с t, который вызываетcallable_object(arg1, arg2). Вызываемый объект (т.е. указатель функции, лямбда-выражение, экземпляр класса с вызовом функцииoperator) немедленно выполняется новым потоком с (выборочно) передаваемыми аргументами. Они копируются по умолчанию. Если хотите передать по ссылке, придётся использовать метод warp к аргументу с помощьюstd::ref(arg). Не забывайте: если хотите передать unique_ptr, то должны переместить его (std::move(my_pointer)), так как его нельзя копировать. - Жизненный цикл потока|
t.join()иt.detach()Если основной поток завершает выполнение, все второстепенные сразу останавливаются без возможности восстановления. Чтобы этого не допустить, у родительского потока имеются два варианта для каждого порождённого:
→ Блокирует и ждёт завершения порождённого потока, вызывая на нём методjoin.
→ Прямо объявляет, что порождённый поток может продолжить выполнение даже после завершения родительского, используя методdetach. - Запомните: объект потока можно перенести, но нельзя копировать.
Здесь вы можете найти пример кода, иллюстрирующий практически всё, что написано выше.
4. Зачем нужна синхронизация?
Из-за того, что несколько потоков делят одно адресное пространство и ресурсы, многие операции становятся критичными, и тогда многопоточности требуются примитивы синхронизации. И вот почему:
- Память — дом с привидениями
Память никогда больше не будет обычным хранилищем данных — теперь это обитель привидений. Представьте: поток смотрит Netflix, уютно устроившись перед Smart TV, и тут вдруг экран мигает и выключается. В панике поток набирает 112, а в ответ… «Доставка пиццы, спасибо, что позвонили». Что происходит? А то, что в доме полно привидений (где в роли привидений другие потоки): они все в одной комнате и взаимодействуют с одними и теми же объектами (это называется гонка данных), но друг для друга они привидения.
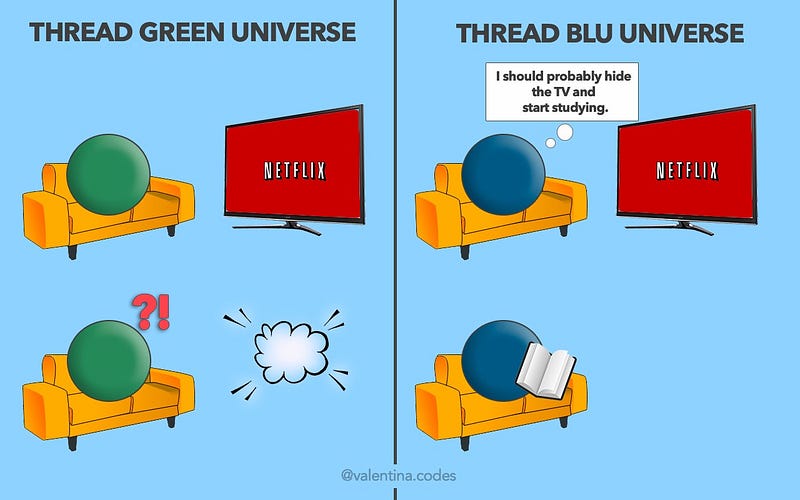
Поток должен объявить, что он использует. А затем, прежде чем трогать этот объект, проверить, не использует ли его кто-то ещё. Зелёный поток смотрит ТВ? Значит, никто не должен трогать ТВ (другие могут рядышком сесть и посмотреть, если что). Это можно сделать с помощью мьютекса.
- Нужны атомарные операции!
Большинство операций неатомарные. Если операция неатомарная, можно увидеть её промежуточное состояние, так как она не является неделимой. Например: запись 64 битов, 32 бита за один раз. Во время этой операции другой поток может увидеть 32 старых бита и 32 новых, получая совершенно неверный результат. По этой причине результаты таких операций должны казаться атомарными, даже если они такими не являются.
→ Примечание: даже инкремент не является атомарной операцией:int tmp = a; a = tmp + 1;Самое простое решение здесь — использовать шаблонstd::atomic, который разрешает атомарные операции разных типов. - Когерентность кеша и выполнение с изменением очерёдности
Каждое ядро пытается сохранить результаты какой-то работы, помещая недавние значения в локальный кеш. Но несколько потоков выполняются на разных ядрах, и значения, хранящиеся в кеше, больше не могут быть валидными, так что рано или поздно кеш должен обновляться. В то же время изменения не видны другим, пока кеш не очищен. Чтобы распространить изменения и обеспечить корректную видимость памяти, нужны определённые механизмы.
Кроме того, для повышения эффективности процессор и/или компилятор может поменять очерёдность выполнения команд. Это может привести к непредсказуемому поведению в параллельно выполняемой программе, в связи с чем необходимо гарантировать исполнение критически важных команд в первоначальном порядке.
Эта работа выполняется примитивами синхронизации, предполагающими использование барьеров доступа к памяти (строки кода, которые не вычеркнуть какими-то операциями) для обеспечения согласованности и предотвращения изменения очерёдности выполнения (инструкции внутри барьеров памяти нельзя вытащить оттуда).
Пример кода
Обратимся к коду. Теперь вы сами можете проверить это недетерминированное поведение многопоточности.
#include <thread>
#include <iostream>
#include <string>
void run(std::string threadName) {
for (int i = 0; i < 10; i++) {
std::string out = threadName + std::to_string(i) + "\n";
std::cout << out;
}
}
int main() {
std::thread tA(run, "A");
std::thread tB(run, "\tB");
tA.join();
tB.join();
}Возможный вывод:
B0
A0
A1
A2
B1
A3
B2
B3
..В отличие от однопоточной реализации, каждое выполнение даёт разный и непредсказуемый результат (единственное, что можно сказать определённо: строки А и B упорядочены по возрастанию). Это может вызвать проблемы, когда очерёдность команд имеет значение.
#include <thread>
#include <iostream>
#include <string>
void runA(bool& value, int i) {
if(value) {
//значение всегда должно быть равным 1
std::string out = "[ " + std::to_string(i) + " ] value " + std::to_string(value) + "\n";
std::cout << out;
}
}
void runB(bool& value) {
value = false;
}
int main() {
for(int i = 0; i < 20; i++) {
bool value = true; //1
std::thread tA(runA, std::ref(value), i);
std::thread tB(runB, std::ref(value));
tA.join();
tB.join();
}
}Возможный вывод:
..
[ 12 ] value 0
[ 13 ] value 1
[ 14 ] value 0
[ 15 ] value 0
[ 16 ] value 0
[ 17 ] value 0
[ 18 ] value 1
[ 19 ] value 0
..Но что здесь происходит? После того как поток А оценивает «значение» как истинное, поток B меняет его. Теперь мы внутри блока if, даже если нарушены ограничения.
Если два потока имеют доступ к одним и тем же данным (один к записи, другой — к чтению), нельзя сказать наверняка, какая операция будет выполняться первой.
Доступ должен быть синхронизирован.
Заключение
Вы можете сказать: «Батюшки! Сколько всего намешано в этой статье!» Просто помните, что не надо пытаться понять всё и сразу, важно ухватить основные идеи.
Предлагаю пока что поиграть с примерами и посмотреть, как в них проявляется многопоточность. Можете подумать над другими примерами, где нужна синхронизация, и протестировать их (подсказка: потоки, удаляющие элементы из начала очереди. Не забывайте: прежде чем удалять, надо проверить, не пуста ли очередь).
План статей
В будущих статьях будут освящены следующие темы:
- Теория + Простые примеры
→ Низкоуровневые подходы
1. Мьютекс
2.std::condition_variable
3. Атомарность
→ Высокоуровневые подходы
3. Future и async
4. Промисы
5.std::packeged_task - Практика + самостоятельная работа и упражнения
valentina-codes/Cpp-Concurrency
A guided tour to learn C++ Multithreading and Concurrency. Theory, code examples and challenges. This repository…github.com
Библиотека C++11 представляет стандартный механизм для синхронизации, независимый от базовой платформы, так что говорить о потоках, выполняемых в Linux и Windows, мы не будем. Тем более, что основные принципы похожи.
В следующей статье рассмотрим примитив синхронизации мьютекса и как его задействовать по максимуму.
Читайте также:
- Языки C и C++. Где их используют и зачем?
- Почему Go прекрасно подходит для DevOps
- Что такого в языке Go?
Перевод статьи: Valentina: [C++] Multithreading and Concurrency: INTRODUCTION





