
Цель использования обработки естественного языка в описываемом проекте — анализ обзоров на товары, оставленных онлайн-покупателями.
Я начал работу над этим проектом для достижения трех бизнес-целей:
- Найти основные компоненты рейтингов, используя неконтролируемое обучение для обработки естественного языка.
- Предсказывать рейтинг товара с помощью контролируемого обучения, основываясь на конкретных отзывах.
- Рекомендовать с помощью алгоритма схожести товары покупателям, основываясь на истории заказов.
Используем набор данных из Kaggle, предоставленный Datafiniti. Более 70,000 отзывов на 1,000 товаров от 58,000 уникальных покупателей.
Сфокусируемся на 2 колонках этого набора данных:
- Рейтинг отзывов по шкале от 1 до 5.
- Сам текст отзывов, в котором покупатели свободно описывают, что им понравилось или не понравилось в товаре.
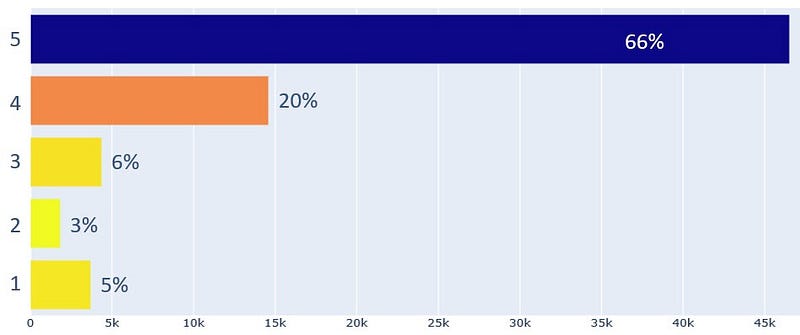
Как распределяются рейтинги?
Большинство покупателей остались довольны, 86% из них ставят оценки 4 и 5.
Какие слова люди используют в своих отзывах?
В заголовках слова ‘великолепно’ и ‘здорово’ появляются довольно часто.

Покупатели также много описывают ‘фильмы’ и ‘товар’, которые они купили. Довольно трудно классифицировать эти отзывы по осмысленным группам, используя неконтролируемое обучение.

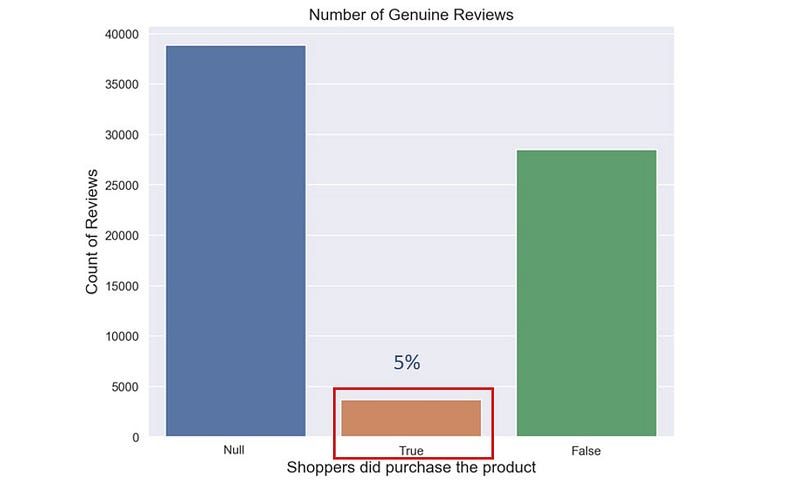
Далее я сосредоточился на 5% всех отзывов от пользователей, которые действительно купили товар — я оцениваю эти отзывы как более подлинные и весомые. В этом наборе данных более 3,680 таких отзывов, и теперь можно произвести некоторый анализ.
Я искал самый популярный товар, который покупали и оценивали чаще всего.
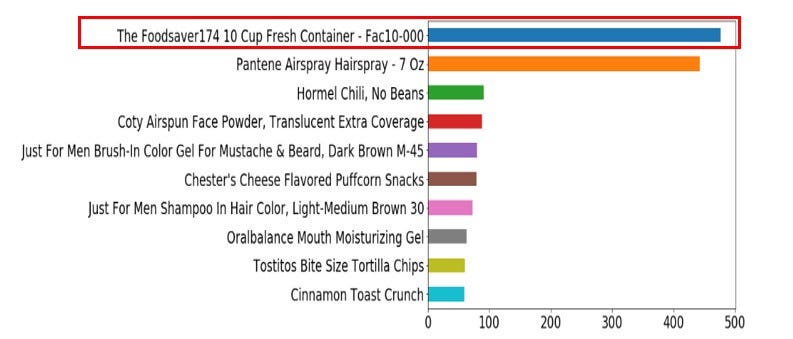
Это контейнеры для еды, заказанные почти 500 раз. Сам товар выглядит так:

Я отфильтровал все рейтинги с оценкой 5 звезд, чтобы найти 3 причины, почему людям нравится этот товар, и произвел латентно-семантический анализ (ЛСА), используя модель Count Vectorizer, в основном подсчитывая частотность слов.
Людям нравится этот товар за функции вакуумной упаковки, которая позволяет сохранять овощи свежими; также товар был доступен к заказу.

Как насчет плохих рейтингов? Я выполнил неотрицательное матричное разложение (НМР), используя TF-IDF Vectorizer, который придает больший вес редким словам.
Люди очень недовольны тем, что функция вакуумной упаковки работает плохо, ее хватает всего на один день.

Резюме из облака слов дает свежую перспективу — многие из этих покупателей считают, что переплатили за товар. Бизнес может использовать эти данные для анализа.

Можно ли использовать машинное обучение для предсказания рейтинга товара на основе этих комментариев? Люди могут читать и понимать комментарии и соотносить их с рейтингами. Как насчет машин?
Я обучил и настроил несколько моделей, такие как логистическая регрессия, случайный лес и XGBoost, соотносить слова в описании с соответствующим рейтингом.

Также можно сделать и рекомендации товаров. Бизнес может рекомендовать товары, основываясь на истории покупок и рейтингах, оставленных покупателем.
Вот 3 похожих покупателя, в результате могут быть рекомендованы товары “пустого пространства”.
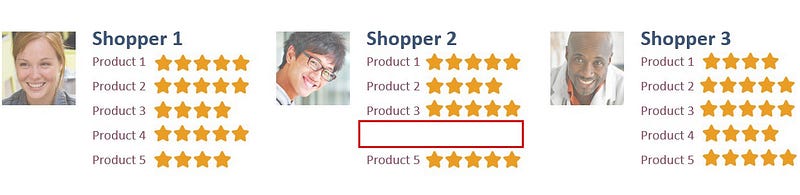
Например, “Джесс” купила несколько семейных фильмов. Применяя тот же алгоритм, модель рекомендует “похожие” фильмы — триллеры и анимационные фильмы. Бизнес может использовать эти результаты для стимулирования продаж.

В итоге, обработка естественного языка может использоваться для:
- описательной аналитики (неконтролируемое обучение);
- предсказательной аналитики (контролируемое обучение);
- нормативной аналитики (алгоритм схожести).
Код на Python описанного анализа доступны на моем GitHub.
Читайте также:
- Распознавание лиц с помощью CoreML и ARKit
- Обратные вызовы Keras за 2 минуты
- Распознавание лиц с помощью OpenCV
Перевод статьи Black Raven: Natural Language Processing (NLP) to analyse product reviews by online shoppers





