
Golang использует горутины для параллельного программирования. На них можно ссылаться как на подзадачи для приложения. Если вы новичок в Golang, то рекомендую для начала ознакомиться с концепцией горутин.
Горутинам необходимы механизмы для связи между собой — каналы, которые гарантируют, что горутины и основной поток могут взаимодействовать друг с другом.
В этой статье мы поговорим о создании и обмене данными с помощью каналов.
Введение в базовые каналы
Каналы привносят в программу большую гибкость и решают проблемы, связанные с параллелизмом. Общие характеристики каналов:
- Они являются механизмом связи.
- Их можно отправить в качестве параметров в различные горутины.
- Они работают и как публикатор, и как подписчик.
Изоляция памяти в Golang
Раньше приложения использовались для глобального хранения данных и должны были отслеживать манипулирование данными различными потоками/подпроцессами, что приводило к многочисленным проблемам, связанным с синхронизацией данных.
Golang предоставляет каналы для безопасного конвейера потока информации, в котором только один подпроцесс может воздействовать на доступные данные. Данные внутри канала Go доступны только для одной горутины, а отправитель и получатель данных находятся в отношениях «один на один».
Шаг 1: создание базовых каналов
package main
import "fmt"
func main() {
dataChannel := make(chan string)
fmt.Println(<-dataChannel)
}Рассмотрим детали приведенного выше кода:
- Ключевое слово
makeиспользуется для создания нового объекта. - Мы указываем тип объекта, созданного с помощью
chan. - Мы указываем тип данных, возвращаемый из канала с помощью строки.
В строке 6 мы создали объект типа channel, который можно использовать для передачи данных string в рамках горутин.
Ожидание данных из канала
В строке 7 мы сообщаем основной функции о необходимости подождать, пока канал не получит данные. В вышеприведенной программе нет горутин, отправляющих данные на канал. Из-за отсутствия другого доступного канала программа блокируется в ожидании получения данных.
Рассмотрим следующий вывод:
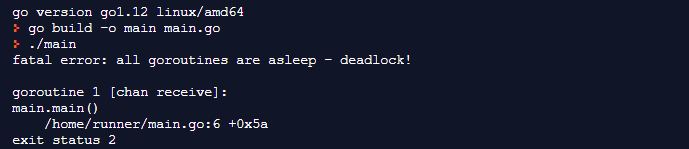
Мы видим, что программа блокировалась, поскольку основной поток продолжал ожидать данные в канале в строке 7.
Шаг 2: добавление данных в канал
В приведенном выше коде мы создали канал и ожидали доступные данные для канала. Поскольку данные не были доступны, программа блокировалась.
Следующим шагом будет наполнение канала данными в той же основной функции. Рассмотрим результат:
package main
import "fmt"
func main() {
dataChannel := make(chan string)
dataChannel <- "Some Sample Data"
fmt.Println(<-dataChannel)
}
Здесь мы добавляем выборочные данные в канал. Как вы думаете, можем ли мы теперь получать данные с канала?
Давайте посмотрим на вывод:
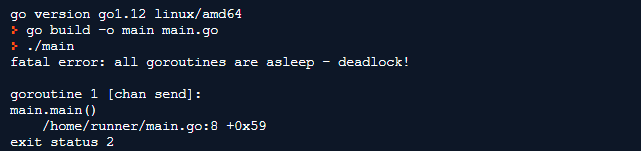
Как видим, программа снова заблокирована. В чем же причина?
В приведенном выше коде мы добавляем данные в канал. Как только мы отправляем данные, поток блокируется до тех пор, пока другой поток не сможет получить входящие данные. Из-за отсутствия другого потока, который смог бы получать данные из канала, основной поток блокируется. Он так и не выполняется, что приводит к тупиковой ситуации в строке 8.
Шаг 3: выход из блокировки
Повторюсь: по умолчанию каналы не могут хранить информацию, поэтому сообщение должно сразу передаваться от отправителя к получателю. При отсутствии получателя сообщение застревает.
Добавляя буфер в канал, мы предоставляем ему возможность сохранения некоторых сообщений, позволяя отправителю продолжить свою работу, даже если данные не извлекаются на другом конце.
Таким образом, чтобы избежать блокировки можно использовать буферизованные каналы.
Создание буферизованных каналов
Чтобы поток продолжал выполняться, даже если данные не извлекаются с другого конца, необходимо предоставить буфер для канала.
Рассмотрим на примере:
package main
import "fmt"
func main() {
dataChannel := make(chan string, 3)
dataChannel <- "Some Sample Data"
dataChannel <- "Some Other Sample Data"
dataChannel <- "Buffered Channel"
fmt.Println(<-dataChannel)
fmt.Println(<-dataChannel)
fmt.Println(<-dataChannel)
}Здесь мы создаем канал с буфером.
Значение буфера помечено как 3. Это означает, что канал может хранить три строковых значения.
В приведенном выше коде мы добавляем данные в канал, поэтому их не нужно удалять. Поскольку он буферизован, основной канал продолжит работу при добавлении большего количества данных.
Когда буфер заполнится, нужно будет удалить данные, иначе программа снова заблокируется.
Таким образом, добавляя буферы, мы позволяем потоку сохранять данные в канале, которые могут быть удалены позже во время выполнения, и устраняем блокировку. Рассмотрим следующий вывод:

На этом краткое введение в каналы в Golang окончено. Спасибо за внимание!
Читайте также:
- Разбираемся с компилятором Go
- Как реализовать древовидную сортировку в стандартной библиотеке Go
- Как я встраивал ресурсы в Go
Перевод статьи Mayank Gupta: Getting Started With Golang Channels





