
В этой статье мы докажем, что использование Nuclio и RAPIDS, бесплатной open-source платформы для ускорения обработки данных от NVIDIA, может значительно увеличить производительность Python.
Я продемонстрирую самый популярный вариант использования обработки живых данных, состоящих из журналов на основе Json. Мы выполним несколько аналитических задач и получим агрегированные результаты в сжатом формате Parquet для дальнейших запросов или обучения МО. Помимо этого, мы рассмотрим потоковую передачу в пакетном режиме и в реальном времени (с простым кодом Python!).
Что делает Python медленным и не масштабируемым?
При работе с pandas над небольшим набором данных мы получаем приличную производительность, если весь набор помещается в память, а обработка выполняется с помощью оптимизированного кода C под слоем pandas и NumPy. Обработка большого количества данных требует интенсивного ввода-вывода, преобразования и копирования данных и т. д., которые выполняются медленно. По своей природе Python является синхронным ЯП из-за печально известного GIL и очень неэффективен при работе со сложными задачами. Асинхронный Python — лучший выбор, однако он усложняет разработку и не решает проблемы блокировки.
Преимущество таких фреймворков, как Spark, заключается в наличии асинхронных движков (Akka) и оптимизированных для памяти структур данных. Они могут распределять работу между несколькими воркерами на разных машинах, что приводит к повышению производительности и масштабируемости.
Ускорение Python с RAPIDS
Разработчики из NVIDIA придумали блестящую идею: сохранить API-интерфейсы Python для популярных фреймворков, таких как pandas, Scikit-learn и XGBoost, но обрабатывать данные в высокопроизводительном C-подобном коде в графическом процессоре. Они приняли удобный для памяти формат данных Apache Arrow, ускоряющий передачу данных и манипулирование ими.
RAPIDS поддерживает ввод-вывод (cuIO) и анализ данных (cuDF), а также машинное обучение (cuML). Эти различные компоненты совместно используют одни и те же структуры памяти, поэтому конвейер обработки данных, аналитики и МО работают без копирования данных в ЦП.
В следующем примере продемонстрировано чтение большого файла Json (1,2 ГБ) с агрегированием данных с помощью API pandas. Как можно заметить, один и тот же код работает в 30 раз быстрее с помощью RAPIDS (полная версия notebook). С вычислениями без ввода-вывода скорость будет в 100 раз быстрее, что освобождает место для более сложных вычислений.

Мы использовали один графический процессор (NVIDIA T4), который увеличивает стоимость сервера примерно на 30% и обеспечивает 30-кратное увеличение производительности, и обработали 1 гигабайт сложных данных за секунду, используя несколько строк кода Python!
Если упаковывать этот код в бессерверную функцию, то он сможет запускаться при каждом запросе пользователя или периодически, а также считывать или записывать в динамически прикрепленные тома данных.
Возможна ли потоковая передача в реальном времени с Python?
Следующий код, взятый из руководств по лучшим практикам Kafka, читает из потока и выполняет минимальную обработку:
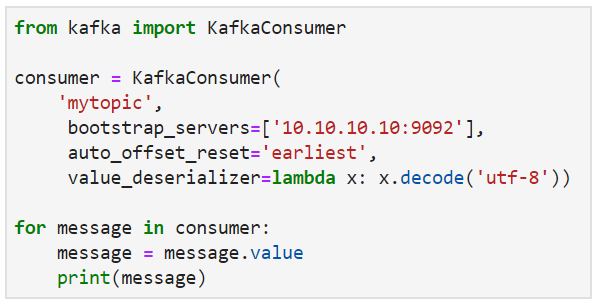
Проблема заключается в том, что Python по своей природе является синхронным и довольно неэффективным ЯП при работе в режиме реального времени или сложных манипуляциях с данными. Эта программа генерирует пропускную способность всего в несколько тысяч сообщений в секунду. При добавлении обработки json и pandas, используемой в предыдущем примере (notebook), производительность снижается еще больше, а скорость обработки составляет лишь 18 МБ/с. Стоит ли вернуться к использованию Spark?
Подождите.
Nuclio — самый быстрый бессерверный фреймворк, который также является частью Kubeflow (фреймворк Kubernetes ML). Он работает с различными ЯП в режиме реального времени, обладает высокопроизводительной параллельной системой, выполняет несколько экземпляров кода параллельно (с эффективными микропотоками) без дополнительного написания кода, а также управляет автоматическим масштабированием внутри процесса и между несколькими процессами/контейнерами.
Nuclio управляет обработкой потоков и доступом к данным в высоко оптимизированном двоичном коде и вызывает функции через простой обработчик. Он поддерживает 14 различных протоколов запуска и потоковой передачи (включая HTTP, Kafka, Kinesis, Cron, batch), которые указываются в конфигурации (без изменения кода), а также быстрый доступ к внешним томам данных. Одна функция Nuclio может обрабатывать сотни тысяч сообщений в секунду и обладает пропускной способностью более гигабайта в секунду.
Но самое главное, Nuclio — единственный на сегодняшний день бессерверный фреймворк с оптимизированной поддержкой графических процессоров NVIDIA.
Ускоренная в 30 раз обработка потока без Devops
Попробуем объединить Nuclio и RAPIDS, чтобы насладиться всеми преимуществами ускоренной обработки потоковой передачи на базе Python. Следующий код не сильно отличается от варианта с пакетной обработкой, мы просто поместили его в обработчик функций и собрали входящие сообщения в большие пакеты, чтобы выполнять меньше вызовов GPU (полная версия notebook).
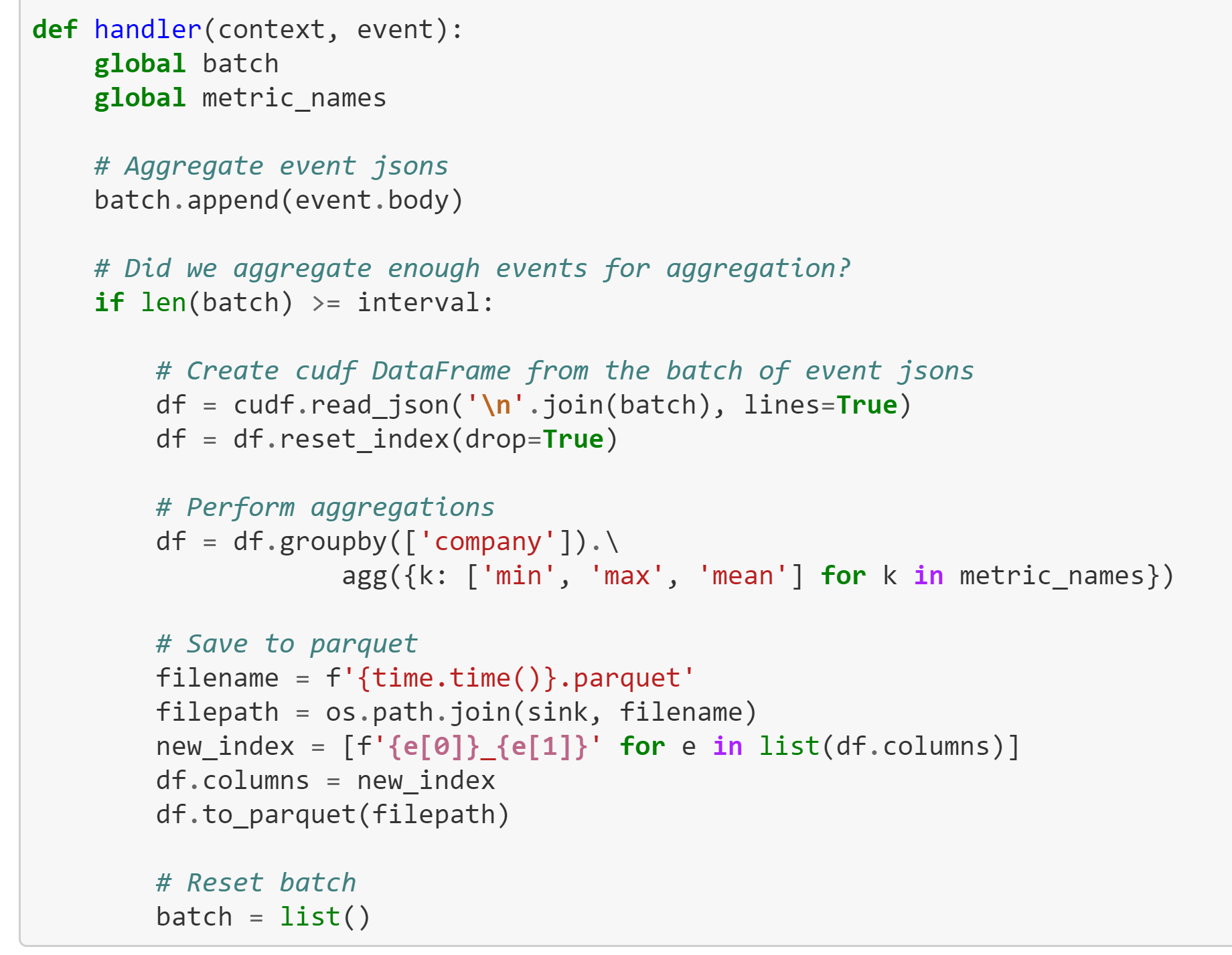
Эту функцию также можно протестировать с помощью триггера HTTP или Kafka: в обоих случаях Nuclio будет обрабатывать параллелизм и распределять потоковые разделы на несколько воркеров без дополнительной работы со стороны разработчика. Мы протестировали установку с использованием 3-х узлового кластера Kafka и одного функционального процесса Nuclio (на сервере Intel с двумя сокетами и одним NVIDIA T4). Нам удалось обработать 638 МБ/с, что в 30 раз быстрее, чем при написании клиента Python Kafka, а полученный код автоматически масштабируется для обработки любого объема трафика.
В данном тесте были использованы не все возможности графического процессора, соответственно мы можем выполнять более сложные вычисления с данными (объединения, предсказания МО, преобразования и т.д.), при этом сохраняя те же уровни производительности.
Таким образом, мы ускорили производительность с меньшими затратами на разработку, однако истинное преимущество бессерверных решений заключается в самой «бессерверности». Возьмите тот же код, разработайте его в notebook (пример) или в IDE, и с помощью одной команды он будет собран, упакован и отправлен в кластер Kubernetes с полным набором инструментов (журналы, мониторинг, автоматическое масштабирование и т.д.)
Nuclio интегрируется с конвейерами Kubeflow. Создавая многоуровневый конвейер данных или МО, вы сможете автоматизировать рабочий процесс по обработке данных с минимальными усилиями, а также собрать метаданные о выполнении и артефактах для воспроизведения результатов эксперимента.
Здесь можно скачать Nuclio и развернуть его на Kubernetes (примеры RAPIDS).
Читайте также:
Перевод статьи yaron haviv: Python Pandas at Extreme Performance





