
Опытный ли вы инженер-программист или студент, пишущий университетский проект, в какой-то момент вам нужно будет выбрать базу данных для ваших целей.
Если вы ранее уже использовали какую-то БД, вы можете просто сказать: “Я выберу эту базу, потому что знаком с ней”. Это вполне подходящее решение, когда производительность не критична для вашего проекта. В противном случае выбор неподходящей базы станет препятствием при расширении проекта. Исправить ошибку может быть довольно сложно. Даже если вы работаете в зрелом проекте, который использует конкретную БД, важно знать ее ограничения и понимать, когда стоит добавить базу другого типа к вашему стеку. Комбинирование нескольких баз данных довольно распространено.
Еще одна причина разобраться с базами данных и их свойствами: вопросы о БД очень распространены на собеседованиях. Когда вам будет нужна короткая шпаргалка, прокрутите в конец поста.
Реляционные базы данных
Эти базы состоят из связанных между собой таблиц. Каждая строка таблицы представляет собой запись. Почему такие базы называются реляционными? Потому, что они строятся на отношениях между объектами, описанными в БД.
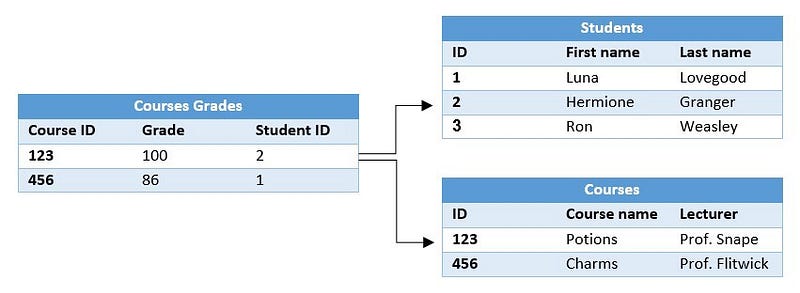
Допустим, у вас есть таблица с информацией о студентах и таблица оценок курса (курс, оценка, идентификатор студента). Каждая строка с оценкой соотноситсяс записью о студенте. На диаграмме ниже значение в столбце Student ID указывает на строки в таблице Students по их значению в столбце ID.
Все данные из реляционных баз данных запрашиваются с помощью SQL-подобных языков, имеющих встроенную поддержку операции объединения. Реляционные базы позволяют индексировать столбцы для быстрых запросов. Из-за своей структурированной природы, схема реляционных баз данных определяется до ввода данных. Примеры таких баз:
- MySQL.
- PostgreSQL.
- Oracle.
- MS SQL Server.
NoSQL базы данных
В реляционных базах данных все структурировано по колонкам и столбцам. В свою очередь, в нереляционных базах нет общей структурированной схемы для записей. Большая часть NoSQL баз содержит JSON записи. Разные записи могут содержать разные поля.
Это семейство БД называется NoSQL (Not only SQL — не только SQL), так как многие NoSQL базы данных поддерживают SQL, но это не самый лучший вариант их использования. Cуществует 4 типа баз данных NoSQL.
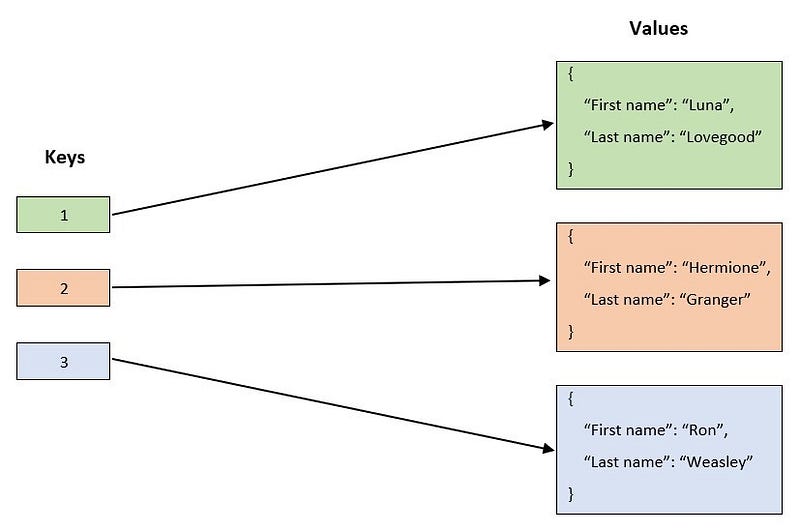
Документные
Атомарной (неделимой) единицей таких БД является документ. Каждый документ — JSON, схема может различаться в разных документах и содержать разные поля. Документные БД позволяют индексировать некоторые поля документа для ускорения запросов на основе этих полей. Следовательно, во всех документах есть поля.
Использование
Поскольку различные записи независимы друг от друга (логически и структурно), эти базы данных поддерживают параллельные вычисления, что позволяет легко анализировать большой объём данных. Примеры:
- MongoDB
- CouchDB
- DocumentDB

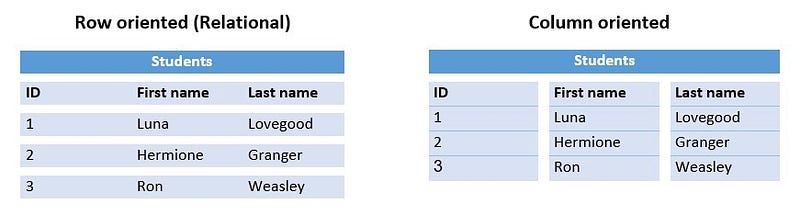
Колоночные
Атомарная единица таких БД — колонка таблицы. Данные сохраняются столбец за столбцом, что делает колоночные запросы очень эффективными, и, поскольку данные в каждой колонке однородны, это позволяет лучше сжимать данные.
Использование
В тех случаях, когда удобно делать запросы к подмножеству столбцов (оно не обязательно должно быть одинаковым каждый раз!). Колоночные БД обрабатывают такие запросы очень быстро, так как читают только конкретные колонки (в то время как строчные БД должны читать строки полностью).
В науке о данных часто бывает, что каждая колонка представляет определенную характеристику. Как специалист по данным я часто тренирую свои модели на подмножествах характеристик и проверяю отношения между ними и оценками (корреляция, дисперсия, значимость). То же подходит и для логов— в них зачастую множество полей, но при каждом запросе используются только некоторые. Например:
- Cassandra.
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.
Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached
Графовые
Содержат узлы, отображающие объекты, а также ребра, отображающие отношения между ними.
Использование
Созданы для работы с графовыми данными, такими как сети знаний или социальные сети. Примеры баз:
- Neo4j
- InfiniteGraph

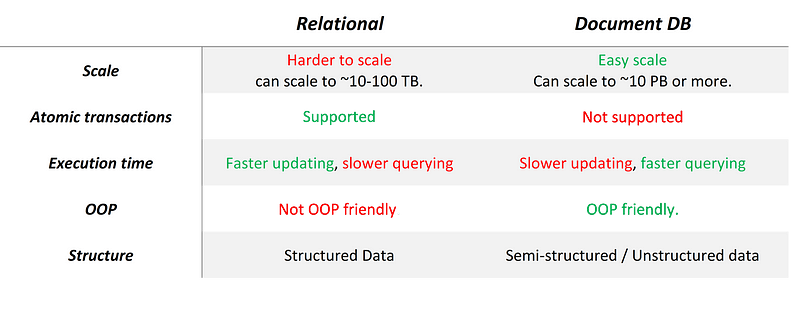
Реляционные или документные?
Как вы уже догадались, универсального решения нет. Самые распространенные БД для регулярного использования — реляционные и документные. Давайте сравним их.
Достоинства реляционных баз
- Имеют простую структуру, которая подходит к большинству типов данных.
- Используют SQL, который широко распространен и по умолчанию поддерживает операции объединения.
- Позволяют быстро обновлять данные. Вся БД хранится на одном компьютере, а отношения между записями используются как указатели, то есть вы можете обновить одну запись — и все связанные с ней записи немедленно обновятся.
- Реляционные БД также поддерживают атомарные транзакции. Что это? Предположим, я хочу перевести X долларов от Алисы к Бобу. Я хочу осуществить 3 действия: уменьшить баланс Алисы на X, увеличить баланс Боба на X и задокументировать транзакцию. Я могу назначить эти действия атомарной единицей БД — или произойдут все действия, или ни одно. Это защищает от ошибок при сбоях.
Недостатки реляционных баз
- Поскольку каждый запрос выполняется к целой таблице, время выполнения запроса зависит от размера таблицы. Это важное ограничение, которое заставляет нас сохранять таблицы относительно небольшими и проводить оптимизацию БД для ее масштабирования.
- Масштабирование осуществляется добавлением вычислительных мощностей к компьютеру, на котором установлена БД, этот метод называется вертикальное масштабирование. Почему это недостаток? Потому, что существует предел вычислительной мощности компьютера, добавление ресурсов провоцирует простой.
- Не поддерживаются объекты на основе ООП, даже представление простых списков очень сложно.
Достоинства документных баз
- Позволяют хранить объекты с разной структурой.
- Могут отображать почти все структуры данных, включая объекты на основе ООП, списки и словари, используя старый добрый JSON.
- Несмотря на то, что NoSQL не схематичны по своей природе, они часто поддерживают проверку схемы. Это значит, что вы можете сделать коллекцию со схемой. Эта схема не будет простой, как таблица: это будет JSON схема со специфическими полями.
- Запросык NoSQL очень быстрые — каждая запись независима и, следовательно, время запроса не зависит от размера базы. По той же причине эта БД поддерживает параллельность.
- В NoSQL масштабирование БД осуществляется добавлением компьютеров и распределением данных между ними, этот метод называется горизонтальное масштабирование. Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
Недостатки документных баз
- Обновлениеданных —медленный процесс в документной БД, потому что данные могут быть распределены между компьютерами и могут дублироваться.
- Атомарные транзакции по умолчанию не поддерживаются. Вы можете сами добавить их в код, используя механизм проверки и возврата, но, поскольку записи распределены между компьютерами, транзакция не может быть атомарной единицей, а значит, может возникнуть состояние гонки.
Шпаргалка
- Для кэширования используем БД типа ключ-значение.
- Для графов— графовые БД.
- Если удобно делать запросы по колонкам или характеристикам — колоночные БД.
- Для всех остальных случаев реляционные или документные базы данных.
Читайте также:
- Шесть рекомендаций для начинающих специалистов по Data Science
- Почему за способностью объяснения модели стоит будущее Data Science
- Как составить Data Science портфолио? Часть 1
Перевод статьи Tzoof Avny Brosh: How to Choose the Right Database





