
Open Data Barcelona — это сервис, предоставляющий наборы данных Барселоны, который содержит около 400 наборов, охватывающих широкий спектр тем, таких как население, бизнес и жилье. Проект был создан в 2010 году с целью повышения доступности государственных ресурсов.
В этой статье используется набор данных о происшествиях, зарегистрированных местной полицией в городе Барселона в 2017 году. Набор включает в себя такую информацию, как количество травм, степени их тяжести, количество задействованных транспортных средств, дата и географическое положение места происшествия.
Поскольку набор данных написан на каталанском языке, мы будем использовать английскую версию, доступную в Kaggle.
Исследовательский анализ и очистка данных
Исследовательский анализ данных состоит из анализа основных характеристик набора данных с помощью методов визуализации и получения сводной статистики. Цель заключается в том, чтобы понять данные, обнаружить шаблоны, аномалии и проверить допущения, прежде чем перейти к оценке.
Скачиваем файл csv на Kaggle, загружаем его в dataframe Pandas с помощью функции pandas.read_csv и визуализируем первые 5 строк с помощью метода pandas.DataFrame.head.
import pandas as pd
df = pd.read_csv('accidents_2017.csv')
df.head()
Dataframe содержит 15 столбцов: id, название округа, район, улица, день недели, месяц, день, час, часть дня, легкие травмы, серьезные травмы, жертвы, задействованные транспортные средства, долгота, широта.
Напечатать список с названиями столбцов можно с помощью метода pandas.DataFrame.columns. Помимо этого, метод pandas.DataFrame.info предоставляет информацию о dataframe, включая типы столбцов, ненулевые значения и использование памяти.
# Список названий столбцов
list(df.columns)
# ['Id','District Name','Neighborhood Name','Street','Weekday','Month','Day','Hour','Part of the day','Mild injuries','Serious injuries','Victims','Vehicles involved','Longitude','Latitude']
# Информация о dataframe: названия и типы столбцов, нулевые значения и использование памяти.
df.info()
Судя по всему, нулевые значения в таблице отсутствуют, поскольку во всех столбцах содержится 10339 позиций. Однако в некоторых позициях есть строка Unknown. Мы можем заменить эту строку нечисловым значением и повторно оценить количество нулевых значений с помощью метода pandas.DataFrame.info.
import numpy as np
# По-видимому, нулевые значения отсутствуют.
df.isnull().sum().any()
# False
# замена Unknown на n.a
df.replace('Unknown',np.nan, inplace=True)
# Появление нулевых значений
df.isnull().sum().any()
# True
# Получение доступа к нулевым значениям с помощью метода info().
df.info()
Только столбцы District Name и Neighborhood Name содержат нулевые значения. Поскольку эти столбцы не будут использоваться в дальнейшем анализе, учитывать эти значения не нужно. Мы будем проводить анализ места происшествия, используя долготу (Longitude) и широту (Latitude).
Прежде чем перейти к выводам на основе данных, необходимо провести очистку. Первый этап очистки состоит в удалении ненужных столбцов для упрощения таблицы данных.
# Удаление ненужных столбцов.
df.drop(['District Name','Neighborhood Name','Part of the day'],axis=1 ,inplace=True)
# Столбцы после удаления.
df.columns
# 'Id', 'Street', 'Weekday', 'Month', 'Day', 'Hour', 'Mild injuries','Serious injuries', 'Victims', 'Vehicles involved', 'Longitude','Latitude'После удаления столбцов модифицируем некоторые типы данных. Просмотреть типы данных можно с помощью метода pandas.DataFrame.info или атрибута pandas.DataFrame.dtypes. Последний возвращает Series с типом данных каждого столбца.

Месяц, день и час не являются объектами datetime, поэтому объединяем их в один столбец, используя функцию pandas.to_datetime. Перед использованием этой функции модифицируем названия столбцов, заменяя пробелы подчеркиванием, а заглавные буквы строчными. Кроме того, включаем столбец с указанием года.
# Изменяем названия столбцов. Заменяем пробелы подчеркиванием и заглавные буквы строчными.
df.rename(columns=lambda x:x.replace(' ','_').lower(), inplace=True)
# Новые названия столбцов
df.columns
# Index(['id', 'street', 'weekday', 'month', 'day', 'hour', 'mild_injuries','serious_injuries', 'victims', 'vehicles_involved', 'longitude','latitude'],dtype='object')
# Добавляем столбец с годом (в данном случае 2017)
df['year'] = np.repeat(2017,df.shape[0])
# первые строки после добавления года
df.head()
Тепер объединяем день недели, месяц, день, час и год в один столбец с названием date. Чтобы избежать ошибки ValueError, необходимо преобразовать названия месяцев в целые числа перед использованием функции pandas.to_datetime.
# Получаем названия месяцев
list(df.month.unique())
# ['October','September','December','July','May','June','January','April','March','November','February','August']
# Названия месяцев в int
month_to_int = {'January':1,'February':2,'March':3,'April':4,'May':5,'June':6,'July':7,'August':8,'September':9,'October':10,'November':11,'December':12}
# Преобразуем названия месяцев в числа
df['month'].replace(month_to_int,inplace=True)
# Получаем новые названия месяцев
list(df.month.unique())
# [10, 9, 12, 7, 5, 6, 1, 4, 3, 11, 2, 8]После преобразования составляем столбец datetime, используя вышеупомянутую функцию следующим образом:
# Объединяем столбцы месяц, день, час и год, чтобы создать один столбец datetime.
df['date']=pd.to_datetime(df[['year', 'month', 'day','hour']])
# Просматриваем первые 5 столбцов.
df.head()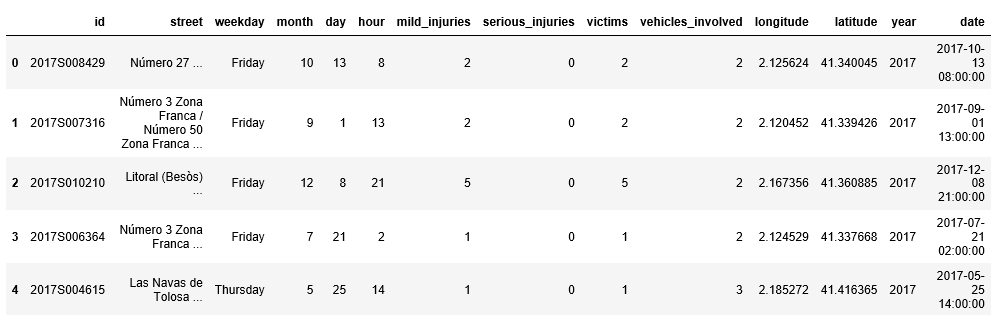
Проверить тип данных столбца date можно с помощью атрибута pandas.DataFrame.dtypes.
# Проверяем тип данных столбца date
df.date.dtypes
# dtype('<M8[ns]')Для получения доступа к отдельным элементам date, таким как месяц, день или час, используем атрибут pandas.Series.dt. Получить доступ к дню недели можно с помощью атрибута pandas.Series.dt.dayofweek, где Monday=0 и Sunday=6. ?
# Извлекаем год
df['date'].dt.year
# Извлекаем месяц
df['date'].dt.month
# Извлекаем день
df['date'].dt.day
# Извлекаем час
df['date'].dt.hour
# Извлекаем день недели
df['date'].dt.dayofweek
# День недели - первые пять элементов возвращенной serie.
df['date'].dt.dayofweek.head()
Поскольку получить доступ ко всей необходимой информации, связанной с датой аварии, можно с помощью атрибута pandas.Series.dt, то удаляем столбцы месяц, год, час, день и день недели, поскольку они больше не нужны.
# Удаляем столбцы час, день, месяц, год, день недели
df.drop(['hour','day','month','year','weekday'], axis=1, inplace=True)
# Столбцы Dataframe
list(df.columns)
# ['id','street','mild_injuries','serious_injuries','victims','vehicles_involved','longitude','latitude','date']Теперь можно отбросить столбец street, поскольку мы будем визуализировать место происшествия с помощью долготы и широты.
# Удаляем столбец street
df.drop(['street'], axis=1, inplace=True)
# Первые 5 строк dataframe
df.head()
Полученный dataframe содержит 8 столбцов: id, mild_injuries, serious_injuries, victims, vehicles_involved, longitud, latitude и date.
Для получения доступа к информации об автоаварии устанавливаем id в качестве индекса dataframe, удалив конечные пробелы в записях id.
# Мы заметили наличие пробелов у id в конце строки
df.id.loc[0]
# '2017S008429 '
# Удаляем пробелы в записях id
df.id = df.id.apply(lambda x: x.strip())
# Мы успешно удалили пробелы
df.id.loc[0]
# '2017S008429'
# Устанавливаем id в качестве индекса dataframe
df.set_index('id', inplace=True)
# Теперь можно получить доступ к информации об аварии с помощью id.
df.loc['2017S008429']
Заключительный этап очистки состоит в оценке наличия дублированных записей в data frame, которые необходимо удалить, поскольку они представляют одну и ту же автоаварию.
# Оцениваем, содержит ли dataframe дублированные строки.
df.duplicated().sum()
# 9
# Печатаем дублированные строки.
df[df.duplicated()]
# Форма dataframe до удаления дублированных столбцов.
df.shape
# (10339, 7)
# Удаление дубликатов.
df.drop_duplicates(inplace=True)
# Форма после удаления дубликатов.
df.shape
#(10330, 7)Очистка данных завершена! ? Теперь можно перейти к ответам на вопросы и получению выводов на основе данных. ? ?
Ответы на вопросы и получение выводов
Исследовательский анализ данных и очистка данных — это шаги, позволяющие получить представление о наборе данных и подготовить его к получению выводов на его основе. Теперь мы готовы ответить на следующие вопросы:
Анализ времени
Сколько происшествий было зарегистрировано полицией в Барселоне в 2017 году?
Получить общее количество зарегистрированных происшествий в Барселоне можно с помощью атрибута pandas.DataFrame.shape, поскольку каждая запись в dataframe представляет определенную автомобильную аварию.
print('Total number of accidents in 2017 :{}'.format(df.shape[0]))
# Общее число происшествий в 2017 :10330В 2017 году полиция зарегистрировала 10330 несчастных случаев в Барселоне.
Распределение автомобильных аварий по месяцам
Для анализа распределения автомобильных аварий по месяцам используем функцию pandas.DataFrame.groupby. Операция groupby включает в себя комбинацию разделения объекта, применения функции и объединения результатов. Сначала выполняем группировку по месяцам, а затем вычисляем количество происшествий в каждом месяце. Чтобы интерпретировать результат, используем гистограмму следующим образом:
import calendar
# Количество происшествий в месяц
accidents_month = df.groupby(df['date'].dt.month).count().date
# Замена целых чисел месяца названиями месяцев.
accidents_month.index=[calendar.month_name[x] for x in range(1,13)]
accidents_month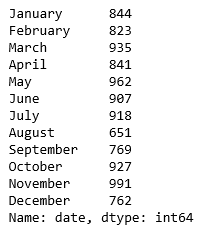
import matplotlib.pyplot as plt
% matplotlib inline
plt.style.use('ggplot')
# график происшествий за месяц
accidents_month.plot(kind='bar',figsize=(12,7), color='blue', alpha=0.5)
# заголовок и метки x, y
plt.title('Accidents in Barcelona in 2017', fontsize=20)
plt.xlabel('Month',fontsize=16)
plt.ylabel('Number of accidents',fontsize=16);
Можно заметить, что количество несчастных случаев уменьшается в августе и декабре. Одна из причин может заключаться в том, что меньшее количество людей ездит на работу в эти месяцы.
Распределение автомобильных аварий по дням недели
Как и в случае с месяцами, проанализировать распределение автоаварий по дням недели можно с помощью гистограммы.
# Количество происшествий в день недели
accidents_day = df.groupby(df['date'].dt.dayofweek).count().date
# Замена целых чисел дня названиями дней.
accidents_day.index=[calendar.day_name[x] for x in range(0,7)]
# график происшествий за день
accidents_day.plot(kind='bar',figsize=(12,7), color='magenta', alpha=0.5)
# заголовок и метки x, y
plt.title('Accidents in Barcelona in 2017', fontsize=20)
plt.xlabel('Day of the week',fontsize=16)
plt.ylabel('Number of accidents',fontsize=16);
Как показано на графике выше, количество автомобильных аварий уменьшается в выходные дни. В будние дни происходит в среднем 1656 дорожно-транспортных происшествий в день, примерно на 600 больше, чем в выходные дни (в среднем 1025 происшествий в день).
Следующий график демонстрирует количество происшествий в течение каждого дня года. Можно заметить, что в день происходит от 10 до 50 несчастных случаев, а число происшествий в пятницу, как правило, намного выше, чем в воскресенье.
accidents = df.groupby(df['date'].dt.date).count().date
accidents.plot(figsize=(13,8), color='blue')
# аварии по воскресеньям
sundays = df.groupby(df[df['date'].dt.dayofweek==6].date.dt.date).count().date
plt.scatter(sundays.index, sundays, color='green', label='sunday')
# аварии по пятницам
friday = df.groupby(df[df['date'].dt.dayofweek==4].date.dt.date).count().date
plt.scatter(friday.index, friday, color='red', label='friday')
# Заголовок, метка x и метка y
plt.title('Accidents in Barcelona in 2017', fontsize=20)
plt.xlabel('Date',fontsize=16)
plt.ylabel('Number of accidents per day',fontsize=16);
plt.legend()
Распределение автомобильных аварий в час
Выполнив те же шаги, что и выше, создаем график распределения автомобильных аварий по времени.
# Количество происшествий в час
accidents_hour = df.groupby(df['date'].dt.hour).count().date
# график происшествий в час
accidents_hour.plot(kind='bar',figsize=(12,7), color='orange', alpha=0.5)
# заголовок и метки x, y
plt.title('Accidents in Barcelona in 2017', fontsize=20)
plt.xlabel('Hour',fontsize=16)
plt.ylabel('Number of accidents',fontsize=16);
В соответствии с графиком большее количество несчастных случаев происходит ранним утром с 8 до 9 и между 12 и 20 часами.
Распределение автоаварий по дням недели и часам
Мы также можем проанализировать количество происшествий за день недели и час, используя графики, стоящие рядом друг с другом. Используем горизонтальный график для лучшей визуализации.
# Количество аварий в час и день
accidents_hour_day = df.groupby([df['date'].dt.hour.rename('hour'),df['date'].dt.dayofweek.rename('day')]).count().date
accidents_hour_day.unstack().plot(kind='barh', figsize=(16,26))
# заголовок и метки x, y
plt.legend(labels=[calendar.day_name[x] for x in range(0,7)],fontsize=16)
plt.title('Accidents in Barcelona in 2017',fontsize=20)
plt.xlabel('Number of accidents',fontsize=16)
plt.ylabel('Hour',fontsize=16);
Как можно заметить, в вечера выходных происходит больше аварий, чем в будние дни. С другой стороны, с раннего утра до полудня в будние дни происходит гораздо больше несчастных случаев, чем в выходные дни.
Анализ времени — выводы
- В августе 2017 года произошло наименьшее количество автомобильных аварий — 651. В остальные месяцы число несчастных случаев составляет около 800–900.
- Количество автомобильных аварий уменьшается по выходным.
- Большее количество автомобильных аварий происходит в промежутки с 8 до 9 и с 12 до 20.
- По вечерам большинство несчастных случаев случаются в выходные дни.
Можно также выполнить группировку по разным временным переменным и создать более комплексные графики, чтобы извлечь более сложные шаблоны и выводы относительно зависимости от времени.
Анализ типов происшествий
Данные, которые мы анализируем, содержат информацию, относящуюся к дате аварии, ее типу и месту. Относительно типа аварии в dataframe содержится такая информация, как количество жертв, количество транспортных средств, причастных к происшествию, и тип травм (легкие или серьезные). По указанному выше примеру мы будем проверять распределение всех этих переменных, используя гистограммы.
Количество причастных транспортных средств
На предыдущем графике показано количество происшествий в 2017 году в зависимости от количества причастных транспортных средств. В большинстве аварий были задействованы два автомобиля (7028 аварий в 2017 году). Кроме того, полиция зафиксировала автомобильные аварии, в которых было задействовано до 14 автомобилей. Автомобильные аварии с большим количеством транспортных средств случаются редко.
# Рассчитываем количество аварий в зависимости от количества транспортных средств
vehicles_involved = df.vehicles_involved.value_counts()
# Аварий с участием 12 транспортных средств не зафиксировано. Для лучшей визуализации включаем 0.
vehicles_involved[12]=0
vehicles_involved.sort_index(inplace=True)
# График количества аварий в зависимости от количества транспортных средств
vehicles_involved.plot(kind='bar',figsize=(12,7), color='darkblue', alpha=0.5)
# Заголовок и метки x, y
plt.title('Accidents in Barcelona in 2017',fontsize=20)
plt.xlabel('Vehicles involved',fontsize=16)
plt.ylabel('Number of accidents',fontsize=16);
# Печатаем метку над каждой полосой с указанием количества происшествий
for index in vehicles_involved.index:
plt.text(x=index,y=vehicles_involved.loc[index],s=str(vehicles_involved.loc[index]),horizontalalignment='center')
Травмы по степени тяжести (легкие и серьезные)
Data frame содержит информацию о том, сколько жертв получили легкие и серьезные травмы в каждом инциденте. Представить процент легких и серьезных травм можно с помощью круговой диаграммы:
# Serie с количеством легких травм и серьезных травм
injuries = df[['mild_injuries','serious_injuries']].sum()
# Круговая диаграмма с процентом пострадавших с легкими и серьезными травмами
injuries.plot(kind='pie',figsize=(7,7), colors=['green','red'], labels=None, autopct='%1.1f%%', fontsize=16)
# Надпись и заголовок
plt.legend(labels=['Mild Injuries', 'Serious Injuries'])
plt.title('Injuries in 2017', fontsize=16)
plt.ylabel('')
Согласно графику, только 2% травм составляют серьезные повреждения. Несмотря на то, что большинство травм в автомобильных авариях были легкими, было бы интересно проанализировать, при каких обстоятельствах (время, дата, место) серьезные травмы происходят чаще.
Следующий график показывает процент травм в зависимости от дня недели. Легкие травмы соответствуют ожидаемому шаблону, поскольку они имеют более высокие показатели в будние дни, когда происходит больше несчастных случаев. Тем не менее, серьезные травмы чаще встречаются в выходные дни, хотя среднее число несчастных случаев в выходные дни (1656) ниже, чем в будние дни (1025). Таким образом, в выходные дни случаются более серьезные происшествия, чем в будние дни.
# Количество серьезных травм в день недели
accidents_serious = df[df['serious_injuries']!=0].groupby(df['date'].dt.dayofweek).sum().serious_injuries
# Процент серьезных травм в день недели
rate_serious = accidents_serious/accidents_serious.sum()
# Количество легких травм в день недели
accidents_mild = df[df['mild_injuries']!=0].groupby(df['date'].dt.dayofweek).sum().mild_injuries
# Процент легких травм в день недели
rate_mild = accidents_mild/accidents_mild.sum()
# Объединяем две series в виде dataframe, чтобы расположить графики рядом
rates = pd.DataFrame({'Serious injures':rate_serious,'Mild injuries':rate_mild})
rates.plot(kind='bar',figsize=(12,7),color=['red','green'],alpha=0.5)
# Заголовок и метки
plt.title('Rate of injuries type by day of the week',fontsize=20)
plt.xlabel('Day of the week',fontsize=16)
plt.ylabel('Percentage',fontsize=16)
plt.xticks(np.arange(7),[calendar.day_name[x] for x in range(0,7)]);
Можно также построить график с процентом травм в зависимости от часа.

Как можно заметить, поздно вечером и ночью, как правило, случаются более серьезные происшествия.
Анализ типа происшествий — выводы
- В большинстве происшествий были задействованы 1, 2 или 3 автомобиля. В 2017 году полиция Барселоны зарегистрировала автомобильные аварии, в которых было задействовано до 14 автомобилей.
- Большинство людей, пострадавших в автомобильных авариях в 2017 году, получили легкие травмы (98%).
- Несчастные случаи, как правило, более серьезны ночью, поздно вечером и в выходные дни.
Анализ местоположения
При анализе пространственных данных лучше всего использовать карты. Folium — это библиотека Python, с помощью которой можно создавать несколько типов карт. С ее помощью можно с легкостью сгенерировать карту Барселоны, создав объект Folium Map. Используя аргумент location, можно центрировать карту в определенном месте (в данном случае в Барселоне). В этом месте также можно обеспечить начальный уровень масштабирования для увеличения карты в центре.
import folium
# Определяем карту вокруг Барселоны
barcelona_map = folium.Map(location=[41.38879, 2.15899], zoom_start=12)
# Отображаем карту
barcelona_map
Сгенерированная карта интерактивна (можно увеличивать и уменьшать масштаб).
Набор данных включает в себя широту и долготу каждой автомобильной аварии, которые можно визуализировать с помощью круговых меток. На следующей карте показаны происшествия, в результате которых пострадавшие получили серьезные травмы, с указанием их количества с помощью всплывающего ярлыка.
# Создаем объект map города Барселоны
barcelona_map= folium.Map(location=[41.38879, 2.15899], zoom_start=12)
# Отображаем только те несчастные случаи, в которых зафиксированы серьезные травмы
for lat, lng, label in zip(df.latitude, df.longitude, df.serious_injuries.astype(str)):
if label!='0':
folium.features.CircleMarker(
[lat, lng],
radius=3,
color='red',
fill=True,
popup=label,
fill_color='darkred',
fill_opacity=0.6
).add_to(barcelona_map)
# Отображаем карту
barcelona_map
В Folium можно также группировать маркеры в разные блоки, используя объект MarkerCluster. На следующем графике изображены автомобильные аварии с тяжело ранеными жертвами, как и на графике выше, но на этот раз аварии сгруппированы в блоки.
from folium import plugins
# Создаем объект map города Барселоны
barcelona_map= folium.Map(location=[41.38879, 2.15899], zoom_start=12)
# Создание объекта mark cluster для автомобильных аварий
accidents = plugins.MarkerCluster().add_to(barcelona_map)
# Отображаем только те несчастные случаи, в которых зафиксированы серьезные травмы
for lat, lng, label in zip(df.latitude, df.longitude, df.serious_injuries.astype(str)):
if label!='0':
folium.Marker(
location=[lat, lng],
icon=None,
popup=label,
).add_to(accidents)
# Отображаем карту
barcelona_map
Одной из особенностей Folium является возможность создания анимированных тепловых карт, изменяющих отображаемые данные на основе определенного измерения (например, часов). Для создания такой карты используем метод класса HeatMapWithTime(). Сначала создаем вложенный список, в котором каждая позиция содержит широту и долготу всех автомобильных аварий в этот конкретный час. Например, hour_list[0] содержит автомобильные аварии, которые происходят с 00:00:00 до 00:59:00 (например, hour_list[0] → [[lat1, lon1],[lat2, lon2],[lat3, lon3],…,[Latn, LOGN]). Затем вызываем метод и добавляем его на карту.
from folium.plugins import HeatMapWithTime
# Создаем объект map города Барселона
barcelona_map= folium.Map(location=[41.38879, 2.15899], zoom_start=12)
# Вложенный список, который содержит широту и долготу различных аварий.
hour_list = [[] for _ in range(24)]
for lat,log,hour in zip(df.latitude,df.longitude,df.date.dt.hour):
hour_list[hour].append([lat,log])
# Метки с указанием часов
index = [str(i)+' Hours' for i in range(24)]
# Создание тепловой карты с объектом time для автомобильных аварий
HeatMapWithTime(hour_list, index).add_to(barcelona_map)
barcelona_map
Выше видим, что количество несчастных случаев увеличивается с 8 часов, оставаясь высоким до 21 часа, а затем начинает уменьшаться.
Читайте также:
- Создаем чат-бот в Python с помощью nltk
- 20 фрагментов Python, которые стоит выучить прямо сегодня
- Введение в модульное тестирование на Python
Перевод статьи Amanda Iglesias Moreno: Analysis of car accidents in Barcelona using Pandas, Matplotlib, and Folium





