
Чат-бот — это искусственный интеллект, который может имитировать разговор с пользователем на естественном языке через мессенджеры, веб-сайты, мобильные приложения, телефон и т.д. Чат-боты можно использовать в различных отраслях и для разных задач.
Мы напишем простой чат-бот, используя библиотеку nltk (набор инструментов обработки естественного языка, Natural Language Toolkit). Это ведущая платформа создания программ на Python для работы с данными на “человеческом” языке.
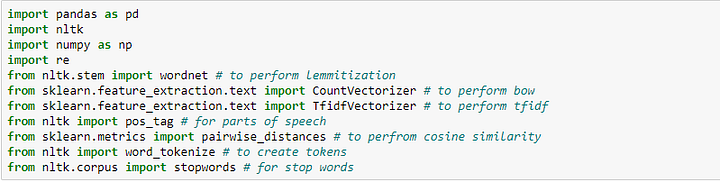
Импортируем необходимые библиотеки:
Импортируем набор данных в блок данных pandas:
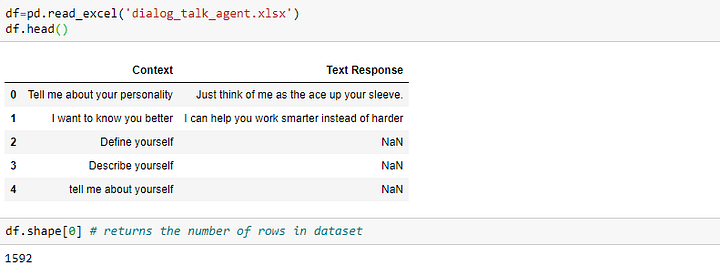
Данные выше содержат 1592 единицы и две колонки контекста, который может быть логически выведен в виде запроса, а текстовый ответ является ответом на этот запрос. Если открыть набор данных в Excel, видно, что в нем существуют нулевые значения; также мы можем обнаружить, что данные расположены в различных кластерах, то есть за вопросами одного типа в одном месте следуют вопросы аналогичного типа.
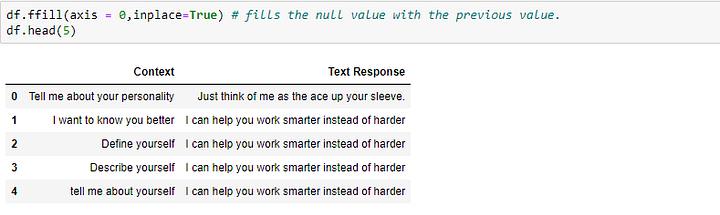
Нулевые значения передаются для того же типа вопросов, ответ на которые может быть почти одинаковым и в подобной группе вопросов; ответ дается на первый вопрос, остальные остаются с нулевым значением. Таким образом, мы можем использовать ffill(), возвращающий значение предыдущего ответа вместо нуля, как показано ниже:
По шагам:
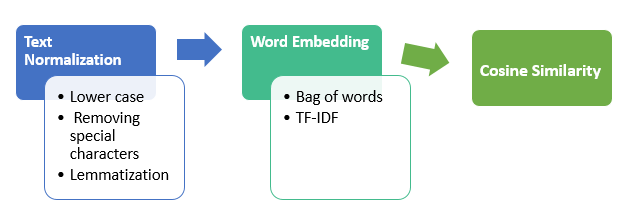
Давайте рассмотрим подробнее первый шаг — нормализацию текста — где мы преобразуем данные в нижний регистр, затем удаляем специальные символы и выполняем лемматизацию.
Давайте создадим функцию, которая преобразует данный текст в нижний регистр и удалит специальные символы и числа.
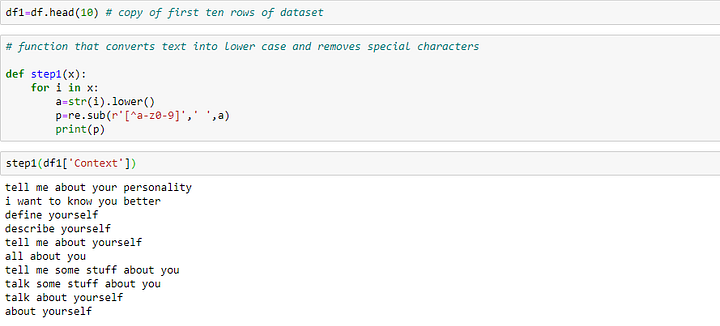
Мы видим, что текст чист. Токенизация слов — это процесс преобразования обычных текстовых строк в список токенов.

Функция pos_tag возвращает части речи каждого токена, таким образом функция-лемматизатор определяет части речи токена и преобразует токен в корневое слово, как показано ниже:


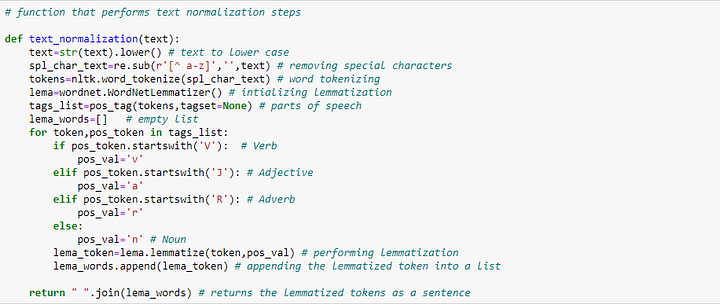
Теперь создадим функцию, выполняющую все перечисленные выше шаги:
Давайте проверим функцию, применив ее к набору данных:
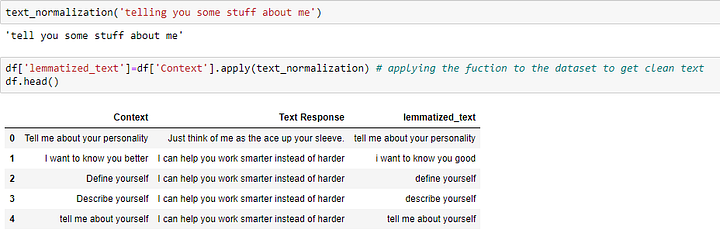
Функция работает хорошо. Следующий шаг — извлечение признаков слов. Это представление текста, где у слов, имеющих схожее значение, схожее представление. У нас есть две модели для этого процесса: bag of words (bow) и tf-idf.
Использование bow:
BOW — это представление текста, которое описывает частотность слов в документе. Предположим, ваш словарь содержит слова {Playing, is, love}, и мы хотим векторизовать текст “Playing football is love”. У нас получится следующий вектор: (1, 0, 1, 1).
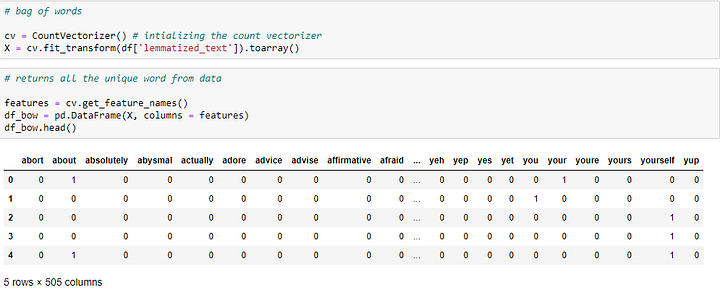
В строке 0 набора данных bow помечает 1 все присутствующие в тексте слова, а остальные 0.
Стоп-слова — это чрезвычайно распространенные слова, которые, имеют низкое значение для соответствия целям пользователя, следовательно, они полностью исключаются из словаря. Ниже заданные заранее стоп-слова:
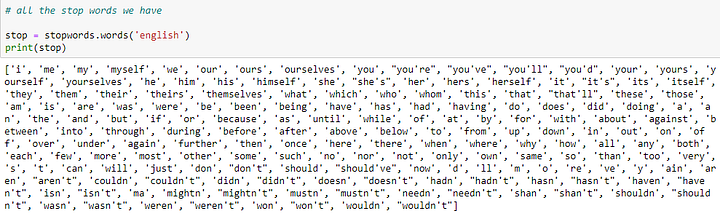
Давайте рассмотрим пример и попробуем получить ответ на запрос:
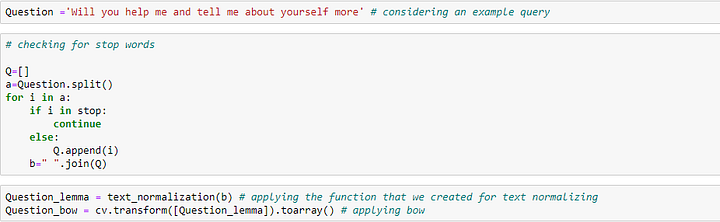
Выше мы задали вопрос ‘Will you help me and tell me about yourself more’, выполнили нормализацию текста и затем применили bow к вопросу. Теперь, чтобы получить соответствующий ответ, найдем косинусное сходство между вопросом и ответом и лемматизированным текстом.
Косинусное сходство:
Косинусное сходство — это мера сходства между двумя векторами. Оно представляет значение, которое вычисляется путем деления скалярного произведения на произведение норм между двумя векторами.
Косинусное сходство a и b — это скалярное произведение a и b, поделённое на |a| * |b|.
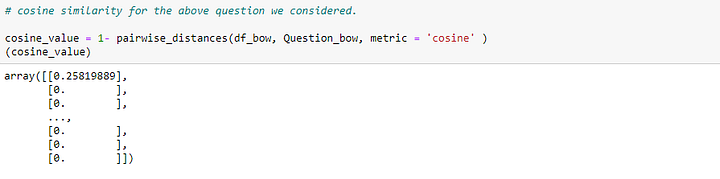
В индексе 194 мы получили наивысшее сходство с запросом. Давайте напечатаем текст в этой позиции и посмотрим, связан он с вопросом или нет.

Смотрите, модель работает очень хорошо 🙂
Использование tf-idf:
tf — частотность терма, term frequency—частотность слова в текущем документе, а idf — обратная частотность документа, inverse document frequency —подсчет того, насколько редко слово встречается в документе. Здесь документ представляет собой текст, например, строку 0 или 1 и т.д., где документы ссылаются на все строки в наборе данных.
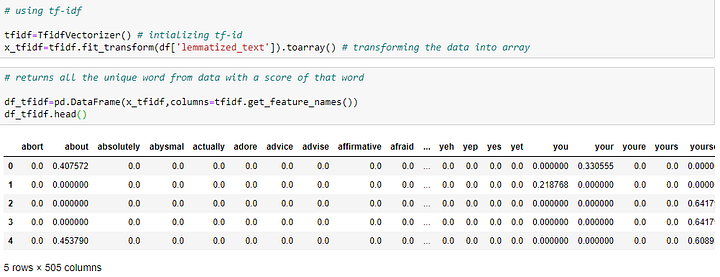
Выше значения, полученные с использованием tf-idf. Теперь использования косинусного сходства позволяет найти ответ, полученный с помощью tf-idf.
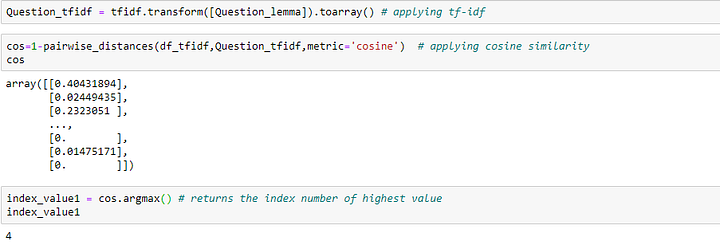
В индексе 4 у нас есть наиболее схожий текст, имеющий отношение к нашему вопросу. Давайте посмотрим на ответ на вопрос:

Используя tf-idf, мы получили другой ответ, который тоже хорошо подходит к вопросу.
Давайте создадим функцию, которая возвращает ответ на запрос, используя tf-idf. Это очень просто — нам нужно объединить все темы, которые были выше в этой статье:

Давайте посмотрим на некоторые ответы на разные запросы.
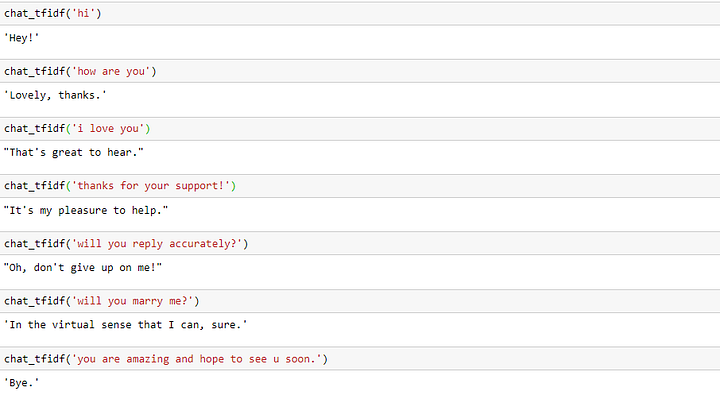
Прекрасно, модель отвечает очень хорошо.
Заключение
Таким же образом можно написать бот, используя bow. Все, что нужно сделать, — это следовать трем шагам: нормализация текста, объединение слов и косинусное сходство. Собранная нами модель не использует искусственный интеллект, но, тем не менее, отвечает весьма хорошо. Полный код можно найти здесь GitHub.
Читайте также:
- 20 фрагментов Python, которые стоит выучить прямо сегодня
- Введение в модульное тестирование на Python
- Альтернатива switch в Python
Перевод статьи Bhargava Sai Reddy P: A Chatbot in Python using nltk





