
Одна из главных задач при работе с текстовыми данными — это создание множества текстовых функций.
Некоторые функции ищут конкретные паттерны в тексте, например, адреса электронной почты или номера телефонов.
Создание этого функционала может казаться довольно тривиальным, но значительно проще использовать модули регулярных выражений.
Например, нужно посчитать количество знаков препинания в конкретном куске текста. Используем отрывок из Диккенса (оригинал).
Как бы вы это сделали?
Достаточно простой путь, к примеру, такой:
target = [';','.',',','–']
string = "It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way – in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only."
num_puncts = 0
for punct in target:
if punct in string:
num_puncts+=string.count(punct)print(num_puncts)
------------------------------------------------------------------
19Это нормально, но в нашем распоряжении есть модуль re, с ним получается всего 2 строчки кода:
import re
pattern = r"[;.,–]"
print(len(re.findall(pattern,string)))
------------------------------------------------------------------
19Эта статья посвящена наиболее часто используемым паттернам регулярных выражений, а также некоторым функциям регулярных выражений.
Что такое регулярные выражения?
Проще говоря, регулярное выражение используется для поиска паттернов в указанной строке.
Паттерном может быть все что угодно.
Можно создавать паттерны соответствия электронной почте или мобильному номеру. Можно создать паттерны, которые ищут слова в строке, начинающиеся на “a” и заканчивающиеся на “z”.
В примере выше:
import re
pattern = r'[,;.,–]'
print(len(re.findall(pattern,string)))Паттерн, который нужно найти — r’[,;.,–]’. Он выделяет любой из четырех символов. Я нашел regex101, прекрасный инструмент для тестирования паттернов. Вот как выглядит данный паттерн, примененный к строке.
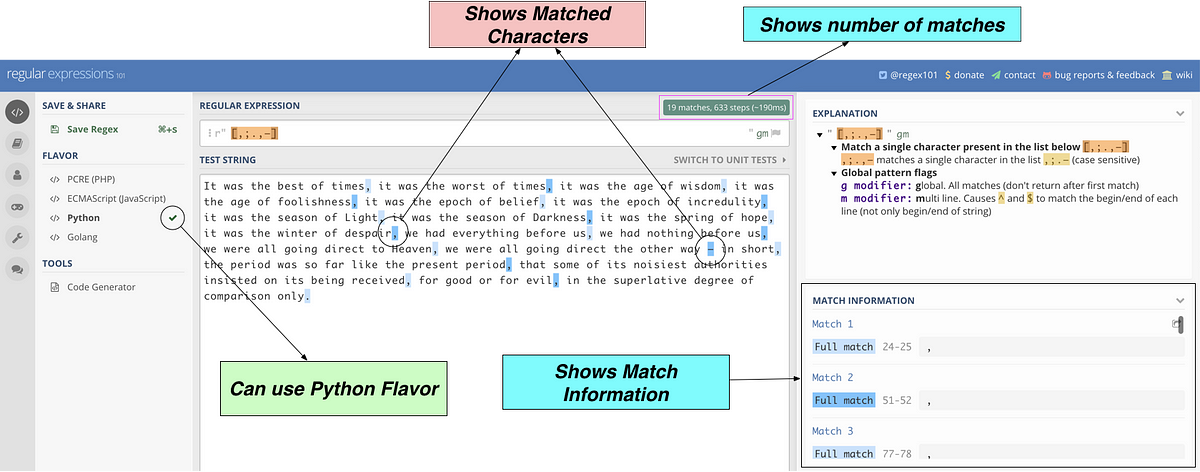
Как видим, мы можем найти любое из значений ,;.,– в указанной строке.
Я использую этот инструмент всегда, когда мне нужно протестировать регулярное выражение. Так значительно быстрее, чем запускать python снова и снова, и гораздо проще при отладке.
Теперь мы знаем, что можем найти паттерны в целевой строке, но как создавать эти паттерны?
Создание паттернов

Первое, что нужно освоить в работе с регулярными выражениями, — это создание паттернов.
Рассмотрим некоторые наиболее часто используемые паттерны.
Простейший паттерн — это просто строка.
pattern = r'times'
string = "It was the best of times, it was the worst of times."
print(len(re.findall(pattern,string)))Но это не очень полезно. Для создания сложных паттернов регулярные выражения содержат специальные символы/операторы. Давайте рассмотрим эти операторы по очереди.
1. Оператор “[ ]"
Этот оператор использовался в первом примере. Мы ищем любой из символов в квадратных скобках.
[abc]— найдет a, b, и c.
[a-z]— найдет все значения от a до z.
[a-z0–9A-Z]— найдет значения от a до z, от A до Z и от 0 до 9.

В Python этот паттерн использовать легко:
pattern = r'[a-zA-Z]'
string = "It was the best of times, it was the worst of times."
print(len(re.findall(pattern,string)))В регулярных выражениях есть и другие функции, кроме .findall , но мы вернемся к ним чуть позже.
2. Оператор точки
Оператор точки (.) используется для поиска соответствия любому единичному символу, кроме символа новой строки.
Самое классное в этом операторе то, что его можно использовать в сочетании с другими.
Например, нужно найти в строке подстроки длиной в 6 знаков, начинающиеся с маленькой “d” и заканчивающиеся маленькой “e”.
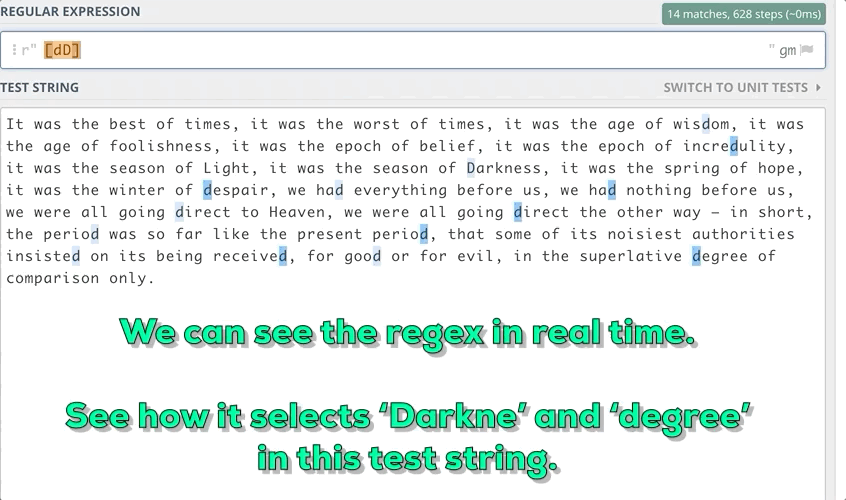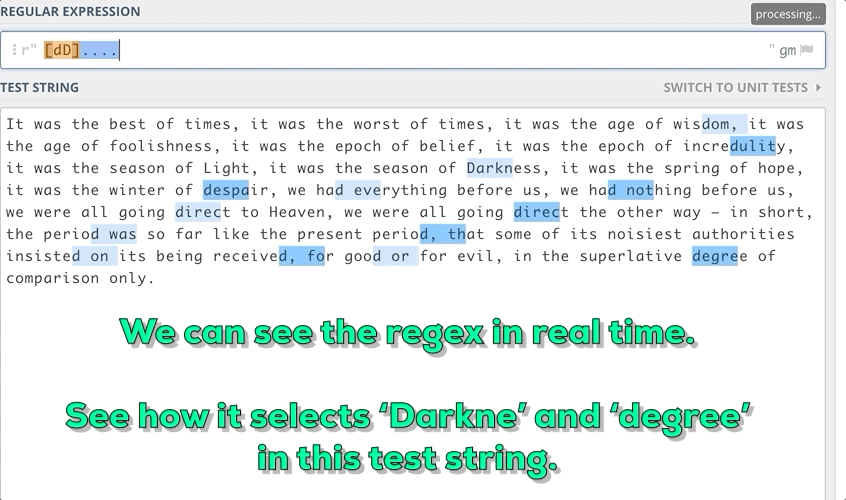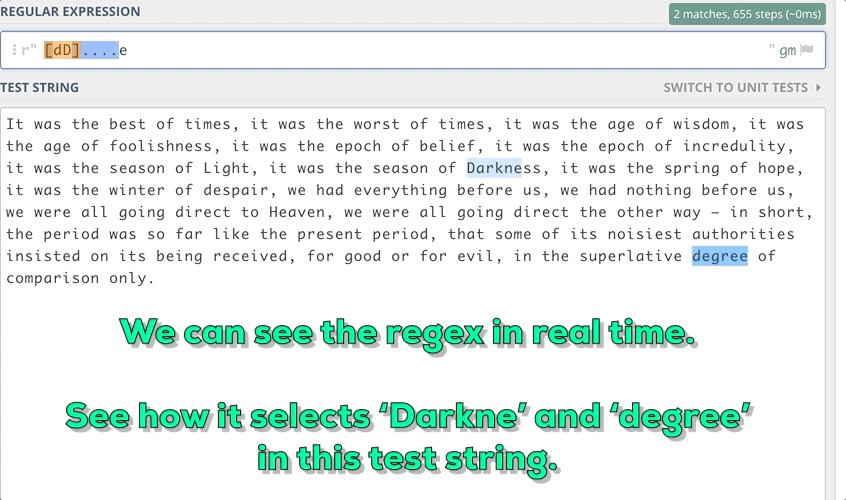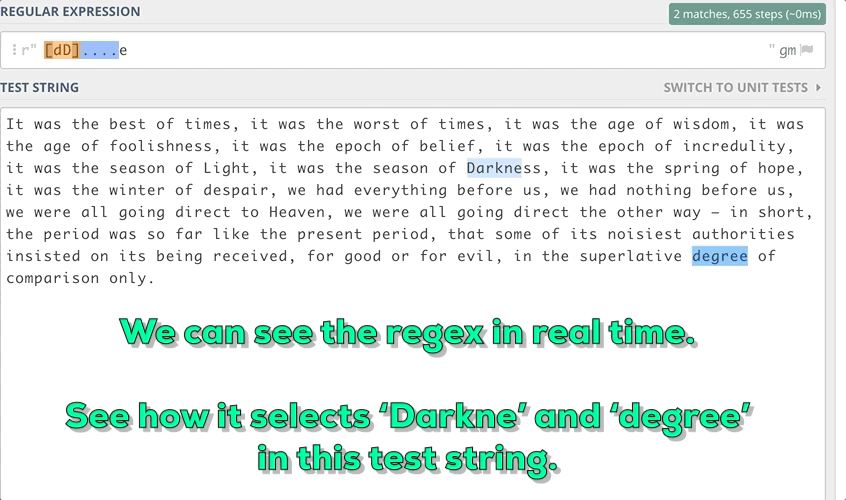
3. Некоторые метапоследовательности
Некоторые паттерны используются постоянно. Для них существуют шорткаты. Вот самые часто используемые:
\w — соответствие любой букве, цифре или подчеркиванию, эквивалентен [a-zA-Z0–9_].
\W — соответствие любому символу, кроме буквенного и цифрового символа и знака подчёркивания.
\d — соответствие любому цифровому символу, эквивалентен [0–9].
\D — соответствие любому нецифровому символу.
4. Операторы “+” и “*”

Символ точки используется для поиска единичного символа. Что если нам нужно найти больше?
Символ + используется для 1 или более значений крайнего левого символа.
Символ * используется для 0 или более значений крайнего левого символа.
Например, если нужно найти все подстроки, начинающиеся с “d” и заканчивающиеся на “e”, нам может встретиться ноль или более символов между “d” и “e”. Используем: d\w*e
Если нужно найти все подстроки, начинающиеся с “d” и заканчивающиеся на “e” с как минимум одним символом между “d” и “e”, используем: d\w+e
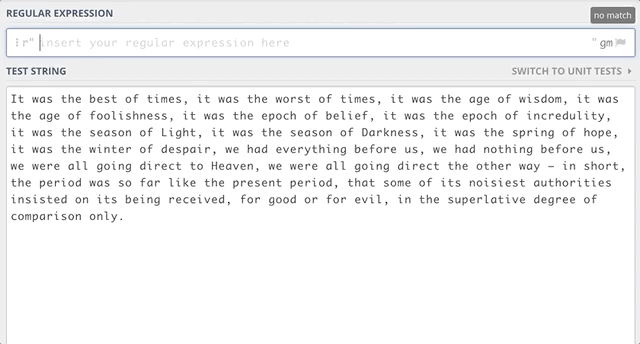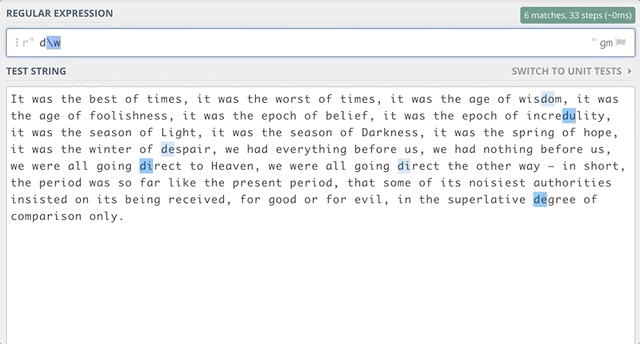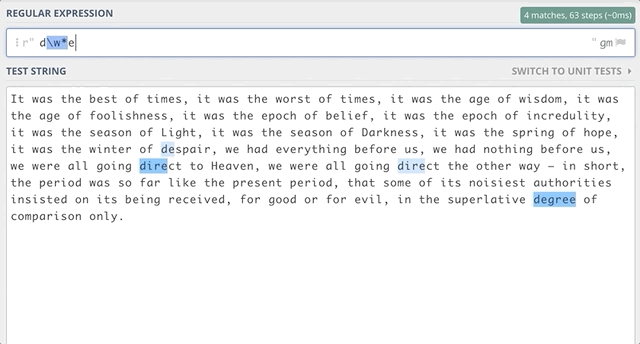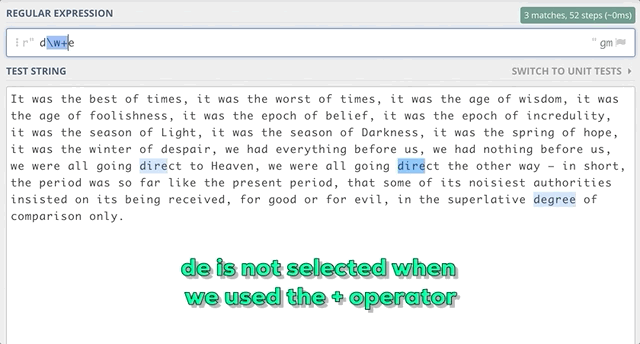
Также можно применить более общий подход с добавлением “{ }”
\w{n} — повторяет \w ровно n раз.
\w{n,} — повторяет \w хотя бы n раз или более.
\w{n1, n2} — повторяет \w хотя бы n1 раз, но не более n2 раз.
5. Операторы “^" и “$"
Оператор “^” выделяет начало строки, а “$” выделяет конец строки.

6. Границы слов
Вы заметили, что в примерах выше я всегда выделял подстроки, а не слова?
Что если нужно найти все слова, начинающиеся с “d”?
Можно ли использовать паттерн d\w*? А давайте посмотрим.

Функции регулярных выражений
До сих пор мы использовали только функцию findall из пакета re, но он содержит значительно больше функций. Давайте рассмотрим их по очереди.
1. findall
Мы уже применяли findall. Ее я использую чаще всего. Давайте изучим ее детальнее.
Ввод: паттерн и тестовая строка.
Вывод: список строк.
#USAGE:
pattern = r'[iI]t'
string = "It was the best of times, it was the worst of times."
for match in matches:
print(match)
------------------------------------------------------------
It
it2. Поиск

Ввод: паттерн и тестовая строка.
Вывод: местоположение первого совпадения объекта.
#USAGE:
pattern = r'[iI]t'
string = "It was the best of times, it was the worst of times."
location = re.search(pattern,string)
print(location)
------------------------------------------------------------
<_sre.SRE_Match object; span=(0, 2), match='It'>Данные местоположения объекта получим, используя:
print(location.group())
------------------------------------------------------------
'It'3. Замена
Это еще одна прекрасная функциональность. При работе с NLP иногда нужно заменить целые числа иксами или отредактировать какой-то документ. Простая функция “найти и заменить” в любом текстовом редакторе.
Ввод: паттерн поиска, паттерн замены и целевая строка
Вывод: измененная строка
string = "It was the best of times, it was the worst of times."
string = re.sub(r'times', r'life', string)
print(string)
------------------------------------------------------------
It was the best of life, it was the worst of life.Некоторые примеры применения:
Регулярные выражения используются во многих случаях, когда нужна проверка данных. Вы наверняка видели на веб-сайтах подсказки вроде “этот адрес электронной почты не действителен”. Такая подсказка может быть написана с помощью нескольких условий if и else, но регулярные выражения в данном случае удобнее.
1. PAN номера

В Индии используются PAN номера для налоговой идентификации вместо SSN номеров в США. Основной критерий действительности PAN — все буквы должны быть заглавными, а символы должны располагаться в следующем порядке:
<char><char><char><char><char><digit><digit><digit><digit><char>Вопрос:
‘ABcDE1234L’ — действительный PAN?
Как решается эта задача без регулярных выражений? Возможно, будет написан цикл for с индексом, проходящим через строку. С регулярными выражениями все проще:
match=re.search(r’[A-Z]{5}[0–9]{4}[A-Z]’,'ABcDE1234L')
if match:
print(True)
else:
print(False)
-----------------------------------------------------------------
False2. Поиск доменных имен

Иногда в большом текстовом документе нужно найти телефонные номера, адреса электронной почти или доменные номера.
Возьмем для примера такой текст:
<div class="reflist" style="list-style-type: decimal;">
<ol class="references">
<li id="cite_note-1"><span class="mw-cite-backlink"><b>^ ["Train (noun)"](http://www.askoxford.com/concise_oed/train?view=uk). <i>(definition – Compact OED)</i>. Oxford University Press<span class="reference-accessdate">. Retrieved 2008-03-18</span>.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.atitle=Train+%28noun%29&rft.genre=article&rft_id=http%3A%2F%2Fwww.askoxford.com%2Fconcise_oed%2Ftrain%3Fview%3Duk&rft.jtitle=%28definition+%E2%80%93+Compact+OED%29&rft.pub=Oxford+University+Press&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span></li>
<li id="cite_note-2"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Atchison, Topeka and Santa Fe Railway (1948). <i>Rules: Operating Department</i>. p. 7.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Atchison%2C+Topeka+and+Santa+Fe+Railway&rft.aulast=Atchison%2C+Topeka+and+Santa+Fe+Railway&rft.btitle=Rules%3A+Operating+Department&rft.date=1948&rft.genre=book&rft.pages=7&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li>
<li id="cite_note-3"><span class="mw-cite-backlink"><b>^ [Hydrogen trains](http://www.hydrogencarsnow.com/blog2/index.php/hydrogen-vehicles/i-hear-the-hydrogen-train-a-comin-its-rolling-round-the-bend/)</span></li>
<li id="cite_note-5"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Central Japan Railway (2006). <i>Central Japan Railway Data Book 2006</i>. p. 16.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Central+Japan+Railway&rft.aulast=Central+Japan+Railway&rft.btitle=Central+Japan+Railway+Data+Book+2006&rft.date=2006&rft.genre=book&rft.pages=16&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li>
<li id="cite_note-5"><span class="mw-cite-backlink"><b>^</b></span> <span class="reference-text"><span class="citation book">Central Japan Railway (2006). <i>Central Japan Railway Data Book 2006</i>. p. 16.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.au=Central+Japan+Railway&rft.aulast=Central+Japan+Railway&rft.btitle=Central+Japan+Railway+Data+Book+2006&rft.date=2006&rft.genre=book&rft.pages=16&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook" class="Z3988"><span style="display:none;"> </span></span></span></li>
<li id="cite_note-6"><span class="mw-cite-backlink"><b>^ ["Overview Of the existing Mumbai Suburban Railway"](http://web.archive.org/web/20080620033027/http://www.mrvc.indianrail.gov.in/overview.htm). _Official webpage of Mumbai Railway Vikas Corporation_. Archived from [the original](http://www.mrvc.indianrail.gov.in/overview.htm) on 2008-06-20<span class="reference-accessdate">. Retrieved 2008-12-11</span>.</span><span title="ctx_ver=Z39.88-2004&rfr_id=info%3Asid%2Fen.wikipedia.org%3ATrain&rft.atitle=Overview+Of+the+existing+Mumbai+Suburban+Railway&rft.genre=article&rft_id=http%3A%2F%2Fwww.mrvc.indianrail.gov.in%2Foverview.htm&rft.jtitle=Official+webpage+of+Mumbai+Railway+Vikas+Corporation&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Ajournal" class="Z3988"><span style="display:none;"> </span></span></span></li>
</ol>
</div>А нужно найти все основные домены в тексте askoxford.com; bnsf.com; hydrogencarsnow.com; mrvc.indianrail.gov.in; web.archive.org
Как это сделать?
match=re.findall(r'http(s:|:)\/\/(www.|ww2.|)([0-9a-z.A-Z-]*\.\w{2,3})',string)
for elem in match:
print(elem)
--------------------------------------------------------------------
(':', 'www.', 'askoxford.com')
(':', 'www.', 'hydrogencarsnow.com')
(':', 'www.', 'bnsf.com')
(':', '', 'web.archive.org')
(':', 'www.', 'mrvc.indianrail.gov.in')
(':', 'www.', 'mrvc.indianrail.gov.in')| — здесь это оператор or, который возвращает наборы, содержащие паттерн внутри ().
3. Find Email Addresses:
Вот регулярное выражение, которое ищет адрес электронной почты в тексте:
match=re.findall(r'([\w0-9-._]+@[\w0-9-.]+[\w0-9]{2,3})',string)
Это продвинутые примеры, но их понимание поможет вам усвоить полученную информацию.
Заключение

Хотя сперва регулярные выражения могут выглядеть устрашающе, они предоставляют великолепную гибкость при манипулировании данными, создании функций и поиске паттернов.
В работе с текстовыми данными я использую их очень часто, а также включаю их в работу над проверкой данных.
Еще я большой поклонник инструмента regex101 и использую его для проверки работы регулярных выражений. Не думаю, что использовал бы регулярные выражения так часто, если бы не этот прекрасный инструмент.
Читайте также:
Перевод статьи Rahul Agarwal: The Ultimate Guide to using the Python regex module





