
Pandas — библиотека, которая не нуждается в представлении, если речь идёт о работе с данными. Она привносит высокую производительность, структурирование данных и удобную работу с ними. Однако при работе со значительно большим количеством данных, например, на одноядерном процессоре, работа библиотеки замедляется. Для сохранения производительности понадобится использование распределённых систем. Ещё один способ повысить производительность заключается в увеличении крутизны кривой обучения. В основном пользователи не хотят сталкиваться с такими трудностями и менять скрипт при смене железа. Гораздо удобнее и проще использовать один и тот же скрипт и для датасетов в 10 килобайт, и для датасетов в 10 терабайт. Modin позволяет оптимизировать работу библиотеки pandas так, чтобы специалист по работе с данными направлял свои усилия на анализ данных, а не на их загрузку или операции над ними.
Modin

Modin — находящийся на ранней стадии разработки проект UC Berkeley’s RISELab для упрощения процесса распределённых вычислений. Это многопроцессная библиотека для работы с датафреймами. API modin точно такой же, как и у pandas, что позволяет разработчикам ускорить процесс работы.
Например, на восьмиядерных процессорах modin ускоряет выполнение запросов в 4 раза. Для этого требуется изменить лишь одну строчку кода. Система была разработана для нынешних пользователей pandas, которым необходимо ускорить работу их программы и сделать возможным увеличение количества обрабатываемых данных без изменения кода. Основная цель библиотеки — сделать возможным использование pandas в облачной среде.
Установка
Modin — проект с открытым исходным кодом, который доступен на GitHub.
Библиотеку можно установить при помощи pip:
pip install modinОдна из зависимостей библиотеки в Windows — Ray. Этот фреймворк пока не поддерживается операционной системой, поэтому для установки придётся использовать WSL (подсистемы Windows для запуска Linux-приложений).
Как Modin ускоряет работу программы
На ноутбуке
Представьте современный ноутбук с четырёхъядерным процессором и датафрейм, умещающийся в памяти ноутбука. При работе с датафреймом в то время как pandas использует только одно из ядер, modin задействует все четыре.
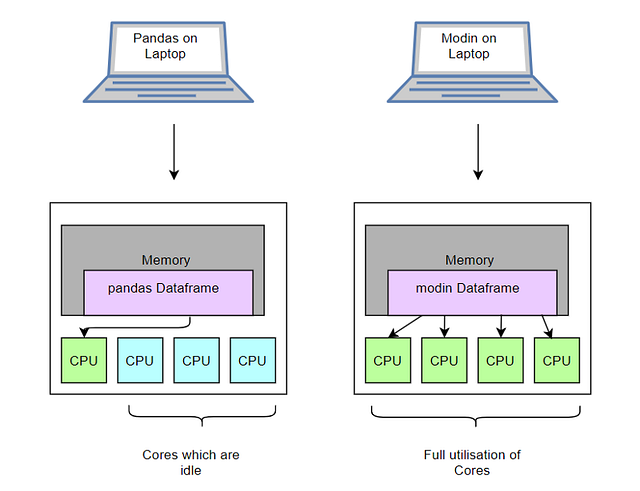
Вкратце, modin задействует все ядра процессора параллельно, таким образом увеличивая производительность.
На мощных компьютерах
На мощных вычислительных машинах увеличение производительности с использованием modin вместо pandas становится более выраженным. Давайте представим, что у нас есть сервер или очень мощный компьютер. Pandas, как говорилось ранее, будет использовать только одно ядро процессора, тогда как modin — все. Вот пример, показывающий зависимость времени работы команды read_csv от размера файла на 144-ядерном компьютере с использованием modin и без.
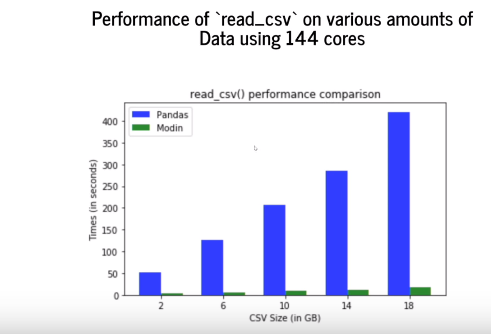
Время работы read_csv в pandas растёт линейно, так как эта библиотека всегда использует лишь одно ядро. При этом, зелёные столбики, соответствующие времени работы modin, достаточно трудно увидеть, так как время работы очень мало.
Как правило, загрузка двух гигабайт данных занимает две секунды, а загрузка 18 гигабайт — немного меньше 18 секунд.
Архитектура
Давайте рассмотрим архитектуру modin подробнее.
Разбиение датафрейма
Датафрейм разбивается на части как по строкам, так и по колонкам. Это обеспечивает гибкость в количестве поддерживаемых строк и столбцов в таблице.
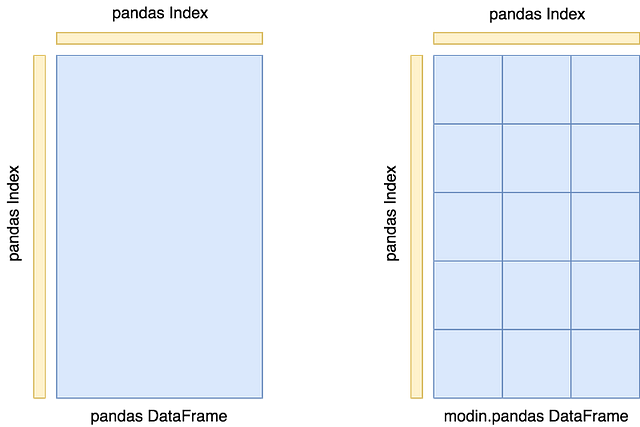
Системная архитектура
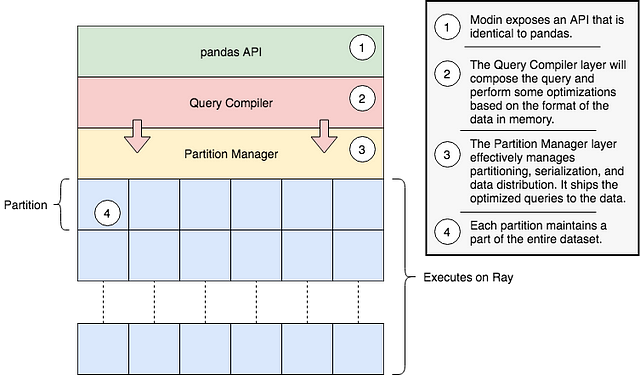
Modin разделена на три слоя:
- API pandas расположен на самом верхнем слое.
- Следующий слой — компилятор запросов, который получает запросы с предыдущего слоя и производит оптимизацию.
- На последнем слое находится менеджер разбиения. Он несёт ответственность за разбиение данных, их распределение и упорядочивание задач, отправляемых каждому разделу.
Реализация pandas API в modin
API библиотеки pandas огромен, поэтому сама библиотека так распространена: она может быть использована для решения большого количества задач.
Имея в распоряжении такое большое количество операций, modin опирается на статистику. Создатели собрали данные со всех блокнотов и скриптов на Kaggle и выяснили, что распределение популярности методов pandas таково:
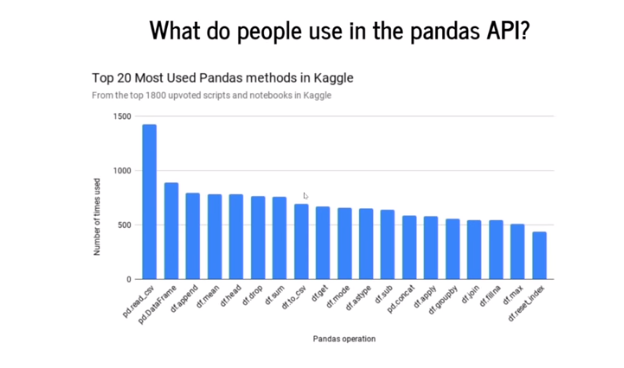
pd.read_CSV — самый широко используемый метод, сопровождаемый pd.Dataframe. Оптимизацию для функций в modin решили реализовывать в порядке убывания популярности этих функций.
- Сейчас modin поддерживает примерно 71% всего API pandas.
- При этом modin охватывает примерно 93% случаев использования библиотеки.
Ray
Modin использует Ray для того, чтобы ускорить скрипты, библиотеки и блокноты, использующие pandas. Это высокопроизводительный распределённый фреймворк для крупномасштабного машинного обучения и обучения с подкреплением. Он позволяет использовать один и тот же код как на персональном компьютере для многопроцессорной обработки данных, так и на вычислительном кластере.
Использование
Импорт
Modin — обёрточная библиотека для pandas. Она распределяет данные и операции между ядрами всего лишь одной строчкой кода. То есть пользователь может ускорить программу, используя те же методы и функции, что и ранее. Единственное, что нужно изменить — импортировать modin.pandas вместо pandas.
import numpy as np
import modin.pandas as pd
Давайте создадим датасет при помощи numpy. В нём будут случайные целые числа. Заметьте, нам не нужно определять разбиение.
data = np.random.randint(0,100,size = (2**16, 2**4))
df = pd.DataFrame(data)
df = df.add_prefix("Col:")Если мы запросим тип датафрейма, программа выведет modin.pandas.dataframe.DataFrame. Если же выведем первые 5 строк таблицы командой head, то получим точно такую же часть таблицы, как и при использовании этой же команды в pandas.
df.head()
Сравнение
Modin отвечает за перемешивание и разделение данных, чтобы пользователь мог сфокусироваться на работе со значениями. Следующий код был запущен на четырёхъядерном iMac 2013 года с 32 Гб оперативной памяти.
pd.read_csv
read_csv — самая часто используемая команда pandas. Давайте сравним её использование в pandas и modin.
- pandas
%%time
import pandas
pandas_csv_data = pandas.read_csv("../800MB.csv")
-----------------------------------------------------------------
CPU times: user 26.3 s, sys: 3.14 s, total: 29.4s
Wall time: 29.5 s- modin
%%time
modin_csv_data = pd.read_csv("../750MB.csv")
-----------------------------------------------------------------
CPU times: user 76.7 ms, sys: 5.08 ms, total: 81.8 ms
Wall time: 7.6 sПри помощи modin read_csv работает почти в четыре раза быстрее на четырёхъядерном процессоре.
df.groupby
Функция groupby в pandas работает достаточно быстро. Несмотря на это, modin и в ней обгоняет pandas.
- pandas
%%time
import pandas
_ = pandas_csv_data.groupby(by=pandas_csv_data.col_1).sum()
-----------------------------------------------------------------
CPU times: user 5.98 s, sys: 1.77 s, total: 7.75 s
Wall time: 7.74 s- modin
%%time
results = modin_csv_data.groupby(by=modin_csv_data.col_1).sum()
-----------------------------------------------------------------
CPU times: user 3.18 s, sys: 42.2 ms, total: 3.23 s
Wall time: 7.3 sИспользование имплементации pandas
При желании разработчик может использовать методы pandas, если их оптимизация ещё не была реализована в modin. Так как метод не оптимизирован, производительность программы в целом упадёт. Однако это позволит использовать modin даже для программ, использующих ещё не реализованные методы. При вызове появится предупреждение:
dot_df = df.dot(df.T)
Метод возвращает датафрейм modin.
type(dot_df)
-----------------
modin.pandas.dataframe.DataFrameЗаключение
Modin, все еще находящийся на ранней стадии разработки, является многообещающим проектом. Библиотека сама заботится о разбиении датафрейма на части и разделения команд и задач, чтобы разработчик фокусировался на ходе работы. Цель создателей библиотеки — разработка инструмента, который позволит пользователям применять одни и те же методы как для больших, так и для маленьких д
Перевод статьи Parul Pandey: Get faster pandas with Modin, even on your laptops





