
Если вы когда-то использовали Keras для создания модели машинного обучения, то скорее всего перед этим вы строили примерно такие графики:
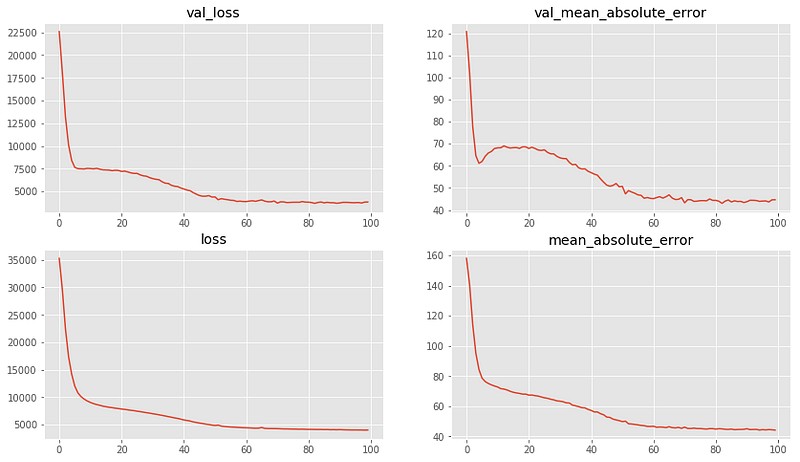
Здесь представлена матрица потери при обучении, потери при валидации, точности обучения и графики точности валидации. Они являются первым и важным этапом при оценке точности и уровня обучения или переобучения для модели. Но для моделирования производительности существует большое количество нюансов, которые находятся в зоне недосягаемости для простых линейных графиков. Но что, если хочется учесть все?
Yellowbrick — набор инструментов для визуализации данных, предоставляющий множество современных графиков для оценки данных и моделей. С их помощью можно построить следующие графики:
Впервые я опробовал Yellowbrick год назад, и с тех пор он является одним из моих любимых инструментов.
Но он предназначен для работы со Scikit-Learn и пока не совместим с Keras. К счастью, это можно исправить, создав простую оболочку для модели. И это отличная новость, так как вам открывается доступ к нескольким продвинутым графикам для оценки моделей нейронной сети.
Создание оболочки scikit-learn для Keras.
yellowbrick предназначен для работы с алгоритмами машинного обучения при помощи известной библиотеки scikit-learn. У каждой модели в scikit-learn есть один и тот же основной API:
# import a classifier object
from sklearn.svm import LinearSVC
# initialize it with hyperparameters
clf = LinearSVC(penalty='l2', loss='hinge')
# call fit on data to train the model
clf.fit(X, y)
# call predict to get predictions
y_pred = clf.predict(y)API для keras в значительной степени опирается на scikit-learn, но при этом адаптирует эту библиотеку под дополнительные потребности (например, компиляция модели), возникающие при обучении нейронной сети:
# import model base and layers
from keras.models import Sequential
from keras.layers import Dense
def twoLayerFeedForward():
# stack the layers
clf = Sequential()
clf.add(Dense(9, activation='relu', input_dim=3))
clf.add(Dense(9, activation='relu'))
clf.add(Dense(3, activation='softmax'))
# compile the model
clf.compile(
loss='categorical_crossentropy', optimizer=SGD(),
metrics=["accuracy"]
)
return clf
# initialize the model object
model = twoLayerFeedForward()
# call fit to train the model
# notice how hyper-parameters are set at fit, not at init
model.fit(
X, y, epochs=50, batch_size=256,
validation_data=(X_test, X_test)
)
# call predict to get predictions
y_pred = model.predict(X)В Keras заранее встроены оболочки для scikit-learn: keras.wrappers.scikit_learn.KerasClassifier для классификаторов и keras.wrappers.scikit_learn.KerasRegressor для регрессоров:
from keras.wrappers.scikit_learn import KerasClassifier
# notice how we go back to stating hyperparameters at init time
# this is the "scikit-learn" way
model = KerasClassifier(
twoLayerFeedForward, epochs=100, batch_size=500, verbose=0
)
# now fit and predict
model.fit(X, y)
y_pred = model.predict(X)Это позволяет использовать нейронную сеть Keras с такими инструментами Scikit-Learn, как перекрестная проверка и сеточный поиск.
К сожалению, если наша цель заключается в использовании визуализаций Yellowbrick для моделей Keras, то KerasClassifier и KerasRegressorне будут достаточно эффективными. ?И вот почему:
- Yellowbrick опирается на некоторую модель семантической сети Scikit-Learn, которую
KerasClassifierне предоставляет. KerasClassifierне предоставляет альтернативные методы обучения, такие какfit_generatorиfit_dataframe, без которых не обойтись.
Но это можно исправить, написав самостоятельно подкласс KerasBatchClassifier:
import numpy as np
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.base import BaseEstimator
class KerasBatchClassifier(KerasClassifier, BaseEstimator):
def __init__(self, model, **kwargs):
super().__init__(model)
self.fit_kwargs = kwargs
self._estimator_type = 'classifier'
def fit(self, *args, **kwargs):
# taken from keras.wrappers.scikit_learn.KerasClassifier.fit
self.model = self.build_fn(**self.filter_sk_params(self.build_fn))
self.classes_ = np.array(range(len(self.fit_kwargs['train_generator'].class_indices)))
self.__history = self.model.fit_generator(
self.fit_kwargs.pop('train_generator'),
**self.fit_kwargs
)KerasBatchClassifier исправляет проблему #1 с помощью настройки свойств _estimator_type и classes_ и добавления ромбовидной зависимости в BaseEstimator, а также исправляет проблему #2, с помощью использования fit_generator в fit.
Невозможность использовать fit_generator с KerasClassifier — известная проблема. Этот код — адаптация (и усовершенствование) уже существующих решений, разработанных другими пользователями, в частности это.
Теперь мы можем перейти к интересной части: применение визуализаций yellowbrick к нашим моделям нейронной сети!
Оценочная классификация
Начнем с проверки графиков оценочной классификации. Для демонстрации, я обучил самую базовую клеточную нейронную сеть на основе изображений фруктов из Google картинок. Демонстрационный набор данных можно найти здесь, а код здесь.
Простейшей оценочной классификацией являетсяClassPredictionError в виде гистограммы с моделями прогнозирования по классам:
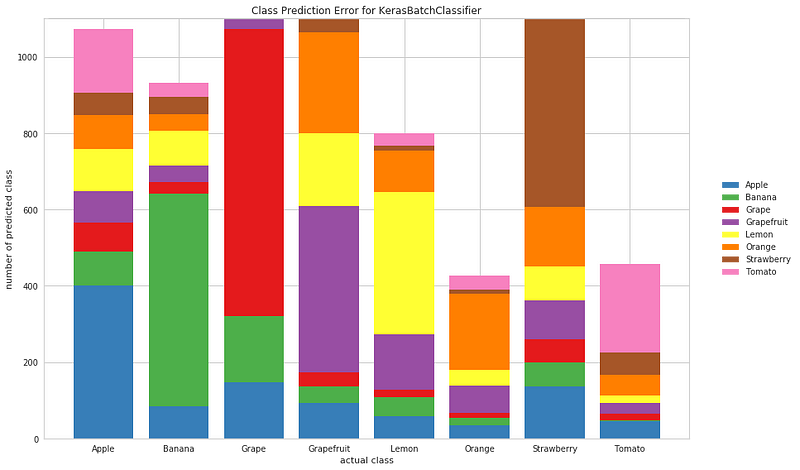
С таким графиком можно быстро оценить, какие классы являются популярными целями классификации, а какие — нет. А также можно увидеть, какие наиболее распространенные ошибки классификации находятся в определенном классе.
Но лично я предпочитаю ConfusionMatrix:
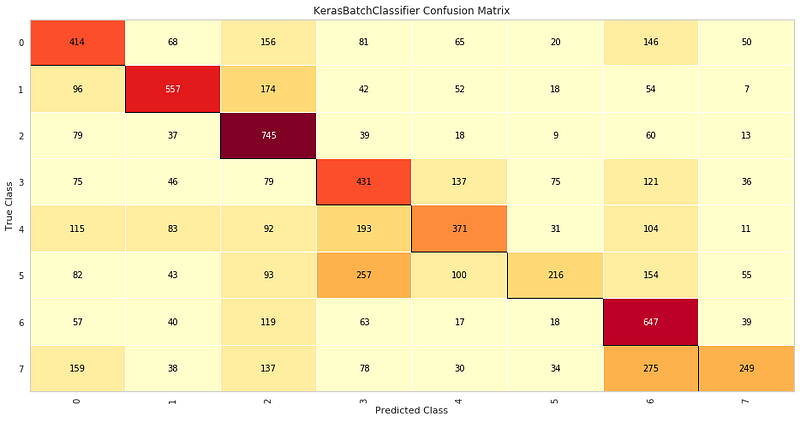
Такая визуализация позволяет быстро распознать важные свойства модели:
- Наиболее точно предсказанные классы.
- Наименее точно предсказанные классы.
- Наиболее распространенные ошибки классификации.
Наконец, мы видим отчет классификации. Он состоит из четырех основных показателей матричной модели классификации — точность (precision), полнота (recall), F-мера (F1 score) и поддержка (support). Эти показатели представлены в удобной визуальной форме:
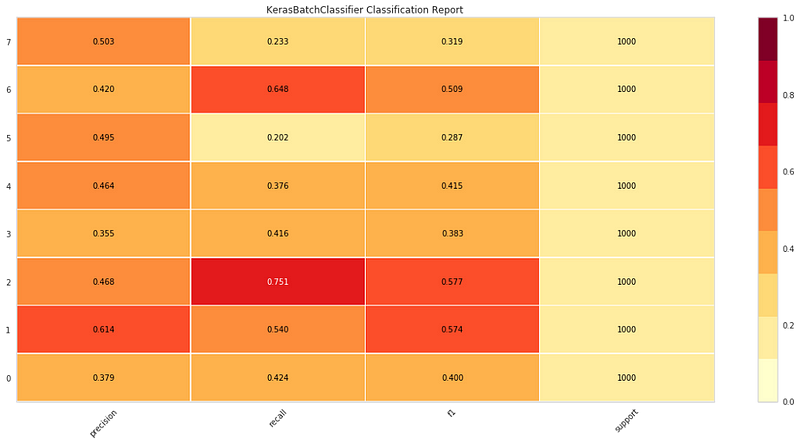
Оценочная регрессия
Yellowbrick также упаковывает инструменты для моделей оценочной регрессии. Для наглядности я обучил простую нейронную сеть прямого распространения для прогнозирования цен на определенный день различных домов из набора данных Boston AirBnBs на Kaggle. Код можно просмотреть здесь.
Мы используем базовый график регрессионного анализа PredictionError, который показывает прогнозируемые значения из модели в зависимости от истинных значений набора данных:
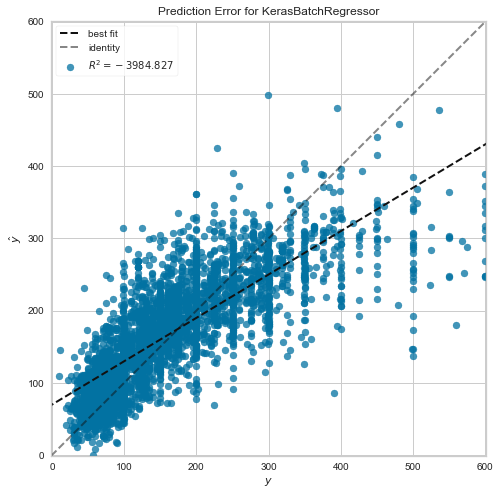
Такая диаграмма полезна для определения закономерностей в данных и наблюдения за тем, насколько хорошо модель к ним адаптируется. Например, значения y на этом графике показывают, что пользователи гораздо чаще выбирают арендную плату, кратную 100.
Также существует график остатков:
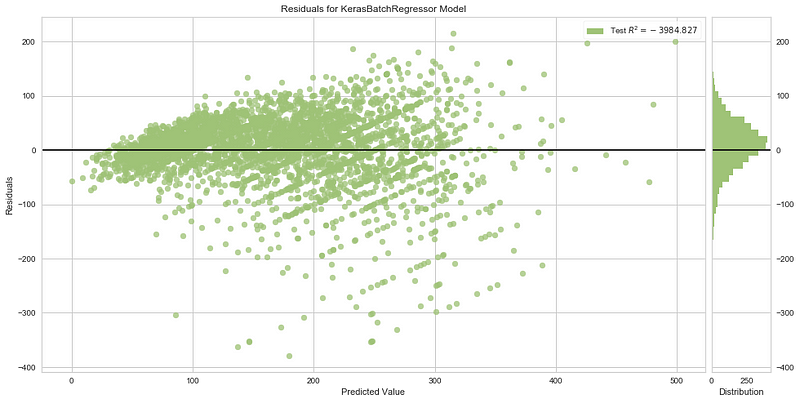
Остаток модели — это интервал между фактическим и спрогнозированным значениями одной записи. Показав все остатки на одном графике, можно оценить, в какой части данных модель работает лучше, а в какой — хуже. Здесь мы видим, что чем больше спрогнозированное значение, тем больше остатки. Это значит, что модель больше подходит для меньших значений в наборе данных.
Заключение
Работая с нейронными сетями, используйте более развитые визуализации, чтобы подробнее изучить определенные свойства модели. Это поможет вам эффективно проводить итерацию модели.
Итак, в данной статье мы разобрали способы использования yellowbrick c keras для создания некоторых графиков. И теперь вы можете заменить заезженные коды из matplotlib хорошо поддерживаемыми визуализациями с продуманной архитектурой, приведенными в данной статье.
Перевод статьи Aleksey Bilogur: Evaluating Keras neural network performance using Yellowbrick visualizations





