
Вряд ли найдётся занятие бесполезнее, чем вновь и вновь запускать одну и ту же ячейку, немного меня значение входных данных и параметров. Несмотря на то, что я понимаю это, часто замечаю себя за запуском одной и той же ячейки, внося в неё незначительные изменения. Например, используя другое значение для функции, выбирая различные диапазоны данных для анализа, или, меняя цветовую схему визуализации. Это не только непродуктивно, но и отвлекает от основной задачи анализа данных.
Решение проблемы — интерактивное управление, которое позволяет менять переменные, не внося изменений в код. К счастью, как это часто происходит в случае с Python, люди уже столкнулись с этой проблемой и был создан продукт, решающий её. В этой статье мы увидим, как работать с IPywidgets, инструментом интерактивного управления. Эта библиотека превращает блокнот Jupyter из статичного текстового документа в диалоговую панель, удобную для визуализации и работы с данными.
Вы можете посмотреть на пример интерактивного блокнота в этой статье на mybinder.

К сожалению, визуализация виджетов IPython не поддерживается на GitHub или на nbviewer, поэтому для просмотра примеров запустите блокнот локально.
Начало работы с IPywidgets
Первым делом устанавливаем библиотеку: pip install ipywidgets. Как только установка завершится, активируйте виджеты при помощи команды:
jupyter nbextension enable --py widgetsnbextension
Чтобы использовать с JupyterLab, выполните команду:
jupyter labextension install @jupyter-widgets/jupyterlab-manager
Для того, чтобы импортировать ipywidgets в блокнот, создайте ячейку со следующим содержанием:
import ipywidgets as widgets
from ipywidgets import interact, interact_manual
Интерактивное управление в одну строчку
Пусть нашими данными будет статистика статей в Medium (это моя действительная статистика).
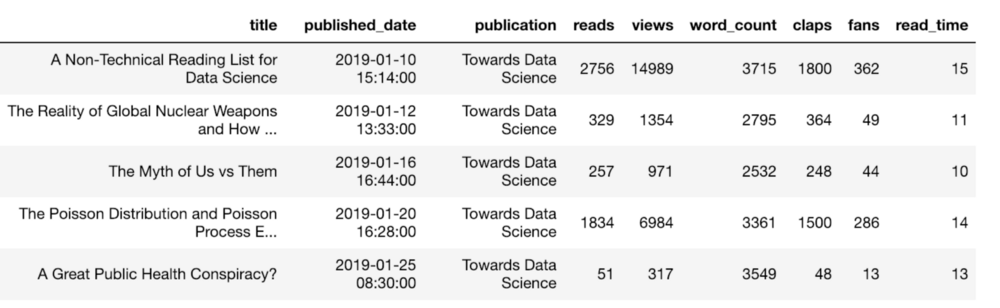
Предположим, что нужно посмотреть статьи со значением просмотра больше 1000. Вот как можно это сделать:
df.loc[df['reads'] > 1000]
Но, если мы хотим вывести статьи, у которых больше 500 хлопков, нам придётся написать ещё одну строчку:
df.loc[df['claps'] > 500]
Было бы гораздо удобнее, если бы мы могли менять эти параметры: и колонку, и пороговое значение без изменений кода. Попробуем выполнить это:
@interact
def show_articles_more_than(column='claps', x=5000):
return df.loc[df[column] > x]
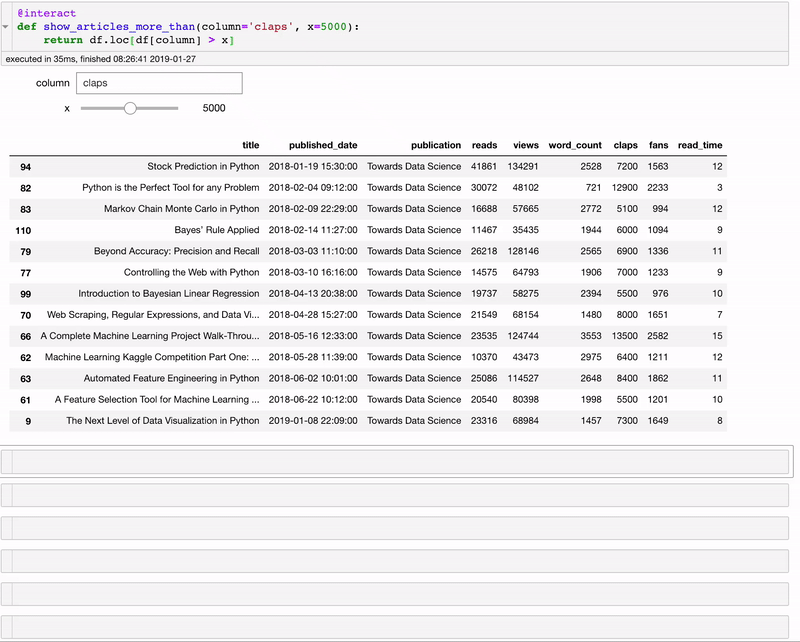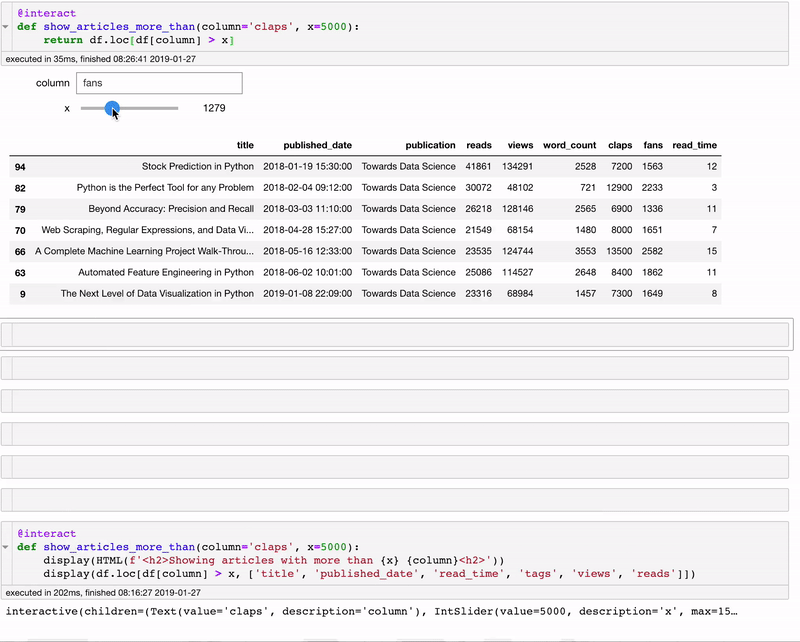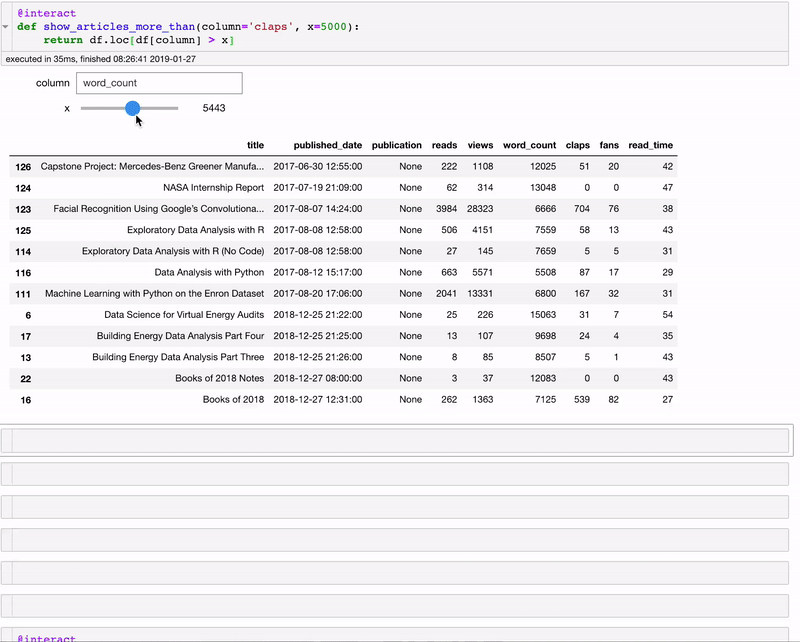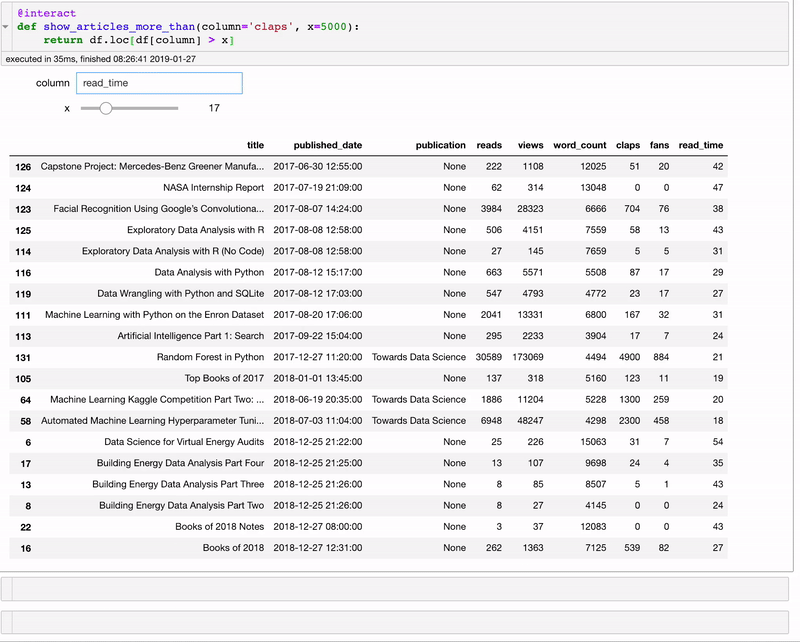
@interact автоматически создаёт текстовое поле и слайдер для выбора колонки и числа! Декоратор смотрит на введённые параметры и создаёт панель диалогового управления, основываясь на типах данных. Теперь мы можем разделять данные, не меняя код.
Возможно, вы заметили, что в нашем виджете x может быть отрицательным, а в графу column необходимо вводить существующие названия колонок. Это неудобство можно исправить, задав возможные параметры функции.
# Interact with specification of arguments
@interact
def show_articles_more_than(column=['claps', 'views', 'fans', 'reads'], x=(10, 100000, 10)):
return df.loc[df[column] > x]
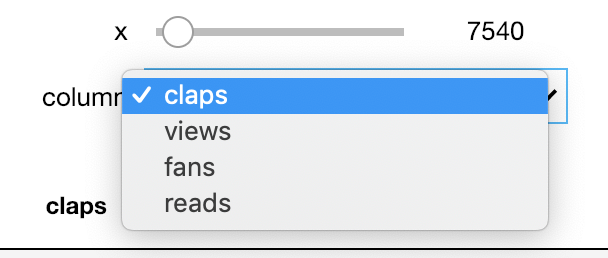
Теперь у нас есть выпадающий список с названиями колонок и слайдер с ограниченной область значений (формат: (начало, конец, шаг)). За подробностями о параметрах обратитесь к документации.
Используем тот же декоратор @interact для того чтобы преобразовать функцию в интерактивный виджет. Например, если есть директория с изображениями, которые мы хотим просмотреть:
import os
from IPython.display import Image
@interact
def show_images(file=os.listdir('images/')):
display(Image(fdir+file))
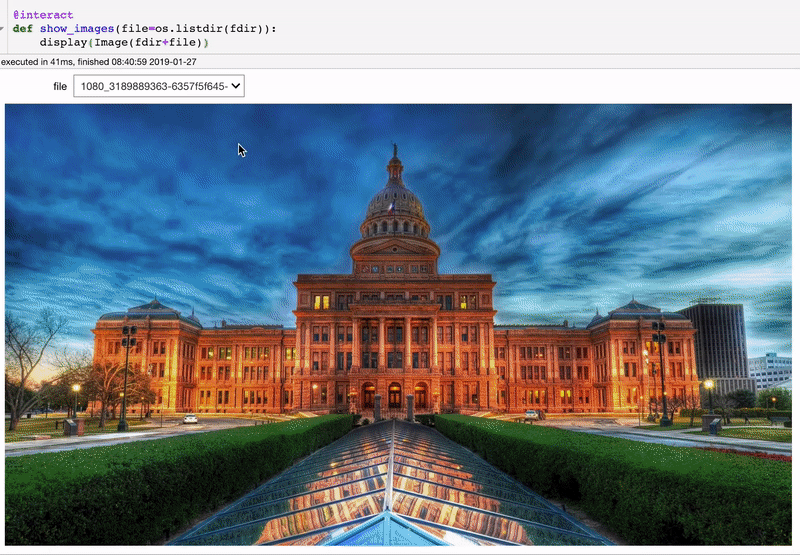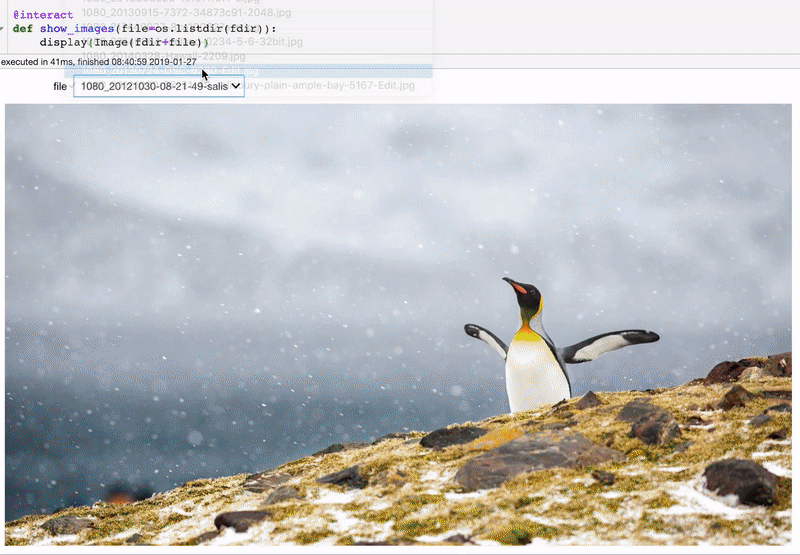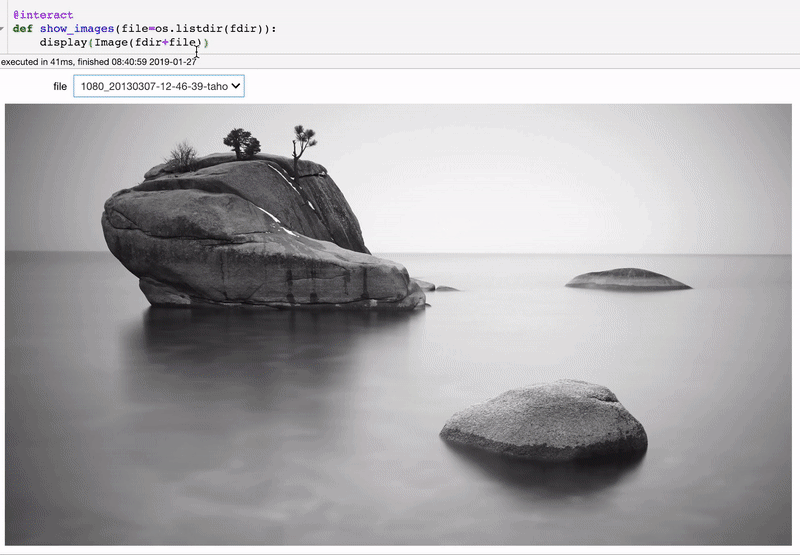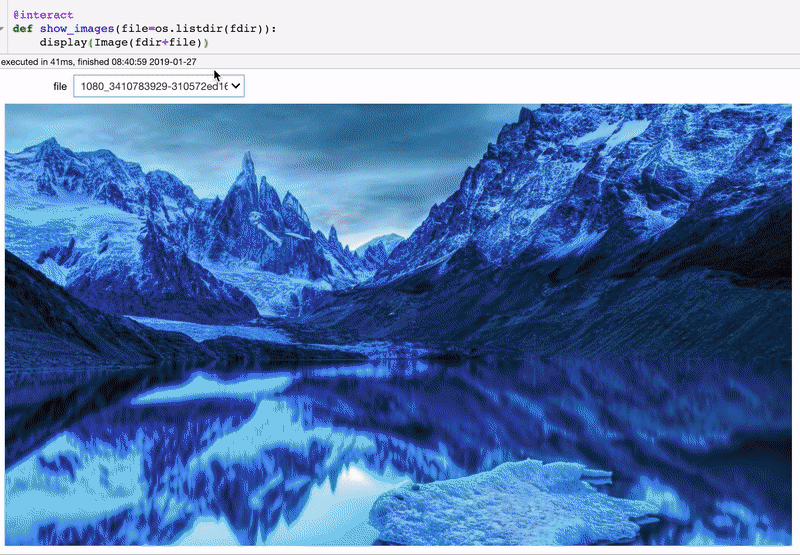
Теперь мы можем просматривать все изображения, не перезапуская ячейку каждый раз. Это полезно, если, например, вы создаёте свёрточную нейронную сеть и хотите увидеть изображения, на которых классификатор допустил ошибку.
На самом деле, область использования этих виджетов ничем не ограничена. Ещё одним примером рассмотрим поиск корреляции между двумя столбцами:
@interact
def correlations(column1=list(df.select_dtypes('number').columns),
column2=list(df.select_dtypes('number').columns)):
print(f"Correlation: {df[column1].corr(df[column2])}")
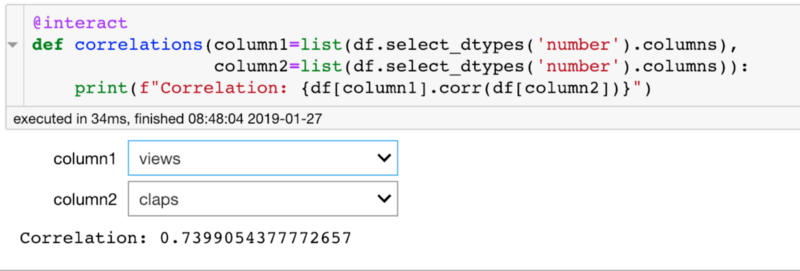
На GitHub можно найти ещё больше примеров использования ipywidgets.
Виджеты для графиков
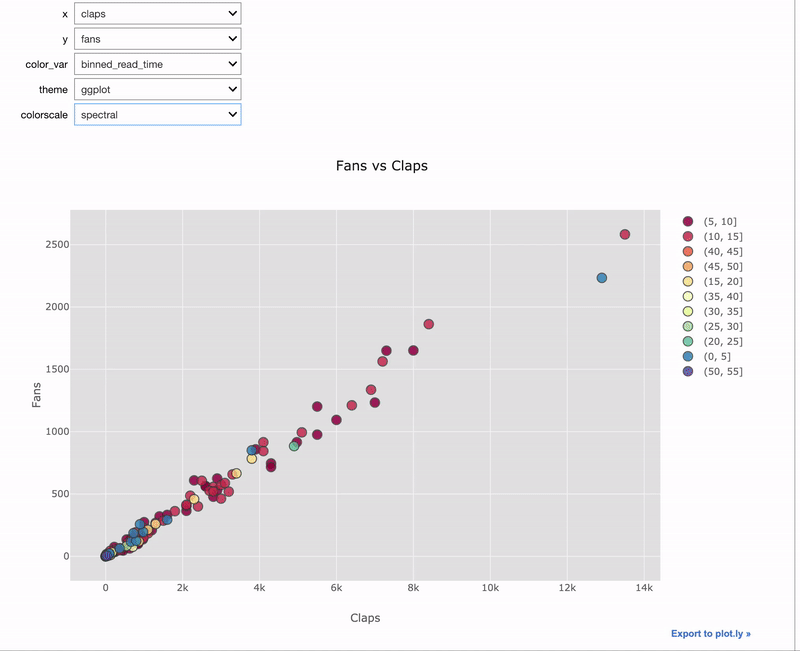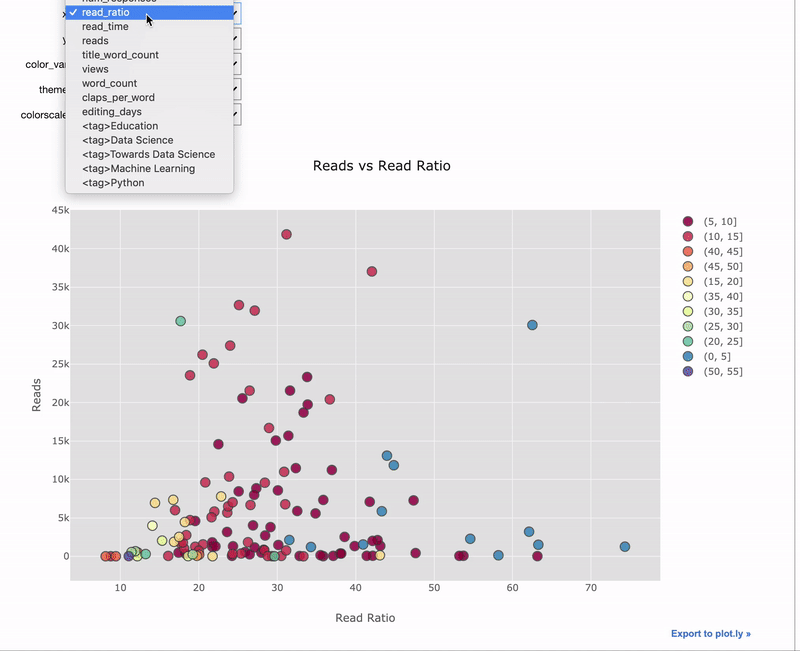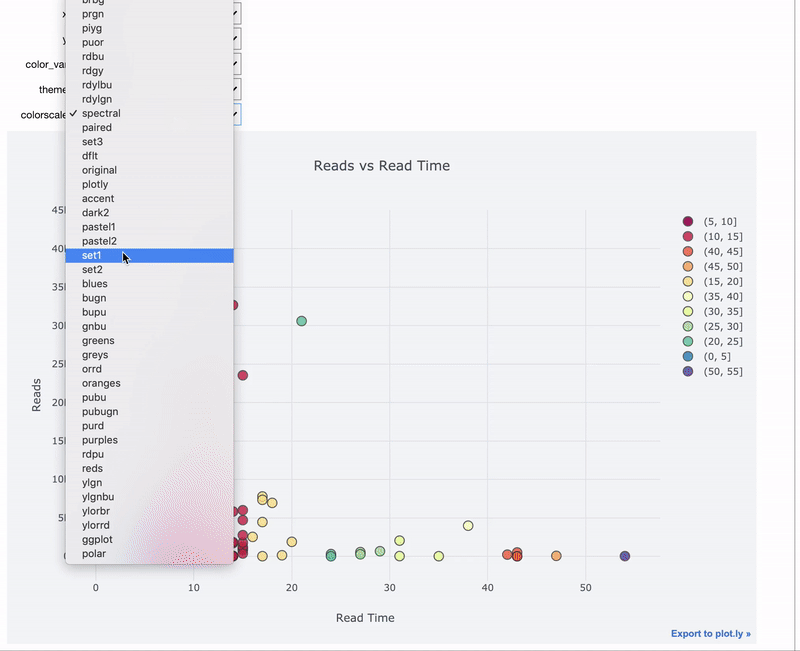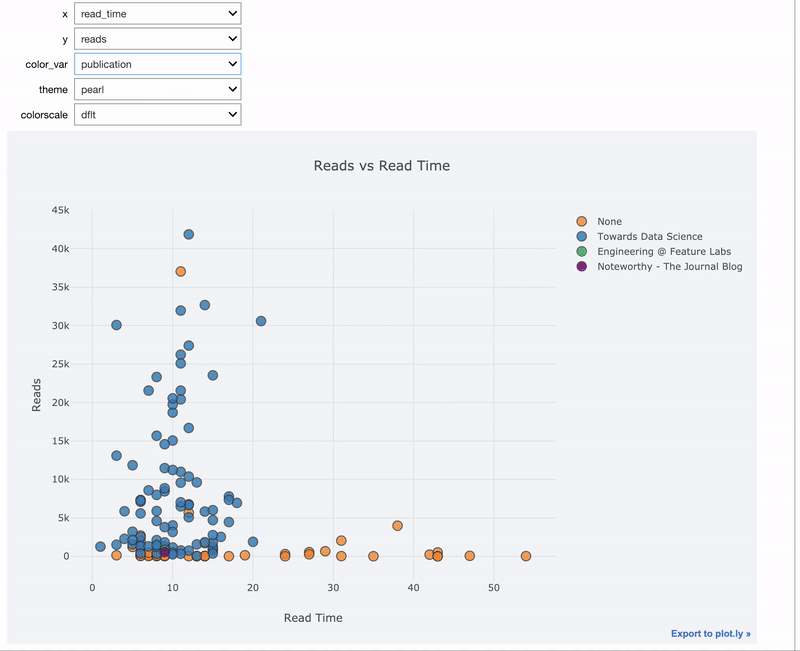
Интерактивные виджеты особенно полезны для данных, которые мы хотим визуализировать. Используем тот же самый декоратор @interact:
import cufflinks as cf
@interact
def scatter_plot(x=list(df.select_dtypes('number').columns),
y=list(df.select_dtypes('number').columns)[1:],
theme=list(cf.themes.THEMES.keys()),
colorscale=list(cf.colors._scales_names.keys())):
df.iplot(kind='scatter', x=x, y=y, mode='markers',
xTitle=x.title(), yTitle=y.title(),
text='title',
title=f'{y.title()} vs {x.title()}',
theme=theme, colorscale=colorscale)
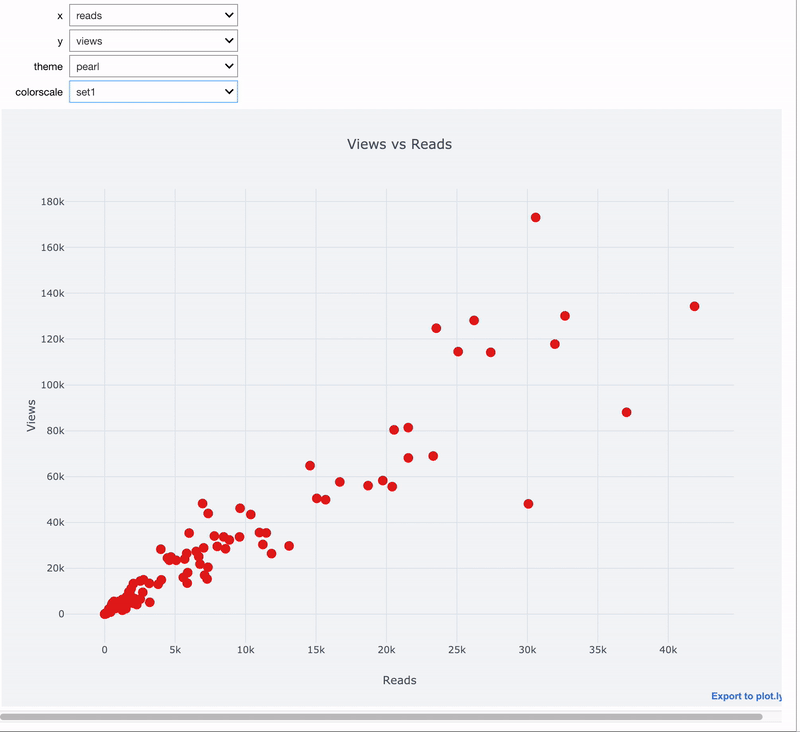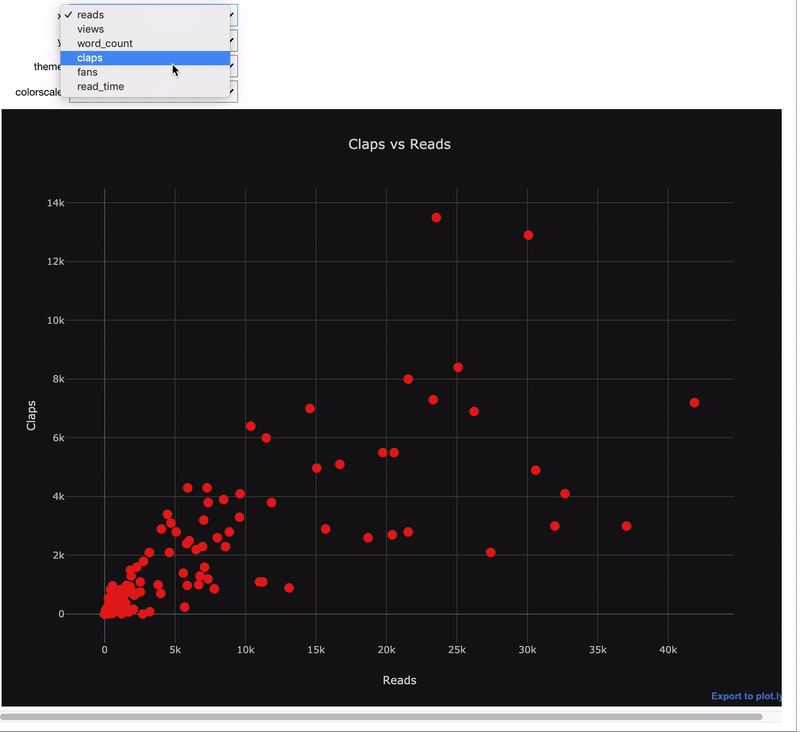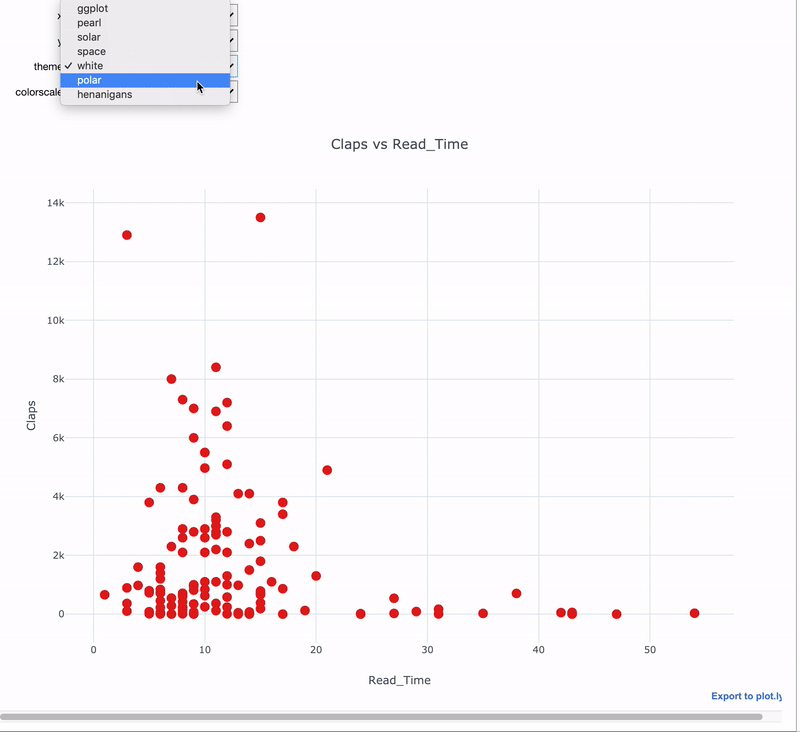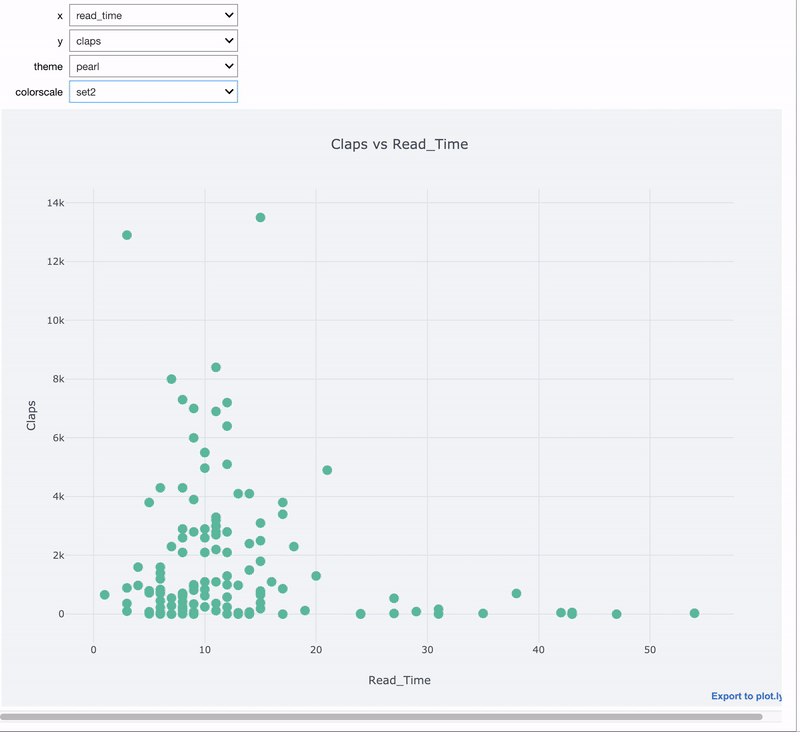
Здесь мы используем комбинацию cufflinks + plotly для создания интерактивного графика с интерактивным управлением при помощи виджетов.
Возможно, вы заметили, что график достаточно медленно обновляется. В этом случае, мы можем использовать @interact_manual с отдельной кнопкой для обновления.

Теперь график будет обновлён только после нажатия кнопки. Это полезно для функций с относительно долгим временем выполнения.
Расширение возможностей интерактивного управления
Мы можем сами создавать виджеты и использовать их в функции interact. Один из моих любимых виджетов — DatePicker. Допустим, у нас есть функция stats_for_article_published_between, которая получает на вход начальную и конечную дату и выдаёт все статьи, опубликованные в этот промежуток. Для виджета используем следующий код:
# Create interactive version of function with DatePickers
interact(stats_for_article_published_between,
start_date=widgets.DatePicker(value=pd.to_datetime('2018-01-01')),
end_date=widgets.DatePicker(value=pd.to_datetime('2019-01-01')))
Теперь у нас есть два виджета для выбора даты. ходные данные передаются в функцию (подробности в блокноте):
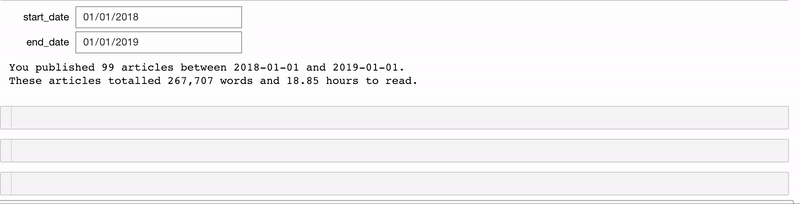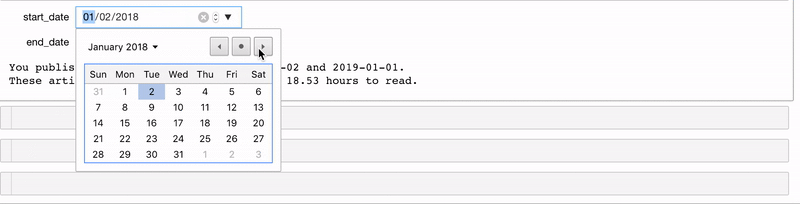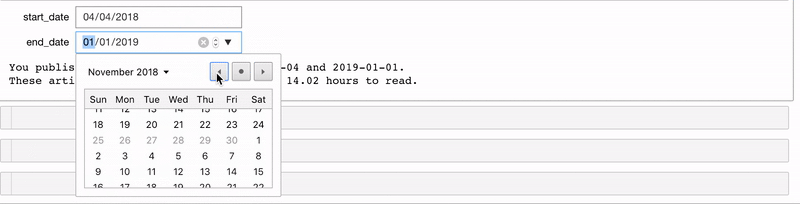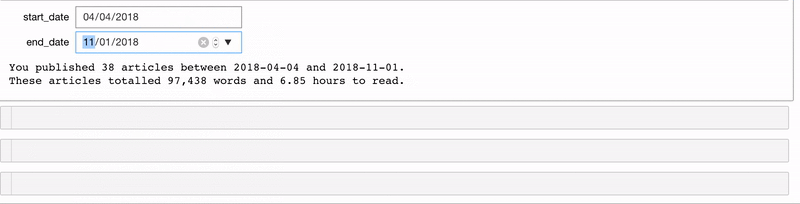
Точно так же мы можем сделать функцию, которая создаёт график столбцов до определённой даты.
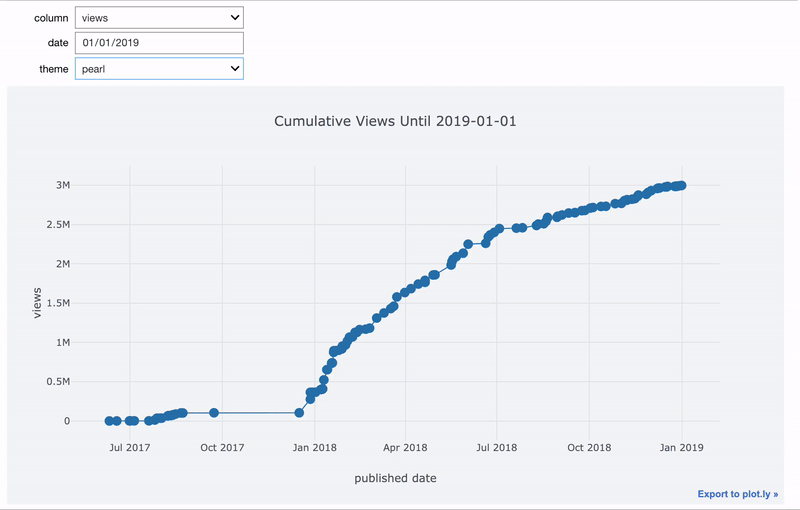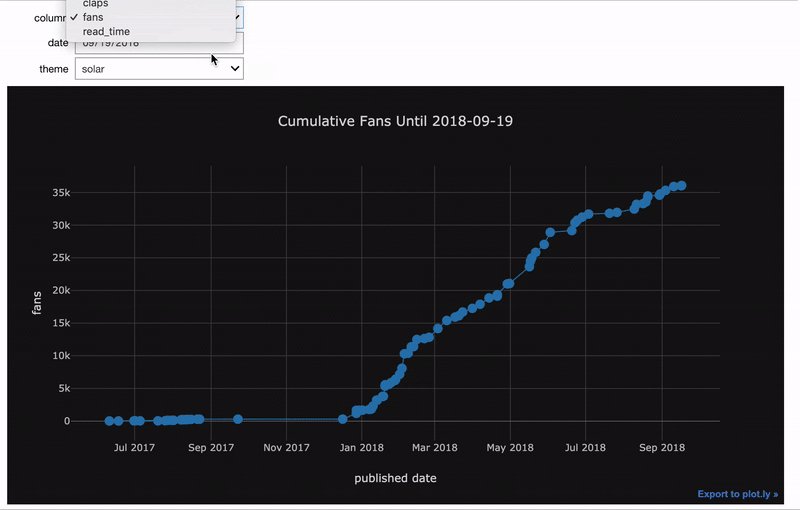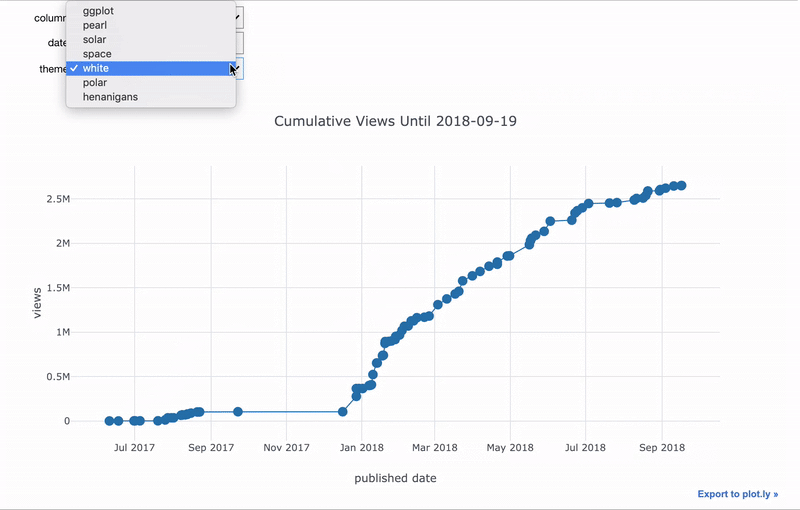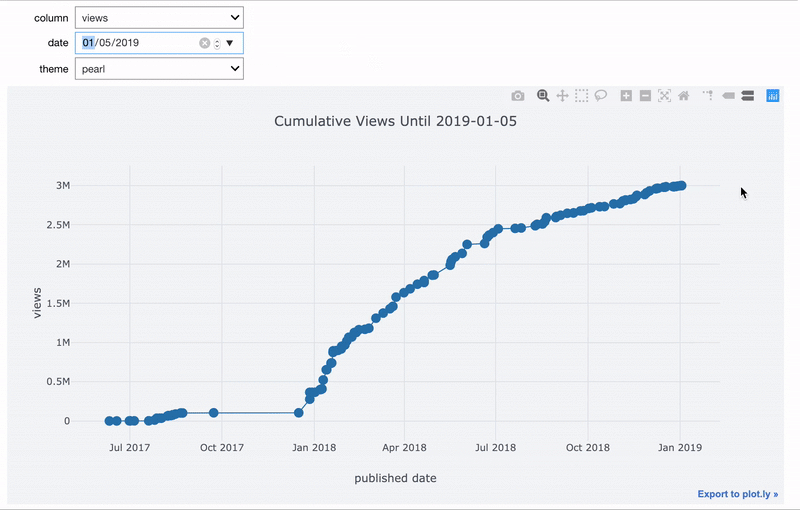
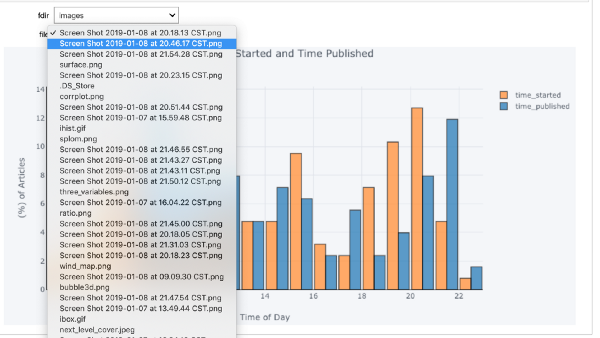
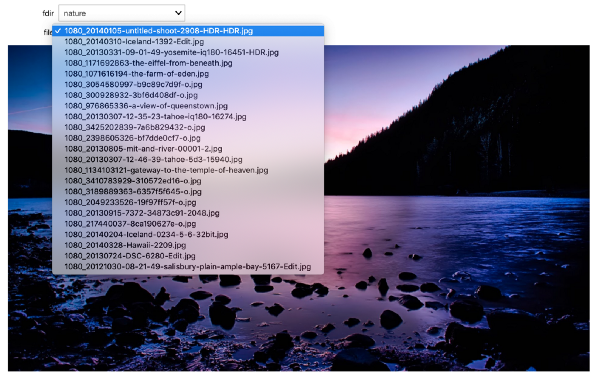
Если мы хотим, чтобы значение одного виджета зависело от значения другого, используем функцию observe. Здесь мы модифицируем функцию просмотра изображений так, чтобы выбирать и директорию, и картинку. Список изображений меняется при смене директории.
# Create widgets
directory = widgets.Dropdown(options=['images', 'nature', 'assorted'])
images = widgets.Dropdown(options=os.listdir(directory.value))
# Updates the image options based on directory value
def update_images(*args):
images.options = os.listdir(directory.value)
# Tie the image options to directory value
directory.observe(update_images, 'value')
# Show the imagesdef show_images(fdir, file): display(Image(f'{fdir}/{file}'))
_ = interact(show_images, fdir=directory, file=images)
Повторное использование виджетов
Если мы хотим использовать виджет в нескольких ячейках, присвоим ей значение выходных данных функции interact:
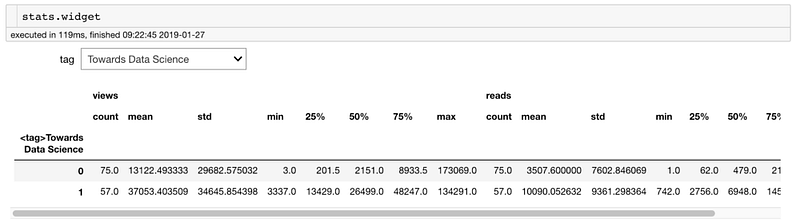
def show_stats_by_tag(tag):
return(df.groupby(f'<tag>{tag}').describe()[['views', 'reads']])
stats = interact(show_stats_by_tag,
tag=widgets.Dropdown(options=['Towards Data Science',
'Education', 'Machine Learning', 'Python',
'Data Science']))
Теперь из любой ячейки мы можем вызвать stat.widget.
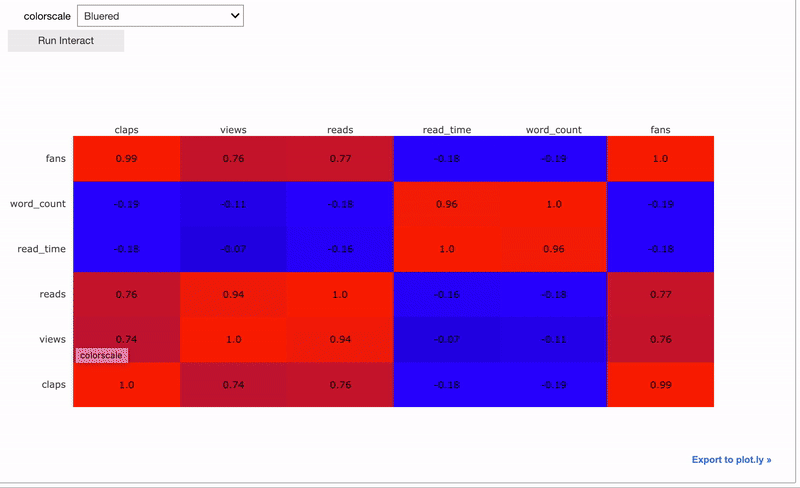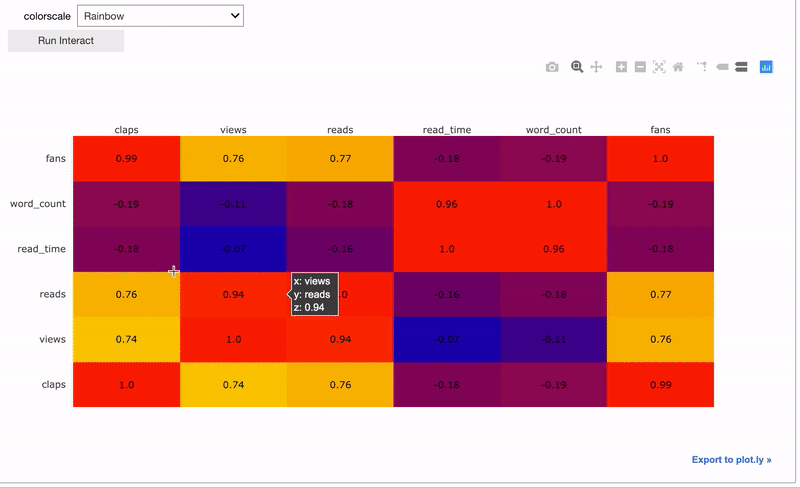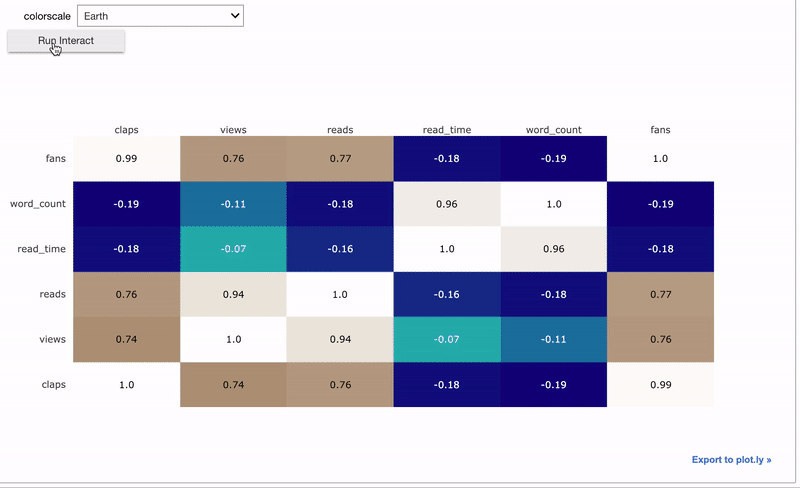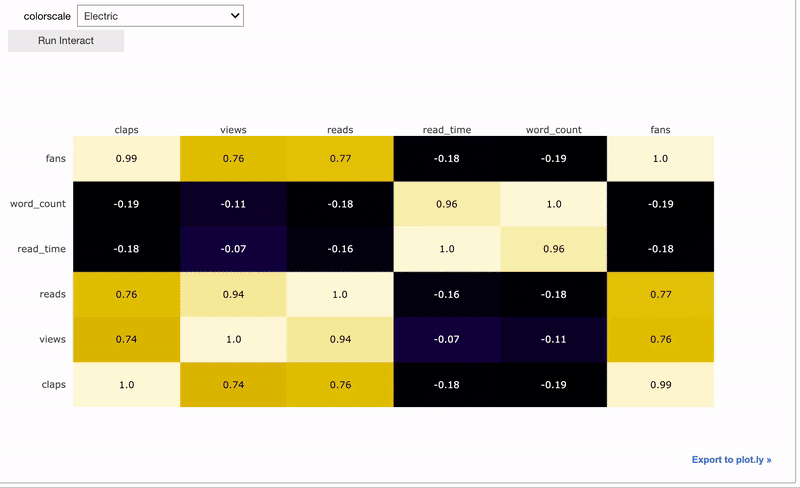
Это позволяет использовать виджеты во всём блокноте. Заметьте, что виджеты привязаны друг к другу, а это значит, что при изменении его в одной ячейке он автоматически поменяется и в остальных
Конечно, мы не узнали о всех возможностях библиотеки ipywidgets. Мы научились привязывать значения друг к другу, создавать виджеты, кнопки, панели с вкладками и анимацию. Для дальнейшего использования и для знакомства с полным функционалом ознакомьтесь с документацией. Надеюсь, что даже та маленькая часть возможностей этой библиотеки, о которой я рассказал, дала понять вам то, как сильно она упрощает вашу работу.
Заключение
Jupyter Notebook — прекрасная среда для обработки и анализа данных. Однако, она одна не предоставляет удобный функционал. Использование расширений и интерактивных виджетов значительно улучшает блокнот и делает работу специалистов науки о данных более эффективной!
Перевод статьи Will Koehrsen: Interactive Controls in Jupyter Notebooks





