
Адресуем эту в целом образовательную статью разработчикам, которые создают небольшое хранилище/витрину данных или уже делали это и хотят разложить все по полочкам, подкорректировав свое видение.
Сделаем простое хранилище данных DW, шаг за шагом проходя все основные аспекты процесса. Предполагается, что читателю доступен Linux с установкой нужных пакетов вроде postgres, dbt и базовыми операциями.
Итерация 1
Сначала сделаем пилотную версию, но без подробностей.
Этап 1. Источник
Для целевого DW возьмем одну систему-источник — базу данных dvdrental, другие источники добавятся позже.
Чтобы воспроизвести реальные условия, вместо пользователя postgres создадим базу данных и роль login для учетки, видимой при запуске whoami. Допустим, что это user0 и мы находимся в одном каталоге с dvdrental.tar:
createdb -U postgres dvdrental
pg_restore -U postgres -d dvdrental dvdrental.tar
psql -U postgres -d dvdrental -c 'create role user0 with login'
Система-источник управляется из postgres, как разработчика DW: прав у нас там не много, внешним пользователям администраторами системы-источника обычно разрешается только чтение, что совершенно правильно. Чтобы обойти авторизацию в postgres, будем работать как пользователь DW user0, как в учетной записи ОС.
Проверяем, что все таблицы находятся в dvdrental:
psql -d dvdrental -c '\dt public.*'
List of relations
Schema | Name | Type | Owner
--------+---------------+-------+----------
public | actor | table | postgres
public | address | table | postgres
public | category | table | postgres
public | city | table | postgres
public | country | table | postgres
public | customer | table | postgres
public | film | table | postgres
public | film_actor | table | postgres
public | film_category | table | postgres
public | inventory | table | postgres
public | language | table | postgres
public | payment | table | postgres
public | rental | table | postgres
public | staff | table | postgres
public | store | table | postgres
(15 rows)
user0 мы создали с пустым паролем. Если инструменты «ругаются» на это, ничего страшного.
Вот немного переупорядоченная модель данных dvdrental, посмотрите, нет ли пропусков, поделайте запросы в таблицы источников, обнаруживая странности:
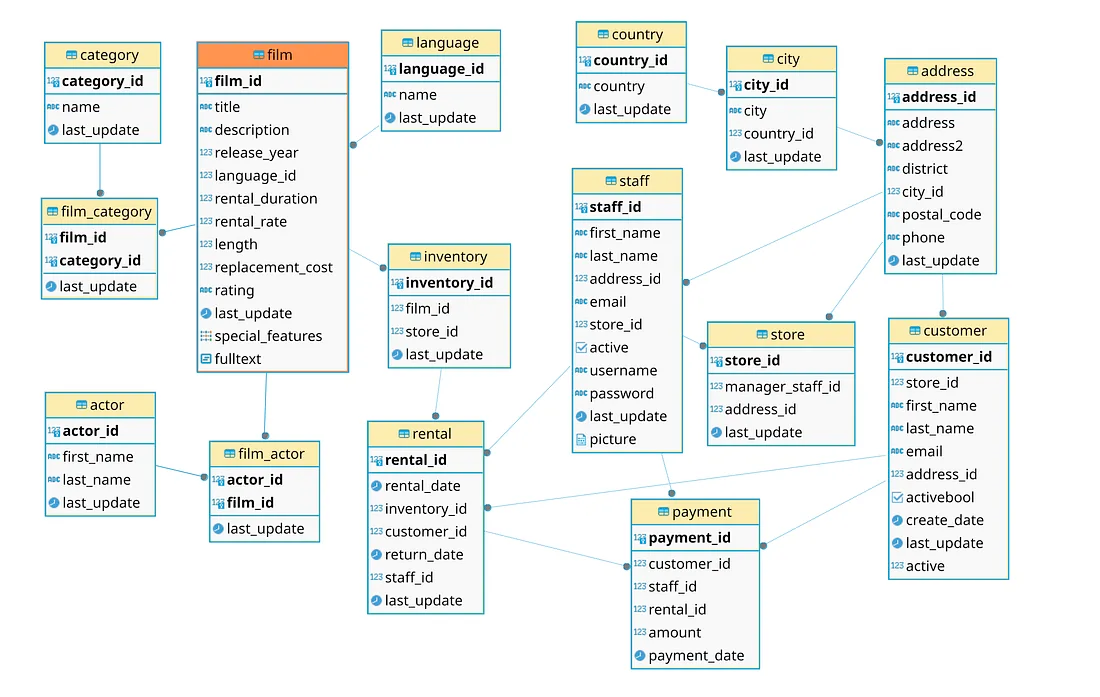
Одна из них: связи «родитель-потомок» направлены сверху вниз. Так проще перемещаться по модели.
Этап 2. Извлечение метаданных
Здесь просто подключаемся к источнику и переносим все в целевое местоположение — это, конечно, подход не для продакшена.
Сначала настроим целевую базу данных, снова запускаемся как postgres, как user0 она не создастся:
createdb -U postgres demo
Теперь нужен набор таблиц, которым принимаются данные источника, в мире ELT это точные копии таблиц источника за вычетом всех триггеров и ограничений. Создадим в базе данных DW demo специальную схему raw_1 — для сохранения необработанных данных из источника данных 1:
psql -d demo -c 'create schema raw_1'
Для каждой таблицы источника извлекается соответствующий язык описания данных, который затем применяется к целевой схеме, но сначала для выполнения запросов в базу данных dvdrental требуется user0:
psql -U postgres -d dvdrental -c "grant select on all tables in schema public to user0"
Теперь запустим простую комбинацию psql:
psql -t -d dvdrental -c "
select 'CREATE TABLE raw_1.' || table_name ||'(' ||
STRING_AGG ( column_name ||' '||
case when data_type='USER-DEFINED' then 'text' else udt_name end, ','
ORDER BY table_name, ordinal_position )
||');'
from information_schema.columns
join information_schema.tables using (table_schema,table_name)
where table_schema = 'public' and table_type = 'BASE TABLE'
group by table_name
" | psql -d demo
Для создания инструкций create table запустили psql в базе данных dvdrental, затем для их выполнения передали результат в другой psql в базе данных demo.
В схеме raw_1 получилось 15 упрощенных — без триггеров, индексов, пользовательских типов, последовательных столбцов, ограничений — таблиц, готовых принимать необработанные данные.
В реальных условиях пришлось бы создавать скрипты языка описания данных и хранить их в системе контроля версий.
Этим user0 считываются все 15 таблиц dvdrental, но не больше. Доступ для каждой новой или перестроенной таблицы предоставляется отдельно.
Этап 3. Извлечение и загрузка необработанных данных
Начальная загрузка выполняется как конвейерная комбинация этапа 2, обернутая циклом:
for tbl in `psql -t -d dvdrental -c "
select table_name
from information_schema.tables
where table_schema='public'
and table_type='BASE TABLE'
"`
do
echo -: $tbl
psql -t -d dvdrental -c "copy public.$tbl to stdout" |\
psql -t -d demo -c "copy raw_1.$tbl from stdin"
done
Дальнейшие загрузки обычно инкрементные. Пока пропустим это со всеми промежуточными этапами преобразования и перейдем к целевому DW.
Этап 4. Построение DW
Сейчас у нас имеется полная копия системы-источника. И так будет всегда. Покуда дисковое пространство не ограничение, это вполне нормально. Но позже обсудим другие сценарии.
Возьмем подмножество таблиц источника: film, inventory, store, category, а также film_category, actor и film_actor. Четыре таблицы измерения: category_dim, actor_dim, film_dim, store_dim и две таблицы фактов: film_fact, на самом деле это таблица-мост, и inventory_fact.
Чтобы загрузить целевые таблицы, выполним над хранилищем данных типичные операции: очистку данных, то есть обработку записей-дублей в таблице актеров, и нормализацию, то есть язык фильма и адрес в хранилище. Но без отдельного слоя вроде промежуточной схемы, а просто «на лету».
В целевых таблицах содержатся естественные ключи, где это возможно, или — согласно терминологии хранилища данных — «бизнес-ключи», а суррогатные ключи заимствуются из источника. Какие элементы данных сохранять, решим на следующей итерации.
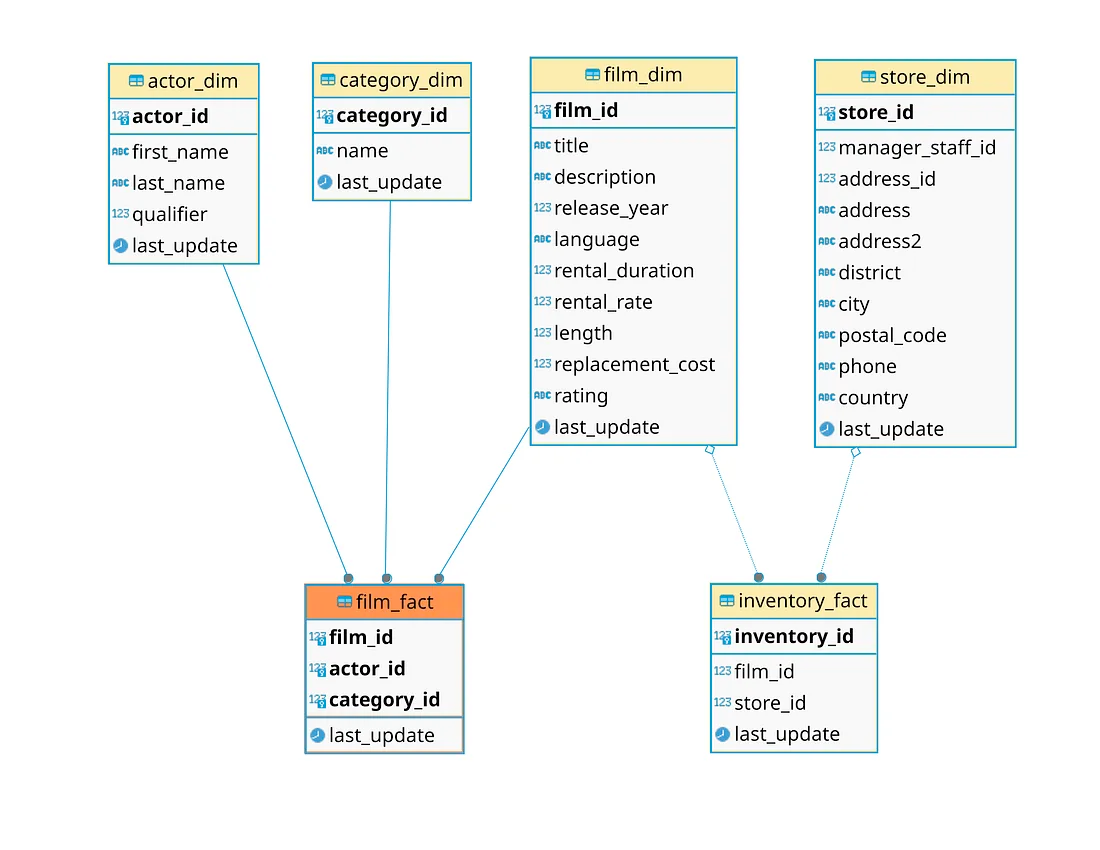
Факты расположены ниже измерений, поскольку «весомее» количественно, в итоге схема представляется в виде воздушного шара.
Скрипты для измерений:
psql -d demo -c "create schema if not exists dw"
psql -d demo -c "create table dw.category_dim as
select *
from raw_1.category;
alter table dw.category_dim add primary key (category_id);
alter table dw.category_dim add unique (name)"
psql -d demo -c "create table dw.actor_dim as
with _v as (
select *
,row_number() over (partition by first_name,last_name order by actor_id) rnum
,count(*) over (partition by first_name,last_name) rcnt
from raw_1.actor
)
select actor_id, first_name, last_name
, case when rcnt>1 then rnum end as qualifier
, last_update
from _v
;
alter table dw.actor_dim add primary key (actor_id);
alter table dw.actor_dim add unique (first_name,last_name,qualifier)"
psql -d demo -c "create table dw.film_dim as
select F.film_id, F.title, F.description, F.release_year
, L.name as language
, rental_duration, rental_rate, length, replacement_cost, rating
, greatest(F.last_update, L.last_update) as last_update
from raw_1.film F
join raw_1.language L using (language_id)
;
alter table dw.film_dim add primary key (film_id);
alter table dw.film_dim add unique (title)"
psql -t -d demo -c "create table dw.store_dim as
with _a as (
select ci.city_id, ci.city, co.country_id, co.country, ad.address_id
, ad.address, ad.address2, ad.district, ad.postal_code, ad.phone
, greatest(ci.last_update, co.last_update, ad.last_update) as last_update
from raw_1.city ci
join raw_1.country co using (country_id)
join raw_1.address ad using (city_id)
)
select st.store_id, st.manager_staff_id, st.address_id
, ad.address, ad.address2, ad.district, ad.city, ad.postal_code, ad.phone
, ad.country
, greatest(st.last_update, ad.last_update) as last_update
from raw_1.store st
join _a ad using (address_id)
;
alter table dw.store_dim add primary key (store_id)"
Скрипты для фактов:
psql -t -d demo -c "create table dw.film_fact as
select film_id, actor_id, category_id
, greatest(fa.last_update,f.last_update,fc.last_update,c.last_update) as last_update
from raw_1.film_actor fa
join raw_1.film f using(film_id)
join raw_1.film_category fc using(film_id)
join raw_1.category c using(category_id)
;
alter table dw.film_fact add primary key (film_id,actor_id,category_id)"
psql -t -d demo -c "create table dw.inventory_fact as
select *
from raw_1.inventory
;
alter table dw.inventory_fact add primary key (inventory_id)"
Перейдем ко второй итерации и предоставим эти данные пользователям.
Этап 5. Предоставление данных
Установив Metabase, запускаем java -jar metabase.jar и переходим на localhost:3000, устанавливаем java и проверяем версию java -version. Администратором Metabase становится первый, кто вошел в систему.
Указываем параметры подключения к Postgres и при необходимости создаем другого пользователя в Metabase и Postgres, предоставляя разрешения в схеме dw:

Вернемся к остальным компонентам создаваемого хранилища.
Итерация 2
Отрефакторим этапы 3 и 4 и вернемся к этапу 2.
Этап 3+. Инкрементные извлечение и загрузка необработанных данных
Создадим еще один уровень данных, схему stg_1 для системы-источника 1 dvdrental, и перераспределим процедуры обработки данных: raw_1 становится временным, а в stg_1 теперь содержится полная копия данных источника.
Выполним инкрементную загрузку stg_1 при помощи delta — части исхочника, извлекаемой в raw_1. Процессом Delta обозначается, что мы работаем только с той частью, которая отличается от предыдущего и текущего состояний источника. Часть delta выбирается по временны́м меткам last_update или эквивалентным.
Поскольку извлекаются только имеющиеся записи источника согласно снимку, возможны такие варианты:
- Записи в копии источника, которых больше нет в источнике, никогда не удаляются.
- Периодически выполняется полная перезагрузка и удаление записей, которых больше нет в источнике, или, скорее, мягкое удаление.
- Чтобы извлечь список удаленных записей и перенести его в целевое местоположение, выполняются обновления системы-источника.
- Выполняется захват изменения данных, это универсальный вариант.
Проще всего реализуется первый, но здесь увеличивается нагрузка на конечных пользователей, когда, например, по количеству сотрудников нужно определить закрытые хранилища. Для первого варианта выполняются вставка-обновление, объединение или удаление-вставка.
Сначала создадим схему stg_1 с 15 таблицами, как в этапе 2, загрузим таблицы, затем добавим тестовые записи источника в film — одну новую, в category — одну новую, в actor — две новых и одну измененную:
psql -U postgres -d dvdrental -c "
insert into category values(10017,'Western');
insert into film values(11001,'Tres Amigos','Test 1 film',2022,2,5,1.99,55,22.2,'R');
insert into film_category values(11001,10017);
insert into film_category values(11001,9);
insert into actor values(10201,'Amigo','Uno');
insert into actor values(10202,'Amigo','Dos');
insert into film_actor values(10201,11001);
insert into film_actor values(10202,11001);
update inventory set film_id=11001 where inventory_id=1;
update actor set last_name='Davids' where actor_id=110"
В параметрах указываем временной интервал для цикла загрузки:
cycle_from=2024-01-01
cycle_upto=2025-01-01
(
echo cycle_from=$cycle_from, cycle_upto=$cycle_upto
while read tbl ts
do
echo -: $tbl $ts
psql -t -d dvdrental -c "copy (select * from public.$tbl \
where $ts>='$cycle_from' and $ts<'$cycle_upto') to stdout" |\
psql -t -d demo -c "truncate raw_1.$tbl; copy raw_1.$tbl from stdin"
done
)<<EOF
actor last_update
film last_update
film_category last_update
inventory last_update
language last_update
rental last_update
staff last_update
payment payment_date
film_actor last_update
store last_update
address last_update
customer last_update
category last_update
city last_update
country last_update
EOF
Здесь список параметров отправляется в цикл, которым считываются данные из источника и загружается схема raw_1 — согласно указанному временному интервалу. При извлечении данных источника включается левый и исключается правый интервалы, так процесс больше контролируется.
Обновим полную копию источника, хранимую в stg_1:
(
echo cycle_from=$cycle_from, cycle_upto=$cycle_upto
while read tbl key
do
echo -: $tbl $key
psql -t -d demo -c "
delete from stg_1.$tbl where ($key) in (select $key from raw_1.$tbl);
insert into stg_1.$tbl select * from raw_1.$tbl"
done
)<<EOF
actor actor_id
film film_id
film_category film_id,category_id
inventory inventory_id
language language_id
rental rental_id
staff staff_id
payment payment_id
film_actor actor_id,film_id
store store_id
address address_id
customer customer_id
category category_id
city city_id
country country_id
EOF
Теперь все можно перестроить, как в этапе 4, данные берутся только из схемы stg_1. Просто, но на это требуется время. Рассмотрим инкрементный подход.
Этап 4+. Инкрементное создание DW.
Теперь создадим хранилище данных delta DW. Вот, например, select в SQL для film_dim:
select F.film_id, F.title, F.description, F.release_year
, L.name as language
, rental_duration, rental_rate, length, replacement_cost, rating
, greatest(F.last_update, L.last_update) as last_update
from $schs.film F
join $schs.language L using (language_id)
where ( F.$ts>='$cycle_from' and F.$ts<'$cycle_upto'
or L.$ts>='$cycle_from' and L.$ts<'$cycle_upto' )
;
Здесь schs — это stg_1, ts — это last_update, а интервал цикла задается двумя переменными: cycle_from и cycle_upto. С этим or в предложении where из таблиц-участниц выбираются все записи, которые могут повлиять на целевое местоположение. То есть создается замыкание. Например, обновлений языка language нет, а нужные записи из этой таблицы все равно считываются, хотя и не все.
Вот полные скрипты.
На заключительном этапе, используя тот же подход удаления-вставки, обновляем целевое хранилище данных в схеме dw из хранилища данных delta в схеме stg_1:
schs=stg_1
scho=dw
(
echo cycle_from=$cycle_from, cycle_upto=$cycle_upto
while read tbl key
do
echo -: $tbl $key
psql -t -d demo -c "
delete from $scho.$tbl where ($key) in (select $key from $schs.$tbl);
insert into $scho.$tbl select * from $schs.$tbl"
done
)<<EOF
actor_dim actor_id
category_dim category_id
film_dim film_id
film_fact film_id,actor_id,category_id
inventory_fact inventory_id
store_dim store_id
EOF
Если запускать скрипты DW прямо в базе данных источника, не понадобятся копия источника в raw_1 и сложные преобразования: достаточно простым select создать замыкание и продолжать в промежуточной области.
В реальных условиях, чтобы создать хранилище данных, потребуется больше преобразований и слоев в виде представлений или таблиц на большем количестве схем. Сколько именно — определяется конкретным проектом. Но обнаруживается минимум два общих этапа: один для объединения данных из разных источников, другой для достижения требуемого уровня качества данных.
Планировщик
Представим планировщик для запуска циклов DW. При создании пилотной версии все запускается вручную из командной строки, в продакшене же стоит воспользоваться более цивилизованным способом. Но не crontab, а простым Rundeck.
Сначала загружаем версию сообщества Rundeck, создаем проект и импортируем задание при помощи опции Remove UUIDs, как описано здесь:
- defaultTab: nodes
description: 'DW cycle - extract delta part, load, then transform to DW'
executionEnabled: true
id: -Dont-forget-Remove-UUIDs-option-
loglevel: INFO
name: DW cycle - ELT
nodeFilterEditable: false
plugins:
ExecutionLifecycle: {}
schedule:
dayofmonth:
day: '*'
month: '*'
time:
hour: 9-19
minute: 0/10
seconds: '0'
year: '*'
scheduleEnabled: true
sequence:
commands:
- configuration:
export: PGUSER
group: export
value: user0
description: globals
nodeStep: false
type: export-var
- exec: PGUSER=${export.PGUSER} /home/${export.PGUSER}/DataProcess/dw-cycle--EL.sh
- exec: PGUSER=${export.PGUSER} /home/${export.PGUSER}/DataProcess/dw-cycle--T.sh
keepgoing: false
strategy: node-first
uuid: -Dont-forget-Remove-UUIDs-option-
Загружаем скрипты DW для циклического задания Rundeck и помещаем в каталог DataProcess.
Все скрипты DW и каталоги, включая домашний, должны быть доступны пользователю rundeck, если Rundeck так выполняется.
Задание запускается каждые 10 минут, найденные в базе данных dvdrental новые или обновленные записи обрабатываются. Например, добавляем эти записи:
psql -U postgres -d dvdrental -c "insert into staff values(10003,'William','Bonce',1,'bill@noname.net',1,true,'Bill',null,now())"
psql -U postgres -d dvdrental -c "insert into store values(10003,10003,1)"
И смотрим, как это отражается в таблице хранилища данных store_dim, а также журнал в Rundeck.
Итерация 3
Поговорим о задачах, которые должны включаться в процесс обработки данных, но часто не включаются, а именно о тестах. Это два типа тестов: тесты качества данных, выполняемые в каждом цикле как часть процесса продакшена, и приемочные тесты или тесты сборки, которые выполняются до того, как код помечается как готовый к продакшену — выполняются вручную или как часть непрерывной интеграции и непрерывного развертывания.
Этап 5. Тесты качества данных
Как пример посмотрим, имеются ли в DW родители без потомков. Воспользуемся только что добавленной записью 10003 хранилища: по меньшей мере подозрительно, когда хранилище обходится без инвентаризации. Возвращение следующим оператором минимум одной записи — это сигнал об ошибке или предупреждении:
psql -t -d demo -c "
select S.* from dw.store_dim S
left join dw.inventory_fact I using (store_id)
where I.store_id is null"
Другой случай: если в системе имеются потомки без родителей, в большинстве случаев это ошибка. Удалим вручную из film_dim запись с film_id=1, а затем запустим:
psql -t -d demo -c "
select FA.* from dw.film_fact FA
left join dw.film_dim FD using (film_id)
where FD.film_id is null"
Опять же, если этим запросом что-то возвращается, имеется проблема.
Что нужно проверять, диктуется здравым смыслом и опытом. Такие тесты необходимы для предоставления цикла конечным пользователям и включаются в последний(-ие) этап(-ы) в задании цикла DW. Другие тесты не более чем справочные, за ними нужно приглядывать, но процессы ими никогда не блокируются. Те же ошибки и предупреждения.
Вот простой скрипт для запуска таких тестов, он включается в последний этап цикла хранилища данных:
-:- warning tests...
-: film-facts-without-film.sql
Warning! record sample:
film_id | actor_id | category_id | last_update
---------+----------+-------------+-------------------------
1 | 188 | 6 | 2013-05-26 14:50:58.951
1 | 198 | 6 | 2013-05-26 14:50:58.951
1 | 40 | 6 | 2013-05-26 14:50:58.951
-:- error tests...
-: store-empty-for-1-day.sql
Error! record sample:
store_id | manager_staff_id | address_id | address | address2 | district | city | postal_code | phone | country | last_update
----------+------------------+------------+-------------------+----------+----------+------------+-------------+-------+---------+----------------------------
10003 | 10003 | 1 | 47 MySakila Drive | | Alberta | Lethbridge | | | Canada | 2024-12-19 18:09:05.225573
(1 row)
-: store-empty-for-3-days.sql
Последний тест выполнился, поэтому выходных данных нет, первый же тест на наличие ошибок не выполнился, и всем скриптом возвращается код ошибки 1. Если переместить скрипт store-empty-for-1-day.sql в warnings/, задание выполнится:
├── cycle-tests
│ ├── errors
│ │ ├── store-empty-for-1-day.sql
│ │ └── store-empty-for-3-days.sql
│ └── warnings
│ └── film-facts-without-film.sql
На DBT тесты выполняются аналогично.
Для включения тестов в задание Rundeck достаточно добавить задание-оболочку, которой вызывается задание основного цикла и затем выполняется еще один этап:
Этап 6. Тесты сборки
В рабочем процессе непрерывной интеграции и непрерывного развертывания база данных dvdrental используется как образец, затем выполняются два-три цикла и результаты сравниваются с сохраненными копиями DW. Необязательно хранить фактические таблицы, достаточно контрольной суммы или хеша для каждой таблицы или для столбца, группы столбцов, разбитых на группы записей… все что угодно. Применяется такая табличная структура:
create schema etl;
create table etl.stored_hash_values (
schema_name text
,table_name text
,table_group text
,column_name text
,column_group text
,cycle_id text
,cycle_tag text
,record_count int
,hash_value bigint
);
А таким скриптом она загрузится с записями, запускается единожды после каждого цикла тестов:
sch=stg_1
(
echo cycle=$cycle
while read tbl
do
echo -: $tbl
psql -t -d demo -c "
with _v as (
select hashtext(concat(t.*)) hash_value
from $sch.$tbl t
)
insert into etl.stored_hash_values
select '$sch','$tbl',null,null,null,$cycle,null
,count(*), sum(hash_value)
from _v"
done
)<<EOF
actor
film
film_category
inventory
language
rental
staff
payment
film_actor
store
address
customer
category
city
country
EOF
Затем, чтобы убедиться, что новым кодом ничего не ломается, запускаем тот же скрипт с загрузкой значений в другую временную таблицу и сравниваем результаты с сохраненными значениями. Это другой тестовый скрипт, которым отыскиваются записи без несоответствия. Если бы такие записи имелись, тестовый этап планировщика бы прерывался.
Заключение
Хоть и не каждую деталь мы объяснили, весь процесс должен быть достаточно понятен для использования в качестве основы.
Бонус
Если нужен DBT, начните тестами с минимальной его конфигурацией. Имея установленный Python, загрузите и установите DBT. Добавьте в ~/.dbt/profiles.yml параметры подключения:
profile_pg_local_demo_user0:
outputs:
dev:
dbname: demo
host: localhost
pass: .
port: 5432
schema: dw
threads: 1
type: postgres
user: user0
target: dev
Создайте в DataProcess отдельный каталог dbt, скопируйте туда тестовые файлы и добавьте другой yaml-файл:
.
├── dbt_project.yml
└── tests
├── errors
│ ├── store-empty-for-1-day.sql
│ └── store-empty-for-3-days.sql
└── warnings
└── film-facts-without-film.sql
Теперь заполните файл dbt_project.yml вот этим:
name: 'project_dw'
config-version: 2
version: '0.0.1'
profile: 'profile_pg_local_demo_user0'
Вот и все. Из подкаталога dbt запустите dbt build примерно так:
09:45:57 Running with dbt=1.8.8
09:45:57 Registered adapter: postgres=1.8.2
09:45:58 Found 3 data tests, 423 macros
09:45:58
09:45:58 Concurrency: 1 threads (target='dev')
09:45:58
09:45:58 1 of 3 START test film-facts-without-film ...................................... [RUN]
09:45:58 1 of 3 FAIL 10 film-facts-without-film ......................................... [FAIL 10 in 0.03s]
09:45:58 2 of 3 START test store-empty-for-1-day ........................................ [RUN]
09:45:58 2 of 3 FAIL 1 store-empty-for-1-day ............................................ [FAIL 1 in 0.01s]
09:45:58 3 of 3 START test store-empty-for-3-days ....................................... [RUN]
09:45:58 3 of 3 PASS store-empty-for-3-days ............................................. [PASS in 0.02s]
09:45:58
09:45:58 Finished running 3 data tests in 0 hours 0 minutes and 0.11 seconds (0.11s).
09:45:58
09:45:58 Completed with 2 errors and 0 warnings:
09:45:58
09:45:58 Failure in test film-facts-without-film (tests/warnings/film-facts-without-film.sql)
09:45:58 Got 10 results, configured to fail if != 0
09:45:58
09:45:58 compiled code at target/compiled/project_dw/tests/warnings/film-facts-without-film.sql
09:45:58
09:45:58 Failure in test store-empty-for-1-day (tests/errors/store-empty-for-1-day.sql)
09:45:58 Got 1 result, configured to fail if != 0
09:45:58
09:45:58 compiled code at target/compiled/project_dw/tests/errors/store-empty-for-1-day.sql
09:45:58
09:45:58 Done. PASS=1 WARN=0 ERROR=2 SKIP=0 TOTAL=3
При сбое любого теста возвращается 1, проверьте с помощью echo $?, для планировщика Rundeck этого достаточно. В dbt run ничего не делается, поскольку модель не определена.
Читайте также:
- PostgreSQL и MySQL: подробное сравнение
- Продвинутые техники SQL
- Интеграция Django с материализованными представлениями PostgreSQL
Читайте нас в Telegram, VK и Дзен
Перевод статьи sefedo: End to end ELT process example for DW using Postgres





