
Большие языковые модели (LLM) обучаются на огромном корпусе текстовых данных, по сути поглощая весь интернет на этапе предварительного обучения. LLM раскрывают свой потенциал, когда у них есть доступ ко всем релевантным данным, чтобы дать соответствующий ответ на вопрос пользователя.
Однако во многих случаях мы ограничиваем возможности LLM, не предоставляя им достаточно данных. В этой статье я расскажу, почему стоит задуматься о том, чтобы «кормить» LLM большим количеством данных, как получать эти данные и какие бывают конкретные примеры использования такого подхода.

Содержание
- Зачем добавлять в LLM больше данных?
- Поиск дополнительных метаданных
- Информационный поиск метаданных
- Варианты использования метаданных в LLM
- Заключение
Зачем добавлять в LLM больше данных?
Начну с пояснения. LLM невероятно прожорливы в плане данных, то есть для эффективной работы им требуется огромный объем информации. Это наглядно демонстрирует корпус данных для предварительного обучения LLM, который состоит из триллионов текстовых токенов, используемых для тренировки модели.
Однако принцип использования большого объема данных применим к LLM и во время инференса (когда модель используется в рабочей, продакшн-среде). Необходимо предоставлять LLM все нужные данные, чтобы она могла ответить на запрос пользователя.
Во многих случаях мы невольно снижаем производительность LLM, не снабжая ее релевантной информацией.
Представьте систему вопросов и ответов, где пользователи могут загружать файлы и взаимодействовать с ними. Естественно, вы предоставляете текстовое содержимое каждого файла, чтобы пользователь мог «общаться» с документом. Однако можно, допустим, забыть добавить к контексту разговора названия этих документов. Это повлияет на производительность LLM, например, если какая-то информация есть только в имени файла или если пользователь ссылается на это имя в чате.
Вот еще несколько конкретных примеров применения LLM, где полезны дополнительные данные:
- классификация;
- извлечение информации;
- поиск ключевых слов для нахождения релевантных документов, которые можно передать LLM.
Ниже я расскажу, где можно найти такие данные, а также о методах извлечения дополнительных данных и о некоторых конкретных вариантах их использования.
Поиск дополнительных метаданных
В этом разделе я рассмотрю данные, которые, вероятно, уже есть в вашем приложении. Один из примеров — моя предыдущая аналогия с системой вопросов и ответов для файлов, где вы забыли добавить название файла в контекст. Вот другие примеры:
- расширения файлов (.pdf, .docx, .xlsx);
- путь к файлу (если пользователь загрузил целую папку);
- временные метки (например, если пользователь запрашивает самый последний документ, эта информация необходима);
- номера страниц (пользователь может попросить LLM найти конкретную информацию, расположенную на странице 5).
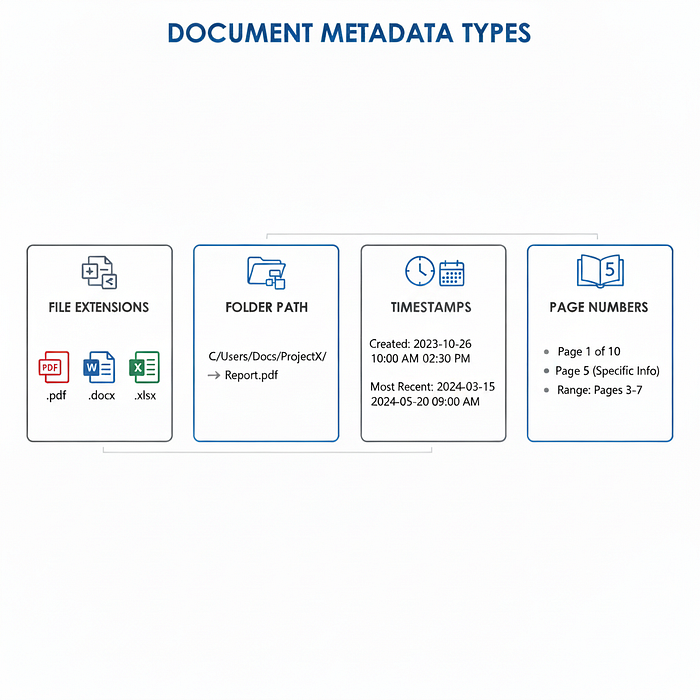
Существует множество других подобных примеров данных, которые у вас, вероятно, уже есть или которые можно быстро получить и добавить в контекст LLM.
Типы доступных данных могут сильно различаться в зависимости от приложения. Многие примеры, которые я привел в этой статье, ориентированы на текстовый ИИ, так как это та область, в которой я работаю больше всего. Однако если вы, например, работаете в сфере визуального или аудио-ИИ, вы сможете найти аналогичные примеры в этой нише.
Для визуального ИИ это могут быть:
- геоданные о месте, где было сделано фото или видео;
- имя файла изображения или видео;
- автор файла.
Возможные варианты для аудио-ИИ:
- метаданные о том, кто и когда говорит;
- временные метки для каждого предложения;
- геоданные о месте записи.
Суть в том, что существует огромное количество доступных данных; все, что вам нужно сделать, — это поискать их и подумать, как они могут пригодиться в вашем приложении.
Информационный поиск метаданных
Иногда тех данных, которые уже есть в вашем распоряжении, оказывается недостаточно. Возможно, понадобится предоставить LLM еще больше информации, чтобы помочь ей адекватно отвечать на вопросы. В таком случае потребуется получить дополнительные данные. Естественно, поскольку мы живем в эпоху больших языковых моделей, будем использовать сами LLM для получения этих данных.
Предварительный сбор информации
Самый простой подход — извлечь дополнительные данные до обработки живых запросов. В контексте ИИ для работы с документами это означает извлечение конкретной информации из документов на этапе их обработки. Можно извлекать тип документа (юридический документ, налоговый документ, рекламный буклет) или конкретную информацию, содержащуюся в документе (даты, имена, местоположения и т. д.).
Преимущества предварительного сбора информации:
- скорость (в рамках рабочей среды вам нужно только получить значение из базы данных);
- эффективность (можно использовать пакетную обработку для снижения затрат).
Сегодня извлечение такого рода информации довольно просто. Вы настраиваете LLM с помощью специального системного промпта для сбора информации и подаете этот промпт вместе с текстом в LLM. Модель обработает текст и извлечет для вас релевантную информацию.
Также стоит заранее определить все информационные точки для извлечения, например:
- местоположение;
- даты;
- имена;
- …
После составления этого списка можно извлечь все метаданные и сохранить их в базе данных.
Однако главный недостаток предварительного сбора информации заключается в том, что вам нужно заранее определить, какую именно информацию извлекать. Во многих сценариях это сложно сделать, и в таких случаях можно применить динамический информационный поиск, который я рассмотрю в следующем разделе.
Динамический информационный поиск (по требованию)
Когда вы не можете заранее определить, какую информацию нужно извлечь, можно сделать это по требованию. Это означает настройку универсальной функции, которая принимает в качестве параметров тип извлекаемых данных и текст, из которого нужно их извлечь.
Например:
Copyimport jsonИзвлеки следующие данные из приведенного ниже текста и верни их в виде объекта JSON.
def retrieve_info(data_point: str, text: str) -> str:
prompt = f"""
Data Point: {data_point}
Text: {text}
Example JSON Output: {{"result": "example value"}}
"""
return json.loads(call_llm(prompt))
Вы определяете эту функцию как инструмент, доступный вашей LLM, который она может вызывать при необходимости. Именно так компания Anthropic настроила свою систему глубокого поиска (deep research): они создают главный агент-оркестратор, который может порождать дочерние агенты для получения дополнительной информации.
Важно отметить, что предоставление LLM доступа к использованию дополнительных промптов может привести к значительному расходу токенов, поэтому следует внимательно следить за их потреблением.
Варианты использования метаданных в LLM
До сих пор мы говорили о том, почему стоит использовать дополнительные данные и как их получить. Однако для полного понимания также приведу конкретные примеры применения, где эти данные улучшают производительность LLM.
Поиск с фильтрацией по метаданным
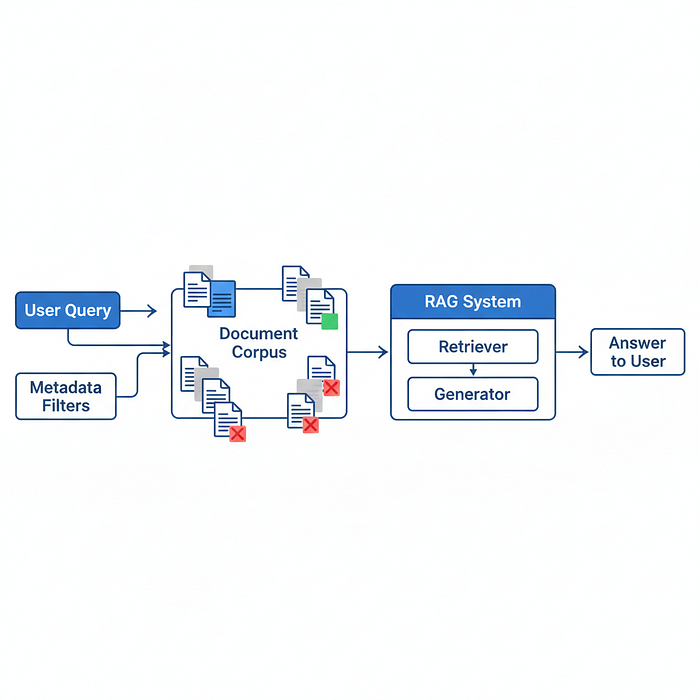
Мой первый пример — это возможность выполнять поиск с фильтрацией по метаданным. Указание такой информации, как:
- тип файла (pdf, xlsx, docx, …);
- размер файла;
- имя файла
поможет приложению в получении релевантной информации. Например, это может быть информация, которая будет загружена в контекст LLM, как при использовании RAG (Retrieval-Augmented Generation). Можете использовать дополнительные метаданные, чтобы отфильтровать неподходящие файлы.
Например, пользователь задает вопрос, относящийся только к документам Excel. В этом случае применение RAG для извлечения фрагментов из файлов, отличных от Excel, будет неэффективным использованием контекстного окна LLM. Вместо этого следует отфильтровать доступные фрагменты, оставив только документы Excel, и использовать их для оптимального ответа на запрос пользователя.
Поиск в интернете с помощью ИИ-агента
Приведу еще один пример. Допустим, вы задаете своему ИИ-агенту вопросы о недавних событиях, произошедших после даты окончания предварительного обучения LLM. Как правило, у языковых моделей есть ограничение по датам для обучающих данных, поскольку данные требуют тщательной подготовки, и поддерживать их в состоянии актуальности — сложная задача.
Это создает проблему, когда пользователи спрашивают о недавних событиях, например, о каких-нибудь новостях. В этом случае ИИ-агенту, отвечающему на запрос, необходим доступ к поиску в интернете (по сути, извлечение информации из сети). Это пример динамического извлечения информации (on-demand information extraction).
Заключение
Итак, вы узнали, как можно значительно улучшить LLM, предоставив ей дополнительные данные. Их можно найти в существующих метаданных (имена файлов, их размер, геолокация) или извлечь с помощью информационного поиска (тип документа, имена, упомянутые в документе, и т. д.). Эта информация часто критически важна для способности LLM успешно отвечать на запросы пользователей, и во многих случаях отсутствие таких данных практически гарантирует, что модель не даст корректный ответ на вопрос.
Читайте также:
- Обучение LLM (и не только) на Go. С Python в люльке
- Что если LLM лучше, чем мы думаем?
- Создание локально работающего голосового помощника
Читайте нас в Telegram, VK и Дзен
Перевод статьи Eivind Kjosbakken: How to Enrich LLM Context to Significantly Enhance Capabilities

![[SwiftUI] @AppStorage: управление UserDefaults с помощью ViewModel](https://nuancesprog.ru/wp-content/uploads/2025/02/SwiftUI-pattern-100x70.png "[SwiftUI] @AppStorage: управление UserDefaults с помощью ViewModel")



