
Появление нового функционала или системы вроде автомасштабирования никогда не обходится без багов и сбоев. Причина — поведение при запуске и перезапуске или выключении сервисов в случайных событиях. Для устранения этих проблем включаются шаблоны проектирования, тесты.
Как сказал Мартин Клеппман:
Чем больше становится система, тем вероятнее, что один из ее компонентов сломан. Со временем сломанное чинится, ломается что-то новое — в системе с тысячами узлов разумно предположить, что что-то всегда ломается. Если бы стратегия устранения ошибок заключалась в капитуляции, такая крупная система никогда бы не была рабочей.
Рассмотрим их на примере реальной проблемы: все больше пользователей заходят на сайт, но зарегистрироваться получается очень немногим, это просто катастрофа.
При изучении проблемы быстро обнаруживается: работа сервиса и базы данных корректна, а узким местом является API отправки сообщений. Из-за него случилась блокировка. Сервис тоже начал блокироваться, поскольку выполнялся синхронный запрос.
Регистрация оказалась невозможной «благодаря» единственному слабому звену со сторонним API. Теперь понятно, почему нужно учитывать сбои. Но как это делать при реализации шаблонов проектирования?
Подход «запустил и забыл»
Здесь этот подход оптимальный. Просто добавляем запрос со всеми деталями сообщения в высокодоступную очередь, которой гарантируется минимум одна доставка, и идем пить кофе. Отдельным воркером записи очереди обрабатываются и отправляются в сторонний API. Если там начинаются проблемы, прекращаем обработку очереди — на сервисе регистрации это никак не скажется.
Вот пример отправляемого приветственного сообщения: вместо того чтобы напрямую вызывать последующий сервис по его интерфейсу REST или RPC, добавляем в очередь событие со всеми деталями для обработки этого сообщения получателем:
{
"id": "ABCDERE2342323SDSD",
"queue" "registration.welcome_email",
"dispatch_date": "2016-03-04 T12:23:12:232",
"payload": {
"name": "Nic Jackson",
"email": "mail@nicholasjackson.io"
},
"error": [{
"status_code": 3343234,
"message": "Message rejected from mail API, quota exceeded",
"stack_trace": "mail_handler.go line 32 ...",
"date": "2016-03-04 T12:24:01:132"
}]
}
Добавляем эту ошибку каждый раз, когда не удается обработать сообщение. И перед глазами будет история того, что случилось, а также количество попыток обработать сообщение. Когда пороговое значение превышено, перемещаем это сообщение во вторую очередь — для диагностической информации.
Очередь недоставленных сообщений
Будь у нас очередь order_service_emails, мы бы создали и вторую — order_service_emails_deadletter и при отладке системы просматривали бы в ней необработанные сообщения. Мало знать, что случилась ошибка, нужно разобраться, что это за ошибка. А добавляя сведения об ошибке прямо в тело сообщения, мы получаем историю именно там, где она и нужна.
Задержка
Повторы сразу после сбоя подключения, как правило, не желательны — иначе сеть или сервер переполнится запросами. Чтобы этого избежать, в стратегии повторов реализуется задержка. Алгоритмом задержки предусматривается время ожидания после первого сбоя до повтора, с последующими сбоями оно увеличивается до максимальной продолжительности.
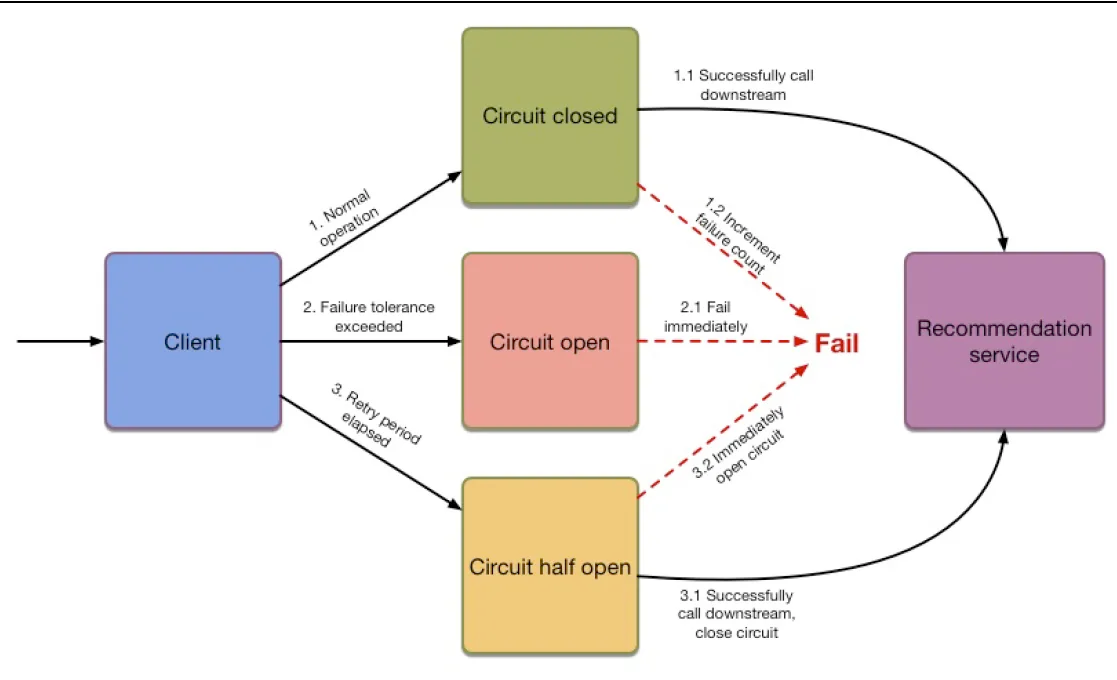
Выключатель
При нормальной работе выключатель — подобно автомату в электрощитке — замыкается, и трафик осуществляется в обычном режиме.
Когда же предварительно заданный порог ошибки превышен, выключатель переводится в открытое состояние и сразу случается сбой всех запросов, даже не предпринятых. Спустя время допускается следующий запрос и выключатель переводится в полуоткрытое состояние, в котором сбой немедленно возвращается в открытое состояние, независимо от порога ошибки errorThreshold.
Как только запросы обработаются без ошибок, выключатель вернется в закрытое состояние; он снова откроется, только если количеством сбоев превышен порог ошибки.
Проиллюстрируем примерами кода.
В Go имеется пакет go-resilience, выключатели создать легко:
func New(errorThreshold, successThreshold int, timeout time.Duration) *Breaker
Создаем выключатель с тремя параметрами
errorThreshold— это количество сбоев запроса, прежде чем выключатель откроется.successThreshold— сколько нужно успешных запросов в полуоткрытом состоянии, прежде чем вернуться к открытому.timeout— сколько времени выключатель останется в открытом состоянии, прежде чем переместится в полуоткрытое.
b := breaker.New(3, 1, 5*time.Second)
for {
result := b.Run(func() error {
// вызывается сервис
time.Sleep(2 * time.Second)
return fmt.Errorf("Timeout")
})
switch result {
case nil:
// успех
case breaker.ErrBreakerOpen:
// функция не вызвалась, так как выключатель был открыт
fmt.Println("Breaker open")
default:
fmt.Println(result)
}
time.Sleep(500 * time.Millisecond)
}
Пока переварите это, а потом переходите к обнаружению сервисов, балансировке нагрузки, троттлингу.
Читайте также:
- Чистая архитектура фронтенда
- Реализация паттерна доступа к данным при работе с Drizzle
- 5 типичных ошибок веб-разработчиков
Читайте нас в Telegram, VK и Дзен
Перевод статьи Swarup: Backend Design patterns





