
Хотеть большего — не всегда хорошо.
Не верите? Спросите дата-инженера, который берется за задачи, потому что не может сказать «нет». О, это вы? Простите, не хотел обидеть.
Или того исполнителя, которому добавили в очередь еще пять задач, потому что он — это снова вы? — не разобрался, сколько ядер исполнителя требуется заданию Spark.
А если серьезно, как настроить кластер Spark для эффективной обработки 100 Гб данных?
Шаг 1. Количество ядер исполнителя
Начнем с того, сколько нужно ядер исполнителя:
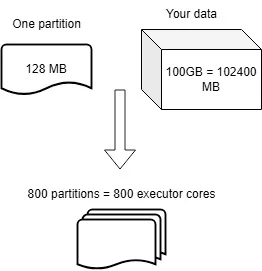
- по умолчанию размер одного раздела — 128 Мб, запомним это;
- требуемое количество ядер рассчитывается, исходя из общего количества разделов:
- 100 Гб = 100\*1024 Мб = 102400 Мб;
- Количество разделов = 102400/128 = 800.
- То есть всего требуется 800 ядер исполнителя:
Шаг 2. Количество исполнителей
Зная количество ядер, определим, сколько требуется исполнителей:
- в среднем на одного исполнителя рекомендуется по 2–5 ядер исполнителя;
- если взять количество ядер исполнителя на одного исполнителя = 4, то общее количество исполнителей = 800/4 = 200;
- то есть для выполнения этой задачи требуется 200 исполнителей.
Очевидно, это число варьируется в зависимости от того, сколько ядер исполнителя берется на одного исполнителя.
Шаг 3. Общий объем памяти исполнителя
Это важный этап, сколько памяти выделяется каждому исполнителю:
Общий объем памяти ядра исполнителя по умолчанию равен
4хкратному объему памяти раздела по умолчанию = 4 * 128 = 512 Мб.
Следовательно, общий объем памяти исполнителя = количество ядер * 512 = 4 * 512 = 2 Гб.
Подводим итог: общий объем памяти для обработки 100 Гб данных
Определим общий объем памяти, который потребуется для обработки 100 Гб данных:
- на каждого исполнителя приходится 2 Гб памяти;
- а всего исполнителей 200.
Следовательно, чтобы обработать 100 Гб данных полностью параллельно, потребуется минимум 400 Гб общей памяти.
То есть все задачи выполнятся параллельно.
Если одна задача выполняется пять минут, за сколько обработается 100 Гб данных? Ответ: за пять минут, ведь все задачи выполнятся параллельно.
Дополнительный этап
Память драйвера:
- она зависит от конкретного сценария;
- если запустить
df.collect(), потребуется 100 Гб памяти драйвера, ведь драйверу отправятся данные всех исполнителей; - если вывод просто экспортировать в облако или на диск, то память драйвера в идеале вдвое превысит объем памяти исполнителя = 4 Гб.
Вот как эффективно обрабатывается 100 Гб данных. Это идеальное решение, которое подгоняется под бюджет проекта: если он ограничен, количество исполнителей легко сокращается вдвое или вчетверо. Но и время на обработку увеличится.
Читайте также:
- 8 экспертных советов по использованию Apache Spark
- Дашбордное решение Apache Superset
- Создание локального озера данных с нуля
Читайте нас в Telegram, VK и Дзен
Перевод статьи Avin Kohale: Spark — Beyond basics: Required Spark memory to process 100GB of data





