
Что такое «запаздывание Kafka»?
Запаздывание получателя — это разница между последним смещением, сохраненным брокером, и последним фиксированным смещением для конкретного раздела. То есть это количество отправленных сообщений темы, которые еще не получены пользователями.
Если отправителем отправляются сообщения со смещениями от 1 до 100, а получателем обработаны сообщения со смещением до 80, запаздывание для этой группы получателей равно 20. Значит, 20 сообщений в теме получателем еще не обработано.
При настройке автомасштабирования не по использованию процессора/памяти, а по запаздыванию Kafka применяется KEDA или Prometheus Adapter.
Что именно применять, определим из такого сценария.
На маркетплейсе во время распродаж случаются внезапные всплески трафика. Каждый такой всплеск сопровождается ростом сообщений Kafka, что чревато запаздыванием. При KEDA система масштабируется в реальном времени, мгновенно реагируя на запаздывание Kafka и не дожидаясь периодического сбора метрик Prometheus. Это идеально для высокодинамичных систем, управляемых событиями. Prometheus Adapter же оптимален в средах, где допустима небольшая задержка и Prometheus уже используется для других метрик.
Благодаря такой гибкости KEDA выбирают для задач событийно ориентированного масштабирования реального времени. Но, если Prometheus у вас уже настроен на сбор других метрик и добавлять в кластер поды не желательно, выберите Prometheus Adapter.
Что такое KEDA?
При помощи управляемого событиями автомасштабирования KEDA, или Kubernetes Event-Driven Autoscaling, приложения масштабируются на основе внешних источников событий: очередей сообщений, баз данных или HTTP-запросов. Этот инструмент является мостом между событийно ориентированными рабочими нагрузками и горизонтальным автомасштабировщиком подов Kubernetes — для более динамичного масштабирования, исходя из потребностей реального времени.
Благодаря встроенной в KEDA поддержке источников событий, рабочие нагрузки масштабируются на основе внешних метрик.
Настройка KEDA
KEDA настраивается двумя способами:
1) встроенными метриками Kafka;
2) при помощи Prometheus как источника-триггера.
Настройка KEDA встроенными метриками
Устанавливаем Keda:
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda — namespace keda — create-namespace
Создаем ScaledObjects:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-lag-scaler
namespace: default
spec:
scaleTargetRef:
kind: Deployment
name: your-consumer-deployment
minReplicaCount: 1
maxReplicaCount: 10
triggers:
— type: kafka
metadata:
bootstrapServers: “<kafka-service>.<kafka-namespace>.svc.cluster.local:9092”
topic: “your-kafka-topic”
consumerGroup: “your-consumer-group”
lagThreshold: “10” #количество запаздываний, на которых приложение масштабируется
offsetResetPolicy: "latest"
ScaledObjects — это эквивалент горизонтального автомасштабировщика подов.
Развертываем ScaledObject и проверяем:
kubectl apply -f scaledobjects.yaml
kubectl get scaledobjects
Проверяем пользовательские метрики:
kubectl get — raw “/apis/custom.metrics.k8s.io/v1beta1” | jq
kubectl api-resources - api-group=custom.metrics.k8s.io
kubectl get apiservices | grep custom.metric
Настройка KEDA с Prometheus как источником-триггером
Устанавливаем kafka-lag-exporter:
helm install kafka-lag-exporter . — namespace monitoring — set clusters[0].name=monitoring — set clusters[0].bootstrapBrokers=<kafka-service>.<kafka-namespace>.svc.cluster.local:9092
Редактируем values.yaml из чарта Helm и добавляем:
clusters:
- name: "monitoring"
bootstrapBrokers: "<kafka-service>.<kafka-namespace>.svc.cluster.local:9092"
image:
repository: seglo/kafka-lag-exporter
tag: 0.8.2
Пробрасываем порт для проверки доступных метрик:
kubectl port-forward svc/kafka-lag-exporter-service 8000:8000 -n monitoring
Добавляем конфигурацию сбора метрик в Prometheus:
prometheus:
prometheusSpec:
namespaceSelector:
matchNames:
- default
- kafka
additionalScrapeConfigs:
- job_name: 'kafka-lag-exporter'
metrics_path: /metrics
static_configs:
- targets: ['kafka-lag-exporter-service:8000']
Создаем ScaledObjects:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-hpa
namespace: default # Заменяем пространством имен, в котором сервис развернут
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: <kafka-consumer-service>
minReplicaCount: 1 # Минимальное количество реплик
maxReplicaCount: 30 # Максимальное количество реплик
pollingInterval: 1
cooldownPeriod: 100
triggers:
- type: prometheus
metadata:
serverAddress: http://<prometheus-server-address>:9090
metricName: kafka_lag
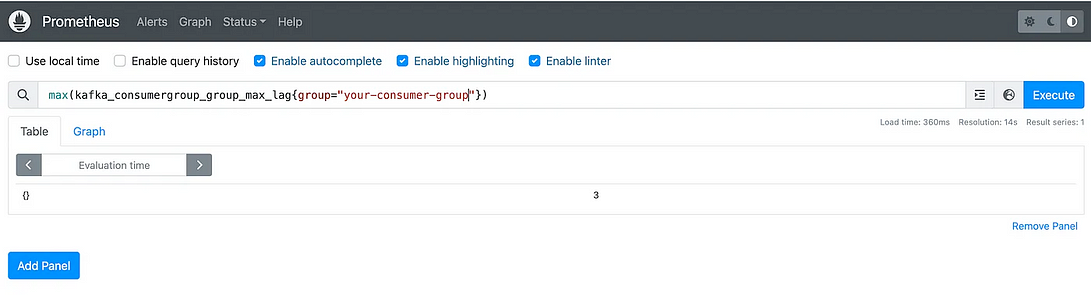
query: max(kafka_consumergroup_group_max_lag{group="your-consumer-group"})
threshold: "20" #количество запаздываний, на которых приложение масштабируется
Здесь, когда максимальное значение запаздывания Kafka добирается до 20, приложение масштабируется автоматически.
Проверяем ScaledObjects:
kubectl get hpa | grep keda OR kubectl get scaledobjects
Проверяем запрос в Prometheus:
Дополнительно добавляем в Grafana дашборд мониторинга: импортируем json-файл.
Заключение
Благодаря автомасштабированию по запаздыванию Kafka системы обработки сообщений остаются эффективными, респонсивными и экономичными. Динамической настройкой ресурсов исходя из потребностей реального времени в организациях поддерживаются оптимальные уровни производительности, адаптируются к меняющимся рабочим нагрузкам.
Метод автомасштабирования приложения выбирается в зависимости от конкретного сценария и доступности.
Читайте также:
- Почему микросервисы нужны каждому разработчику
- Продвинутые концепции Kafka для старшего инженера-программиста
- Лучшие практики модульного тестирования
Читайте нас в Telegram, VK и Дзен
Перевод статьи Medhavi singh: Auto-scaling based on Kafka lag using KEDA




