
Представляем веб-оболочку и реализацию веб-сборки DuckDB. Установки не требуется: вводим этот url-адрес, после чего в браузере загружается и запускается движок DuckDB:
Все дальнейшие операции выполняются локально. В браузере. Когда DuckDB запущен, переходим в автономный режим и работаем с данными приватно.
Данные перемещаются в экземпляр DuckDB посредством добавления локальных файлов. Вводим в командной строке .files add, при этом открывается файловое диалоговое окно браузера, где выбираем файлы поддерживаемых форматов CSV, JSON, Parquet:
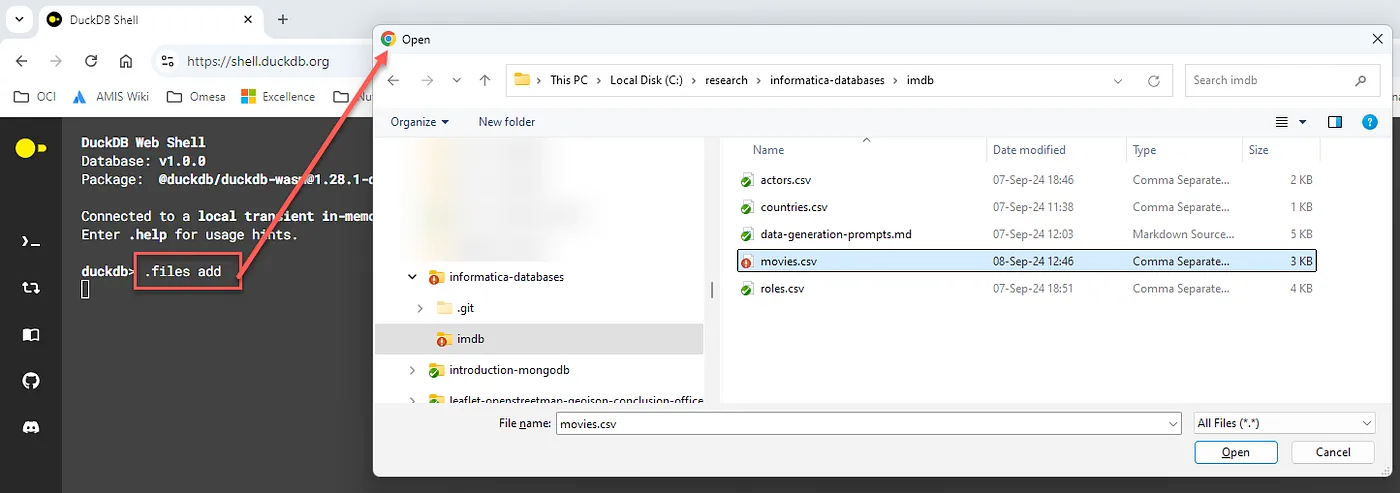
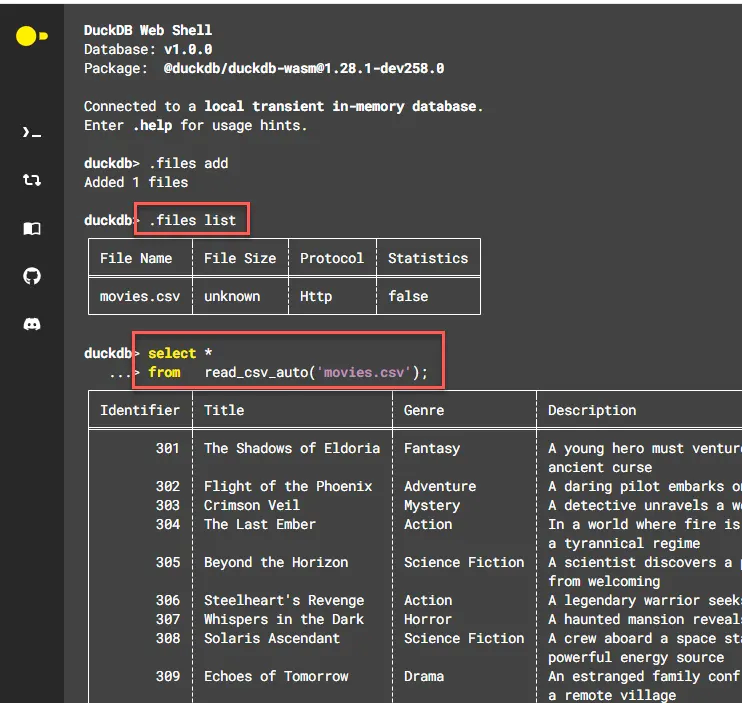
Добавив файл, командой .files list проверяем, является ли он теперь частью контекста. Если да, добираемся до него, например, с помощью функции read_csv_auto:
select *
from read_csv_auto('movies.csv');
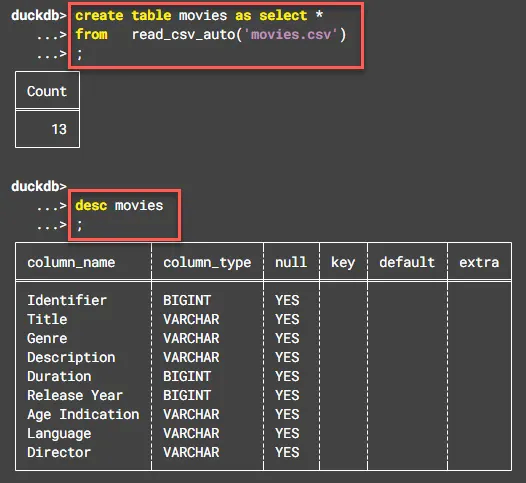
Данные из этого файла легко преобразуются в реальную таблицу в DuckDB:
create table movies as select *
from read_csv_auto('movies.csv')
;
Оставаясь в командной строке, получаем удаленный файл по HTTP теперь и из локальной базы данных DuckDB. Но не загружая локальный файл в DuckDB локального же браузера, а добираясь до файлов, например, на GitHub или S3.
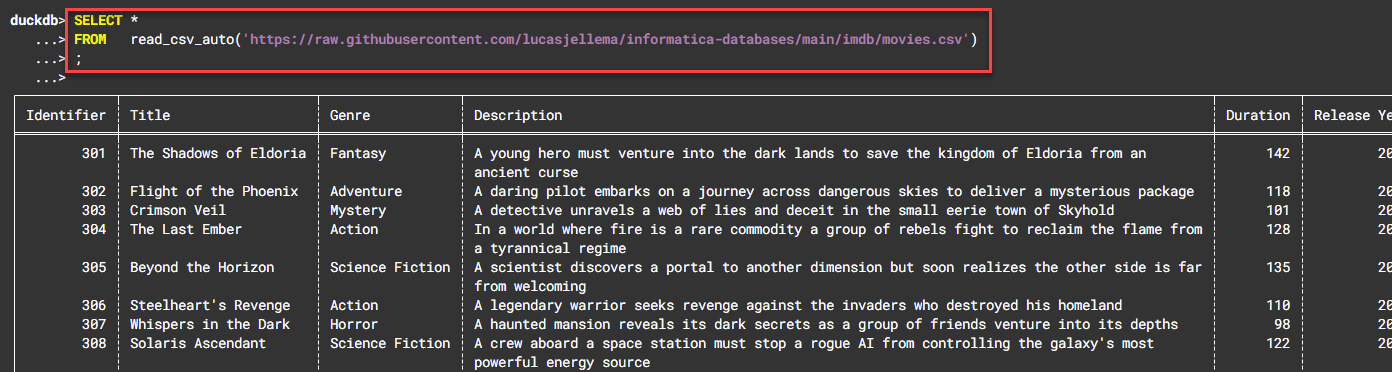
Вот пример использования конечной точки необработанного содержимого для csv-файла на GitHub:
SELECT *
FROM read_csv_auto('https://raw.githubusercontent.com/lucasjellema/informatica-databases/main/imdb/movies.csv')
;
В этом случае синтаксисом create table as select * from … данные также добавляются в локальную таблицу:
CREATE TABLE imdb_movies AS
SELECT *
FROM read_csv_auto('https://raw.githubusercontent.com/lucasjellema/informatica-databases/main/imdb/movies.csv')
;
Кроме скорейшего доступа к полнофункциональной базе данных SQL и аналитическому движку запросов, благодаря DuckDB выполняется простой анализ локальных наборов данных. Часто работаете с данными в CSV или подобном формате? Быстрый их перенос в этот SQL-движок придется вам кстати, как и последующий анализ — намного проще и полнофункциональнее, чем в Excel.
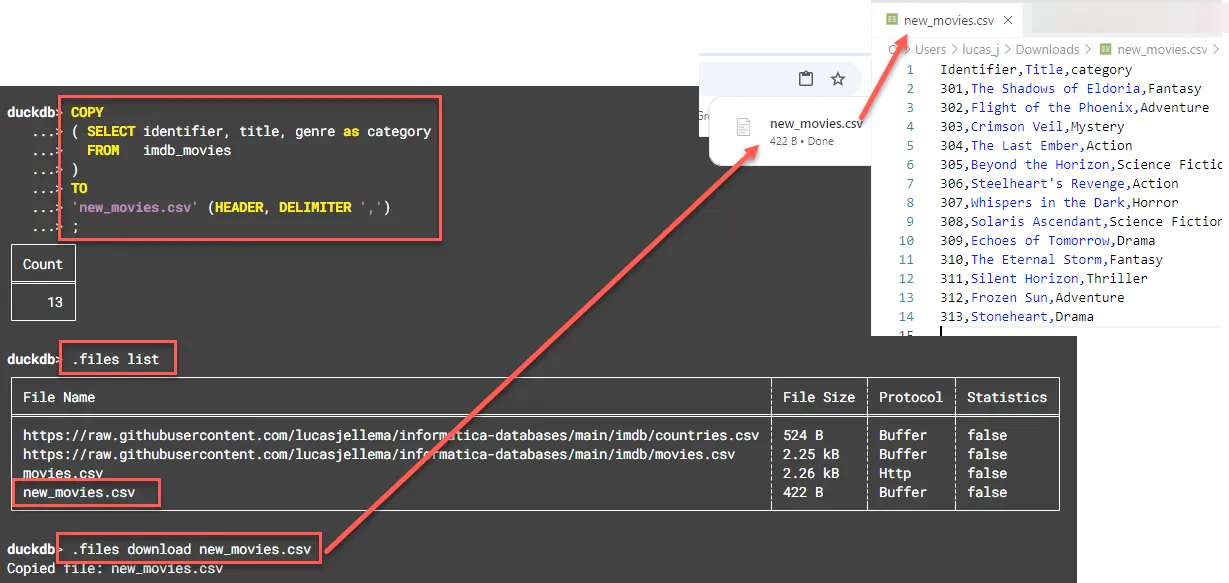
Поработав с данными в DuckDB с SQL, вы легко вернете их в CSV или JSON. В любом операторе SELECT простым COPY создается локальный файл DuckDB, а командой .files download <название файла> файл загружается из браузера в операционную систему и на локальный жесткий диск:
Читайте также:
- Наш первый миллиард строк в DuckDB
- Откажитесь от SQLite в пользу DuckDB
- Реализация захвата изменения данных с Docker, PostgreSQL, MongoDB, Kafka и Debezium: подробное руководство
Читайте нас в Telegram, VK и Дзен
Перевод статьи Lucas Jellema: SQL in your browser — DuckDB Web Shell for purely local data analytics





