
Затронутый код, вероятно, работает медленнее, недоиспользует ресурсы компьютера и имеет нежелательные скачки задержки.
Я провел несколько экспериментов на Rust, показывающих, что именно это означает, но думаю, что это верно в любой системе, где нет специальной обработки ввода-вывода отображаемой памяти, включая Python и ручной неблокирующий ввод-вывод в C.
Мне нужны цифры
Я установил кое-какие бенчмарки, сканирующие 8 файлов — по 256 МБ каждый — и суммируют значение каждого 512-го байта. Это неинтересная задача, но она придумана, чтобы по максимуму использовать ввод-вывод, сократив что-то иное до минимума. Это худший случай, влияние на реальный код вряд ли окажется настолько же серьезным!
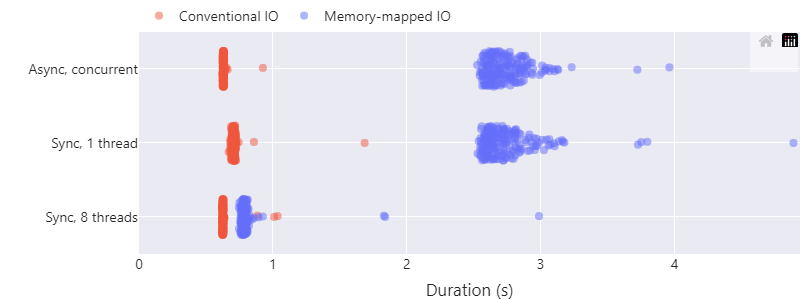
Есть 6 конфигураций, где применяются все комбинации способов чтения файлов и параллельного выполнения.0
Чтение файлов имеет два измерения:
- Обычный ввод-вывод — явные вызовы чтения.
- Ввод-вывод с отображением в память — с библиотекой memmap2.
В случае конкурентности их три:
async/await— библиотека Tokio1 в однопоточном режиме2.- синхронное с 8 потоками — поток создается для каждого файла.
- синхронное с 1 потоком — простой вариант с одним потоком для последовательного чтения.
Результаты3 очевидны: отображаемый в память ввода-вывода с async/await выглядит не использующим конкурентность: для первых двух строк кластеры точек почти идентичны! Явный последовательный одиночный поток с отображаемым в память вводом-выводом сканирует все 2 ГБ от 2,5 до 3 секунд; «конкурентная» версия async/await выглядит идентично. Для сравнения, отображаемый в память ввод-вывод в 8 полных потоков намного быстрее, это примерно от 0,75 до 0,8 секунды.
Между тем, обычный ввод-вывод ведет себя скорее так, как мы надеялись: любая форма параллелизма заметно быстрее последовательного выполнения. Использование потоков с async/await или потоков операционной системы приводит к чтению всех файлов менее чем за 0,65 секунды4, а последовательная однопоточная версия читает немного дольше (0,7 с), но с небольшим пересечением в распределениях.
Что происходит?
Обычно операционные системы различают байты в оперативной памяти и файлы на диске. Чтение файла — это специальная операция, которая переносит байты с диска в массив в памяти. Но есть и оттенки серого: системный вызов Unix mmap (или его эквивалент на других платформах) стирает различие между диском и памятью, устанавливая «отображаемый в память ввод-вывод».
Операция mmap выделяет для выбранного файла диапазон (виртуальной) памяти, благодаря чему эта память «содержит» файл: чтение5 первого байта в памяти дает значение первого байта файла, как и второго байта, и так далее. По сути, файл действует как обычный массив &[u8], его можно индексировать или сделать срез:
let file = std::fs::File::open("data.bin")?;
let mmapped = unsafe { memmap2::Mmap::map(file)? };
let first_byte: u8 = mmapped[0];
println!("File starts {first_bytes}");
let central_bytes: &[u8] = &mmapped[1200..1300];
println!("File contains {central_bytes:?}");Это очень похоже на то, что можно получить, если вручную выделить массив памяти как буфер, выполнить поиск в файле, прочитать его, чтобы заполнить буфер, а затем получить доступ к буферу… просто, без всякой бухгалтерии. Что же тут не нравится?
Под капотом
Чтобы это работало, операционная система должна творить чудеса.
Одна из возможных реализаций может заключаться в том, чтобы операционная система буквально выделяла кусок физической памяти и загружала в нее файл, байт за байтом, прямо при вызове mmap… но это медленно и сводит на нет половину магии ввода-вывода с отображением в память — работу с файлами без необходимости извлекать их в память. Возможно, на машине установлено 4 ГБ ОЗУ, но захочется работать с файлом размером в 16 ГБ.
Тогда операционные системы используют возможности виртуальной памяти: это позволит некоторым частям файла находиться в физической памяти, пока другие части остаются на диске; разные части можно выгрузить в память или из неё по необходимости. Разделы файла загружаются в память только по мере доступа.
let mmapped: Mmap = /* отображаем какой-нибудь файл в память */;
let index = 12345;
let byte_of_interest = mmapped[index];
println!("byte #{index} has value {byte_of_interest}");Эта индексация обращается к 12 345-му байту файла. При первом доступе произойдет ошибка страницы, и операционная система возьмет управление на себя: она загрузит соответствующие данные из файла на диске в реальную физическую память, то есть данные будут доступны прямо из обычной оперативной памяти. Загрузится и небольшой окружающая область страницы памяти — доступ к близлежащим адресам станет быстрым.
Во время загрузки поток и его код заблокируются: он будет отменен и не станет выполнять дальнейшую работу, ведь следующим строкам потребуется значение байта.
Сразу после загрузки страница файла какое-то время будет кэшироваться в памяти, в это время любой доступ к адресам на странице окажется быстрым, прямо из памяти. В зависимости от используемой системной памяти и других факторов операционная система может решить удалить страницу из памяти, освободив место для чего-то другого. Доступ к странице после выселения потребует перезагрузки с диска с тем же поведением блокирования, и цикл повторится.
В коде приложения вся эта магия упакована в простую индексацию: byte_of_interest = mmapped[index]. Отдельные случаи доступа «в памяти» (быстрого) и «загрузки с диска» (медленного) в коде невидимы6. В любом случае мы начинаем с адреса памяти и заканчиваем значением байта.
Потеря того самого потока
Именно из-за этой магии наша конкурентность не работает. Конструкция async/await представляет собой совместное планирование с «исполнителем» или «циклом событий», который управляет множеством задач, переключаясь между ними по мере необходимости… но это переключение **возможно только в точках с явным await **. Если задача выполняется долго или «заблокирована» без ожидания, исполнитель не сможет вытеснить ее, чтобы запустить другую.
Помните, что код выглядит примерно так: let byte_of_interest = mmapped[index];? Здесь нет await, поэтому исполнитель async/await не может переключиться на другую задачу. Вместо этого операция блокирует и отменяет планирование всего потока… Но исполнитель — это обычный код, использующий и этот поток, поэтому то, что координируется конкурентностью, отменяется и не может выполнять никакой другой работы.
Это поведение отличается от надлежащего асинхронного ввода-вывода: отдельной задаче все равно придется ждать чтения данных, но «ожидание» означает, что исполнитель может переключиться на другую задачу, пока это происходит — такова конкурентность!
let mut file: tokio::fs::File = /* какой-нибудь файл */;
let mut buffer: [u8; N] = [0; N];
file.read(&mut buffer).await?; // ключевой awaitОтдаленная опасность
Для меня самая неочевидная часть этой опасности заключается в том, что отображенный в память файл выглядит как обычный буфер в памяти. Код, скорее всего, будет неявно предполагать, что индексация &[u8] выполняется быстро и не выполняет неявное чтение файла.
Например, memmap2::Mmap разыменовывает в [u8]. Это означает, что можно взять fn f(b: &[u8]) { ... } и вызвать её как f(&mmapped). Эта функция просто видит b: &[u8], не имея ни малейшего представления о том, что индексация b способна блокировать ввод-вывод. Эта функция не будет знать, что ей нужно уделить внимание любой кооперативной конкурентности, которую она выполняет.
Rust — всего лишь демонстрация, поведение применимо повсеместно: mmap в Python явно говорит «ведёт себя как… bytearray», а mmap C/POSIX возвращает void * (то же самое, что malloc). Весь смысл отображения памяти заключается в том, чтобы представить файл массивом байтов.
Кэширование
Выше мы видели, что проблема возникает, когда данные необходимо загрузить с диска в память. Что произойдет, если данные уже в памяти? В этом случае можно было бы ожидать, что отображаемый в память ввод-вывод, работает намного быстрее, поскольку теоретически он просто обращается к обычной памяти прямо из ОЗУ.
Эта версия бенчмарка определяет, сколько времени потребуется, чтобы выполнить ту же задачу сразу после холодной версии, которую мы видели выше, не очищая кэш.
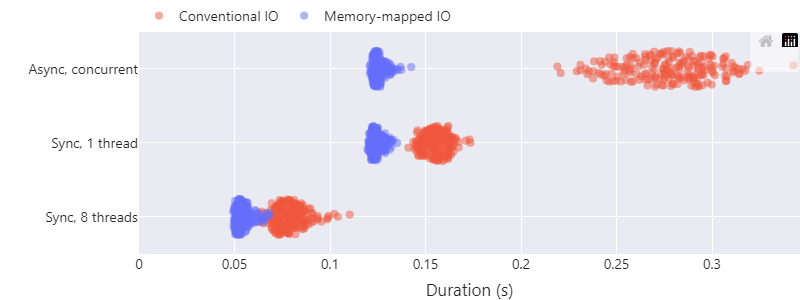
Теория оказалась верной: это намного быстрее: при использовании холодного кэша мы видели, что операции ввода-вывода, отображаемые в память, на одном потоке читают 2 ГБ 2,5 секунды. Теперь чтение занимает 0,12 с — это в 21 раз быстрее, чем с async/await или без них.
Есть и другие примечательные наблюдения о выполнении с «теплым» кэшем:
- Операции ввода-вывода, отображаемые в память, выполняются быстрее обычных. Думаю, потому, что у них меньше накладных расходов: для обычного ввода-вывода есть дополнительное копирование данных
memcpyиз страничного кэша операционной системы в буфер, передаваемый в вызовread. Работа с Tokio иasync/await— это еще больше накладных расходов, вероятно, из-за оверхеда на синхронизацию с пулом потоков, который нужно использовать для асинхронного ввода-вывода файлов. - Асинхронный и однопоточный последовательный ввод-вывод с отображением в память по-прежнему занимает то же время, что и с холодным кэшем… с теплым кэшем оба просто работают быстро.
- Если вам нужна скорость, удобно использовать несколько потоков: ввод-вывод с отображением в память дает скорость «файлового» ввода-вывода ~41 ГиБ/с, считывая 2 ГиБ за 49 мс.
- Похоже, это зависит от системы: я работал на macOS Arm64, и на других системах результаты могут различаться.
Еще вопросы
Я провел несколько экспериментов, объединив «науку» с «компьютерными науками». И, конечно же, появилось больше вопросов. Ответов я не знаю!
- Как это проявляется на других платформах, помимо macOS Arm64? (Гипотеза: на всех платформах одинаково).
- Влияет ли на поведение тип диска, где хранятся файлы? (Гипотеза: да, я ожидаю, что запуск этого процесса на диске с высокой задержкой, типа вращающегося ржавого диска, покажет еще худшее поведение при блокировке, чем SSD, который используется здесь, ведь каждый поток будет блокироваться дольше).
- Помогает ли предварительная выборка с помощью инструкций ЦП устранить проблемы? (Гипотеза: не уверен. Не знаю, приведет ли выполнение инструкции предварительной выборки по отображенному в память адресу к загрузке страницы в фоновом режиме. Возможно, придется заранее выполнить предварительную выборку многих, многих итераций цикла, ведь при этом считывается весь путь с диска, а не только из ОЗУ в кэш ЦП, для чего часто используется предварительная выборка).
- Как на это влияют другие параметры
mmap/madvise(например,MADV_SEQUENTIAL,MADV_WILLNEED,MADV_POPULATE,MADV_POPULATE_READ,mlock)? (Гипотеза: они повысят вероятность того, что данные кэшируются предварительно, а значит, чаще попадают в быстрый путь, но без гарантии). - А как насчет
readahead? (Гипотеза: этот системный вызов сделает быстрый путь более вероятным, но не гарантирует его, как и в предыдущем пункте).
Заключение
Доступ к файлам через ввод-вывод с отображением в память дает очень удобный API: просто прочитайте байт с помощью обычной индексации.
Однако он подвержен ошибкам при использовании с совместно запланированной конкурентностью, например с async/await в Rust или Python, или даже с «ручным» неблокирующим вводом-выводом в C:
- Если данные еще недоступны в памяти, операционной системе придется блокировать поток при чтении с диска, и нет
await, позволяющего исполнителю асинхронно выполнить другую задачу. - Так что интенсивное применение mmap потенциально может оказаться не быстрее последовательного кода!
- Это опасность отдалена: отображенный в память файл можно привести к виду обычного байтового массива (
&[u8],bytearray/list[int]илиvoid */char *) и перед индексацией передать глубоко в асинхронный код. - Если данные кэшируются операционной системой,
mmapтребует меньше накладных расходов, чем обычный ввод-вывод, и может работать немного быстрее (в моей системе).
- У меня есть скрипт, который неоднократно измеряет время сканирования всех 2 ГБ в каждой конфигурации. Чтобы запускать чтение с холодным кэшем, перед каждым измерением он удаляет все кэши файловой системы через
purge. ↩ - Бенчмарки Tokio перебирают каждый файл одновременно с вызовом
join_all. Здесь используется типtokio::fs::Fileдля «обычного ввода-вывода». Примечание: также в фоновом режиме применяется пул потоков: кажется, что поддержка настоящего асинхронного файлового ввода-вывода ограничена, но ключом является открытый API сasync/await. ↩ - Чтобы сделать проблему предельно очевидной и ясной, в бенчмарках используется однопоточная среда выполнения: многопоточная среда выполнения может замаскировать последствия блокировки ввода-вывода mmap, распределяя его по нескольким потокам. ↩
- Вот таблица со всеми результатами, включая холодный и теплый кэши файловой системы, указано наименьшее значение каждого бенчмарка, то есть наиболее благоприятное наблюдение:
| Конкурентность | Ввод-вывод | Холодный кэш в сек. | Прогретый кэш в сек. |
|---|---|---|---|
| Асинхронный | Mmap | 2,5 | 0,12 |
| Асинхронный | Обычный | 0,62 | 0,22 |
| Синхронный в 8 потоков | Mmap | 0,75 | 0,049 |
| Синхронный в 8 потоков | Обычный | 0,62 | 0,063 |
| Синхронный в 1 поток | Mmap | 2,5 | 0,12 |
| Синхронный в 1 поток | Обычный | 0,67 | 0,14 |
- Думаю, это предельно увеличивает пропускную способность SSD машины — около 3300 МБ/с, следовательно, это не намного быстрее однопоточной версии. ↩
- Эта статья посвящена моим наблюдениям за работой mmap в случае чтения, а не записи файла. Насколько я понимаю, запись сопряжена со своими проблемами, включая такие вещи, как неясные гарантии персистентности. Но я не эксперт и не исследовал это. ↩
- Эти случаи невидимы, за исключением побочных каналов, таких как синхронизация операции, наблюдение за статистикой использования памяти, или таблиц распределения страниц. Я их не считаю. ↩
Читайте также:
- Зачем писать компилятор Rust на C — личный опыт
- Многопоточность на Rust: ускоряем приложения, делаем их эффективнее
- LOESS в Rust
Читайте нас в Telegram, VK и Дзен
Перевод статьи Huon Wilson: Async hazard: mmap is secretly blocking IO





