
Сегодня я покажу простой способ сбора данных с множества сайтов и расскажу, как создать веб-скрейпер, который может работать так же, как человек, используя браузер. Такой скрейпер может даже самостоятельно выполнять задания для фрилансеров на сайтах вроде Upwork.
Веб-скрейпинг сильно изменился благодаря ИИ, особенно в 2024 году. Раньше крупным компаниям, таким как Amazon и Walmart, приходилось тратить много времени и денег на сбор данных с других сайтов, чтобы поддерживать конкурентоспособные цены.
Для этого они копировали действия браузера: отправляли запросы к HTML сайта, а затем с помощью специального кода находили и получали нужную информацию.
Это было сложно, потому что каждый сайт отличается от других, и если какой-то сайт менял свой дизайн, скрейпер переставал работать. Это означало, что компаниям приходилось тратить больше времени на исправление и обновление скрейперов.
Допустим, на Amazon и Walmart продаются одни те же товары, и Amazon хочет следить за ценами этих товаров на Walmart. Для этого Amazon понадобится скрейпер, созданный специально для сайта Walmart.
Но если Walmart изменит свой сайт, Amazon придется обновлять скрейпер. Это отнимает много времени и средств.
Скрейперы нужны не только крупным компаниям. Если вы посетите сайты для фрилансеров вроде Upwork, то увидите множество малых предприятий, которые ищут разработчиков скрейперов для поиска контактных данных, отслеживания цен, исследования рынка или размещения объявлений о работе.
Например, небольшому стартапу может понадобиться отслеживать цены на товары на разных сайтах электронной коммерции, чтобы установить собственные цены.
До появления искусственного интеллекта малым предприятиям было сложно и дорого получить такие решения. Теперь с помощью больших языковых моделей (LLM) и новых инструментов создавать веб-скрейперы стало намного проще и дешевле.
То, что раньше занимало у разработчика неделю, теперь можно сделать всего за несколько часов. Способность высокоинтеллектуальных LLM понимать различные структуры сайтов избавляет от переписывания скрейперов для каждого незначительного изменения.
Поговорим о том, как эффективно собирать данные и работать с разными типами сайтов — от простых до очень сложных.
Разделим их на три группы:
- простые публичные сайты;
- сайты, которым нужны более сложные рабочие процессы;
- сложные случаи, для которых нужны высокоинтеллектуальные агенты.
1. Скрейпинг простых публичных сайтов
Простые публичные сайты — страницы вроде Википедии или интернет-ресурсов компаний, на которых не нужно регистрироваться или платить.
Эти сайты все же могут быть сложными для скрейпинга, поскольку имеют различные макеты, но с большими языковыми моделями эта работа стала намного проще.
Допустим, вам нужно собрать информацию о различных растениях из Википедии для школьного проекта.
Раньше пришлось бы просматривать HTML-код каждой страницы, находить теги с нужными данными, а затем писать собственный код для получения этих данных.
Делать это для каждой страницы было бы очень трудоемко.
Но теперь, с помощью LLM, можно просто отдать необработанный HTML искусственному интеллекту, и он извлечет данные за вас.
Вы даже можете указать модели, какие именно данные вам нужны, например «получить название растения, его описание и советы по уходу», и искусственный интеллект выдаст структурированный ответ. Это экономит массу времени и сил.
LLM также умеют определять, где находится информация, если вы не знаете, на какой именно странице она находится.
Например, если вы ищете контактную информацию на сайте компании, но не знаете, на какой странице она находится, скрейпер на базе ИИ может перебрать все страницы, пока не найдет то, что вам нужно. Это что-то вроде помощника, который знает, куда нажать и что прочитать.
2. Скрейпинг сайтов со сложными взаимодействиями
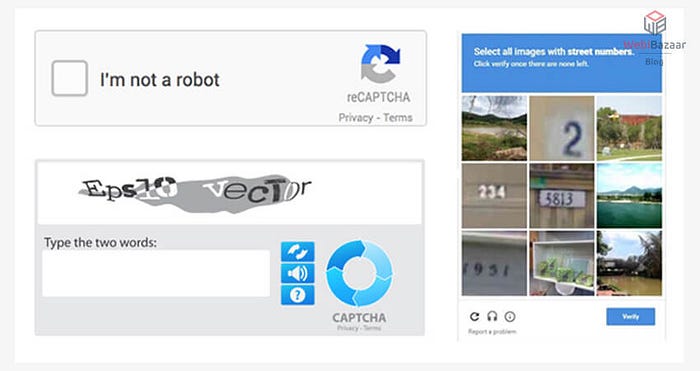
Некоторые сайты сложнее для скрейпинга, потому что требуют взаимодействия с ними, например входа в систему, разгадки капчи или нажатия на всплывающие окна.
Вспомните новостные сайты, на которых для просмотра статей нужно войти в систему. Именно здесь пригодятся такие инструменты, как:
- Selenium;
- Puppeteer;
- Playwright.
Эти инструменты изначально были созданы для тестирования сайтов, но теперь используются для имитации того, как реальный человек будет использовать сайт.
Представьте, что вы хотите взять статьи с новостного сайта, например The New York Times. Статьи доступны только платно, поэтому сначала нужно зарегистрироваться на сайте.
Вы можете использовать такие инструменты, как Playwright или Selenium, чтобы заставить скрейпер пройти регистрацию за вас, кликать по всплывающим окнам и получать доступ к статьям.
Но даже с этими инструментами может оказаться сложным заставить скрейпер взаимодействовать с каждой кнопкой или полем ввода на странице.
Именно здесь на помощь приходит AgentQL, который помогает найти нужные элементы на веб-странице, такие как кнопки и формы, и указывает скрейперу, что нужно делать.
Например, если вы хотите собирать вакансии с нескольких порталов, AgentQL поможет скрейперу найти форму входа, заполнить ее и перейти к списку вакансий. Это означает, что вы можете собрать множество объявлений всего за несколько минут, не выполняя никакой ручной работы.
Вы даже можете попросить скрейпер поместить данные в Google Sheets или Airtable, чтобы их было легко сортировать и анализировать.
Допустим, вы пытаетесь отслеживать вакансии разработчиков ПО на таких сайтах, как Indeed, Glassdoor и LinkedIn. С помощью этих инструментов можно заставить скрейпер входить в систему, искать вакансии и собирать все подробности в одном месте, например в таблице Google Sheets. Это сэкономит часы работы.
3. Продвинутые задачи, требующие высокоинтеллектуального подхода
Последняя группа включает неодносложные задачи, требующие принятия непростых решений, например поиск самого дешевого рейса до места назначения в ближайшие два месяца или покупка билета на концерт с учетом вашего бюджета.
Эти задачи сложны, потому что требуют планирования и рассуждений. Пока еще новые инструменты, которые могут решать эти задачи, находятся в разработке.
Одна из таких платформ — Multion, которая создает агентов, способных самостоятельно справляться с подобными сложными заданиями.
Например, вы можете попросить агента «найти и забронировать самый дешевый рейс из Нью-Йорка в Мельбурн в июле». Он просмотрит различные туристические сайты, сравнит цены и забронирует для вас билет.
Пока инструмент не идеален, но он близок к тому, чтобы вести себя как настоящий человек.
Другой пример — покупка билета на концерт. Вы можете попросить агента: «Купи мне билет на концерт Тейлор Свифт по цене менее 100 долларов». Агент просмотрит различные сайты по продаже билетов, найдет билет, соответствующий бюджету, и совершит покупку.
Эта технология все еще развивается, но инструменты вроде Multion позволяют автоматизировать даже такие сложные задачи.
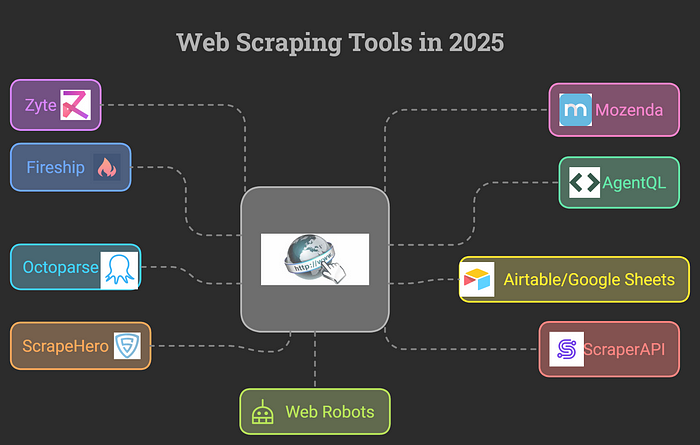
Практические инструменты для веб-скрейпинга
Вот несколько полезных инструментов для желающих заняться веб-скрейпингом с помощью LLM и агентов:
- Fireship, Gina и SpiderCloud. Эти инструменты помогают преобразовать веб-контент в удобный для чтения формат, который лучше понимают модели искусственного интеллекта. Так, Fireship может представить сложный сайт ресторана в виде его простой версии, содержащей только важную информацию, например пункты меню и цены. Таким образом, модели искусственного интеллекта дешевле и быстрее обрабатывают информацию.
- AgentQL. Этот инструмент помогает скрейперу взаимодействовать с сайтами так же, как это делает человек. Например, если вам нужно выполнить скрейпинг доски объявлений о работе, на которой находится множество кнопок для нажатия и форм для заполнения, AgentQL позволит убедиться, что ваш скрейпер сможет сделать все это без проблем.
- Интеграция с Airtable/Google Sheets. Когда скрейпер соберет данные, важно сохранить их в полезном виде. Такие инструменты, как Airtable и Google Sheets, позволяют сохранять данные, чтобы позже можно было легко проанализировать их. Например, если вы отслеживаете цены на жилье на сайтах недвижимости, Google Sheets поможет сравнить и проанализировать тенденции с течением времени.
- Octoparse и ScrapeHero. Эти инструменты эффективны для работы с сайтами, перегруженными JavaScript. Octoparse имеет готовые шаблоны, позволяющие легко собирать данные с сайтов электронной коммерции, и использует умные методы, чтобы избежать блокировки. ScrapeHero отлично подходит для проектов, в которых нужно быстро получить много данных, например собрать цены сразу из нескольких магазинов.
- ScraperAPI и Zyte. Эти сервисы противостоят блокировке скрейпера ротационными прокси. ScraperAPI позволяет настраивать заголовки запросов, что полезно для целевого скрейпинга. Zyte, ранее называвшийся Scrapy, также отлично справляется с объемными заданиями по скрейпингу и обеспечивает получение нужных данных без перебоев.
- Mozenda и Web Robots. Mozenda помогает автоматизировать сложные веб-формы, а также позволяет планировать задания по сбору данных. Web Robots — отличный вариант, если вам нужно создать собственную программу для сбора данных и извлечь их непосредственно в файлы типа CSV или Excel.
Итак, в 2024 и 2025 годах ИИ изменит способ сбора данных с сайтов.
Благодаря большим языковым моделям и таким инструментам, как AgentQL и Playwright, даже на сложных сайтах можно проводить скрейпинг с меньшим количеством ручной работы.
Самое приятное, что эти системы достаточно гибкие, чтобы решать самые разные задачи — будь то сбор бизнес-данных, поиск работы или даже бронирование авиабилетов.
Сейчас возможности автоматизации веб-скрейпинга впечатляют и доступны как никогда.
Будь вы бизнесменом, собирающим данные о рынке, фрилансером, помогающим клиенту, или просто любопытным человеком, интересующимся технологичными новинками, инструменты искусственного интеллекта сделают веб-скрейпинг мощным и простым решением для вас.
Читайте также:
- Веб-скрейпинг с помощью Python и BeautifulSoup
- Автоматизация создания стикеров с помощью веб-скрейпинга и обработки изображений в Python
- Борьба с веб-скрейперами с помощью Rust
Читайте нас в Telegram, VK и Дзен
Перевод статьи Manpreet Singh: Use AI to Scrape Almost All Websites Easily in 2025





