
Вступление
Будь вы студент или уже состоявшийся разработчик, вы наверняка слышали о «контейнерах». Более того, вероятно вы слышали, что контейнеры — это «лёгкие» виртуальные машины. Но что на самом деле это значит, как именно работают контейнеры и почему они важны?
Эта статья посвящена контейнерам, их применению и великолепной идеи, которая за этим стоит. Для этой статьи никакой предварительной подготовки не требуется, кроме базового понимания компьютерных технологий.
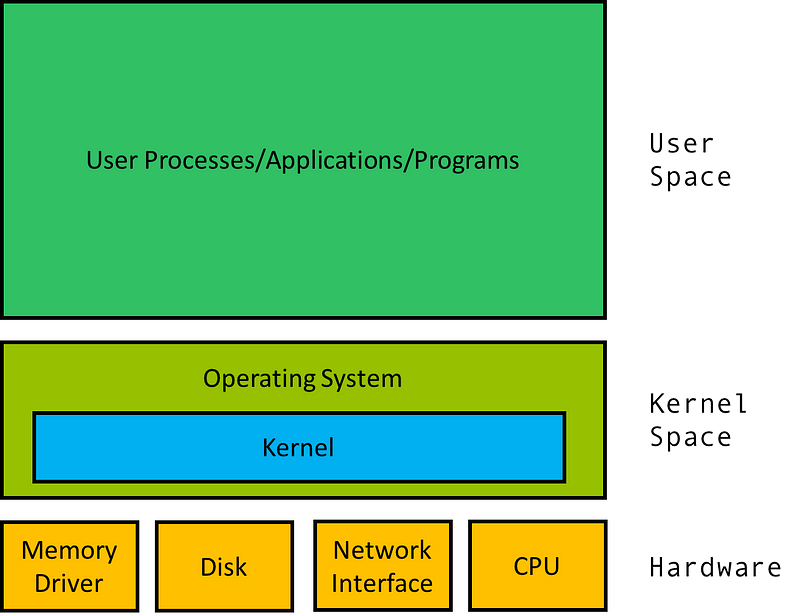
Ядро и ОС
В основе любого компьютера лежит «железо»: процессор, накопитель (hdd, ssd), память, сетевая карта и т.д.
В ОС есть часть программного кода, которая служит мостом между софтом и железом, он называется — kernel (ядро). Ядро координирует запуск процессов (программ), управляет устройствами (чтение и запись адресов на диск и в память) и многое другое.
Остальная часть ОС служит для загрузки и управления пользовательским пространством, где запускаются и постоянно взаимодействуют с ядром процессы пользователя.
Виртуальная машина
Допустим, что ваш компьютер работает под MacOS, а вы хотите запустить приложение написанное для Ubuntu. Наиболее вероятным решением в этом случае будет загрузка виртуальной машины на MacOS, для запуска Ubuntu и вашей программы.
Виртуальная машина подразумевает виртуализацию ядра и железа, для запуска гостевой ОС. Hypervisor — это ПО для виртуализации железа, в том числе: виртуального накопителя, сетевого интерфейса, ЦП и другого. Виртуальная машина также имеет своё ядро, которое общается с этим виртуальным железом.
Hypervisor может быть реализован как ПО, так и в виде реального железа, установленного непосредственно в Host машину. В любом случае hypervisor ресурсоёмкое решение, требующее виртуализации нескольких, если не всех, “железных” устройств и ядра.
Когда требуется несколько изолированных групп на одной машине, запускать виртуальную машину для каждой группы — слишком расточительный подход, требующий много ресурсов.
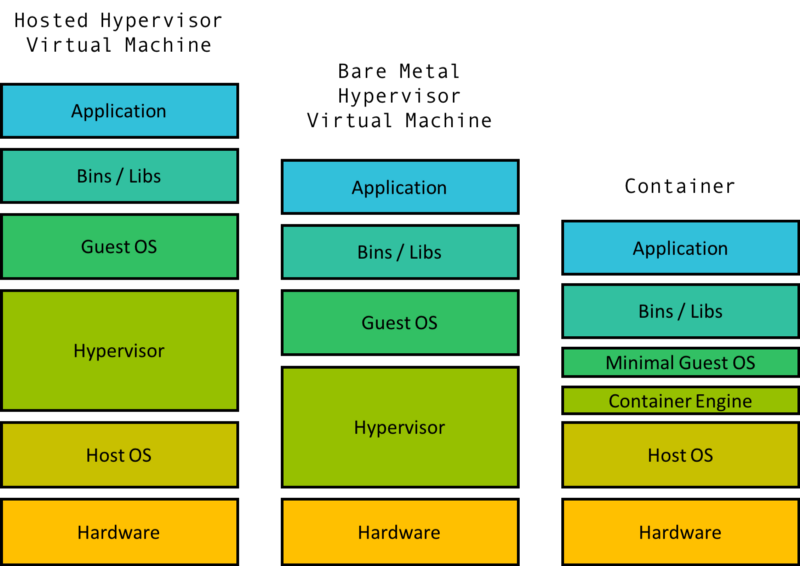
Для виртуальной машины необходима аппаратная виртуализация, для изоляции на уровне железа, тогда как контейнерам требуется изоляция в пределах операционной системы. С увеличением числа изолированных пространств, разница в расходах ресурсов становится очевидной. Обычный ноутбук может работать с десятками контейнеров, но едва справляется даже с одной виртуальной машиной.
cgroups
Cgroups — это аббревиатура от Linux “control groups”. Это функция ядра Linux, которая изолирует и контролирует использование ресурсов для пользовательских процессов. Её создали инженеры из Google в 2006 году.
Эти процессы могут быть помещены в пространства имён, то есть группы процессов, у которых общие ограниченные ресурсы. В компьютере может быть несколько пространств имён, у каждого из которых есть свойства ресурса, закреплённые ядром.
Для каждого пространства имён можно распределять ресурсы, так, чтобы ограничить использование CPU, RAM и т.д., для каждого набора процессов. Например, для фонового приложения агрегации логов, вероятно, потребуется ограничить ресурсы, чтобы не перегружать сам сервер, для которого ведётся лог.
Cgroups была в конечном итоге переработана в Linux, для добавления функции namespace isolation (изоляция пространства имён). Идея изоляции пространства имён не нова. В Linux уже было много видов namespace isolation. Например, изоляция процессов, которая разделяет каждый процесс и предотвращает совместное использование памяти.
Cgroup обеспечивает более высокий уровень изоляции. Благодаря cgroup, процессы из одного пространства имён независимы от процессов из других пространств. Ниже описаны важные функции изоляции пространств имён. Это и есть основа изоляции в контейнерах.
- PID (Process Identifier) Namespaces: эта функция гарантирует изоляцию процессов из разных пространств имён.
- Network Namespaces: изоляция контроллера сетевого интерфейса, iptables, таблиц маршрутизации и других сетевых инструментов более низкого уровня.
- Mount Namespaces: монтирует файловую систему таким образом, чтобы область файловой системы была изолирована и имела доступ только к смонтированными директориями.
- User Namespaces: изолирует пользователя в пространстве имён, чтобы избежать конфликта user ID между пространствами.
Проще говоря, каждое пространство имён для внутренних процессов, выглядит так как будто это отдельная машина.
Linux контейнеры
Linux cgroups стала основой для технологии linux containers (LXC). На самом деле LXC была первой реализацией того, что сегодня называют контейнеры. Для создания виртуальной среды, с разделением процессов и сетевого пространства, взяли за основу преимущества cgroups и изоляцию пространств имён.
Сама идея контейнеров вышла из LXC. Можно сказать, что благодаря LXC стало возможным создавать независимые и изолированные пространства пользователей. Более того, ранние версии Docker ставились поверх LXC.
Docker
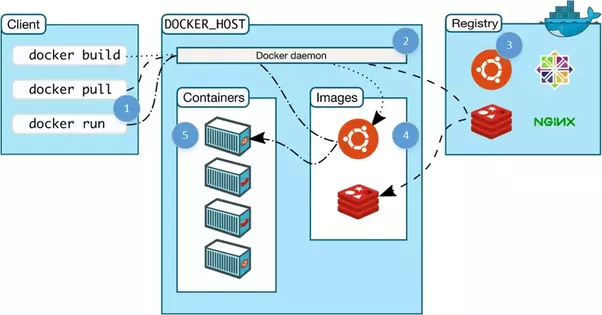
Docker — это наиболее распространённая технология контейнеров, именно Docker имеют в виду, когда говорят о контейнерах вообще. Тем не менее, существуют и другие open source технологии контейнеров, например rkt от CoreOS. Крупные компании создают собственные движки, например lmctfy от Google. Docker стал стандартом в этой области. Он до сих пор строится на основе cgroups и пространстве имён, которые обеспечивает ядро Linux, а теперь и Windows.

В Docker контейнер состоит из слоёв образов, при этом бинарные файлы упакованы в один пакет. В базовом образе содержится операционная система, она может отличаться от ОС хоста.
ОС контейнера существует в виде образа. Она не является полноценной ОС, как система хоста. В образе есть только файловая система и бинарные файлы, а в полноценной ОС, помимо этого, есть ещё и ядро.
Поверх базового образа лежит ещё несколько образов, каждый из них является частью контейнера. Например, следующим после базового, может быть образ, который содержит apt-get зависимости. Следующим может быть образ с бинарными файлами приложения и т.д.
Самое интересное, это объединённая файловая система Docker. Например, у вас есть два контейнера со слоями образов a, b, c и a, b, d , тогда вам нужно хранить только по одной копии каждого слоя т.е. a, b, c, d , локально и в репозитории.
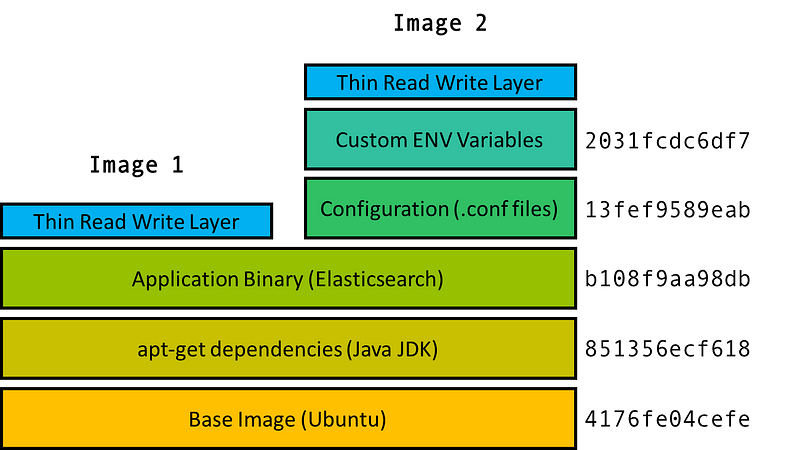
Каждый образ идентифицируется хэшем, и является одним из множества возможных слоёв образов, из которых состоит контейнер. Но идентификатором самого контейнера является только верхний образ, который содержит ссылки на родительские образы. На картинке выше видно, что два образа верхнего уровня (Image 1 и Image 2), разделяют три общих нижних слоя. В Image 2 есть два дополнительных слоя конфигурации, но родительские образы те же, что и у Image 1.
При загрузке контейнера происходит следующее: образ и его родительские образы подгружаются из репозитория, создаётся cgroup и пространство имён, далее образ используется для создания виртуального окружения. Файлы из контейнера, в том числе и бинарные, в образе представлены как будто это единственные файлы на всей машине. После этого, запускается основной процесс контейнера. Теперь можно считать контейнер работающим.
В Docker есть ещё очень классные фичи, например копирование во время записи, тома (общие файловые системы между контейнерами), docker daemon (управление контейнерами), репозитории с контролем версий (например Github для контейнеров), и много чего ещё.
Почему именно контейнеры
Помимо изоляции процессов, у контейнеров есть много преимуществ.
Контейнер — это самоизолированная единица, которая запустится на любой поддерживаемой платформе, и каждый раз это будет всё тот же контейнер. Независимо от операционной системы хоста, вы сможете запустить ту систему, которая находится в контейнере. Поэтому можете быть уверены, что контейнер, который вы создаёте на своём ноутбуке, будет работать так же на корпоративном сервере.
Кроме того, контейнер используют как способ унификации рабочего процесса. Существует даже парадигма — один контейнер — одна задача. Контейнер для запуска одного веб-сервера, одного сегмента базы данных и т. д. Чтобы масштабировать приложение, достаточно масштабировать количество контейнеров.
Эта парадигма подразумевает, что у каждого контейнера своя фиксированная конфигурация ресурсов (CPU, RAM, количество потоков и т.д.), поэтому достаточно масштабировать количество контейнеров, а не индивидуальные ресурсы. Это обеспечивает более простую абстракцию для масштабирования приложений.
Кроме того, контейнеры — это отличный инструмент для реализации архитектуры микросервисов. В таком случае, каждый микросервис это комплекс взаимодействующих контейнеров. Например, микросервис Redis, можно реализовать с одним мастер контейнером и несколькими slave контейнерами.
В такой (микро)сервис-ориентированной архитектуре, есть очень важные особенности, которые позволяют команде инженеров с лёгкостью создать и развернуть приложение.
Администрирование
Со времён Linux контейнеров, для того чтобы развернуть большие приложения, используют большое количество виртуальных машин, где каждый процесс выполняется в собственном контейнере. Такой подход требует эффективно развёртывать десятки, а то и тысячи контейнеров на сотнях виртуальных машин, управлять их сетями, файловыми системами и ресурсами. Docker позволяет делать это чуточку проще. Он предоставляет абстракции для определения сетевых ресурсов, томов для файловой системы, конфигурации ресурсов и т.д.
Для этого инструмента требуется:
- Назначить контейнеры машинам согласно спецификации (планирование)
- Загрузить нужные контейнеры в машины через Docker
- Решить вопросы с обновлениями, откатами и возможными изменениями системы
- Быть готовым к «падениям» контейнеров
- Создать кластерные ресурсы (мониторинг служб, взаимодействие между виртуальными машинами, вход/выход кластера)
Эти задачи относятся к администрированию распределённой системы, построенной на основе контейнеров (временно или постоянно изменяющихся). Для решения этих задач, уже созданы действительно классные системы.
Перевод статьи Will Wang : Demystifying containers 101: a deep dive into container technology for beginners





