
Поиск по тексту — одна из наиболее распространенных технологий, тогда как машинное обучение — самая распространенная. До появления RAG (retrieval-augmented generation — генерация ответа, дополненная результатами поиска) наиболее популярными были методы, основанные на n-граммах, или TF-IDF (term frequency-inverse document frequency — частота термина относительно обратной частоты документа). Однако ситуация изменилась с появлением нейронных сетей, которые позволяют использовать эмбеддинги для достижения более эффективных результатов во всех задачах, где требуется текстовый поиск. Для обучения представлению текста сегодня используются трансформеры. Эмбеддинги способны представлять нюансированную информацию, чего нельзя добиться при использовании статистических методов.
Однако эмбеддинги не всегда оказываются наилучшим выбором. Поэтому часто используется гибридный поиск с применением как плотных, так и разреженных техник. В гибридном поиске сочетаются достоинства этих двух подходов. Плотные векторы (полученные с помощью нейронных сетей) позволяют понять контекст запроса, а разреженные — преуспеть в поиске по ключевым словам. Например, при гибридном поиске по запросу «Что такое свет для Моне?» техника с разреженным вектором позволяет определить термин «свет» в живописи, но без учета его веса, а плотный вектор — найти статьи о Моне.
Использование рассеянных паттернов на основе IDF позволяет выбирать документы, наиболее подходящие для определенных ключевых слов. Плотная система, напротив, фокусируется на поиске глобальной ценности документа.
Гибридный поиск позволяет решать множество сложных задач, но все же он не идеален. Было бы предпочтительнее иметь плотный эмбеддинг, который позволил бы справиться со сложными случаями без необходимости применять гибридный поиск.
Для решения этой проблемы недавно был открыт и опубликован новый метод: CDE (contextual document embeddings — контекстные эмбеддинги документов).
Энкодеры обычно обучаются в ходе контрастного обучения, при котором необходимо минимизировать вектор для двух похожих текстов и сделать его как можно более непохожим на отрицательные примеры (например, в случае с изображениями вектор для изображения собаки должен быть похож на вектор другой собаки и непохож на другие типы животных или объектов).

Таким образом, энкодеры изучают представление, в котором два похожих документа будут иметь значение сходства (косинусное сходство), а разные документы — нижнее значение. Недостатком такой системы является то, что она не учитывает понятие контекста — только сходство между документами. Обычно это не является проблемой, особенно если поиск ведется в домене. Проблема в том, что часто эти модели обучаются только на одном наборе документов (одном домене) и тестируются на других типах документов (других типах доменов). Это приводит к тому, что выученные процессы эмбеддинга не являются надежными и поиск по сложным запросам не работает.
Также в запросе могут быть малоупотребимые слова, которые необходимо учитывать. Эти редкие слова являются важным сигналом для поиска, но система может не придать им правильного веса. Гибридный поиск исправляет это поведение, поскольку использует IDF (или методы, основанные на той же концепции). Редкое слово может быть обычным для определенного набора данных (например, «Моне» не является обычным словом, но очень часто встречается в наборе данных по искусству). Поэтому для обучения сбалансированному процессу эмбеддинга авторы нового метода CDE предлагают модификацию классического контрастивного обучения. Если для классического контрастивного обучения выбирают отрицательные примеры, то для его модификации — по одному примеру для каждого домена (набор данных делится на батчи (пакеты) с разыми метками). Кроме того, используется кластеризация, позволяющая выбрать наиболее сложные примеры для обучения.
Основная проблема заключается в том, как разработать нейронную архитектуру, которая могла бы учитывать контекстуализацию набора данных. С одной стороны, мы могли бы следовать методам, подобным BM25, и предварительно вычислить фиксированный набор статистических данных корпуса, которые можно было бы передать энкодеру документов. С другой стороны, мы можем предоставить энкодеру полный доступ ко всему корпусу документов, используя некую форму перекрестного внимания (источник).
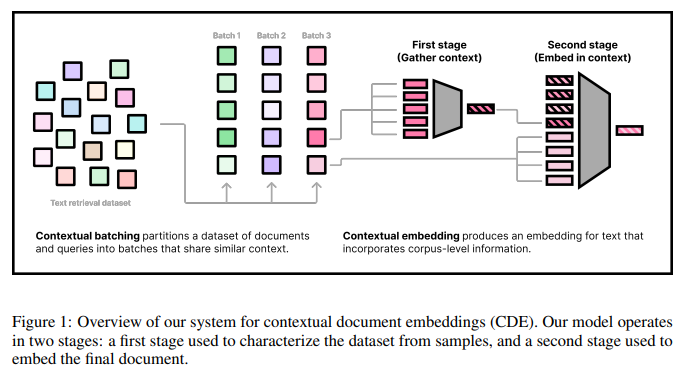
Выбранная авторами стратегия позволяет для начала отобрать лучшие примеры для обучения. После этого модель проходит два этапа: в ходе первого генерируется контекст для корпуса (подготовительный этап эмбеддинга), в ходе второго выполняется окончательный эмбеддинг документа.
Затем авторы CDE тестируют два конкретных параметра: размер батча и размер кластера. В своих экспериментах они также используют небольшой трансформер (6 слоев), обучают его на наборе данных, взятых из интернета, и тестируют на стандартном бенчмарке MTEB.
Для архитектуры предлагаем новый энкодер, который вводит информацию о контекстных документах во время эмбеддинга. Предложенная архитектура дополняет стандартный энкодер в стиле BERT дополнительными условиями, которые предоставляют агрегированную информацию о соседних документах на уровне документов. Вот почему мы называем метод «контекстным эмбеддингом документов»(источник).
Главный результат CDE заключается в том, что, в отличие от классического би-энкодера, модель демонстрирует оптимизированную производительность в задачах поиска. Это особенно заметно при оценке двух небольших и не связанных между собой наборов данных.
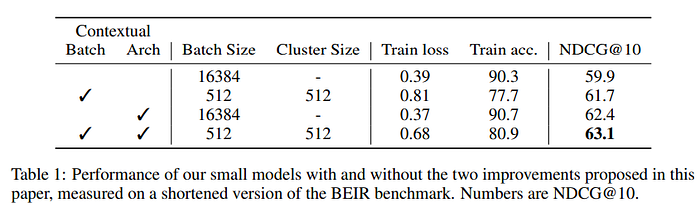
Еще одним достойным внимания результатом является то, что перестановка точек данных для создания более сложных батчей помогает обучению и улучшает обучаемость.
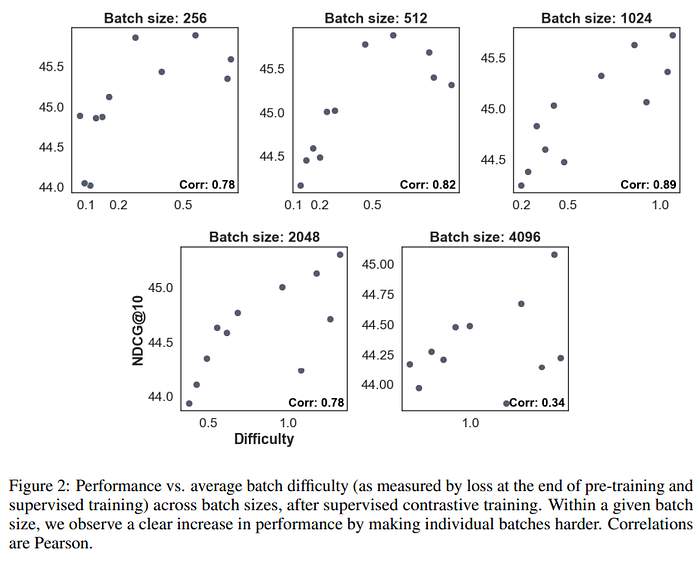
Авторы CDE предлагают применять небольшие батчи, поскольку в них меньше легковесных отрицательных примеров (рекомендуется также использовать небольшие кластеры).
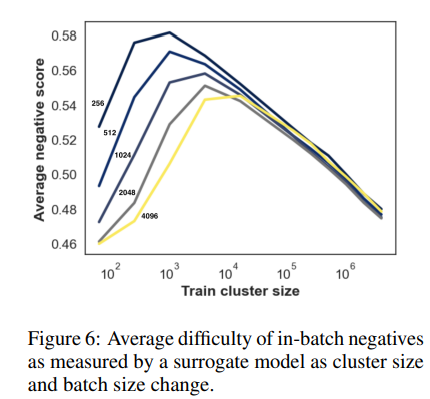
Эта контекстная информация помогает модели, особенно если в наборе данных несколько доменов.
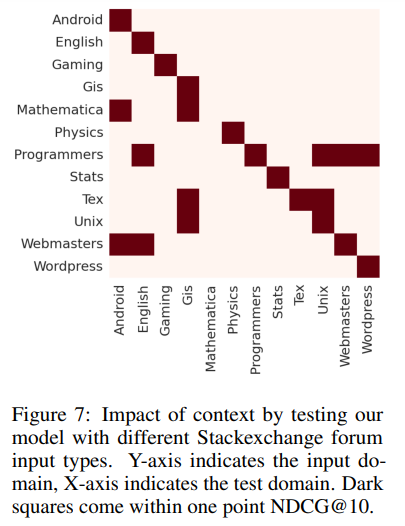
Аналогично предварительно вычисленному на уровне корпуса статистическому значению, этот метод позволяет учитывать при эмбеддинге относительную частоту терминов в контексте. Архитектура контекстного энкодера позволила добиться дополнительных улучшений по сравнению с базовой моделью во всех протестированных областях, причем в таких специфических доменах, как небольшие наборы данных финансовых и медицинских документов, улучшения оказались более значительными (источник).
При всей своей эффективности гибридный поиск имеет ограничения. Система ресурсоемка (использование двух моделей означает увеличение вычислительных затрат). В случае больших наборов данных она становится дорогостоящей, поскольку возникает риск использования большего количества ресурсов или увеличения задержки для пользователей. Особенно серьезной проблема задержки становится при большом количестве пользователей. Кроме того, гибридный поиск требует повторного ранжирования, поскольку объединить результаты, полученные с помощью двух моделей (разреженной и плотной), может быть нелегко. Неправильный выбор гиперпараметров может привести к предвзятости двух моделей. К тому же при разреженном поиске возникают проблемы, связанные с незнакомыми словами и разреженностью данных, которые гибридный поиск не решает. Как уже было сказано, при использовании плотной модели, обученной на другом домене, ее производительность резко падает и эффективность гибридного поиска заметно снижается.
В данной статье мы попытались объединить преимущества двух систем в одной модели. Хотя продвинутые конвейеры RAG являются дорогостоящими, в будущем мы сможем получить модели, объединяющие различные функции отдельных блоков.
Читайте также:
- Продвинутая генерация ответа, дополненная результатами поиска (RAG): от теории до реализации на LlamaIndex
- Как спроектировать рекомендательную систему
- 12 стратегий настройки готовых к производству RAG-приложений
Читайте нас в Telegram, VK и Дзен
Перевод статьи Salvatore Raieli: Neighbors Count: Boosting Document Embeddings with Contextual Encoding




