
Я использую Python уже почти пять лет, и этот язык стал для меня основным средством решения повседневных задач. Независимо от того, пытаюсь ли я повысить эффективность, упростить рабочие процессы или решить сложные задачи написания кода, Python никогда не подводил меня. За последний год я сосредоточился на совершенствовании навыков создания кода и поиске практик, значительно повышающих производительность и эффективность. В этой статье я поделюсь некоторыми из лучших фрагментов кода Python, используемых мной для решения повседневных задач.
Как говорил великий Альберт Эйнштейн, «никогда не запоминайте то, что можно найти в книге».
Зачем запоминать каждое решение по написанию кода, если можно иметь под рукой эти удобные фрагменты Python?
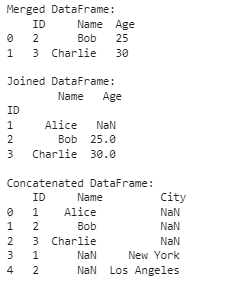
1. Объединение нескольких датафреймов в один
Мы часто получаем данные из нескольких файлов, и для их эффективного анализа необходимо объединить их в один датафрейм.
import pandas as pd
# Примеры датафреймов
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Name': ['Alice', 'Bob', 'Charlie']})
df2 = pd.DataFrame({'ID': [2, 3, 4], 'Age': [25, 30, 35]})
df3 = pd.DataFrame({'ID': [1, 2], 'City': ['New York', 'Los Angeles']})
# Способ 1: Слияние (аналогично SQL JOIN)
merged_df = pd.merge(df1, df2, on='ID', how='inner')
# Способ 2: операция join (объединение на основе индекса)
joined_df = df1.set_index('ID').join(df2.set_index('ID'))
# Способ 3: Конкатенация (добавление строк)
concatenated_df = pd.concat([df1, df3], ignore_index=True)
print("Merged DataFrame:\n", merged_df)
print("\nJoined DataFrame:\n", joined_df)
print("\nConcatenated DataFrame:\n", concatenated_df)
2. Слияние списков
Слияние списков — преобразование списка списков в единый, унифицированный список. Списковое включение делает этот процесс простым и эффективным, упрощая манипулирование данными и доступ к ним.
nested_list = [[1, 2, 3], [4, 5], [6, 7], [8,9],[10,11]]
flattened_list = [item for sublist in nested_list for item in sublist]
print(flattened_list)
"""Вывод"""
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
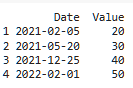
3. Фильтрация данных в Pandas на основе интервала дат
Работа с данными временных рядов часто требует фильтрации записей в определенном интервале дат. Например, чтобы получить данные в интервале между 2 февраля 2021 года и 2 февраля 2022 года, можно использовать аксессор .loc с булевой индексацией. Этот метод обеспечивает чистый и эффективный способ фильтрации данных по дате.
import pandas as pd
# Пример датафрейма со столбцом Date
data = {
'Date': ['2021-01-15', '2021-02-05', '2021-05-20', '2021-12-25', '2022-02-01', '2022-03-10'],
'Value': [10, 20, 30, 40, 50, 60]
}
df = pd.DataFrame(data)
# Преобразование столбца 'Date' в формат datetime
df['Date'] = pd.to_datetime(df['Date'])
# Определение диапазона дат
start_date = '2021-02-02'
end_date = '2022-02-02'
# Фильтрация датафрейма по конкретному диапазону дат
filtered_df = df.loc[(df['Date'] >= start_date) & (df['Date'] <= end_date)]
print(filtered_df)
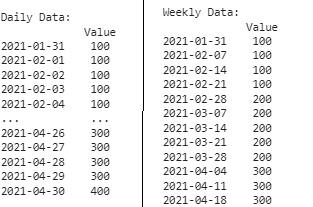
4. Преобразование ежемесячных данных в ежедневные или еженедельные
При работе с данными, представляемыми ежемесячно, может потребоваться преобразовать их в ежедневные или еженедельные интервалы для более тщательного анализа. Этот фрагмент кода позволяет преобразовать ежемесячные данные в ежедневный или еженедельный формат, предоставляя возможность получить более подробную информацию и оптимизировать управление данными.
import pandas as pd
# Пример датафрейма с ежемесячными данными
dates = pd.date_range('2021-01-01', periods=4, freq='M')
data = pd.DataFrame({'Value': [100, 200, 300, 400]}, index=dates)
# Способ 1: Преобразование ежемесячных данных в ежедневные
daily_data = data.resample('D').ffill()
# Способ 2: Преобразование ежемесячных данных в еженедельные
weekly_data = data.resample('W').ffill()
print("Daily Data:\n", daily_data)
print("\nWeekly Data:\n", weekly_data)
5. Простая нарезка текста
Нарезка текста — распространенная задача при работе со строками в Python. С помощью нарезки можно легко извлекать определенные части строки без использования сложных операций со строками.
# Пример списка
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 1. Переворачивание списка
reversed_data = data[::-1]
print("Reversed:", reversed_data)
# 2. Нарезка с шагом
step_slice = data[::2] # Каждый второй элемент
print("Every second element:", step_slice)
# 3. Нарезка с отрицательным шагом (обратная нарезка)
reverse_step_slice = data[8:2:-2] # Нарезка от индекса 8 до 2 с шагом -2
print("Reverse step slice:", reverse_step_slice)
# 4. Нарезка с ориентацией на начальный и конечный индексы
range_slice = data[3:7] # Элементы с индексом от 3 до 6
print("Elements from index 3 to 6:", range_slice)
# 5. Нарезка с комбинацией начала, конца и шага
combined_slice = data[1:9:3] # Элементы с индексом от 1 до 8 с шагом 3
print("Elements from index 1 to 8 with step 3:", combined_slice)
6. Сортировка списка словарей
Сортировка списка словарей по определенному ключу помогает организовать данные более эффективно. Этот фрагмент кода полезен для упорядочивания данных по таким критериям, как даты, имена или числовые значения.
dict1 = [
{"Name":"Karl",
"Age":25},
{"Name":"Lary",
"Age":39},
{"Name":"Nina",
"Age":35}
]
## Использование sort()
dict1.sort(key=lambda item: item.get("Age"))
# Сортировка списка с помощью itemgetter
from operator import itemgetter
f = itemgetter('Name')
dict1.sort(key=f)
# Итерируемая функция sorted
dict1 = sorted(dict1, key=lambda item: item.get("Age"))
'''Вывод
[{'Age': 25, 'Name': 'Karl'},
{'Age': 35, 'Name': 'Nina'},
{'Age': 39, 'Name': 'Lary'}]
'''
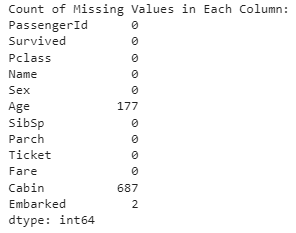
7. Получение количества пропущенных значений в каждом столбце
Отсутствующие данные — одна из основных проблем в проектах дата-сайентистов, и ее решение — одна из самых важных задач. Прежде чем приступать к решению проблемы недостающих значений, необходимо получить представление о недостающих значениях в данных. Этот фрагмент кода позволяет быстро подсчитать количество отсутствующих значений в каждом столбце, что облегчает выявление неполных данных и принятие решения о способе их обработки.
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/Abhayparashar31/datasets/refs/heads/master/titanic.csv')
missing_values_count = df.isnull().sum()
print("Count of Missing Values in Each Column:")
print(missing_values_count)
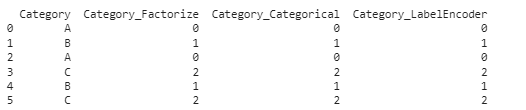
8. Преобразование категориальных данных в целочисленные
Преобразование категориальных данных в целые числа — обычный этап подготовки их для моделей машинного обучения. Этот фрагмент кода упрощает процесс, делая данные более удобными для использования в алгоритмах, которым требуется числовой ввод.
import pandas as pd
# Пример датафрейма с категориальными данными
df = pd.DataFrame({
'Category': ['A', 'B', 'A', 'C', 'B', 'C']
})
# Способ 1: использование pd.factorize()
df['Category_Factorize'] = pd.factorize(df['Category'])[0]
# Способ 2: использование pd.Categorical
df['Category_Categorical'] = pd.Categorical(df['Category']).codes
# Способ 3: использование LabelEncoder из sklearn
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['Category_LabelEncoder'] = le.fit_transform(df['Category'])
print(df)
9. Точное форматирование чисел с плавающей запятой
Точное форматирование чисел с плавающей запятой очень важно для точного и наглядного отображения числовых данных.
# 1. Использование f-строк (форматированных строковых литералов)
value = 123.456789
formatted_value = f"{value:.2f}" # Keeps 2 decimal places
print(formatted_value) # Output: 123.46
# 2. Использование метода format()
formatted_value = "{:.2f}".format(value) # Format with 2 decimal places
print(formatted_value) # Output: 123.46
# 3. Использование функции round()
rounded_value = round(value, 2)
print(rounded_value) # Output: 123.46
# 4. Форматирование строк с помощью оператора %
formatted_value = "%.2f" % value # Format to 2 decimal places
print(formatted_value) # Output: 123.46
# 5. Использование Decimal для точной обработки десятичных чисел
from decimal import Decimal
value = Decimal('123.456789')
formatted_value = round(value, 2)
print(formatted_value) # Output: 123.46
10. Работа со столбцами с британским форматом даты
Во многих странах используется британский формат дат, в котором даты записываются как день-месяц-год. Вы можете работать с этим форматом, включив параметр dayfirst.
import pandas as pd
df = pd.DataFrame({'date_time': ['6/12/2000 12:32', '13/5/2001 11:45', '11/12/2005 1:57'],
'value': [2, 3, 4]})
pd.to_datetime(df['date_time'],dayfirst=True)
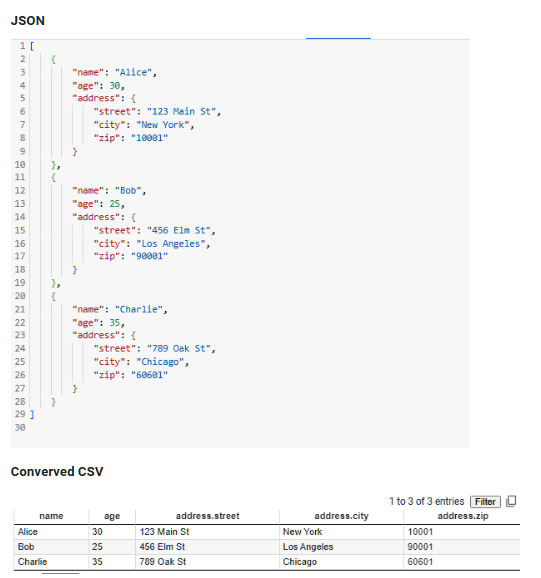
11. Преобразование JSON в CSV
Работа с данными в формате JSON — обычное дело, но многие инструменты и приложения предпочитают файлы CSV. В этом фрагменте кода решается повседневная задача преобразования данных JSON в CSV, что облегчает работу с электронными таблицами или выполнение задач по анализу данных.
import pandas as pd
from pandas import json_normalize
import json
# Загрузка данных в формате JSON
with open('/content/data.json') as f: ## Пример JSOn в Colab
data = json.load(f)
# Нормализация JSON-данных
df = json_normalize(data)
# Сохранение в формате CSV
df.to_csv('output_file.csv', index=False)
12. Нахождение всех подмножеств множества с помощью одной строки
При работе с множествами часто возникает задача поиска всех возможных подмножеств, будь то составление комбинаций для тестирования, математических вычислений или решения алгоритмических задач.
Данный фрагмент кода решает повседневную задачу поиска всех подмножеств множества, сводя ее к одной строке кода. Во многих случаях это удобный инструмент.
from itertools import combinations
data = [55,65,32,44,67]
print(list(combinations(data, 3)))
"""Вывод"""
[(55, 65, 32), (55, 65, 44), (55, 65, 67), (55, 32, 44), (55, 32, 67),
(55, 44, 67), (65, 32, 44), (65, 32, 67), (65, 44, 67), (32, 44, 67)]
13. Декодирование файла в кодировке Base64
Файлы в кодировке Base64 часто встречаются при работе с вложениями электронной почты, изображениями или передачей данных. Проблема возникает, когда нужно декодировать файл в исходный формат.
import base64, sys base64.decode(open(sys.argv[1], "rb"), open(sys.argv[2], "wb"))
14. Принятие множественных вводов, разделенных пробелами
Этот фрагмент кода позволяет одновременно принимать несколько вводов, разделенных пробелами. Он пригодится при выполнении заданий на соревнованиях по программированию.
## Принятие двух целых чисел на вход
a,b = map(int,input().split())
print("a:",a)
print("b:",b)
## Принятие на вход списка
arr = list(map(int,input().split()))
print("Input List:",arr)
Время на выполнение задания:
— — — — — — —
— — — — — — —
a, b = 256, 256 print(a is b)
Что будет получено в результате? True? Ага!
А как насчет a, b = 257, 257 print(a is b)?
Что теперь будет на выходе? True или False?
15. Сортировка списка на основе другого списка
Иногда при работе с двумя связанными списками может потребоваться отсортировать один из них на основе порядка другого. Реальным примером может быть список имен студентов и соответствующий список их оценок. Представьте, что вам необходимо отсортировать имена студентов по их оценкам.
# Списки для сортировки
names = ['Alice', 'Bob', 'Charlie', 'David']
scores = [85, 92, 78, 90]
# Желаемый порядок сортировки
desired_order = [3, 1, 4, 2] # определяет желаемый порядок
# Сортировка имен в нужном порядке
sorted_names = [x for _, x in sorted(zip(desired_order, names))]
print(sorted_names)
"""Вывод"""
['Bob', 'David', 'Alice', 'Charlie']
16. Расчет времени выполнения ячейки
Знание времени выполнения блока кода или ячейки очень важно для оптимизации производительности. Этот фрагмент кода поможет вычислить, сколько времени занимает выполнение участка кода, что позволит выявить медленно выполняемые участки и оптимизировать работу с ними.
# Способ 1
import datetime
start = datetime.datetime.now()
"""
CODE
"""
print(datetime.datetime.now()-start)
# Способ 2
import time
start_time = time.time()
main()
print(f"Total Time To Execute The Code is {(time.time() - start_time)}" )
# Способ 3
import timeit
code = '''
## Участок кода, время выполнения которого необходимо измерить
[2,6,3,6,7,1,5,72,1].sort()
'''
print(timeit.timeit(stmy = code,number = 1000))
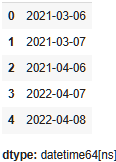
17. Сборка столбца DateTime
В наборах данных с отдельными столбцами для года, месяца и дня их объединение в один столбец DateTime имеет решающее значение для точного временного анализа.
import pandas as pd
df = pd.DataFrame({'year': [2021,2021,2021,2022, 2022],
'month': [3,3,4,4,4],
'day': [6,7,6,7,8],
})
pd.to_datetime(df[['month','day','year']])
18. Наиболее часто встречающийся элемент в списке
Этот фрагмент кода находит наиболее часто встречающиеся элементы в списке.
def most_frequent(given_list):
return max(set(given_list),key = given_list.count)
print(most_frequent([1,2,3,3,3,3,4,4,5,5]))
"""Вывод"""
3
19. Пропуск верхних n строк набора данных
Иногда при загрузке данных из онлайн-источников верхние строки могут содержать метаданные или нерелевантную информацию, не пригодную для анализа или моделирования. Используя параметр skiprows в read_csv(), можно легко пропустить верхние `n` строк и сосредоточиться на самом наборе данных для дальнейшей обработки.
import pandas as pd
pd.read_csv('data.csv',skiprows=3) ## пропуск 3 верхних строк набора данных
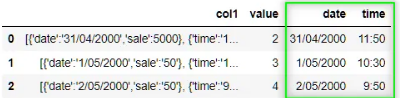
20. Извлечение дат из списка словарей
Извлечение дат из списка словарей необходимо при работе со структурированными данными, содержащими информацию, связанную со временем. Этот фрагмент помогает эффективно извлекать значения дат из нескольких словарных записей, упрощая обработку и анализ данных.
## Создадим пример датафрейма
df = pd.DataFrame({'col1': ["[{'date':'31/04/2000','sale':5000}, {'time':'11:50','info':'checked'}]",
"[{'date':'1/05/2000','sale':'50'}, {'time':'10:30','info':'checked'}]",
"[{'date':'2/05/2000','sale':'50'}, {'time':'9:50','info':'checked'}]"],
'value': [2, 3, 4]})
## Главный код
dates = []
time = []
for row in df['col1']:
for data in eval(row):
try:
dates.append(data['date'])
except:
time.append(data['time'])
df['date'] = dates
df['time'] = time
21. Обработка исключений с помощью выражения else
В Python можно использовать выражение else в блоке try-except. Блок else выполняется только в том случае, если не возникло исключений, что позволяет четко разграничивать обработку ошибок и обычное выполнение.
try:
num = int(input("Enter a number: "))
except ValueError:
print("That's not a valid number!")
else:
print(f"You entered: {num}")
finally:
print("This will always run.")
22. Контроль использования памяти
Мониторинг использования памяти — крайне важная задача, особенно при работе с большими массивами данных или оптимизации производительности кода. Проверка того, сколько памяти потребляют объекты Python, поможет выявить узкие места, предотвратить утечки памяти и повысить общую эффективность.
import sys a = 10 print(sys.getsizeof(a))
23. Обработка ошибок, связанных с обращением к несуществующим ключам в словарях
При работе со словарями обращение к несуществующему ключу приведет к ошибке KeyError. Чтобы избежать этого, можно использовать метод .get(), который позволяет задать значение по умолчанию на случай, если ключ не будет найден.
data = {"name": "Alice", "age": 25}
# Обработка KeyError с помощью значения по умолчанию
age = data.get("age", "Key not found")
print(age)
# Попытка получить доступ к несуществующему ключу
location = data.get("location", "Unknown")
print(location) # Output: Unknown

24. Повторное использование кода с помощью частично определенных функций
Частично определенные функции, доступные через модуль Python functools, позволяют заранее определить некоторые аргументы функции, создавая новую функцию с меньшим количеством входных данных. Это особенно полезно для создания адаптированных версий функций, повышения гибкости кода и повторного использования без изменения исходной функции.
from functools import partial
def calculate_shipping_cost(weight: float, distance: int, rate_per_kg: float) -> float:
total_cost = weight * distance * rate_per_kg
return total_cost
# Создание частично определенных функций для конкретных тарифов на доставку
domestic_shipping = partial(calculate_shipping_cost, rate_per_kg=0.05)
international_shipping = partial(calculate_shipping_cost, rate_per_kg=0.15)
# Расчет стоимости доставки по разным тарифам
domestic_cost = domestic_shipping(weight=10, distance=300)
international_cost = international_shipping(weight=5, distance=1200)
# Вывод результатов
print(f"Domestic shipping cost: ${domestic_cost:.2f}")
print(f"International shipping cost: ${international_cost:.2f}")
25. Подсчет случаев появления элемента
В повседневных задачах по анализу данных часто требуется определить, сколько раз тот или иной элемент появляется в списке. Это может быть полезно для таких задач, как анализ результатов опросов или обработка журналов действий пользователей. Применение моржового (walrus) оператора может упростить этот процесс, позволяя эффективно назначать и использовать подсчеты для каждого элемента.
from collections import Counter
words = ['red', 'blue', 'red', 'green', 'blue', 'blue']
word_counts = Counter(words)
print(word_counts)
"""Вывод"""
Counter({'blue': 3, 'red': 2, 'green': 1})
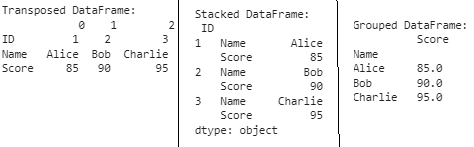
26. Переформатирование датафрейма
Переформатирование датафрейма часто необходимо для корректировки его структуры, позволяющей оптимизировать анализ или визуализацию данных. Этот фрагмент помогает преобразовать структуру данных, облегчая работу с различными форматами и удовлетворяя конкретные аналитические потребности.
import pandas as pd
# Пример датафрейма
df = pd.DataFrame({
'ID': [1, 2, 3],
'Name': ['Alice', 'Bob', 'Charlie'],
'Score': [85, 90, 95]
})
# Способ 1: перенос
transposed_df = df.T
# Метод 2: стек (сводный датафрейм)
stacked_df = df.set_index('ID').stack()
# Способ 3: GroupBy и Aggregate
grouped_df = df.groupby('Name').agg({'Score': 'mean'})
print("Transposed DataFrame:\n", transposed_df)
print("\nStacked DataFrame:\n", stacked_df)
print("\nGrouped DataFrame:\n", grouped_df)
27. Метаклассы для создания классов
В Python метаклассы дают контроль над процессами создания и поведения классов. По сути, метакласс является классом для классов, определяющим поведение классов так же, как классы определяют поведение объектов. Эта возможность метаклассов особенно полезна, когда нужно настроить или автоматизировать создание классов.
class LowercaseAttributeMeta(type):
def __new__(cls, name, bases, dct):
# Применение соглашения о наименовании атрибутов в нижнем регистре
for attr_name in dct:
if not attr_name.islower() and not attr_name.startswith('_'):
raise TypeError(f"Attribute '{attr_name}' is not in lowercase.")
return super().__new__(cls, name, bases, dct)
class MyLowercaseClass(metaclass=LowercaseAttributeMeta):
_private_attr = 10 # Действительно
lowercase_attr = 20 # Действительно
# Это приведет к ошибке, поскольку имя атрибута не находится в нижнем регистре
try:
class InvalidLowercaseClass(metaclass=LowercaseAttributeMeta):
UpperCaseAttr = 10 # Это вызовет TypeError
except TypeError as e:
print(e)
28. Вывод уникального идентификатора переменной
В Python каждому объекту присваивается уникальный идентификатор, доступ к которому можно получить с помощью функции id(). Этот идентификатор полезен при необходимости отслеживать объекты, особенно при работе с изменяемыми типами данных, такими как списки или словари, чтобы знать, указывают ли две переменные на один и тот же объект в памяти.
# Определение переменной
a = [1, 2, 3]
# Вывод уникального идентификатора переменной 'a'
print(f"The unique ID of variable 'a': {id(a)}")
# Присвоение 'a' новой переменной 'b'
b = a
# Вывод уникального идентификатора переменной 'b', чтобы проверить, указывают ли они обе на один и тот же объект
print(f"The unique ID of variable 'b': {id(b)}")
# Определение нового списка и вывод его уникального идентификатора для того, чтобы показать разницу
c = [1, 2, 3]
print(f"The unique ID of variable 'c': {id(c)}")
# Проверка того, являются ли 'a' и 'c' одним и тем же объектом
print(f"'a' and 'c' are the same object: {a is c}")
"""
The unique ID of variable 'a': 140701793403712
The unique ID of variable 'b': 140701793403712
The unique ID of variable 'c': 140701793404032
'a' and 'c' are the same object: False
"""
Читайте также:
- 5 навыков работы в Python на прокачку
- 10 способов повысить качество Python-кода
- Оптимизация кода Python с помощью конечных запятых: мощная техника
Читайте нас в Telegram, VK и Дзен
Перевод статьи Abhay Parashar: 28 Insanely Useful Python Code Snippets For Everyday Problems





