
Представляем новый запуск тестов производительности на Kubernetes 1.26 и Ubuntu 22.04 с обновленной в январе 2024 года версией CNI.
Общий обзор
1) Контекст тестирования
1.1) Выбор CNI
1.2) Протокол тестирования
1.3) Переход к сети 40 Гбит
1.4) Мониторинг со statexec от BlackSwift
2) Результаты тестов
2.1) Полнота необработанных результатов и самостоятельное изучение
2.2) Пример «сырых» данных для теста DTM, то есть Direct TCP Multistream
2.3) Извлечение информации из «сырых» данных
2.4) Меньше разговоров, больше результатов
3) Интерпретация
3.1) Надежность тестов
3.2) Глобальная производительность
3.3) Влияние eBPF
3.4) Стремление к эффективности, путь к экологически безопасным вычислениям?
3.5) Недостаток UDP и опасения по поводу HTTPv3
3.6) Пример Calico VPP
3.7) Выбор правильного протокола сетевого шифрования
4) Заключение, или какой CNI выбрать?
1) Контекст тестирования
1.1) Выбор CNI
Из 33 доступных для Kubernetes сетевых интерфейсов контейнеров, далее — CNI, было отобрано всего семь. Критерии для включения в тестирование строгие, ориентированные на обеспечение актуальности и применимости в разнообразных средах.
Чтобы им соответствовать, CNI должен:
— активно сопровождаться, иметь за последний год хотя бы один коммит;
— быть облачно- или аппаратно-независимым вроде Azure CNI, Cisco ACI…;
— не быть мета-CNI, такими как Multus, Spiderpool…;
— поддерживать сетевые политики, это необязательно, но доступность такой возможности важна в 2024 году;
— легко устанавливаться стандартными командами Kubernetes.
В тестирование CNI включен Flannel, хотя соответствует не всем требованиям, особенно по сетевым политикам. Сделано это в целях сравнения и оценки того, как на фоне простого, ориентированного на подключение Flannel смотрятся другие, полнофункциональные CNI.
Для каждого выбранного CNI из вкладки selection электронной таблицы тестирования рассмотрены изложенные в соответствующей документации различные конфигурации, среди которых — включение шифрования трафика с WireGuard, замена kube-proxy на eBPF и т. д. Всего протестирован 21 вариант CNI из вкладки variants.
Вот семь выбранных CNI с их вариантами, итого 21 конфигурация:
- Antrea v1.15.0
Варианты: стандартный / без инкапсуляции / IPsec / Wireguard. - Calico v3.27.2
Варианты: стандартный / eBPF / Wireguard / eBPF+Wireguard / VPP / VPP IPsec / VPP Wireguard. - Canal v3.27.2
Варианты: стандартный. - Cilium v1.15.2
Варианты: стандартный / с Hubble / без hubble / без kubeproxy / IPsec / Wireguard. - Kube-OVN v1.12.8
Варианты: стандартный. - Kube-router v2.1.0
Варианты: стандартный / весь функционал.
1.2) Протокол тестирования
Тестовой площадкой стало три сервера Supermicro без операционной системы, соединенных между собой 40-гигабитным переключателем, а с ним — пассивными кабелями DAC SFP+ и сконфигурированных в одной и той же сети VLAN с jumbo-кадрами MTU 9000. Подробнее об аппаратно-программной версии — во вкладке context.
Чтобы точнее воспроизвести реальные условия в оценке CNI, от всесторонней настройки системы решено отказаться. Только установили модуль WireGuard для CNI и активировали jumbo-кадры в сетевых интерфейсах. Сервера запускались с ядром Ubuntu 22.04 по умолчанию и были «коробочными».
Этим обеспечиваются максимальная актуальность и применимость результатов тестов для широкого круга пользователей Kubernetes с формированием у них четкого представления о работе каждого CNI в типичных условиях. Специализированных оптимизаций системы не проводилось, ведь у пользователей может не быть ресурсов/опыта/знаний для всесторонней ее настройки.
В Ubuntu 22.04 с помощью дистрибутива RKE2 развернули версию 1.26.12 Kubernetes, для повышения воспроизводимости применялась последовательная структура: плоскость управления Kubernetes всегда располагалась на первом узле a1, серверный компонент тестирования — на втором сервере a2, клиентская часть — на третьем a3, атрибутом nodeName поды статически назначались узлам:
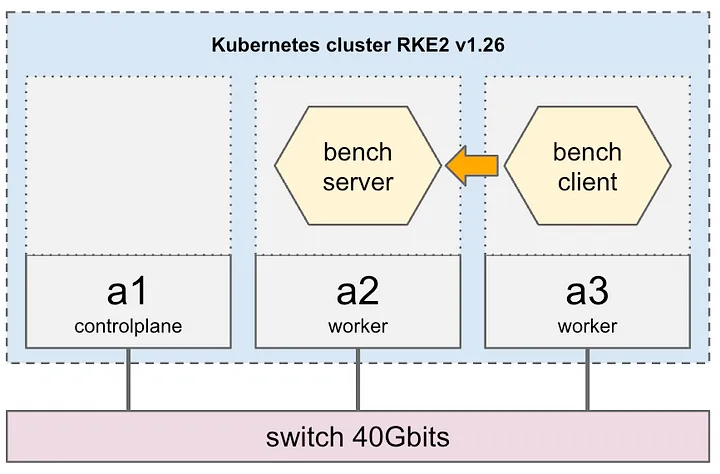
Все варианты CNI подверглись трем тестовым прогонам, на каждом из которых серверы переустанавливались, а кластер переразвертывался. Один прогон с 12 этапами и девятью различными тестами длился около получаса:
- [prepare] развертывание узлов, установка Kubernetes, настройка CNI;
- [info] сбор информации, например данных MTU интерфейсов;
- [idle] измерение производительности в режиме ожидания для оценки накладных расходов на потребление ресурсов процессора и памяти после установки CNI;
- [dts] пропускная способность TCP напрямую из пода в под с одним потоком;
- [dtm] пропускная способность TCP напрямую из пода в под с несколькими потоками (8);
- [dus] пропускная способность UDP напрямую из пода в под с одним потоком;
- [dum] пропускная способность UDP напрямую из пода в под с несколькими потоками (8);
- [sts] пропускная способность TCP из пода в Service с одним потоком;
- [stm] пропускная способность TCP из пода в Service с несколькими потоками (8);
- [sus] пропускная способность UDP из пода в Service с одним потоком;
- [sum] пропускная способность UDP из пода в Service с несколькими потоками (8);
- [teardown] деинсталляция всех узлов и кластера Kubernetes.
Этим протоколом формируется исчерпывающее представление о производительности, надежности и потреблении ресурсов каждого CNI — основа для содержательных сравнений и выводов.
1.3) Переход к сети 40 Гбит
Изначально CNI тестировались на 10-гигабитном оборудовании и однопроцессорных серверах Intel Xeon CPU E5–1630 v3, пока мы не перешли к более современному 40-гигабитному тестированию с процессорами поновее AMD EPYC 7262, хранилищем NVMe и другими доработками, кардинально изменив ими тесты.
Что касается производительности сети, с пропускной способностью 10 Гбит/с однопоточный процесс справляется легко, а вот при 40 Гбит/с появляются сложности. Инструмент для измерения производительности iperf3 фактически однопоточный, и в однопоточном сценарии на процессоре с тактовой частотой более 3,5 ГГц им достигается максимум 20–30 Гбит. Из-за этого ограничения сам iperf3 стал узким местом в тестах. Но его удалось преодолеть, используя iperf3 не с официальных репозиториев Ubuntu, а версию 3.16 с поддержкой многопоточных измерений, которая появилась в декабре 2023 года.
Другим заметным результатом обновления оборудования стало появление двухпроцессорных серверов. Когда сетевая карта подключена через PCI-Express к одному из двух процессоров, запущенные на другом процессоре процессы при интенсивном сетевом трафике оказываются не у дел. Можно, конечно, привязать процессы к корректному узлу NUMA, а фактически к нужному процессору. Но, чтобы вся цепочка обработки — iperf3, связанные с CNI процессы, драйверы карты сетевого интерфейса и т. д. — находилась на одном узле, потребуется настройка системы. Опять же, чтобы максимально точно воспроизвести реальные рабочие нагрузки продакшена, решено отказаться от подобной настройки, допуская свободное распределение процессов по процессорам.
Ограничения пропускной способности одного ядра процессора фактически преодолеваются запуском iperf3 с восемью параллельными потоками, хотя для этого достаточно и двух, а заодно повышается вероятность выполнения на подключенном к сетевой карте оптимальном узле NUMA минимум двух процессов iperf3. Таким образом сетевая карта добралась до своей предельной пропускной способности ~40 Гбит/с.
Этим стратегическим подходом открываются новые возможности, обеспечивается точное отражение в тестах производительности, ожидаемой пользователями в реальных эксплуатационных средах без всесторонней оптимизации системы.
1.4) Мониторинг со statexec от BlackSwift
Уникальный характер тестирования сказался на мониторинге кластера Kubernetes:
- Учитывая, что тесты длятся около минуты, при сборе показателей важно достичь второго уровня детализации.
- Высокими сетевыми нагрузками тестирования сильно затрудняются процессы сбора показателей, которые зависят от передачи по сети, например извлечение с помощью Prometheus узлов-экспортеров в узлах кластера.
- Чтобы избежать влияния на результаты тестирования, при мониторинге важно минимизировать расход ресурсов: процессора, памяти, диска и т .д.
Французская компания BlackSwift при предоставлении пространств имен Kubernetes как услуги, осуществлении НИОКР и оценке технологий для своих продуктов сталкивается с аналогичными сложностями. Вместе мы разработали утилиту statexec, которой во время выполнения той или иной команды фиксируются и в формате OpenMetrics экспортируются системные показатели для интеграции в системы вроде Victoria Metrics и Prometheus.
Этим автономным, без внешних зависимостей инструментом, написанным на Go, расходуется минимум ресурсов. Включенный в него функционал — детализация второго уровня, полный сбор системных показателей в памяти и синхронизация команд — приходится особенно кстати для сетевых тестов с последовательными запусками сервера и клиента. В утилите имеется контейнеризованный стек на основе Docker-compose с Grafana и базой данных Victoria Metrics — с ними проще изучать собранные показатели.
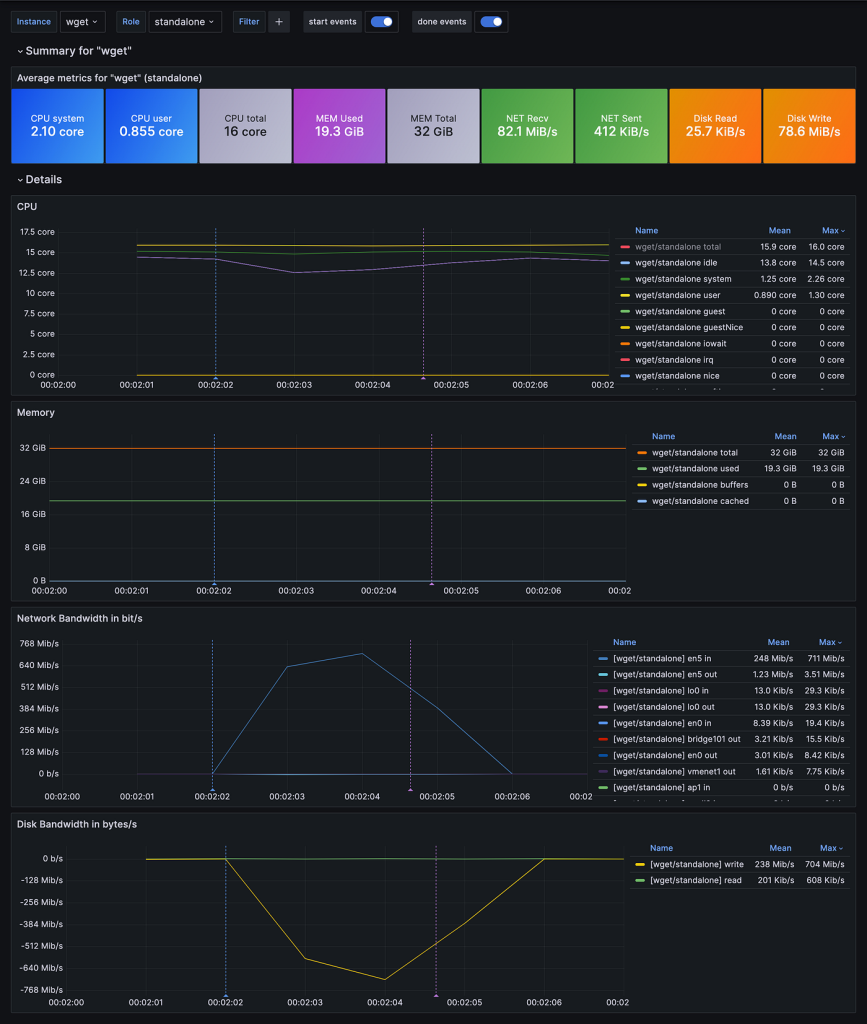
Подробнее — здесь.
2) Результаты тестов
2.1) Полнота необработанных результатов и самостоятельное изучение
В ходе этого тестирования генерируется существенный объем данных. Поэтому, чтобы облегчить понимание и интерпретацию, графики представлены в упрощенном виде. Их полное включение в статью контрпродуктивно. Как пример покажем результаты теста DTM пропускной способности TCP напрямую из пода в под с несколькими потоками (8), а любознательных читателей приглашаем самостоятельно изучить «сырые» данные в полном объеме в репозитории Git. Все данные и дашборды общедоступны, публикуются с открытым исходным кодом. Необходимо только установить в компьютере Docker и Docker-compose, выделив для этого минимум 10 Гб свободного места.
Доступ к данным получаем, следуя этим инструкциям:
# Чтобы получить все ~8 Гб данных тестирования, клонируем репозиторий
git clone https://github.com/InfraBuilder/benchmark-k8s-cni-2024-01.git
cd benchmark-k8s-cni-2024-01
# запускаем стек «docker-compose» и импортируем данные в «victoria metrics»
# затем открываем пользовательский интерфейс «grafana» в дашборде по умолчанию
make results
А дальше изучаем данные в этих дашбордах:
- Сводка по всем CNI.
- Параллельное сравнение.
На основе этих ресурсов формируется исчерпывающее представление о производительности различных CNI, проводятся детальный анализ и сравнения.
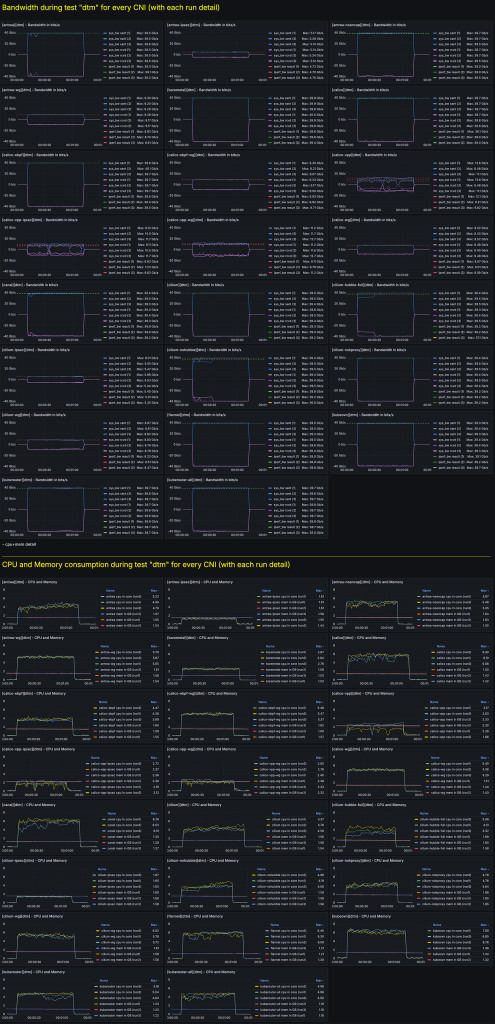
2.2) Пример «сырых» данных для теста DTM, то есть Direct TCP Multistream
Вот скриншот дашборда с «сырыми» данными для каждого CNI:
2.3) Извлечение информации из «сырых» данных
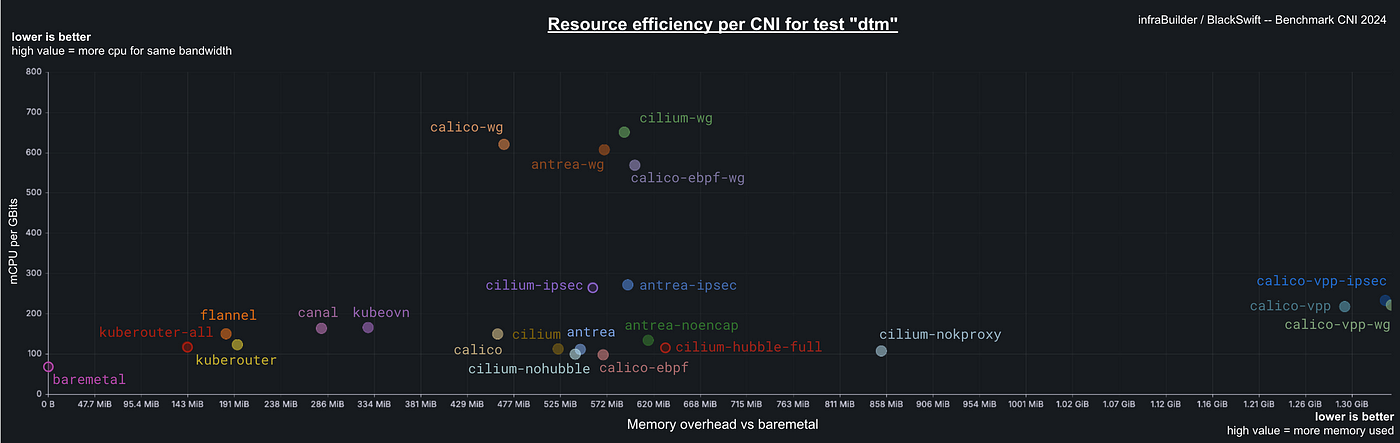
Изучение данных тестирования начали со сравнения абсолютных значений каждого показателя: пропускной способности, использования процессора, расхода памяти и других. Как ни странно, в CNI с реализованным шифрованием часто расходуется меньше ресурсов процессора, чем в CNI без шифрования и операционной системы. Но это объясняется не отсутствием необходимости в аппаратной разгрузке шифрования. В шифрованных CNI значительно ниже производительность и пропускная способность, соответственно, для управления меньшим потоком данных требуется меньшая загрузка процессора. Проиллюстрируем расход ресурсов ЦП в зависимости от пропускной способности показателем эффективности процессора, определяемым как объем используемых ресурсов ЦП, то есть mCPU, деленный на достигнутую пропускную способность в Гбит/с. Так получается представление об эффективности CNI относительно показателя его производительности.
Что касается расхода памяти, объем потребляемой CNI оперативной памяти не коррелирует с его пропускной способностью. Кривые расходования памяти при разных нагрузках были плавными, а значит, корректировать этот показатель в зависимости от пропускной способности, как это делалось с процессором, не нужно. Вместо этого рассчитывались накладные расходы CNI на потребление памяти по сравнению с CNI без операционной системы, благодаря чему точнее сравнивалось влияние на системные ресурсы.
Вот пример отображения на графике эффективности расходования ресурсов в CNI, на оси x показаны накладные расходы CNI на потребление памяти по отношению к CNI без операционной системы, на оси y — эффективность процессора. Чем ближе к началу координат, тем CNI «легче» и эффективнее. И наоборот, чем значения выше, тем больше расход памяти или ресурсов ЦП при эквивалентной пропускной способности:
2.4) Меньше разговоров, больше результатов
2.4.1) [dts] Пропускная способность TCP напрямую из пода в под с одним потоком:
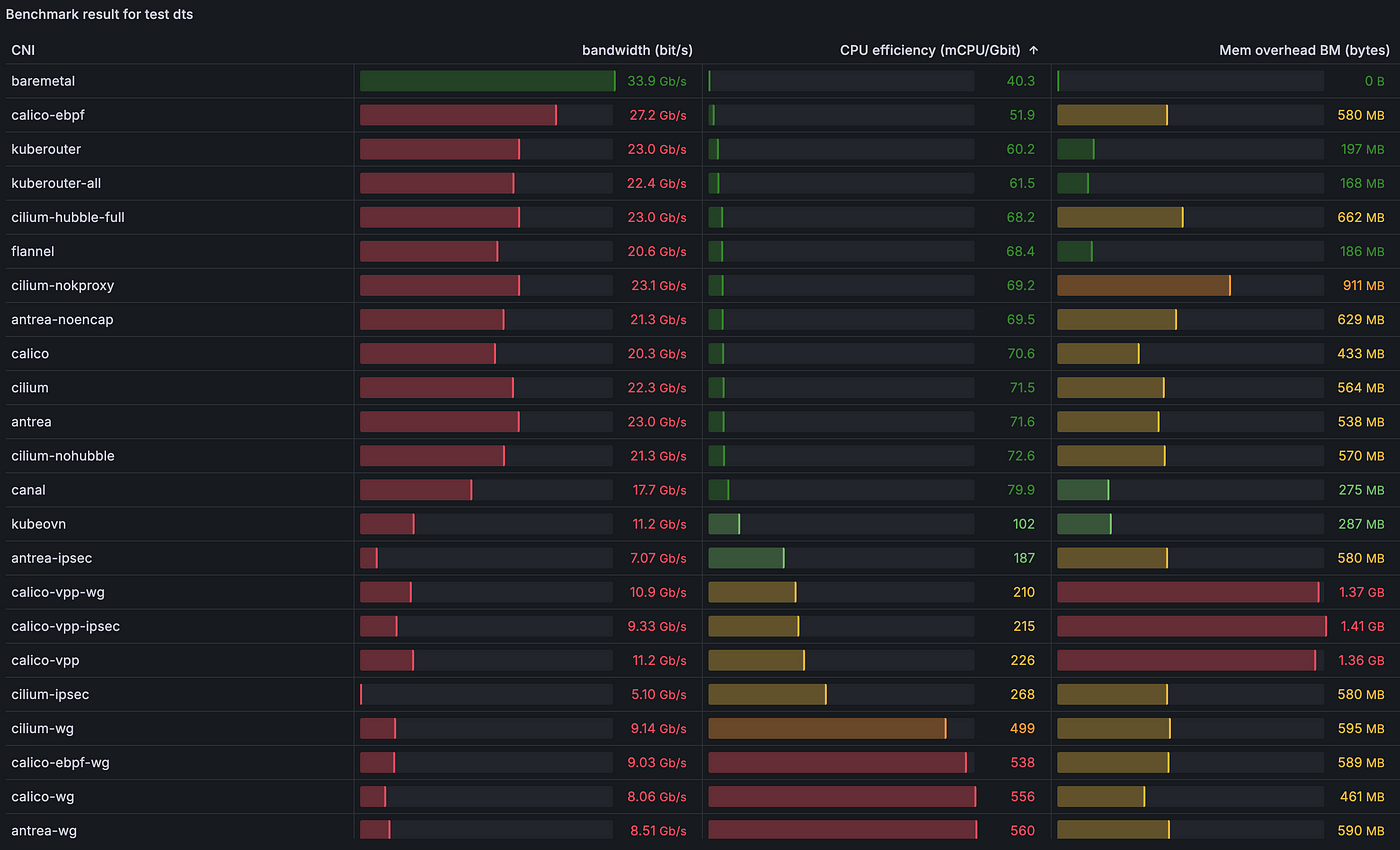
2.4.2) [dtm] Пропускная способность TCP напрямую из пода в под с несколькими потоками (8):
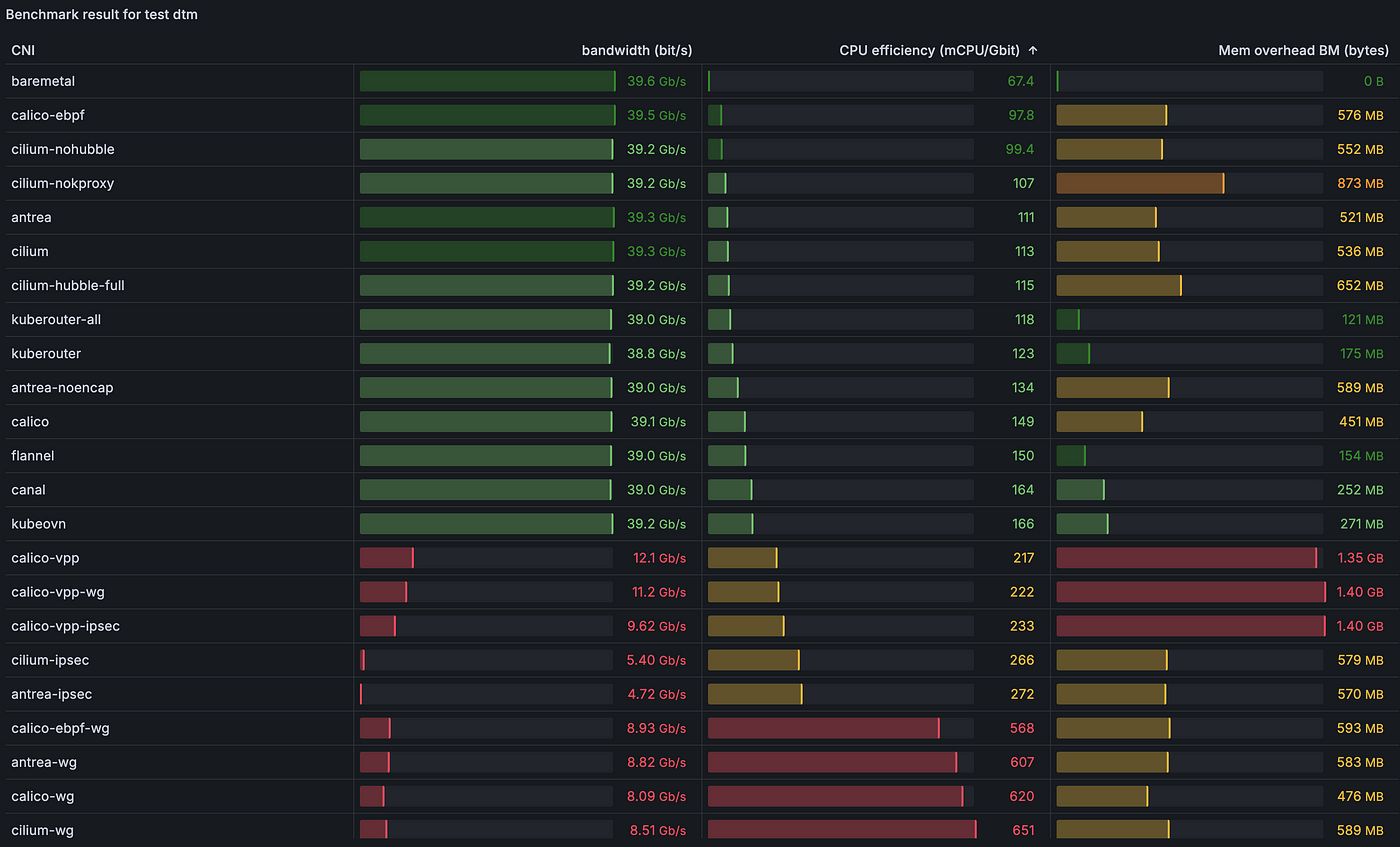
2.4.3) [dus] Пропускная способность UDP напрямую из пода в под с одним потоком:
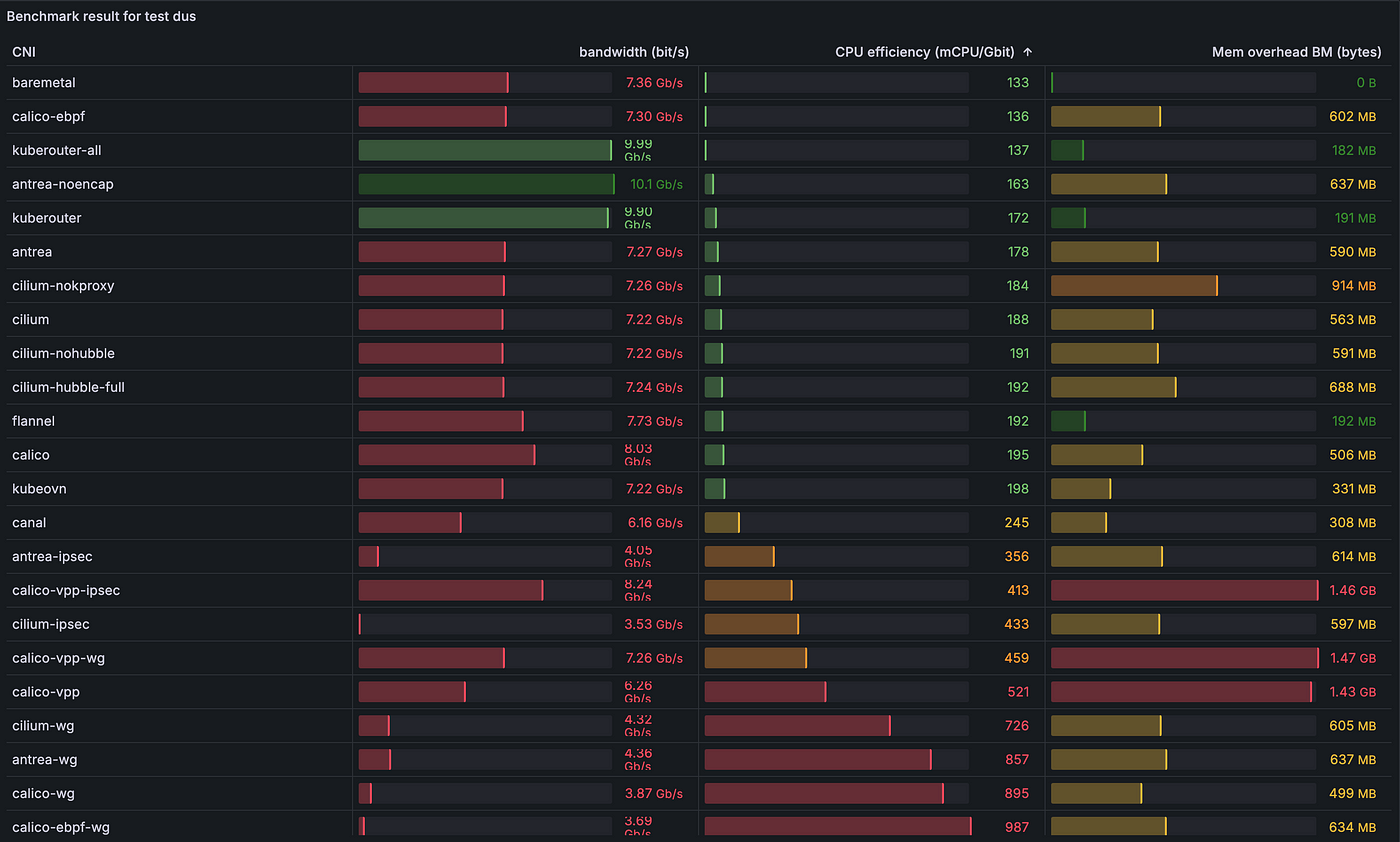
kube-router и antrea неожиданно справились лучше, чем CNI без операционной системы, подробнее — в пункте 3.1).
2.4.4) [dum] Пропускная способность UDP напрямую из пода в под с несколькими потоками (8):
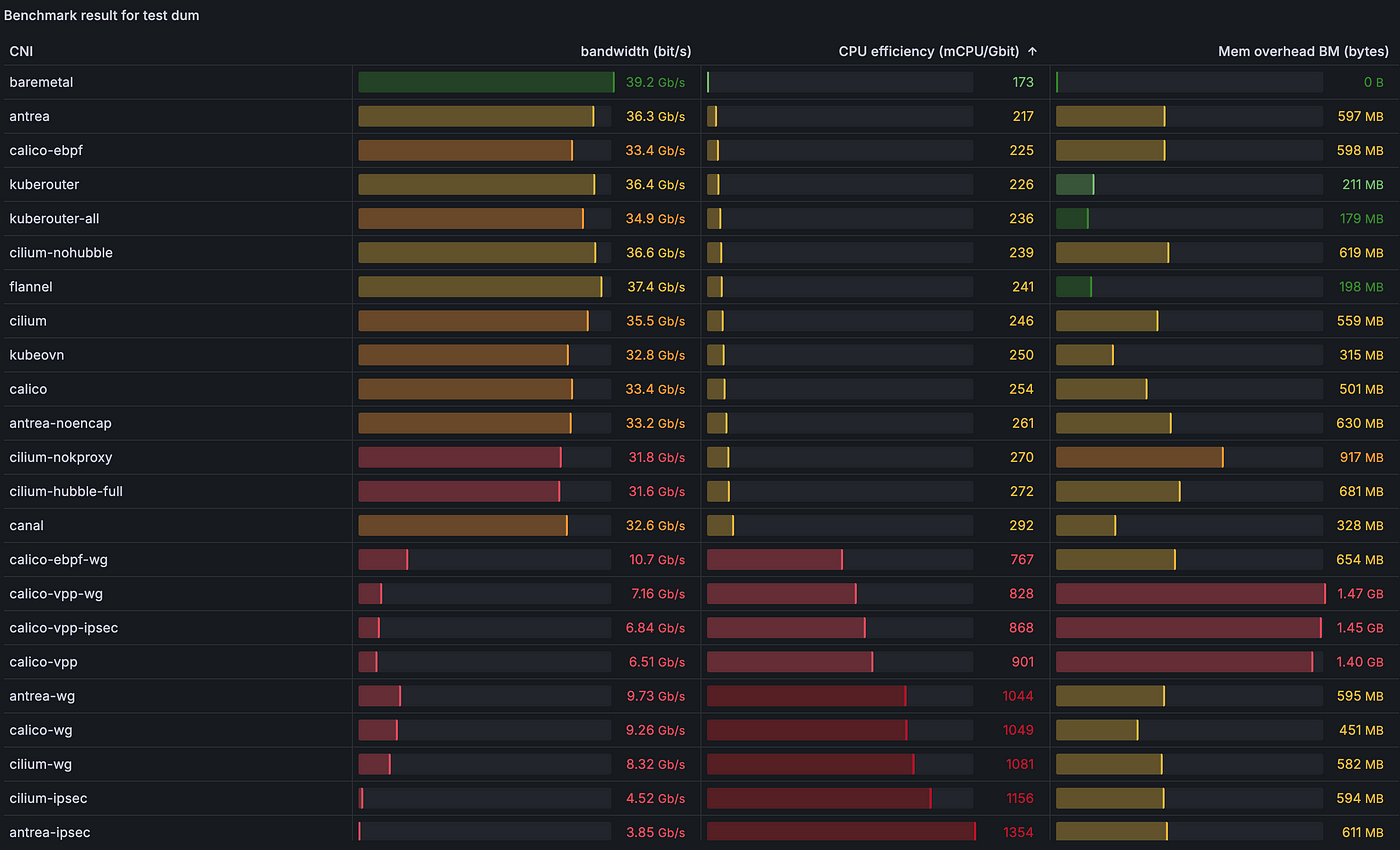
2.4.5) [sts] Пропускная способность TCP из пода в Service с одним потоком:
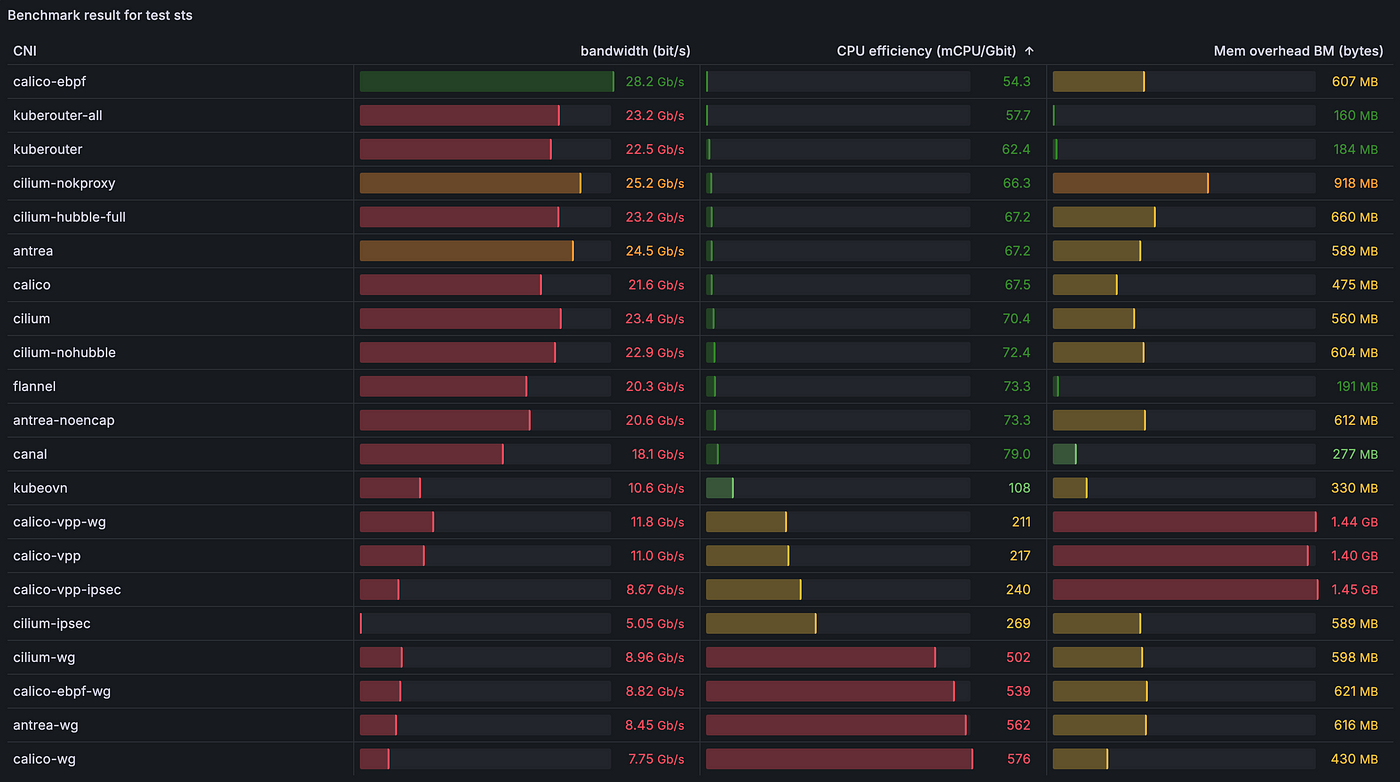
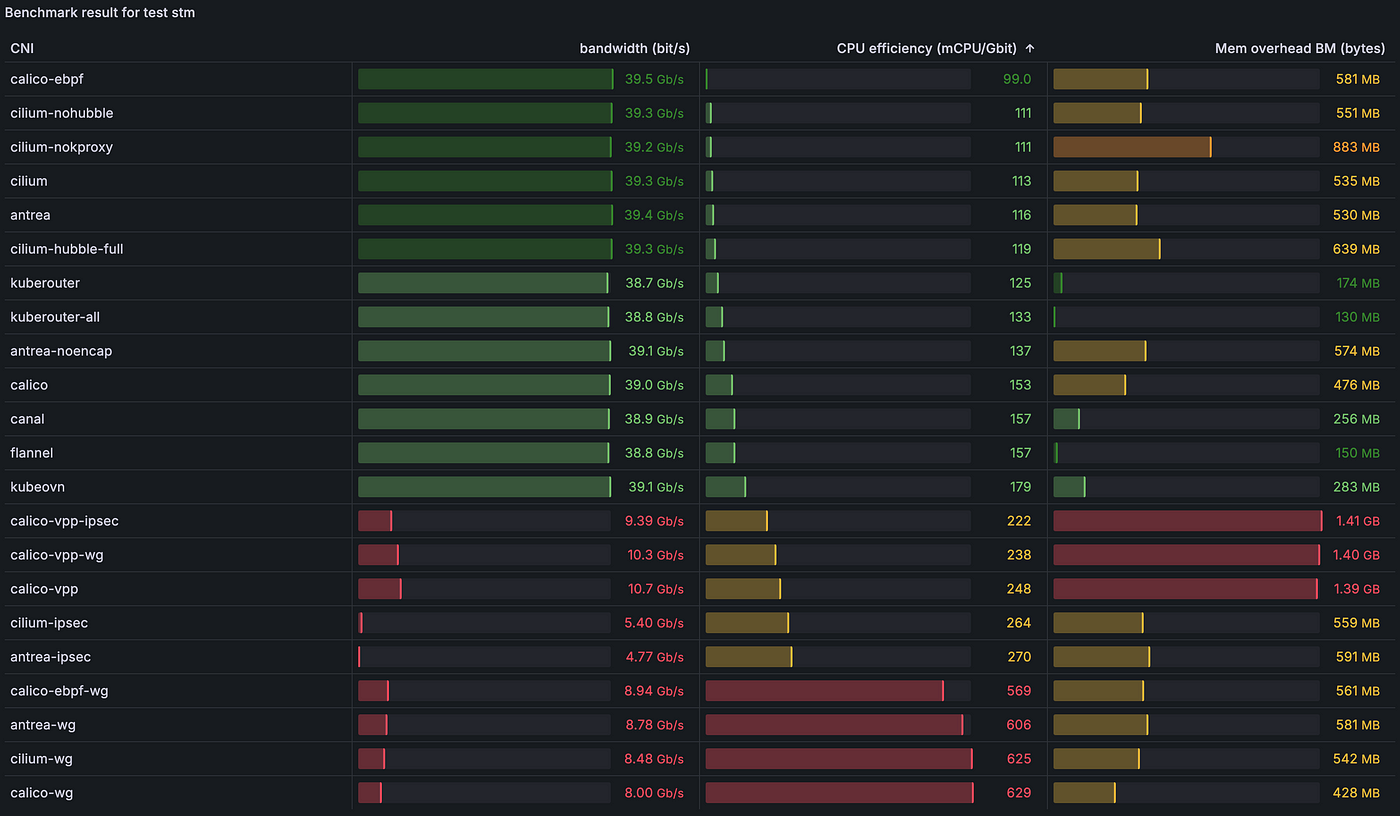
2.4.6) [stm] Пропускная способность TCP из пода в Service с несколькими потоками (8):
2.4.7) [sus] Пропускная способность UDP из пода в Service с одним потоком:
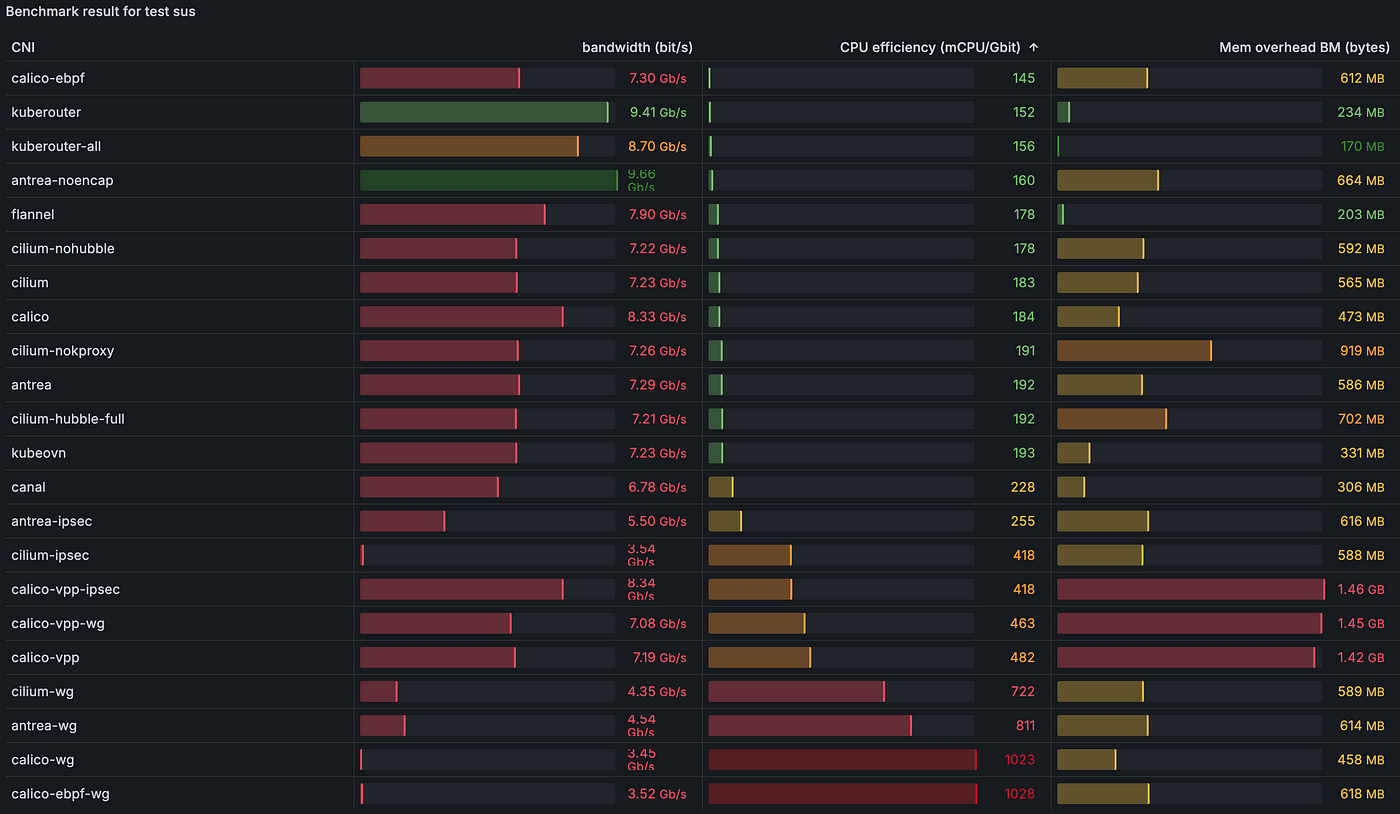
kube-router и antrea снова неожиданно справились лучше, чем CNI без операционной системы, подробнее — в пункте 3.1).
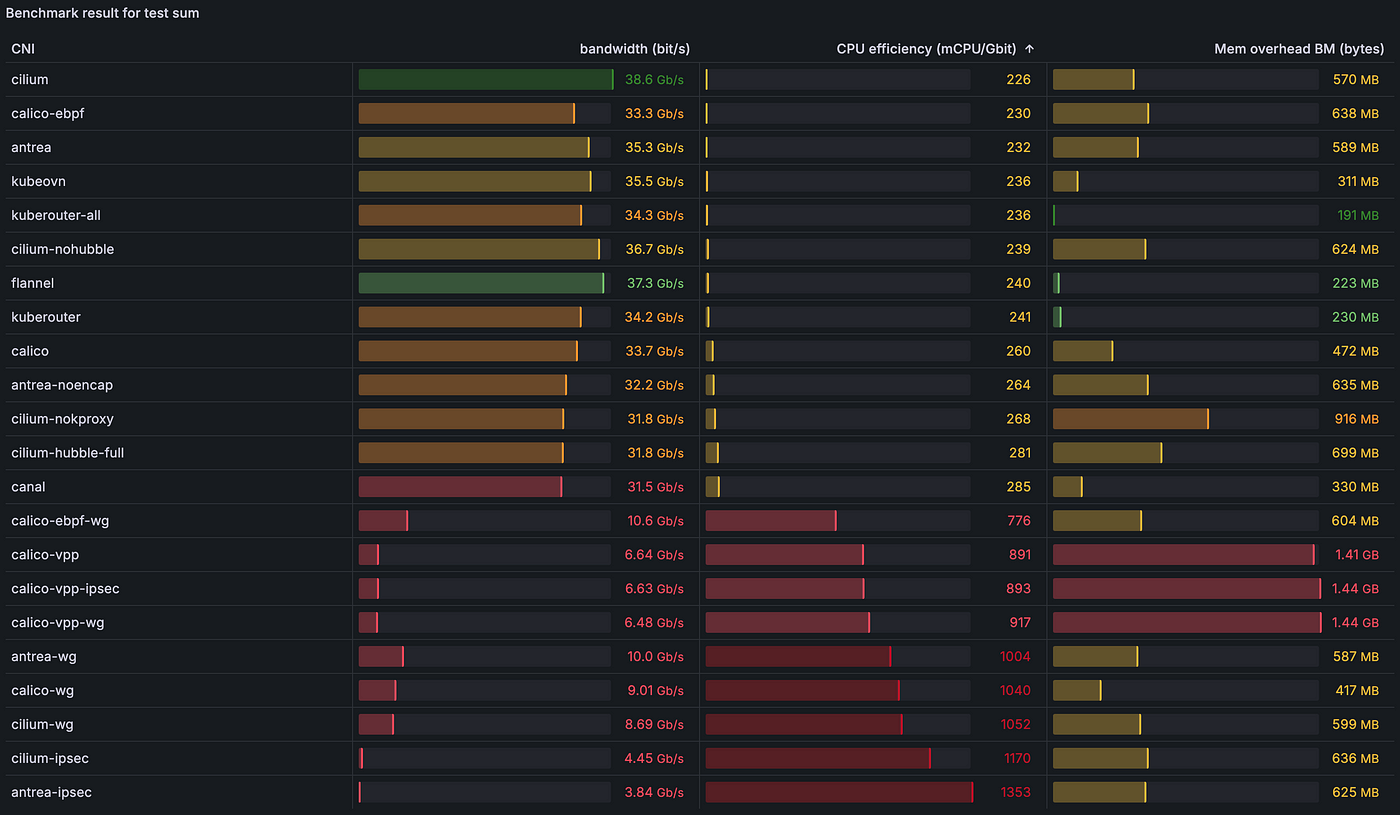
2.4.8) [sum] Пропускная способность UDP из пода в Service с несколькими потоками (8):
3) Интерпретация
Внимание: в этом разделе изложена субъективная интерпретация результатов, рекомендуем самостоятельно изучить необработанные результаты из раздела 2.1) и сделать собственные выводы.
3.1) Надежность тестов
Надежность однопоточных тестов вроде dts direct TCP single stream, dus direct UDP single stream, sts service-to-pod TCP single stream и sus service-to-pod UDP single stream несколько снижена. Производительность однопоточного iperf3 сильно зависит от того, насколько удачно он распределен по соответствующим узлам NUMA, аналогично сетевым драйверам. А вот результаты тестов dtm direct TCP multiple streams, dum direct UDP multiple streams, stm service-to-pod TCP multiple streams и sum service-to-pod UDP multiple streams надежнее благодаря применению восьми процессов, отчего повышается вероятность оптимального распределения ядер процессора, подробнее — в пункте 3.1).
3.2) Глобальная производительность
В ходе всестороннего сравнительного анализа стало очевидно, что общая производительность сетевых интерфейсов контейнеров CNI достигла уровня, при котором различия в показателях необработанных результатов для тестов производительности разных реализаций минимальны. Столь высокий уровень эффективности в целом — признак того, что производительность сама по себе сейчас уже не является важным отличительным фактором при выборе CNI.
3.3) Влияние eBPF
С eBPF производительность в многопоточных сценариях TCP чуть выше. В них точнее отражается большинство реальных рабочих нагрузок, характеризуемых одновременной обработкой многочисленными контейнерами трафика между процессами и ядрами.
Тестирование проводилось с единственной рабочей нагрузкой. Если увеличить количество этих нагрузок и сервисов в кластере, преимуществ eBPF будет больше.
3.4) Стремление к эффективности, путь к экологически безопасным вычислениям?
В многопоточных тестах TCP у всех CNI обнаружились высокая производительность и надежность.
Но резервы повышения эффективности остаются, особенно относительно расходования ресурсов на единицу пропускной способности. Поскольку важность «зеленых» информационных технологий и декарбонизированных дата-центров все увеличивается, повышение эффективности сказывается не только на экологической безопасности, но и на снижении потребности в серверах и энергопотреблении в целом.
Вот кластеризация CNI на основе их эффективности:

3.5) Недостаток UDP и опасения по поводу HTTPv3
Производительность UDP в целом была нерадужной. В соответствующих сценариях обычно обнаруживались меньшая пропускная способность и более вариативные результаты. Основная причина — отсутствие аппаратной разгрузки для UDP на уровне карты сетевого интерфейса, в отличие от TCP. Это чревато серьезными опасениями по поводу внедрения HTTP/3, то есть HTTP поверх QUIC, протокола на основе UDP. По мере того как HTTP/3 становится популярным, распространяясь и на ingress-контроллеры, это оборачивается большими проблемами производительности и надежности, особенно учитывая резкое снижение UDP при высоких значениях пропускной способности.
3.6) Пример Calico VPP
В ходе тестирования производительность Calico VPP оказалась ниже ожидаемой. Этот недостаток главным образом обусловлен необходимостью тщательной настройки программных и аппаратных конфигураций, которой не проводилось. Векторный пакетный процессор Calico VPP — высокопроизводительная плоскость данных пользовательского пространства, которая практически исключена из тестирования из-за сложности настройки. Недавно процесс установки значительно упростили, но одного этого недостаточно для полноценного использования возможностей имеющегося оборудования. Планируете развертывать Calico VPP? Тогда для достижения оптимальных результатов проконсультируйтесь непосредственно с командами его разработки.
3.7) Выбор правильного протокола сетевого шифрования
Согласно результатам тестирования, WireGuard эффективнее IPSec, его производительность выше. Но в IPSec ключи шифрования легко ротируются — например, в решениях вроде Cilium, — а в WireGuard этот функционал не поддерживается. Поэтому, выбирая между этими протоколами, следует руководствоваться конкретными политиками безопасности и требованиями производительности. Если для стратегии безопасности важна ротация ключей, IPSec предпочтительнее, несмотря на небольшое отставание в производительности.
4) Заключение, или какой CNI выбрать?
Внимание: здесь изложены рекомендации сугубо субъективного характера. Эти предложения — скорее дружеский совет, чем истина в последней инстанции.
- Для кластеров с низким потреблением ресурсов, например в пограничных средах, рекомендуем Kube-router. Очень легкий, эффективный, хорош во всех протестированных сценариях, со встроенной поддержкой сетевых политик и разнообразных архитектур: amd64, arm64, riscv64 и т. д. — для периферийных вычислений самое то. Kube-router — аналог Flannel, но с сетевыми политиками, или Canal, но эффективнее. Несмотря на отсутствие многих продвинутых функций, его философией проектирования подчеркиваются «простота эксплуатации и высокая производительность». Одна из проблем — необходимость расширения команды сопровождения, хотя нынешняя довольно реактивна. Если для вас это критично, воспользуйтесь альтернативами — Flannel или Canal.
- Для стандартных кластеров предпочтителен Cilium, на втором-третьем местах — Calico и Antrea. Сейчас всеми CNI обеспечивается приемлемая производительность, они эффективно справляются с обнаружением MTU, так что производительность сама по себе не является первоочереднным фактором принятия решений. Рекомендуем обратить внимание на CNI с ценным функционалом: интерфейсом командной строки для устранения неполадок и настройки, заменой kube-proxy на основе eBPF, инструментами наблюдаемости, исчерпывающей документацией и политиками 7-го уровня. В последнее время полнофункциональной Open Source версией с сильно уменьшенным объемом требуемых ресурсов отличился Cilium. В Open Source версии Calico, несмотря на надежность, нет определенного функционала — он доступен только в корпоративной версии Tigera. Стоит обратить внимание и на быстро развивающийся Antrea, где много интересного функционала.
- Для кластеров с тонкой настройкой, если требуется высокооптимизированный CNI, вы сможете выбрать его самостоятельно. Исходя из наших результатов и обсуждений с командами сопровождения CNI на мероприятиях вроде KubeCon, интересный вариант — Calico VPP. Остается тонко настроить аппаратную часть — карты сетевого интерфейса, «сетевую фабрику», материнские платы, процессоры и т. д. — и программную — операционные системы, драйверы и т. п. Сотрудничая с командой Calico VPP, можно создать высокопроизводительную сеть для эффективного управления значительными объемами зашифрованного трафика. Вот как в Intel протестировали способность VPP обрабатывать 100 Гбит/с. Опять же, не у всех имеется такая тонко настроенная система с достаточно большими серверами для узлов с двумя процессорами Intel® Xeon® Platinum 8480C на 56 ядер, 112 потоков, расчетной величиной теплоотвода TDP 350 Вт на процессор, фабрикой свыше 100 Гбит/с.
Это был общий обзор CNI с различными вариантами применения и требованиями. Окончательный выбор делается под конкретные задачи и технические возможности среды.
Вот репозиторий.
Читайте также:
- Как написать оператор Kubernetes?
- Шаблон Sidecar-контейнера с Kubernetes и Go
- Плавный переход: миграция кластера Kafka в Kubernetes
Читайте нас в Telegram, VK и Дзен
Перевод статьи Alexis Ducastel: Benchmark results of Kubernetes network plugins (CNI) over 40Gbit/s network [2024]





