
По моему мнению, те, кто занимается визуальным программированием, имели бы больше шансов на успех, если бы начали с аспектов программного обеспечения, которые разработчики уже визуализируют.
Контекст
Каждые несколько месяцев кто-то выпускает очень хороший визуальный язык программирования, который выглядит примерно так:
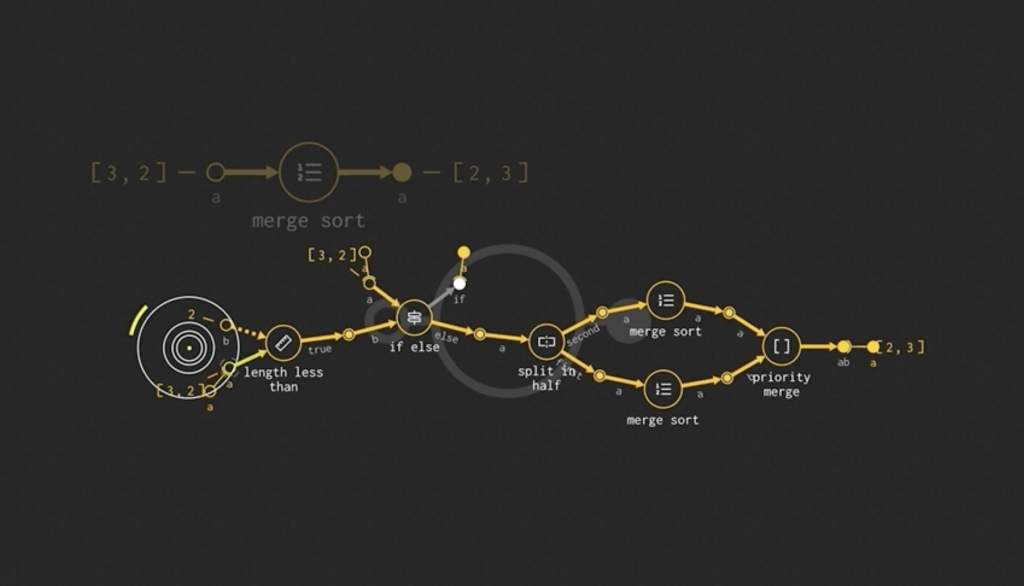
Этот выглядит особенно элегантно, большинство этих языков гораздо менее привлекательны.
Приведенный выше алгоритм заменяет псевдокод, который выглядит так1:
def merge_sort(a):
if (length(a) == 2):
if (a[0] < a[1])
return a
else
return [a[1], a[0]]
else:
[x1, x2] = split_in_half(a)
sorted_x1 = merge_sort(x1)
sorted_x2 = merge_sort(x2)
return priority_merge(sorted_x1, sorted_x2)Как и в приведенном выше примере, системы, о которых я говорю, пытаются заменить сам синтаксис кода.
Но каждый раз, когда появляется одна из этих систем визуального программирования, мы думаем: «О, здорово!» и никогда не пробуем их. Я не видел никогда, чтобы при попытке решения задач какая-нибудь из этих систем визуального программирования даже упоминалась. Почему? Почему мы продолжаем возвращаться к визуальному программированию, если его никто никогда не использует?
Одна из причин заключается вот в чем: мы думаем, что другим, менее опытным программистам с визуальным программированием будет легче. Если бы только код не был таким страшным! Если бы было визуально! Формула Excel — самый популярный язык программирования, на несколько порядков популярнее, и она может выглядеть так:
=INDEX(A1:A4,SMALL(IF(Active[A1:A4]=E$1,ROW(A1:A4)-1),ROW(1:1)),2)Эту причину я проигнорирую, ведь многие из этих инструментов явно предназначены для опытных разработчиков. Они предполагают, что вы установите их с помощью npm install или развернете код в AWS Lambdas.
Почему визуальное программирование не применяется разработчиками?
Разработчики говорят, что им нужно «визуальное программирование». Это заставляет задуматься: «Давайте заменим if и for». Но никто никогда не составлял блок-схему для чтения for (i in 0..10), if even?(i) print(i). Знакомые с кодом разработчики уже любят и понимают текстовые представления для чтения и написания бизнес-логики2.
Посмотрим на то, что делают разработчики, а не на то, что они говорят.
Разработчики тратят время на визуализацию аспектов своего кода, но редко на саму логику. Они визуализируют другие аспекты своего ПО: важные, неявные и трудные для понимания.
Вот некоторые визуализации, с которыми я часто сталкиваюсь в серьезных ситуациях:
- Различные способы визуализации кодовой базы вообще.
- Диаграммы, показывающие, как компьютеры соединены в сеть.
- Диаграммы, показывающие, как данные располагаются в памяти.
- Диаграммы переходов конечных автоматов.
- Волновые диаграммы для протоколов запросов/ответов.
Это — то, о чем просят разработчики визуального программирования. Разработчикам нужна помощь в решении этих проблем, и ради их решения разработчики прибегают к средствам визуализации.
Если вы скептически относитесь к необходимости в них, позвольте спросить: знаете ли вы, как именно ваши данные располагаются в памяти? Плохое расположение памяти — одна из основных причин низкой производительности. Однако очень сложно «увидеть», как расположен конкретный фрагмент данных, и сопоставить его с шаблонами доступа, присутствующими в кодовой базе.
Другой пример: известны ли вам все внешние зависимости, с которыми при ответе на данный HTTP-запрос сталкивается ваш код? Вы уверены? Разве вы не заметили, что кто-то только что добавил в промежуточном ПО вызов сервиса ограничения скорости? Не волнуйтесь, вы узнаете об этом на следующем падении.
На оба вопроса обычно отвечают: «Думаю, я знаю ответ?» и наползает страх, что возможно, вы что-нибудь не увидели и пропустили.
К сожалению, большинство из этих визуализаций:
- сделаны специально кем-то, кто изворачивался изо всех сил, чтобы сделать их;
- сделаны вручную, на салфетке или эксцентричны;
- редко интегрируются в стандартный рабочий процесс.
Это не означает, что в нашей отрасли нечего показать. Некоторые методы визуализации интегрированы в среды разработки и широко используются:
- Представление инспектора элементов DOM.
- Flame-графики в профайлерах.
- Диаграммы таблиц SQL.
Но это исключения, а не подразумеваемое. И разве не прекрасно, когда можно определить проблему производительности с помощью flame-графиков? Это нам нужно и для всего остального.
Сейчас я расскажу о некоторых визуализациях в списке выше, чтобы вы смогли рассмотреть их для своей работы или даже интегрировать их в существующие среды разработки.
Визуализация кодовой базы
Этот замечательный доклад показывает множество способов визуализации различных аспектов кодовой базы. Много способов! Вот некоторые из них.
- Древовидная карта: статистический обзор файлов кодовой базы.
- Sourcetrail: браузер иерархии классов и зависимостей.
- Сохранение кода с течением времени.
Sourcetrail
Sourcetrail — это проект с открытым кодом для визуализации уже неактивных кодовых баз, написанных докладчиком в докладе выше. Здесь представлен отличный обзор о том, как этот инструмент помогает перемещаться по базе кода.
Выглядит это так:
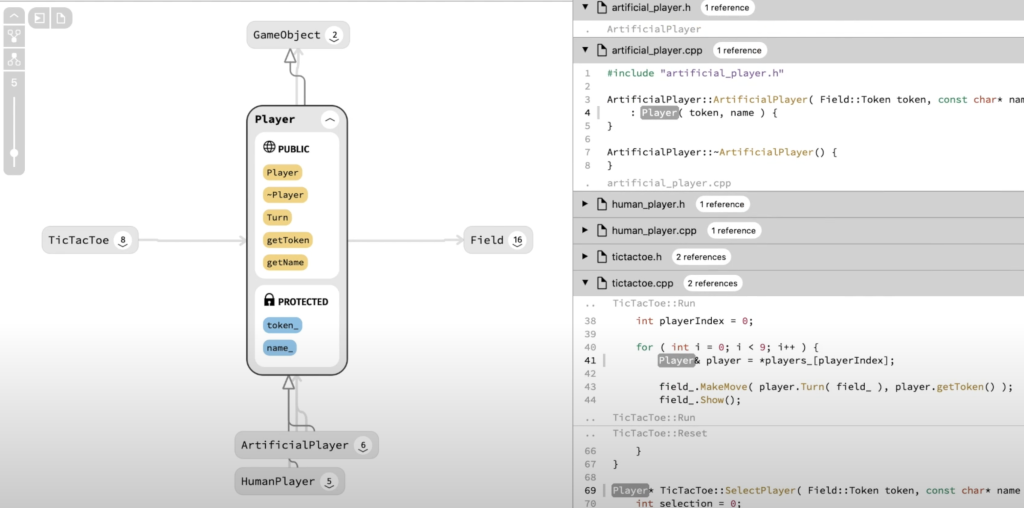
Sourcetrail решает многие распространенные проблемы дизайна в визуализации кода:
- Он показывает визуализацию рядом с кодом. Когда вы просматриваете код, он выделяет его визуальное представление. При наведении курсора на диаграмму код подсвечивается. Когда вы нажимаете на зависимость, вы переходите к коду, ответственному за эту зависимость (например, одна функция вызывает другую, один модуль требует другого модуля).
- С умом скрывает информацию. В кодовых базах часто бывает слишком много связей, чтобы их можно было визуализировать в данный момент и не перегружая пользователя. Sourcetrail показывает, что, по его мнению, вы ищете в первую очередь, а затем просит щелкнуть/навести курсор, чтобы узнать больше. Пользовательский интерфейс предназначен, чтобы задействовать треды, которые кажутся интересными, а не чтобы получить общее представление о кодовой базе. Это противоположно древовидной карте, специально предназначенной, чтобы получить общий обзор.
Но, как показывает демонстрация, Sourcetrail страдает кое-какими типичными проблемами этого типа визуализации:
- Нет очевидных зацепок на тему «когда мне это понадобится». Когда вы профилируете код, то думаете: «Мне нужен флеймграф». Когда же вам нужна эта визуализация?
- Ее нет внутри тех инструментов, которые я хочу использовать. Демо показывает, как пользователь переключается между Sourcetrail и Sublime. Этот тип визуализации кода и навигации должен жить внутри редактора кода.
Древовидная карта
В этом наборе видеородиков Джонатан Блоу реализует «деревовидную карту» для проверки различных аспектов кодовой базы. Судя по видео (я никогда не пользовался его просмотрщиком), последняя версия выглядит так:

- Каждый квадрат отражает файл кода.
- Размер каждого квадрата отражает размер файла.
- Цвет квадрата представляет собой совокупность показателей сложности в каждом файле, таких как глубина вложенности if, глубина вложенности циклов, количество глобальных операций чтения и т. д.
С помощью этого типа визуализации можно визуализировать другие метрики (size, color) кодовой базы, например (code_size, code_quality), (code_size, heap_access / code_size). и т. д.
Даже если вы визуализируете что-то простое, например code_size без цвета, это может быть очень полезно при работе с большими кодовыми базами. Типичный монолит некоторой важной технологии может выглядеть примерно так:
packages/
first_dependency/
first_transitive_dep/
second_dependency/
second_transitive_dep/
...
src/
bingo/
papaya/
lmnop/
racoon/
wingman/
galactus/
...Вы, наверное, взглянули на нее, так? Я просмотрел ее, когда присоединился к большой компании. Когда вы делаете git clone репозитория и перемещаетесь по нему, то на самом деле не узнаете, что там находится — даже общую картину. В приведенном выше примере оказывается, что большая часть кода находится в сервисе racoon/ (3 миллиона строк кода) и Second_transitive_dep/ (1 миллион строк кода). Все остальное имеет LOC менее 300 тыс. и является для сравнения ошибкой округления. Можно годами работать над этой кодовой базой, не изучая этих основных фактов.
Диаграмма долговечности кода
Работа Рича Хики «История Clojure» содержит несколько изящных визуализаций, позволяющих понять, как с течением времени развивалась кодовая база Clojure. Это тепловая карта, созданная с помощью Hercules CLI:
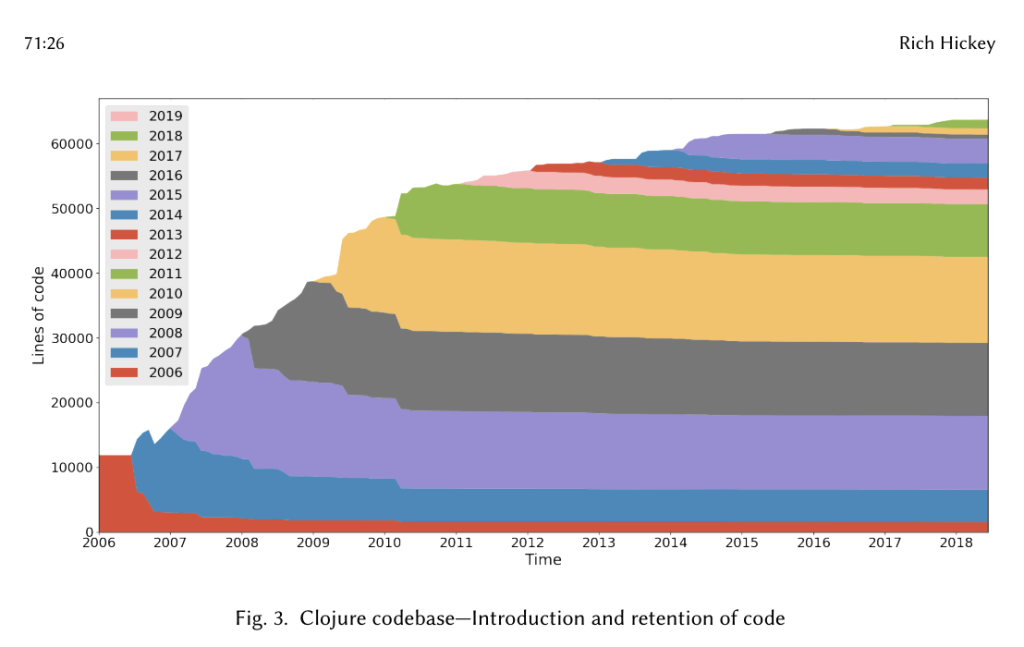
- Код, который записывался каждый год, представлен в виде области определенного цвета (например, красного в случае 2006 года).
- Поскольку в следующем году часть этого кода будет удалена/заменена, его площадь уменьшится.
- Отслеживая цвета, можно увидеть устойчивость кода, написанного в любой год. Например, код, написанный в 2006 году (красный), был по большей части удален или заменен. Но код, написанный в 2011 году (зеленый), с тех пор остался почти нетронутым. Это справедливо для большей части времени!3
Компьютерные сети и топологии сервисов
Если вы когда-нибудь использовали AWS, то увидите, что его документация полна диаграмм вроде такой:
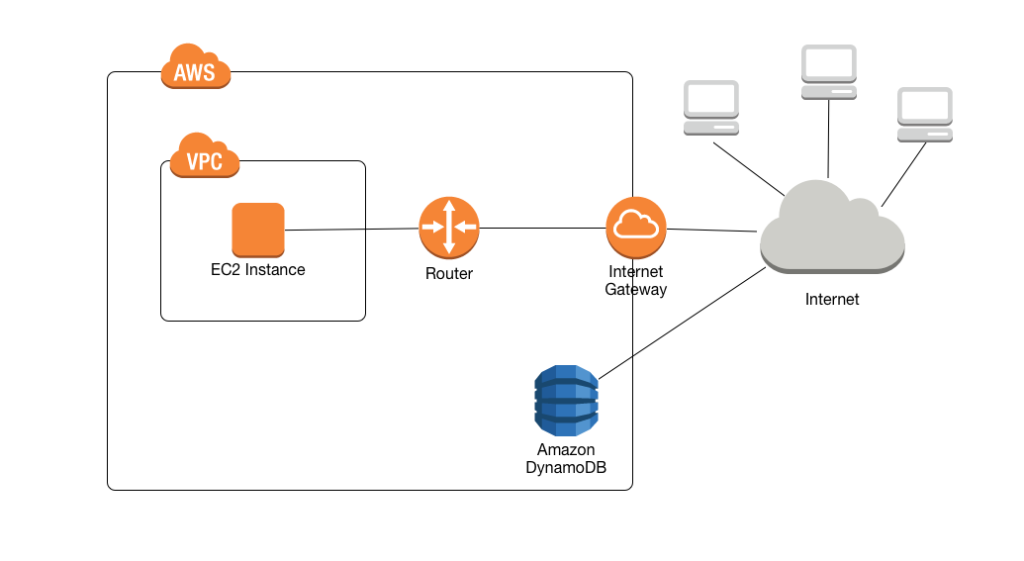
Думаю, диаграмма очень понятна. Он показывает все задействованные «сервисы» и их связи. В этом случае, если знать, что делает каждый из них, очевидно, как они связаны друг с другом. Если нет, вам придется прочитать о каждом сервисе.
На протяжении всей карьеры я составлял по одной такой топологической диаграмме для каждой своей команды. Вот несколько уроков из их подготовки:
- Когда к нам присоединились новые люди, я начинал с последней составленной мной диаграммы (в среднем 6 месяцев или около того), это облегчило задачу. Также по сравнению с прошлым разом что-то менялось.
- Каждый раз, составляя диаграмму, я упускал что-нибудь важное.
- Насколько я могу судить, это был самый важный технический артефакт, который я когда-либо передавал новым людям в команде.
Идея: если использовать определения сервисов gRPC, можно ли сгенерировать эти диаграммы на их основе?
Расположение в памяти
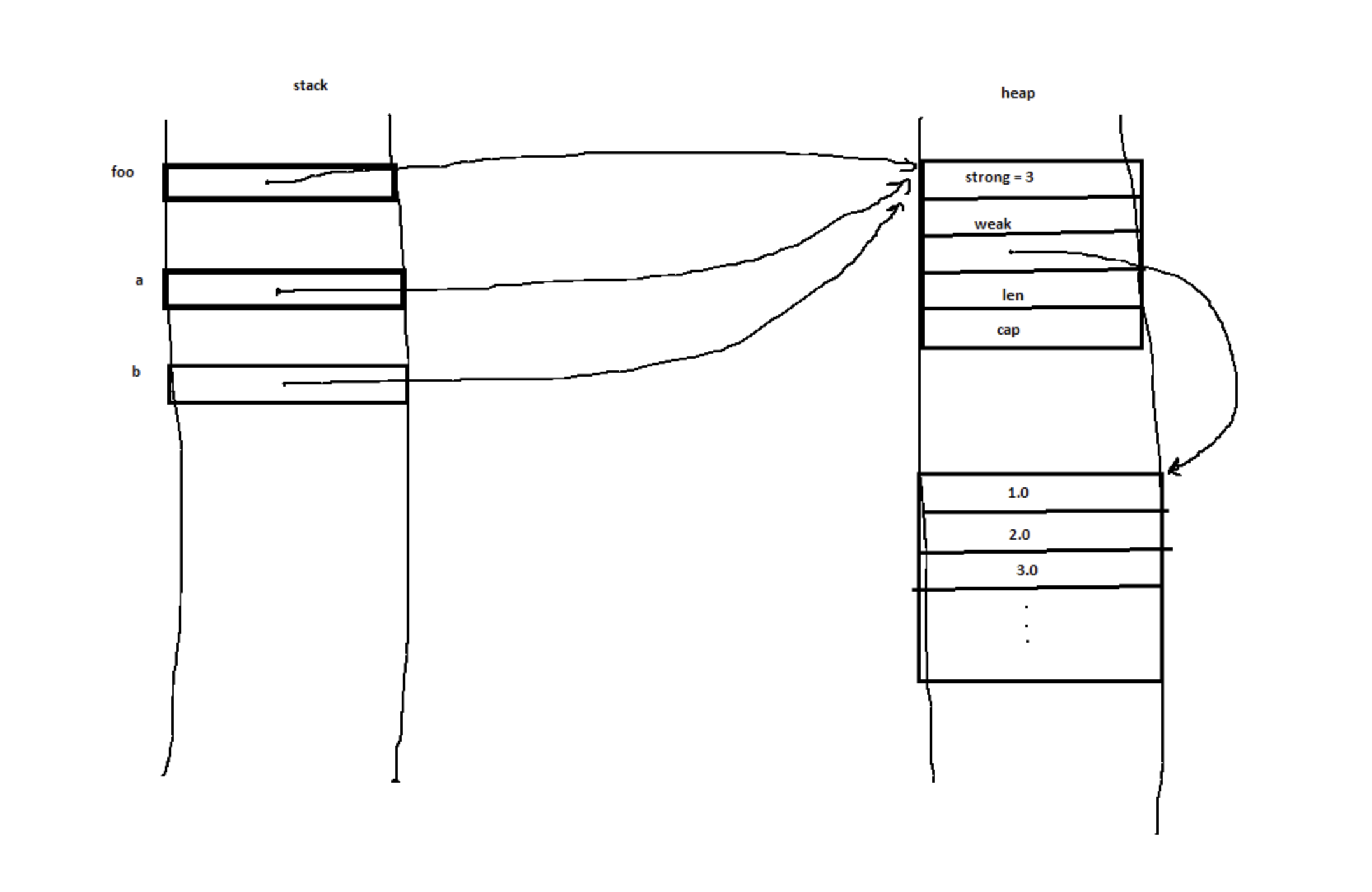
В этой теме на Reddit изображен человек, который пытается понять структуру памяти указателей Rc<T>:
Здравствуйте, я хотел бы понять структуру памяти при выполнении следующего фрагмента кода, взятого из примера стандартной библиотеки:
use std::rc::Rc;
let vec_var = vec![1.0, 2.0, 3.0];
let foo = Rc::new(vec_var);
let a = Rc::clone(&foo);
let b = Rc::clone(&foo);Я представил себе расположение памяти, как на следующем рисунке. Оно правильное? Спасибо!
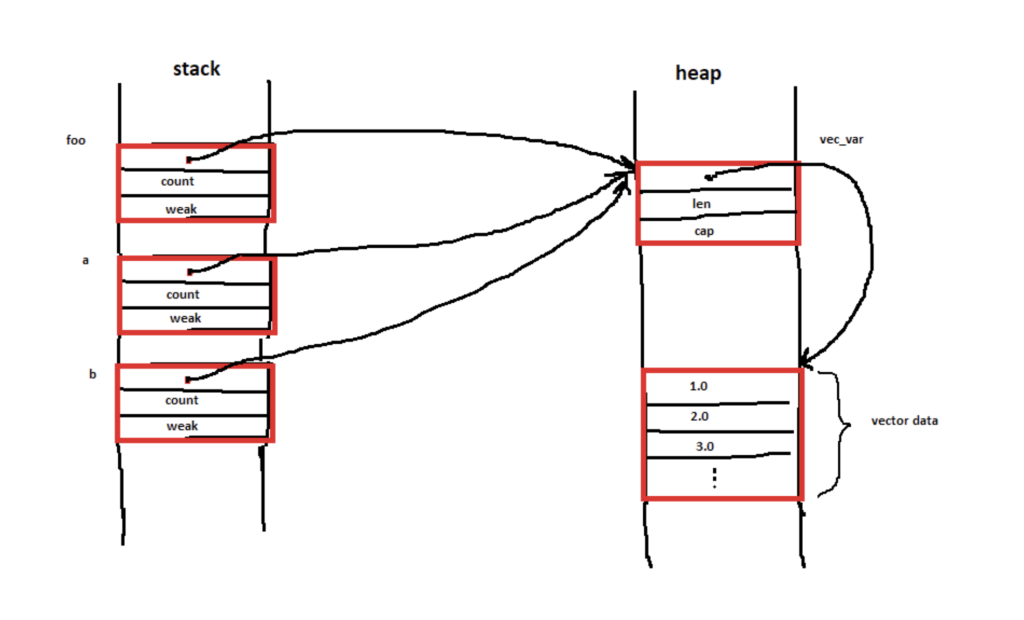
На что другой пользователь отвечает другой диаграммой:
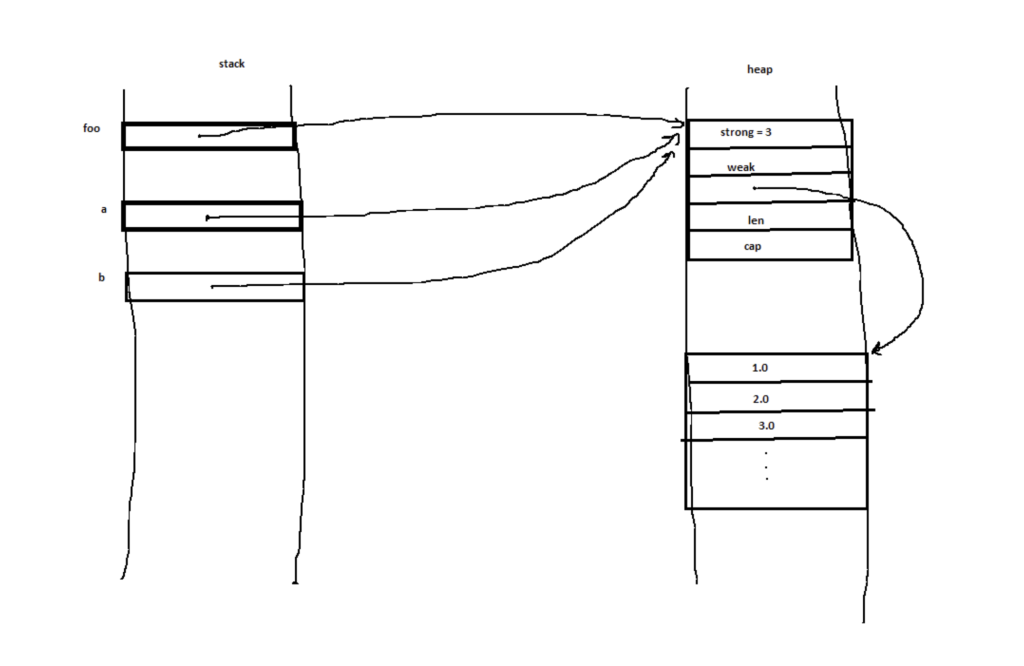
Обратите внимание, что исходный код не изменился. Единственная информация, передаваемая в ответе, — исправленная диаграмма. Это потому, что для человека, который задал вопрос, диаграмма лучше отражает его ментальную модель. Таким образом, исправленная диаграмма влияет на ментальную модель, а просмотр кода — нет.
Разговор завершается (выделение мое):
Здравствуйте и большое спасибо за вашу помощь, вы действительно пролили свет на эту проблему.
Вот почему визуальное программирование так важно: оно часто соответствует тому, что люди визуализируют в своей голове (или не визуализируют). Хорошая диаграмма проясняет мысли в головах.
Диаграммы расположения в памяти великолепно применяются в Rust Programming:
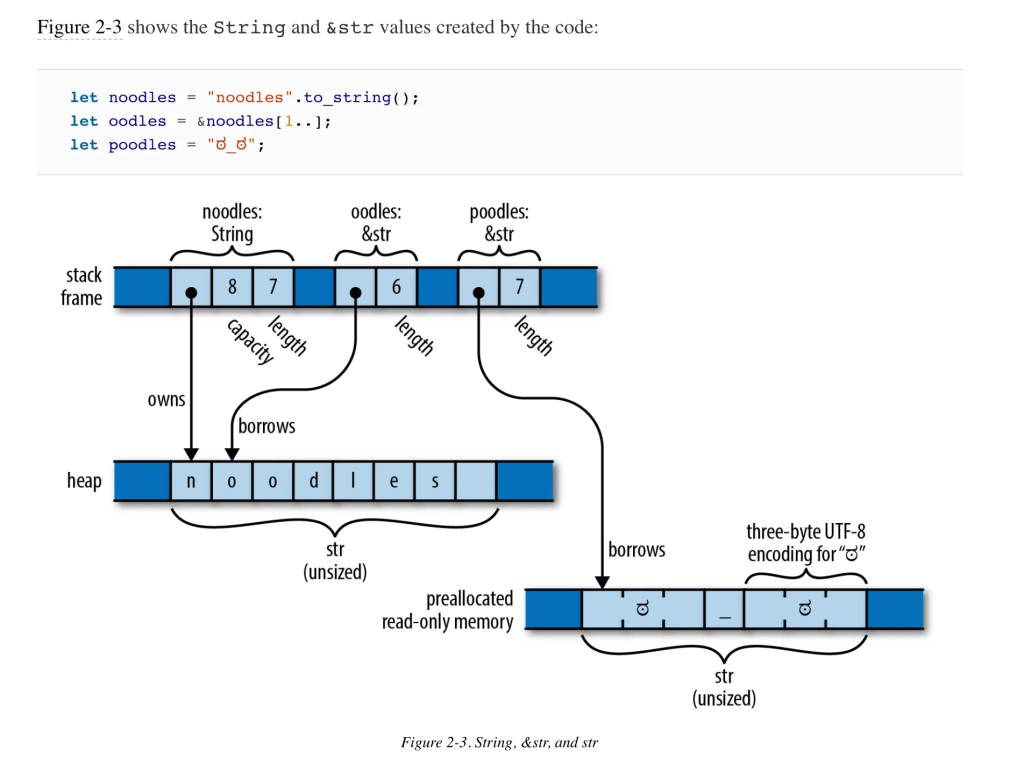
Идея: можно ли создать эти диаграммы напрямую из аннотаций типов структур?
Rust имеет другой способ «распределения памяти» — модель владения. Независимо от формы и размера данных в памяти, разные ссылки «владеют» другими ссылками, образующими дерево. Лучше, чем всеми словами, которые я только могу сказать, владение объясняется этой диаграммой в Programming Rust:
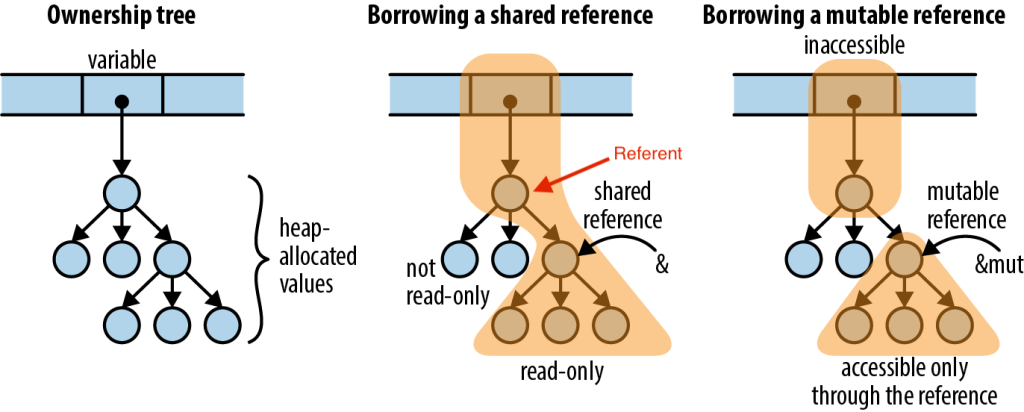
Идея: можно ли генерировать деревья владения, используя сам исходный код Rust?
Машины состояний
Они довольно стандартны. В документации Idris здесь используется одна круговая диаграмма, чтобы показать, о чем они будут говорить, прежде чем представить ряд новых концепций моделирования конечных автоматов в системе типов. Этот пример успешен на двух уровнях:
- Если вы хоть немного знакомы с диаграммами переходов состояний, чтобы понять происходящее понадобится секунда.
- Скорее всего, вы не знакомы с нотацией кода конечного автомата, поэтому иметь для него альтернативное представление действительно полезно.
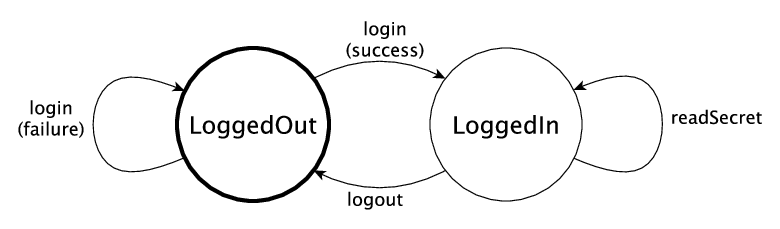
Идея: можно ли создавать эти диаграммы прямо из аннотаций типа Idris?
Вам даже не обязательно придерживаться строгих диаграмм конечных автоматов UML. Для каких состояний они используются?
Платежные намерения — это основной объект, который Stripe использует для представления текущего платежа. С платежом может случиться многое, поэтому в итоге у него получается довольно сложный конечный автомат. Эту диаграмму конечного автомата мы создали для него в 2019 году вместе с Мишель Бу и Изабель Бенсусан. В то время это была одна из первых «диаграмм» в документации.
На диаграмме показаны различные состояния, в которых может находиться PaymentIntent и соответствующий пользовательский интерфейс для каждого из них:
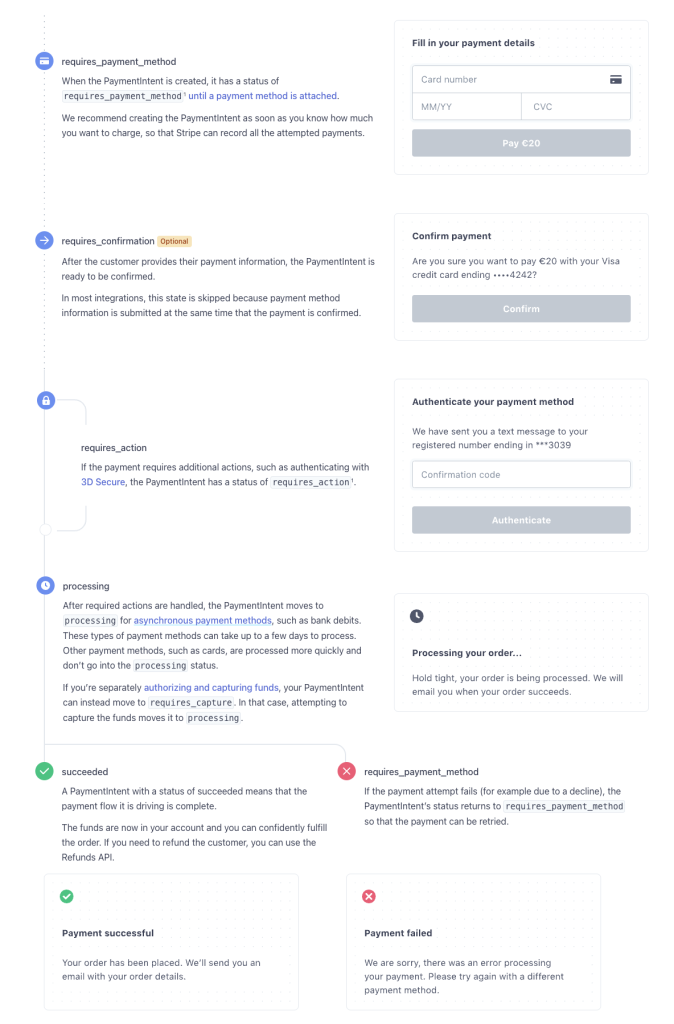
Забавный пример конечных автоматов и способов их формализации можно найти в лекции Лесли Лэмпорта о фиксации транзакций в TLA+.
Диаграммы «плавательных дорожек» (Swimlane) запроса/ответа
Архитектура запросов клиент/сервер может оказаться довольно сложной. Я часто видел, как люди строят такие диаграммы, чтобы отслеживать их.
Вот хороший пример из документации Stripe. Он показывает все запросы/ответы, которые происходят, когда клиент оформляет заказ, сохраняет свой способ оплаты и платит:
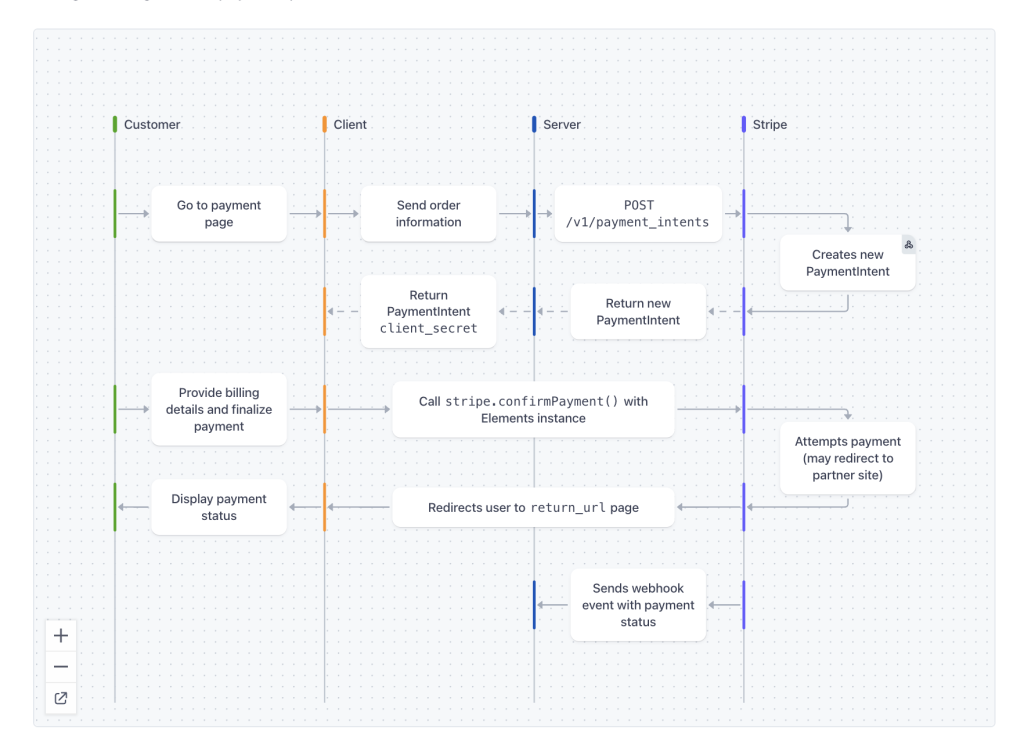
Если вы еще не видели его:
- каждый столбец обозначает, кто делает каждый запрос (компьютер или человек);
- каждый бокс — действие, которое они могут совершить;
- каждая стрелка — запрос и ответ между ними;
- когда они делают запросы — время.
Они великолепны. Вы можете увидеть порядок запросов, зависимости между ними, кто что делает и многое другое. Важно отметить, что когда вы пишете код, то видите фрагмент кода вроде такого:
const r = await stripe.confirmPayment();Вы можете найти соответствующий запрос и увидеть контекст, в котором он происходит, даже если его нет в коде, окружающем данный код.
Адриенн Дрейфус проделала большую часть работы по созданию и стандартизации этих диаграмм во всей документации Stripe.
Идея: можно ли вы создать одну из этих диаграмм прямо по сквозным тестам, которые вы написали для сервиса?
Этот пример не показывает течение времени, пока сообщения передаются. Обратите внимание, что стрелки идут горизонтально. Но вы можете использовать ту же диаграмму для диагностики состояния гонки или других ошибок, которые зависят от проблем с нарушением порядка или тайминга.
Aphyr часто использует собственную версию диаграмм дорожек, чтобы показать, как различные процессы рассматривают состояние в распределенной системе. Например, в анализе VoltDB 6.3 Jepsen показывает, как разные узлы базы данных могут отправлять сообщения друг другу:

В этой версии диаграммы решающее значение для понимания проблем с системой имеет время между запросами.
В том же сообщении также показана интерактивная диаграмма, напоминающая дорожку для плавания, для визуализации результатов от Jepsen:
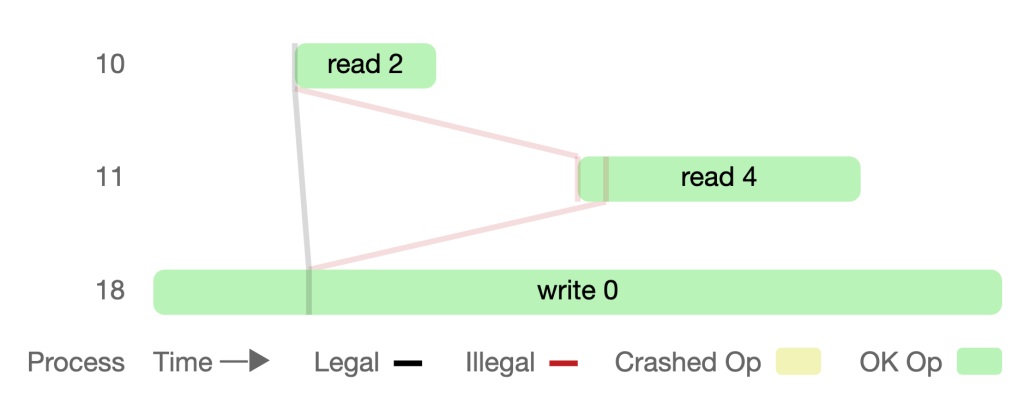
- Каждая «дорожка» теперь — это горизонтальная, пронумерованная строка (10, 11, 18), представляющая процесс, который либо читает, либо записывает данные.
- Блоки — это операции процесса и время, необходимое для их завершения. Линии представляют собой логические связи между данными, которые видят процессы. Линии, нарушающие линейность, отмечены надписью Illegal и красным цветом.
Еще один очень интересный пример можно найти в документации по алгоритму Double Rachet компании Signal. Эти диаграммы отслеживают, что нужно Алисе и Бобу на каждом этапе протокола шифрования и дешифрования следующего сообщения:
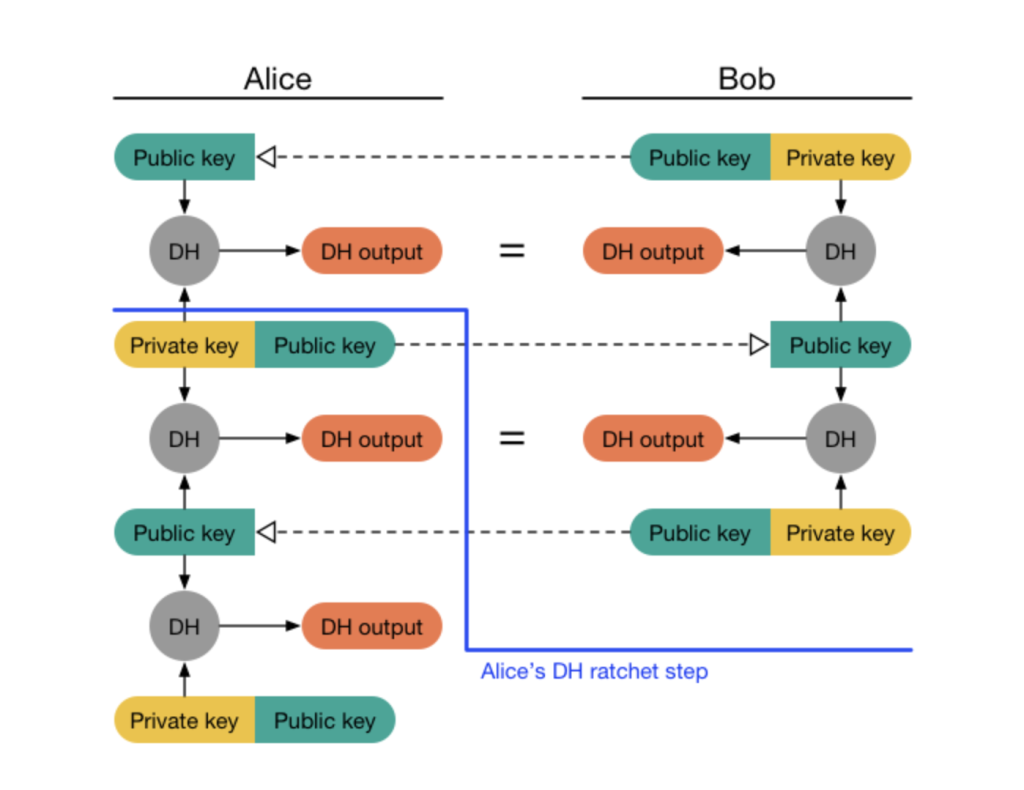
Протокол достаточно сложен, чтобы решить, что диаграммы являются источником истины о протоколе. Иначе говоря, я бы рискнул сказать, что если реализация алгоритма Double Rachet вообще делает что-то, что не соответствует диаграммам, то, скорее всего, код неправильный, а не наоборот. Думаю, что именно в этих областях средством должно быть визуальное программирование.
- Я не знаю, верен ли приведенный выше код — это то, что я смог дедуктивно вывести из диаграммы.↩
- Это стандартная критика систем визуального программирования, и, по моему мнению, толпа имеет право пренебрежительно относиться к ним. Но почему люди продолжают возвращаться к визуальному программированию? Что им нужно сделать вместо этого?↩
- Рич также сделал содержательную презентацию об истории Clojure, рассказав, почему эти Flame-графики выглядят именно так: Clojure избегает переписывания, кроме исправления ошибок, чтобы поддерживать стабильность кода.↩
Читайте также:
- Опытный программист теряет работу
- Креативное программирование: методы и инструменты для JavaScript, Python и других языков
- Преимущества обучения на программиста-дизайнера
Читайте нас в Telegram, VK и Дзен
Перевод статьи Sebastian Bensusan: We need visual programming. No, not like that





{kind=link}