
Как опытному дата-сайентисту, много лет проработавшему в сфере высоких технологий, мне пришлось обработать тонны больших данных. SQL — наиболее часто используемый инструмент для манипулирования данными, их запроса и анализа. Освоить базовый и промежуточный уровни SQL относительно легко, но достичь мастерства в работе с этим инструментом и умело использовать его в различных сценариях бывает непросто. Есть несколько продвинутых техник SQL, с которыми вы должны быть знакомы, если хотите работать в ведущих технологических компаниях. Сегодня я расскажу о самых полезных передовых техниках SQL. Чтобы помочь вам лучше понять их, приведу несколько примеров с использованием фиктивных данных и объясню, в каких сценариях и как их применять. Для каждого случая использования также будет указан программный код.
Оконные функции
Оконные функции (window functions) выполняют вычисления в определенном наборе строк, называемом «окном» («window»), из запроса и возвращают одно значение, относящееся к текущей строке.
Для рассмотрения оконных функций будем использовать данные о продажах в рамках акции в универмаге Star. Таблица содержит три столбца:
- Sale_Person_ID — идентификатор, уникальный для каждого продавца;
- Department — отдел, в котором работает продавец;
- Sales_Amount — объем продаж каждого продавца во время акции.
Руководство универмага Star хочет видеть итоговую сумму продаж по каждому отделу. Ваша задача — добавить в таблицу столбец dept_total.
Сначала создадим таблицу promo_sales с 3 столбцами в базе данных.
CREATE TABLE promo_sales(
Sale_Person_ID VARCHAR(40) PRIMARY KEY,
Department VARCHAR(40),
Sales_Amount int
);
INSERT INTO promo_sales VALUES (001, 'Cosmetics', 500);
INSERT INTO promo_sales VALUES (002, 'Cosmetics', 700);
INSERT INTO promo_sales VALUES (003, 'Fashion', 1000);
INSERT INTO promo_sales VALUES (004, 'Jewellery', 800);
INSERT INTO promo_sales VALUES (005, 'Fashion', 850);
INSERT INTO promo_sales VALUES (006, 'Kid', 500);
INSERT INTO promo_sales VALUES (007, 'Cosmetics', 900);
INSERT INTO promo_sales VALUES (008, 'Fashion', 600);
INSERT INTO promo_sales VALUES (009, 'Fashion', 1200);
INSERT INTO promo_sales VALUES (010, 'Jewellery', 900);
INSERT INTO promo_sales VALUES (011, 'Kid', 700);
INSERT INTO promo_sales VALUES (012, 'Fashion', 1500);
INSERT INTO promo_sales VALUES (013, 'Cosmetics', 850);
INSERT INTO promo_sales VALUES (014, 'Kid', 750);
INSERT INTO promo_sales VALUES (015, 'Jewellery', 950);
Теперь нужно вычислить итоговую сумму продаж для каждого отдела и добавить столбец dept_total в таблицу promo_sales. Не используя оконные функции, с помощью оператора GROUP BY мы бы создали еще одну таблицу с именем department_total, чтобы получить сумму продаж для каждого отдела. Затем объединили бы таблицы promo_sales и department_total. Оконные функции предоставляют мощный способ выполнить это вычисление в рамках одного SQL-запроса, упрощая и оптимизируя обработку данных.
Для выполнения этой задачи можно использовать функцию SUM().
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
SUM(Sales_Amount) OVER (PARTITION BY Department) AS dept_total
FROM
promo_sales;
После этого в таблице promo_sales появится один дополнительный столбец dept_total, как и ожидалось.
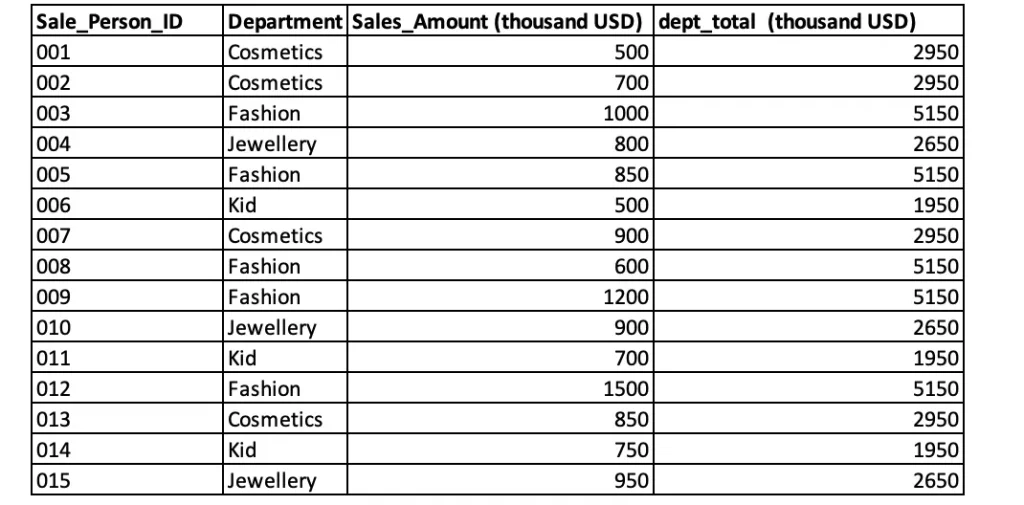
Этот пример показывает, что оконные функции не уменьшают количество строк в результирующем наборе, в отличие от агрегатных функций, используемых с GROUP BY. Оконные функции могут выполнять такие вычисления, как промежуточные итоги, средние значения и подсчеты, а также использоваться для таких операций, как ранжирование и другие. Теперь перейдем к следующему примеру.
Руководство универмага Star также хочет проранжировать продавцов по их эффективности во время акции в каждом отделе. На этот раз будем использовать RANK() для ранжирования продавцов.
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
RANK() OVER (PARTITION BY Department ORDER BY Sales_Amount DESC) AS Rank_in_Dept
FROM
promo_sales;
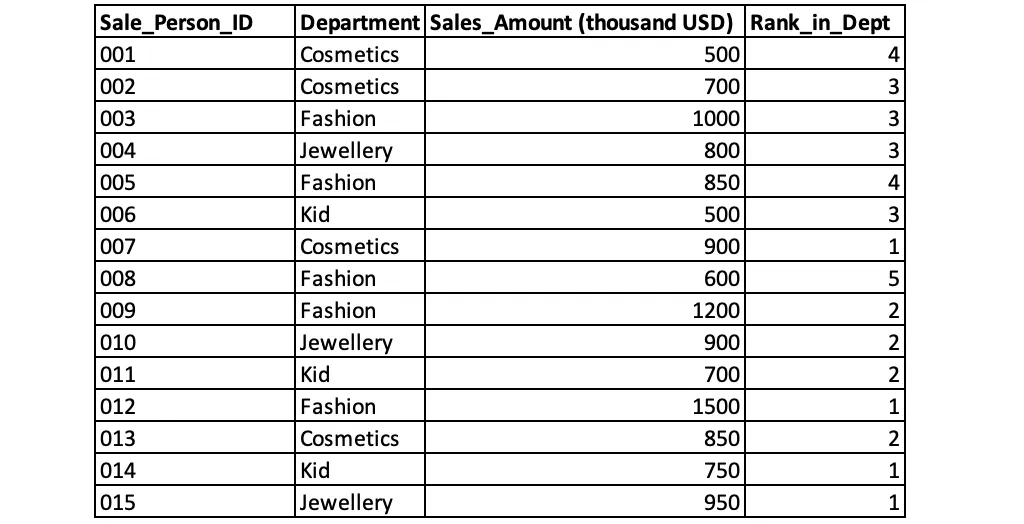
Оконные функции широко используются в анализе данных. К распространенным типам оконных функций относятся функции ранжирования, агрегатные функции, функции смещения и функции распределения.
1. Функции ранжирования: присваивают ранг или номер строки каждой строке в разделе результирующего набора.
- ROW_NUMBER(): присваивает уникальные последовательные целые числа строкам;
- RANK(): присваивает ранг с разрывом для связей;
- DENSE_RANK(): присваивает ранг без разрыва для связей;
- NTILE(n): разбивает строки на n примерно равных групп.
2. Агрегатные функции: используются для выполнения вычислений или статистических расчетов по набору строк, связанных с текущей строкой.
- SUM (): вычисляет общее значение в пределах раздела;
- AVG(): вычисляет среднее значение в разделе;
- COUNT(): получает количество элементов в разделе;
- MAX(): получает наибольшее значения в разделе;
- MIN(): получает наименьшее значение в разделе.
3. Функции смещения: позволяют получить доступ к данным из других строк по отношению к текущей строке. Они используются, когда нужно сравнить значения между строками или когда выполняется анализ временных рядов либо выявление тенденций.
- LAG(): предоставляет доступ к данным из предыдущего ряда;
- LEAD(): предоставляет доступ к данным из последующего ряда;
- FIRST_VALUE(): получает первое значение в упорядоченном наборе;
- LAST_VALUE(): получает последнее значение в упорядоченном наборе.
4. Функции распределения: выполняют вычисление относительного положения значения в группе значений, а также помогают понять распределение значений.
- PERCENT_RANK(): вычисляет перцентильный ранг строки;
- CUME_DIST(): вычисляет совокупное распределение значения;
- PERCENTILE_CONT(): вычисляет постоянное значение перцентиля;
- PERCENTILE_DISC(): вычисляет дискретное значение перцентиля.
Подзапросы
Подзапрос, также известный как вложенный запрос или внутренний запрос, — это запрос внутри другого SQL-запроса. Он может быть использован для создания нового столбца, новой таблицы или определенных условий для ограничения данных, которые будут получены из основного запроса.
Для демонстрации продолжим использовать таблицу данных promo_sales универмага Star.
1. Подзапрос для создания нового столбца
На этот раз добавляем новый столбец, чтобы показать разницу между суммой продаж каждого продавца и средним значением по отделу.
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
Sales_Amount - (SELECT AVG(Sales_Amount) OVER (PARTITION BY Department) FROM promo_sales) AS sales_diff
FROM
promo_sales;
2. Подзапрос для создания новой таблицы
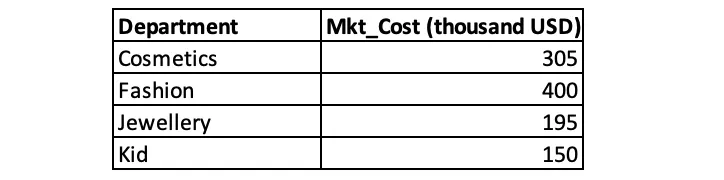
Таблица mkt_cost содержит затраты на рекламу для всех отделов во время акции. Чтобы определить, какой отдел является наиболее экономически эффективным, нужно рассчитать окупаемость рекламных расходов для каждого отдела. Можно использовать подзапрос для создания новой таблицы, содержащей общие суммы продаж и маркетинговые расходы отделов, а затем проанализировать данные в этой новой таблице.
SELECT
Department,
dept_ttl,
Mkt_Cost,
dept_ttl/Mkt_Cost AS ROAS
FROM
(SELECT
s.Department,
SUM(s.Sales_Amount) AS dept_ttl,
c.Mkt_Cost
FROM
promo_sales s
GROUP BY s.Department
LEFT JOIN
mkt_cost c
ON s.Department=c.Department
)
3. Подзапрос для создания ограничительных условий
Подзапрос можно также использовать для отбора продавцов, сумма продаж которых превысила среднюю сумму по всем продавцам.
SELECT
Sale_Person_ID,
Department,
Sales_Amount
FROM
promo_sales
WHERE
Sales_Amount > (SELECT AVG(salary) FROM promo_sales);
Помимо трех вышеперечисленных типов подзапросов, существует еще один часто используемый подзапрос — коррелированный подзапрос, значения которого зависят от внешнего запроса. Он выполняется один раз для каждой строки во внешнем запросе.
Коррелированный подзапрос можно использовать для поиска продавцов, чьи показатели продаж были выше средних по отделу во время акции.
SELECT
ps_1.Sale_Person_ID,
ps_1.Department,
ps_1.Sales_Amount
FROM
promo_sales ps_1
WHERE
ps_1.Sales_Amount > (
SELECT AVG(ps_2.Sales_Amount)
FROM promo_sales ps_2
WHERE ps_2.Department = ps_1.Department
);
Подзапросы позволяют писать сложные запросы, отвечающие на сложные вопросы о данных. Но важно применять их с умом, так как чрезмерное использование может привести к проблемам с производительностью, особенно при работе с большими наборами данных.
Общие табличные выражения
Общее табличное выражение (CTE) — это именованный временный набор результатов, который существует в рамках одного оператора SQL. CTE определяются с помощью оператора WITH и могут быть упомянуты один или несколько раз в последующих операторах SELECT, INSERT, UPDATE, DELETE или MERGE.
В SQL используеются в основном два типа CTE.
- Нерекурсивные CTE: упрощают сложные запросы путем разбиения их на более управляемые части. Они не ссылаются сами на себя, поэтому являются простейшим типом CTE.
- Рекурсивные CTE: ссылаются сами на себя в своих определениях, что позволяет работать с иерархическими или древовидными данными.
Теперь воспользуемся нерекурсивными CTE для работы с таблицей данных promo_sales. Задача состоит в том, чтобы вычислить среднюю сумму продаж по каждому отделу и сравнить ее со средней по магазину во время проведения акции.
WITH dept_avg AS (
SELECT
Department,
AVG(Sales_Amount) AS dept_avg
FROM
promo_sales
GROUP BY
Department
),
store_avg AS (
SELECT AVG(Sales_Amount) AS store_avg
FROM promo_sales
)
SELECT
d.Department,
d.dept_avg,
s.store_avg,
d.dept_avg - s.store_avg AS diff
FROM
dept_avg d
CROSS JOIN
store_avg s;
Поскольку рекурсивные CTE могут работать с иерархическими данными, попытаемся сгенерировать последовательность чисел от 1 до 10.
WITH RECURSIVE sequence_by_10(n) AS (
SELECT 1
UNION ALL
SELECT n + 1
FROM sequence_by_10
WHERE n < 10
)
SELECT n FROM sequence_by_10;
CTE очень полезны, поскольку улучшают читаемость и удобство обслуживания сложных запросов, упрощая их. Они особенно полезны при необходимости несколько раз сослаться на один и тот же подзапрос в основном запросе и при работе с рекурсивными структурами.
Заключение
Эти три продвинутые техники SQL могут значительно расширить ваши возможности по манипулированию данными и их анализу. Оконные функции помогают выполнять сложные вычисления в наборах строк, сохраняя при этом контекст отдельных записей. Подзапросы позволяют писать сложные запросы для ответа на сложные вопросы о данных. CTE предлагают мощный способ структурирования и упрощения SQL-запросов, делая их более читабельными и удобными для обслуживания.
Включив эти продвинутые техники в свой набор инструментов SQL, вы усовершенствуете навыки работы с SQL, чтобы решать сложные задачи, связанные с данными, получать ценные сведения или создавать информационные панели на профессиональном уровне.
Читайте также:
- Основы SQL: разница между GROUP BY и PARTITION BY
- Как выбрать между SQL и No-SQL-решениями?
- SQL в браузере — веб-оболочка DuckDB для анализа локальных данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Jiayan Yin: The Most Useful Advanced SQL Techniques to Succeed in the Tech Industry




