
«Если ты — ничто без этого костюма, не стоит его носить», — Тони Старк.
Как только появились базовые модели, обученные языкам программирования, и термин «промпт-инжиниринг» вошел в профессиональный лексикон инженеров-программистов, открылись возможности генерации кода с помощью промптов.
Как инженер-программист со всесторонним опытом работы в области архитектуры, дизайна, операционного менеджмента и программирования, я вижу причины для энтузиазма от использования ИИ в разработке ПО.
Однако исхожу из того, что экономический эффект определяется количеством усилий, вложенных в составление промптов, и качеством ответа, полученного от модели.
Некоторые проблемы сводятся к небольшим задачам — они просты в описании и имеют тривиальные решения. Их разрешение достигается путем обучения моделей, вплоть до переобучения.
Другие проблемы затрагивают сложные взаимосвязи между различными частями системы. Они трудны для осознания, их решения включают компромиссы, требующие объяснений, которые начинаются словами «это зависит».
Отдельные данные свидетельствуют о галлюцинациях и частоте отказов ИИ при решении сложных проблем. Подобные неудачи, будь они вызваны человеком, привели бы к анализу «кадрового потенциала», «плана повышения производительности» или даже к «анализу мочи».
В этой статье оценим экономический эффект — в краткосрочной и долгосрочной перспективе — написания кода с помощью ИИ при решении нетривиальных задач программной инженерии. Пример из реальной практики позволит сравнить эффективность написания кода традиционным способом и с помощью ассистента на основе ИИ.
Обучение ИИ решению сложных задач
Принцип обучения ИИ решению нетривиальных задач все тот же: покажите ИИ достаточно примеров, чтобы он смог вывести закономерности и предсказать результаты в ситуациях, аналогичных тем, в которых были собраны данные.
Когда программист запрашивает «функцию Python, которая считывает контент URL» у модели ИИ, обученной на 159 гигабайтах исходного Python-кода из 54 миллионов GitHub-репозиториев, можно не сомневаться в наличии идентичного решения в обучающем наборе. Это решение находится прямо в комментариях, практически полностью совпадающих с формулировкой данного запроса.
Если даже такого обилия обучающего материала недостаточно, можно поискать необходимые данные в ряде статей, находящихся в открытом доступе и охватывающих основные темы. Общедоступность таких публикаций в немалой степени объясняется тем, что их легче писать и использовать.
Но что происходит при работе с ИИ на языке программирования, который не входит в число мегапопулярных? Или при использовании комбинации компонентов, соединенных между собой с помощью уникального конфиденциального исходного кода, специально созданного внутри организации?
В таких ситуациях, разумеется, материала для обучения ИИ гораздо меньше. Это приводит к пробелам в обучающих данных и, как следствие, к снижению качества результатов. Этот момент будет проиллюстрирован на конкретном примере в следующем разделе. Кроме того, при работе с исходным кодом, защищенным авторским правом или доступом, часть контента может оказаться за пределами обучающих данных. Это приводит к еще большему количеству пробелов в охвате домена и еще больше снижает качество ответов.
Предвижу вопрос: «А вы не пробовали настраивать базовую модель?»
Да, тонкая настройка базовой модели — популярное решение для адаптации обученной модели ИИ к особенностям конкретного обучающего набора. Тонкая настройка модели (деятельность, подразумевающая работу с более крупной моделью ИИ и предоставление ей образцов, которые ближе к используемым в вашей организации), обходится в ничтожную — тысячную — долю от стоимости обучения модели с нуля.
Потратить мизерную долю стоимости и получить превосходные результаты — звучит как отличная экономия. Но не стоит забывать, что точка отсчета для этой экономии находится в районе десятков миллионов долларов и ежегодно возрастает в 4–5 раз. Так что выгодная цена может по-прежнему исчисляться тысячами долларов в месяц только за счет вычислительных затрат.
Предвижу возражение: «Глупости. Я могу использовать локальную LLM, обучить ее на паре GPU, купленных на eBay, и сделать все это за цену хорошего ужина».
Первая часть опровержения верна: вы можете обучить или точно настроить локальную LLM. Но вот вторая часть не имеет никакого отношения к реальной программной инженерии — разве что только к несущественному проекту выходного дня.
Экономика доработки публичной базовой модели просто повергает в ужас.
Переход от прототипа к решению на хостинге может потребовать в 27 раз больше усилий, чем было затрачено на прототип. Помимо стоимости хостинга, на котором вы либо арендуете вычислительные мощности у облачного провайдера, либо размещаете собственное оборудование, вам придется учесть, что тонкая настройка — это не только добавление знаний в конечную систему, но и улучшение языковой части модели.
В конце концов, не все образцы данных в мире полностью охватывают все возможные сигнатуры функций или команды CLI. Поэтому вам придется обратиться к шаблонам RAG (retrieval-augmented generation — генерация ответа, дополненная результатами поиска), чтобы внедрить недостающие знания в каждый промпт. А это, в свою очередь, означает, что понадобится база данных, механизм запросов и некоторое время на тонкую настройку этих дополнений к каждому промпту, предоставленному модели ИИ.
И если вы всерьез намерены использовать эту тонко настроенную модель, дополненную системой RAG, вам нужно будет разработать пайплайн для машинного обучения на основе своего решения. При разработке пайплайна вы должны определиться с метриками для отслеживания производительности модели, методами сбора этих метрик, создать процессы реагирования на обратную связь, а также процессы внедрения обновлений.
Мало того, вам может понадобиться поэкспериментировать с альтернативными методами тонкой настройки, чтобы выбрать наиболее эффективный подход для выполнения работы.
Экономический эффект всех этих усилий — исследовательский проект с серьезным повышением уровня квалификации в области новых технологий и дополнительными инженерными усилиями по созданию и эксплуатации конечного решения. И последний аргумент против экономической целесообразности обучения локализованной модели — всегда есть шанс, что стоимость следующей версии той же стартовой базовой модели превзойдет все ваши инвестиции.
Полагаю, что убедил вас в нерентабельности развертывания и эксплуатации собственной модели в небольших масштабах локального развертывания. Теперь рассмотрим реальный пример использования в генерации кода помощника на базе ИИ, основанного на публичных базовых моделях. Чтобы получить соотносимые результаты, на протяжении всего эксперимента я использовал три разных модели ИИ.
Пример из практики: конфигурация единого входа
Материал этого раздела основан на недавнем реальном примере. Моя задача была упаковать два компонента более обширного решения для физически изолированной среды (без прямого подключения к интернету в целях безопасности и контроля).
Мне нужно было настроить экземпляр HashiCorp Vault на кластере Kubernetes для защиты входов в систему с помощью OIDC-клиента, размещенного на Keycloak. HashiCorp Vault — сервис для управления секретами, а Keycloak — сервис для управления доступом к другим системам. В данном решении Keycloak используется для авторизации доступа к секретам на Vault.
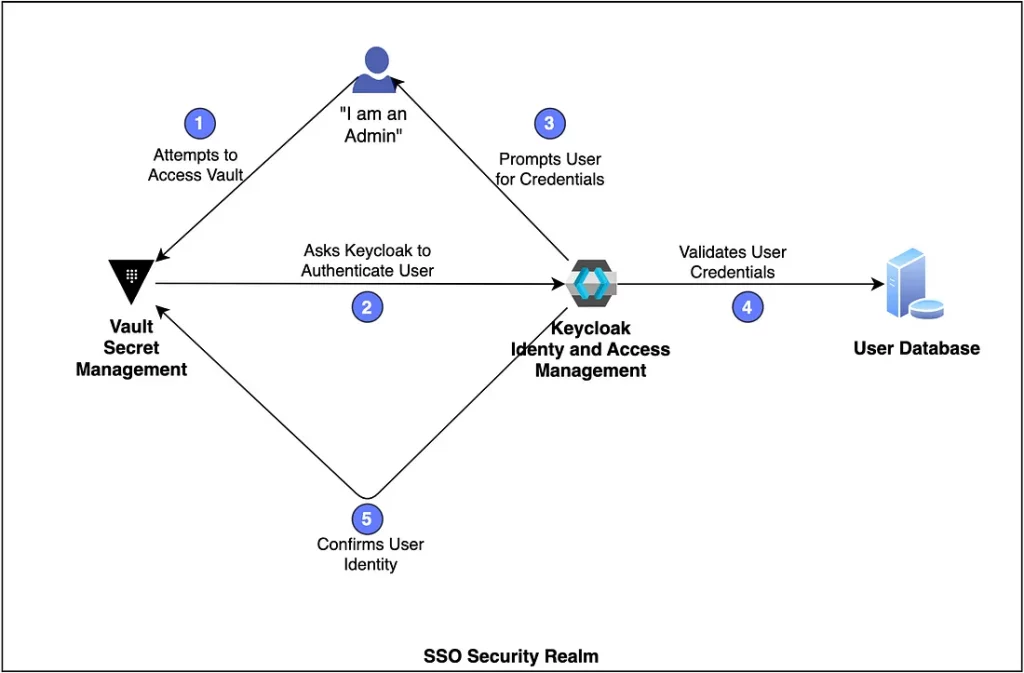
Как пример «трудной задачи», эта интеграция включает элемент программирования в сочетании с аспектами упаковки и конфигурации.
Защита доступа к Vault с помощью внешнего менеджера доступа — не такая уж редкая комбинация систем. Но Vault может работать с дюжиной средств аутентификации, включая публичные хостинговые предложения от крупнейших облачных провайдеров. Поэтому об использовании Keycloak известно значительно меньше, чем о других альтернативах.
При решении этой задачи я следовал пошаговому алгоритму, который впоследствии использовал для оценки работы ИИ.
- Поиск документации по обоим продуктам.
- Поиск API и интерфейсов командной строки.
- Ознакомление с функциями и параметрами.
- Соотношение функций и параметров с общей проблемой.
- Создание драфта первоначального решения в редакторе Notepad (или на чистой странице в редакторе кода).
- Итерация драфта в соответствии с документацией.
- Создание программы для автоматизации выполнения инструкций.
- Написание документации или заметок для компонента.
- Создание публичной статьи или технического комментария о найденном решении (если оно окажется пригодным для использования).
Кажется, работы многовато. Пора обратиться к искусственному интеллекту:
Как настроить Keycloak OIDC в качестве метода аутентификации для HashiCorp Vault? Предоставь URL-ссылки после того, как выдашь инструкции.
ИИ вывел инструкции на двух страницах. Они оказались полезными и привели меня к 5-му этапу (драфту первоначального решения).
Попытки использовать решение в готовом виде не увенчались успехом по ряду причин, что вполне ожидаемо на данном этапе. Однако неожиданные проблемы заставили меня вернуться к предыдущим этапам процесса.
Первая проблема заключалась в том, что Vault выразил недоверие к пользовательскому сертификату в URL для конечной точки обнаружения Keycloak OIDC.
Я изменил первоначальный промпт, чтобы указать, что сервер Keycloak использует пользовательский сертификат. Тем не менее ИИ, похоже, проигнорировал это замечание и не внес никаких изменений в ответы. Предполагая, что дальнейшие уточнения будут так же проигнорированы, я напрямую спросил ИИ о том, как он будет обрабатывать сообщение об ошибке. ИИ тут же исправился, выдав обновленную команду с корректным параметром.
Далее, проверяя решение и, наконец, войдя в Vault с данными пользователя, сохраненными в Keycloak, я заметил, что пользовательский интерфейс Vault показывает цифровой идентификатор пользователя вместо его электронной почты или полного имени. Узнаваемое имя обеспечивает не только приятный пользовательский опыт, но и дополнительный уровень безопасности на случай, если пользователь имеет доступ к нескольким учетным записям с различными привилегиями (что часто встречается в системных операциях).
Можно спорить о важности внесения этого изменения, но я все же объяснил ИИ проблему открытым текстом, надеясь на решение. ИИ сгенерировал еще одно обновление для одной из команд, которое не принесло желаемых результатов. После этого мне пришлось вернуться к 4-му этапу, чтобы проверить параметры команды.
Неудачное решение было вызвано тем, что параметр, предложенный ИИ («oidc_claim_mappings»), не существовал. Правильное имя параметра должно быть «claim_mappings». Отмечу, что, вопреки моим ожиданиям, интерфейс командной строки Vault не возразил против несуществующего параметра.
В результате на 5-м этапе все время, которое я выиграл, пропустив первые четыре этапа, до составления драфта решения, было потеряно (потом эти потери возникали снова и снова). Недаром говорится: «Один час отладки может сэкономить пять минут чтения документации».
Я провел итерации драфта в соответствии с документацией (6-й этап) и обратился за помощью к ИИ на 7-м этапе («Создание программы для автоматизации инструкций»).
Я попросил ИИ создать сценарий оболочки, автоматизирующий действия, связанные с Keycloak. Он создал приличную серию команд сценария оболочки, основанных на низкоуровневых утилитах, таких как «curl» и «jq». С другой стороны, ИИ жестко закодировал все URL-адреса и заполнители для учетных данных в скрипте, что было бы непростительно для разработчика-человека.
Однако более серьезной, хотя менее заметной проблемой оказалась следующая: у Keycloak уже был административный CLI. Задачи по использованию прямого доступа к конечным точкам REST с помощью «curl» и обработке ответов JSON с помощью «jq» были реализованы. Но это привело к коду, который оказался не только сложен в чтении (и сопровождении), но и чувствителен к любым будущим изменениям в API продукта.
С точки зрения экономики, этот модуль пришлось бы переписывать и перепроверять при обнаружении вопиющей ошибки, что, вероятно, совпало бы с первым изменением API в Keycloak. Кроме того, мне грозили репутационные последствия, так как во время написания кода я упустил из виду наличие целого административного CLI.
Я экспериментировал дальше с ИИ, не сообщая о существовании этого CLI. Любопытно, что в итоге ИИ изменил стратегию реализации и предложил решение с использованием соответствующего CLI, не признавая, что в предыдущих промптах предлагал неверный подход.
После завершения семи этапов работы помощь ИИ на 8-м этапе («Написание документации») произвела на меня наибольшее впечатление.
Я использовал следующий промпт:
Напиши пошаговые инструкции для решения следующей задачи, сгруппировав информацию в разделах «Обзор», «Необходимые условия», «Шаги», «Проверка», «Устранение неполадок» и «Ссылки».
Я хочу получить результат в формате Markdown, который можно использовать в файле README.md.
На каждом шаге добавь линк «Ссылка на команду» на страницу оригинальной документации, описывающую команды.
Вот задача:
Как настроить Keycloak в качестве метода аутентификации для HashiCorp Vault?
Мой сервер Keycloak работает на https://keycloak.server.com, используя пользовательский сертификат. Имя Realm — «example».
Сервер Vault работает на https://vault.server.com.
В ответ я получил практически полную техническую статью. В ней были такие проблемы, как отсутствие ссылок на страницы документации по продукту в разделе «Необходимые условия», и те же галлюцинации, что и в предыдущих шагах. Тем не менее ИИ помог мне справиться с проблемой, знакомой многим разработчикам ПО, — написанием документации в завершение творческой сессии, когда мозг, настроенный на создание решений, а не на объяснение конечного решения, уже сильно устал.
Можете прочитать (слегка отредактированную) версию ответа ИИ. Для полного предоставления информации мне пришлось исправить несколько фрагментов разметки для URL-ссылок, но это заняло всего пару минут.
Искусственный интеллект или традиционный метод?
В этом разделе я проанализирую описанный рабочий процесс, выберу «победителя» на каждом этапе (ИИ или «человеческий метод») и прокомментирую свой выбор.
Этап 1. Поиск документации к обоим продуктам
Победитель: ИИ
ИИ выдал полезные для каждого этапа процесса ссылки, встроенные в инструкции. Это потребовало меньше усилий, чем поиск в интернете.
Поиск в интернете выявил полезные записи в блогах и ссылки на Stack Overflow. Но мне пришлось прочитать несколько описаний (и рекламных объявлений), открыть страницы, чтобы просмотреть их, а затем перейти по нескольким ссылкам на сайты продуктов, чтобы найти нужные разделы документации.
Стоит отметить, что традиционный метод имеет преимущества в долгосрочной перспективе (о них расскажу позже). В данном случае я учитываю исключительно затраченное время и немедленные результаты.
Этап 2. Поиск API и интерфейсов командной строки
Победитель: ИИ
Как и на предыдущем этапе, запрос ссылок в контексте реальной задачи дал положительные результаты. Причем преимущество заключалось в том, что они были встроены в инструкции по использованию API и CLI.
На составление промпта для ИИ мне пришлось потратить времени больше, чем обычно у меня уходит на написание поискового запроса. Но это нельзя назвать дополнительной затратой времени, если учитывать объем всей деятельности.
Этап 3. Ознакомление с функциями и параметрами
Победитель: человеческий метод
Чтение руководств и изучение технологий, связанных с определенной проблемой, — фундаментальный аспект создания работоспособного решения с наименьшими эксплуатационными издержками в долгосрочной перспективе.
Драфты ИИ могут быть приемлемы для одноразового прототипа, но недопустимы для реального продукта. ИИ не может создать семантическую сеть документации продукта в человеческом мозгу или в собственных схемах. Об этом свидетельствуют как галлюцинации, связанные с параметром «oidc_claims_mapping», так и временное «белое пятно» по поводу наличия административного CLI Keycloak.
Этап 4. Соотношение функций и параметров с общей проблемой
Победитель: человеческий метод
Драфты ИИ выявляли некоторые параметры готового решения, но эти параметры были лишь частью целого. Чтение документации позволило мне гораздо лучше оценить качество исходного проекта ИИ, а также другие альтернативные варианты и соображения для адаптации решения к производственной системе.
Понимание общего диапазона конфигураций в базовых технологиях — единственный способ оценить, будет ли решение максимально стабильным при минимальной стоимости операций в производственной системе.
Этап 5. Создание драфта первоначального решения в редакторе Notepad (или на чистой странице в редакторе кода).
Победитель: ИИ
После всех итераций первоначальный драфт содержал 90 % окончательного решения, что является выдающимся результатом промпта, состоящего из одного предложения.
Традиционный метод поиска примеров в интернете позволил бы найти все элементы, необходимые для создания такого драфта. Тем не менее ИИ смог собрать их вместе гораздо быстрее и сгенерировать то, что было технической статьей с пошаговым руководством по решению проблемы.
Этап 6. Итерация драфта в соответствии с документацией
Победитель: человеческий метод
Я выполнил итерацию вместо ИИ отчасти потому, что он не смог улучшить свой (надо признать, приличный) первоначальный драфт, но в основном из-за утраты доверия к точности ИИ после устранения проблем с параметром-галлюцинацией для Vault CLI и временным «белым пятном» для CLI Keycloak.
Этот опыт совпадает с рассказами других старших инженеров о том, что чаты ИИ имеют тенденцию затухать и даже сходить на нет, как только вы начинаете добавлять больше деталей в свой запрос.
Этап 7. Создание программы для автоматизации выполнения инструкций
Победитель: человеческий метод
Если отбросить первоначальную ошибку ИИ, связанную с игнорированием административного CLI Keycloak, мне понравилось, как ИИ смог создать шаблон сценария оболочки с помощью команды «getopt».
Однако написание копии существующего сценария оболочки в нашем проекте было бы более эффективным, если бы соответствовало нашим стандартам написания кода (таким как заявления об авторских правах, соглашения об именовании, форматирование сообщений, обработка ошибок и др.).
Этап 8. Написание окончательных инструкций в Markdown-файле
Победитель: ИИ
Первоначальная запись, выполненная на 5-м этапе, выглядела как каркас технической статьи.
Стоит отметить, что ИИ с трудом справился с моей просьбой написать вывод в формате Markdown, переключившись с формата mid-text на свой формат рендеринга rich-text. При этом он не обратил ни малейшего внимания на то, насколько конкретно я пытался описать весь вывод в формате Markdown.
Кроме того, ИИ «оплошал», когда потребовалось улучшить качество ответов на уточняющие промпты. Например, он проигнорировал мои по-разному сформулированные просьбы вставить ссылки на документацию по продукту в раздел «Необходимые условия».
Однако эти проблемы были незначительными по сравнению с общим контентом.
Не стоит жалеть сил на выполнение итераций, чтобы получить окончательную версию инструкций. ИИ экономит время по сравнению с началом работы с чистого листа.
Этап 9. Создание публичной статьи или технического комментария о найденном решении
Не пробовал
Думаю, что решение представляет интерес для широкой аудитории, но у меня просто не хватило времени на написание статьи или технического комментария. Если бы у меня было время, я бы предпочел создать публикацию сам. Возможно, воспользовался бы редакторской помощью ИИ, но полностью перекладывать на него эту работу не стал бы.
Учитывая, что ИИ способен писать технические статьи «на лету», не могу представить, чтобы кто-то захотел ознакомиться с результатом выполнения чужого промпта, когда можно попросить ИИ написать что-то специально для конкретной проблемы.
Привлекательность краткосрочных (потенциальных) выгод
Если говорить о краткосрочной перспективе, то с учетом четырех «побед», одержанных каждой из сторон, и приблизительным подсчетом общих временных затрат, я объявил ничью в экономическом состязании ИИ и «человеческого метода» по созданию кода.
В зависимости от конкретных задач и используемых технологий, баланс может измениться в сторону чистой победы (прибыли) или поражения (убытков). Все определяется тем, насколько полно обучающие данные покрывают область домена.
В моем случае использовался хорошо зарекомендовавший себя продукт: Keycloak является инкубационным проектом СNCF и стандартом де-факто для управления секретами. Это обеспечило мне если не обширный, то достаточный охват обучающих данных.
ИИ изначально допустил серьезное «белое пятно» и галлюцинировал по поводу нескольких параметров. Однако он исправил свои ошибки в областях естественного языка, связанных с выявлением полезных документов и написанием драфтов документации.
Помимо этого, ИИ регулярно демонстрирует превосходство в первоначальных драфтах для коротких Python-функций, которые я часто использую в побочных задачах (таких как анализ контента Git-репозиториев, обычно требующий всего нескольких редакционных изменений).
Думаю, что использование помощников на основе ИИ для выполнения вспомогательных, простых задач — самое подходящее применение этого инструмента. Однако я испытываю по отношению к ИИ скорее умеренный энтузиазм (как при овладении когда-то сводными таблицами в Excel). Вряд ли я бы задумался о том, чтобы бросить работу и открыть компанию по разработке ПО, укомплектованную недорогими роботами-разработчиками.
Катастрофичность возможных потерь в долгосрочной перспективе
Что касается долгосрочной перспективы, то во всех спорах о выгодах и потерях программирования, основанного на промптинге, игнорируется важнейший побочный продукт цикла решения задач — накопление опыта.
Традиционные методы поиска, выявления, абстрагирования, программирования решений и проверки полученного кода предполагают осмысленный подход.
Исследуя концепции, необходимые для решения задачи, мы создаем целостную доменную модель, полную ограничений и компромиссов между элементами, которые хорошо работают в разных обстоятельствах.
Получение ответа на вопрос никогда не заставит наш мозг проделать те же шаги по обработке и сборке концептуальных «кирпичиков» искомого ответа. Более быстрые результаты при использовании репозиториев кода заставляют нас отказываться развивать собственные навыки и способности.
Этот пугающий компромисс подкрепляется амбициозными предположениями о том, что возможности ИИ растут быстрее, чем мы обесцениваем свои собственные.
Как долго сценарии, заканчивающиеся словами «убедитесь, что результаты [промпта] верны», будут оставаться актуальными в системе, где запрос этих результатов становится нормой и происходит наша коллективная атрофия навыков, необходимых для получения этих самых результатов?
Некоторые энтузиасты технологий уверяют, что генеративный ИИ — отличный инструмент обучения. Однако, по моим наблюдениям, так думают в основном опытные специалисты, осваивающие еще один навык — подкрепленный глубокими знаниями в нескольких областях, — а не те, кто находится в начале карьерного пути.
Нередко можно услышать и контраргумент в форме вопроса: «А вы бы предпочли писать код на Ассемблере?». Неужели люди не видят разницы между использованием языка с более высоким уровнем абстракции и когнитивным процессом, в котором предпочтение отдается формированию вопросов, а не абстракции и рассуждениям?
К тому же мало кто признает, что обращение за помощью, лежащее в основе создания кода с помощью промптов, само по себе является развитым навыком.
Возможно, в целом речь идет об индустриальной революции, но индустриальные революции открывают не используемые ранее ресурсы, а это не тот случай.
Генеративный ИИ использует существующие ресурсы, которые уже изучены и нашли различные способы применения. При этом он опирается на поиск ресурсов, ограниченный общедоступными источниками, и на использование образцов данных, закрепляющих опыт на момент их извлечения.
Попутно весь этот процесс ставит под угрозу ранние этапы формирования кадрового резерва, что чревато утратой квалификации авторами контента, создающими исходный материал, от которого зависит ИИ.
Должен быть более перспективный путь.
Читайте также:
- Как писать промпты для ChatGPT
- BabyAGI — автономный ИИ-агент для оптимизации задач
- Создание Copilot для визуального распознавания в Azure
Читайте нас в Telegram, VK и Дзен
Перевод статьи Denilson Nastacio: The Conflicted Economics of Prompt Engineering in Software Development





