
Оконные функции — это ключ к написанию эффективного и понятного SQL-кода. Понимание того, как они работают и когда их следует использовать, откроет новые пути решения проблем с отчетностью.
Цель этой статьи — дать представление об оконных функциях SQL, излагая материал доступно и последовательно, чтобы вам не пришлось полагаться только на запоминание синтаксиса.
Вот что мы рассмотрим:
- Как следует понимать оконные функции.
- Множество примеров, приводимых по возрастанию сложности.
- Конкретный реальный сценарий, позволяющий применить полученные знания на практике.
- Анализ полученных знаний.
Наш набор данных прост: шесть строк данных о доходах двух регионов в 2023 году.
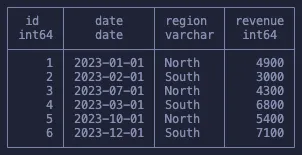
Оконные функции — это подгруппы
Если к этому набору данных применить сумму GROUP BY в отношении доходов каждого региона, будет понятно, что произойдет. В результате останется только две строки, по одной для каждого региона, а также сумма доходов:

Действие оконных функций очень похоже на то, что мы только что описали, но вместо сокращения количества строк, агрегация выполняется “в фоновом режиме”, а значения добавляются к существующим строкам.
Сначала пример:
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER () as total_revenue
FROM
sales
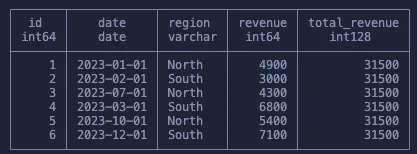
Обратите внимание: мы обошлись без оператора GROUP BY и изменения количества строк в наборе данных. И все же нам удалось получить сумму всех доходов. Прежде чем углубиться в то, как это работает, вкратце рассмотрим полный синтаксис оконной функции.
Синтаксис оконной функции
Синтаксис выглядит следующим образом:
SUM([some_column]) OVER (PARTITION BY [some_columns] ORDER BY [some_columns])
Разберем каждый элемент этого запроса:
- Агрегация или оконная функция:
SUM,AVG,MAX,RANK,FIRST_VALUE.
- Ключевое слово
OVER, указывающее на то, что это оконная функция.
PARTITION BYопределяет группы.
ORDER BYопределяет, является ли данная функция скользящей (рассмотрим ее позже).
Не стоит задумываться о том, что означает каждый из этих элементов: их значения прояснятся при рассмотрении примеров. Пока достаточно запомнить, что для определения оконной функции используется ключевое слово OVER. И, как следует из первого примера, это единственное требование.
Порядок вычислений в оконной функции
Теперь посмотрим, как выполнить группирование данных в оконной функции. Сохраним первоначальные вычисления для демонстрации возможности запускать более одной оконной функции одновременно. Это означает, что оконная функция позволяет выполнять различные агрегации в одном запросе без использования подзапросов.
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (PARTITION BY region) as region_total,
SUM(revenue) OVER () as total_revenue
FROM sales
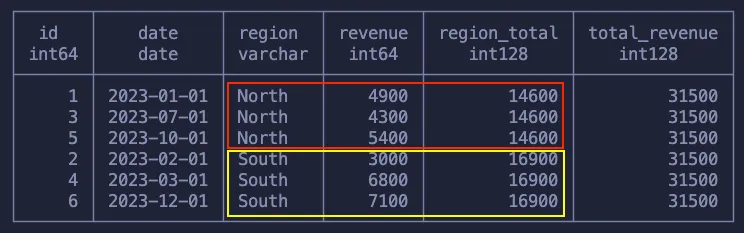
Как уже говорилось, PARTITION BY определяет группы (окна), используемые агрегирующей функцией. Итак, сохранив неизменным набор данных, получаем:
- Общий доход для каждого региона.
- Общий доход для всего набора данных.
Мы не ограничены одной группой. Аналогично GROUP B, можно разделить данные, например, по регионам и кварталам:
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (PARTITION BY
region,
date_trunc('quarter', date)
) AS region_quarterly_revenue
FROM sales
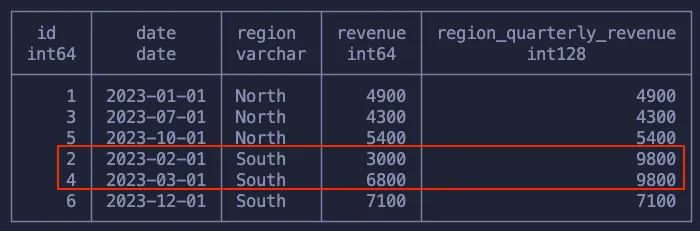
Как следует из приведенной выше таблицы, только две точки данных сгруппировались по региону и кварталу!
Надеюсь, теперь понятно, что оконную функцию можно рассматривать как выполнение GROUP BY, но без уменьшения количества строк в наборе данных. Конечно, это не всегда нужно, хотя не так уж редко встречаются запросы, в которых данные сначала группируют, а затем присоединяют обратно к исходному набору данных, усложняя то, что могло бы быть единой оконной функцией.
Переходим к ключевому слову ORDER BY. Оно определяет функцию скользящего окна. Вы наверняка хоть раз в жизни слышали о скользящей сумме (Running Sum). Если нет, стоит обратиться к примеру, чтобы все стало понятно.
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (ORDER BY id) as running_total
FROM sales
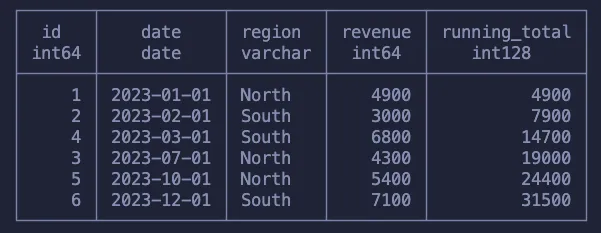
Здесь построчно суммируется доход со всеми предыдущими значениями. В данном случае вычисления выполняются в соответствии с порядком столбца id (хотя это мог быть и любой другой столбец).
Данный пример не особенно полезен, поскольку в нем суммируются данные по случайным месяцам и двум регионам. Но используя полученные знания, можно теперь вычислить суммарный доход по региону. Для этого применим скользящую сумму в каждой группе.
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (PARTITION BY region ORDER BY date) as running_total
FROM sales
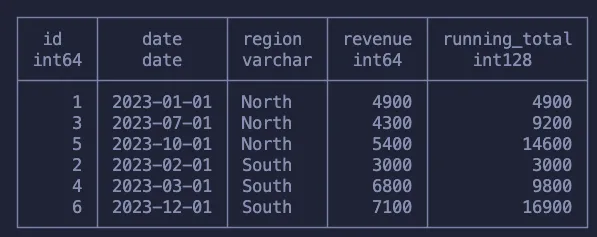
Разберем, что здесь происходит:
- Проходим по всем регионам месяц за месяцем и суммируем доходы.
- Выполним вычисления для одного региона, переходим к следующему, начиная с нуля и снова двигаясь дальше по месяцам.
Интересно заметить, что при написании этих скользящих функций используется “контекст” других строк. Иными словами, для получения скользящей суммы в одной точке необходимо знать предыдущие значения для предыдущих строк. Это становится более очевидным при ручной выборке количества последующих/предыдущих строк, которые необходимо агрегировать.
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (ORDER BY id ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING)
AS useless_sum
FROM
sales
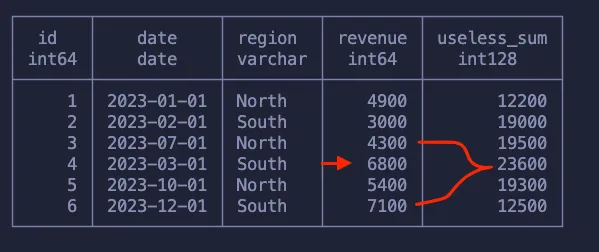
В этом запросе указывается, что для каждой строки необходимо выбрать одну строку позади и две строки впереди, чтобы получить сумму этого диапазона! Такая возможность, дающая полный контроль над группированием данных, позволяет чрезвычайно эффективно решать различные задачи.
Наконец, последнее, что стоит разобрать, прежде чем перейти к более сложному примеру, — это функция RANK. Ее часто включают в вопросы для собеседования. Логика, лежащая в ее основе, такая же, как и во всем, что мы видели до сих пор.
SELECT
*,
RANK() OVER (PARTITION BY region ORDER BY revenue DESC) as rank,
RANK() OVER (ORDER BY revenue DESC) as overall_rank
FROM
sales
ORDER BY region, revenue DESC
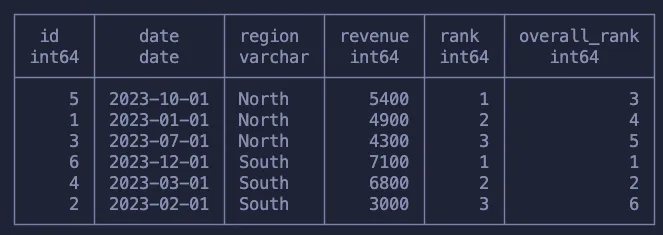
Как и раньше, используем ORDER BY, чтобы указать порядок, которого надо придерживаться, идя построчно, и PARTITION BY, чтобы указать подгруппы.
В первом столбце ранжируется каждая строка в рамках каждого региона, что означает, что у нас будет несколько “ранжированных” строк в наборе данных. Второй столбец — это ранги всех строк в наборе данных.
Заполнение пропущенных впереди данных
Такая проблема возникает время от времени, и для ее решения в контексте SQL требуется активное использование оконных функций. Для рассмотрения этого понятия будем использовать другой набор данных, содержащий временные метки и измерения температуры. Наша цель — заполнить строки, в которых отсутствуют измерения температуры, последним измеренным значением.
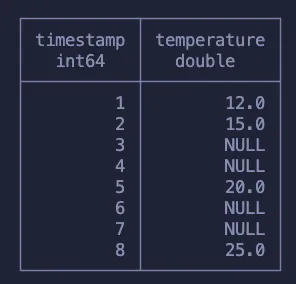
Вот что ожидается получить в итоге:
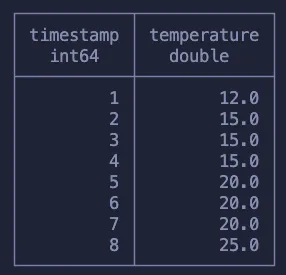
Стоит отметить, что при использовании Pandas эту проблему можно решить запуском df.ffill(). Однако при работе с SQL подобная задача становится немного сложнее.
Первый шаг к ее решению заключается в том, чтобы каким-то образом сгруппировать NULL-значения с предыдущим ненулевым значением. Важно понимать, что для этого потребуется скользящая функция. То есть это функция, которая будет “проходить строку за строкой”, определяя, когда встретится нулевое значение, а когда — ненулевое.
Решением является использование COUNT и, более конкретно, вычисления значений измерений температуры. В следующем запросе выполняются как обычные скользящие вычисления, так и вычисления значений температуры.
SELECT
*,
COUNT() OVER (ORDER BY timestamp) as normal_count,
COUNT(temperature) OVER (ORDER BY timestamp) as group_count
from sensor
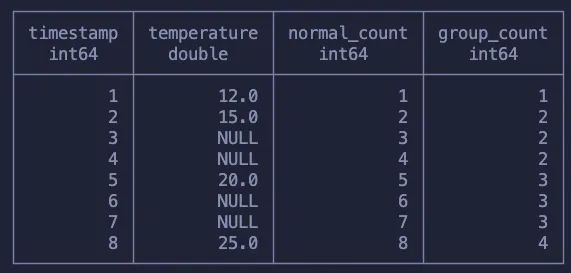
- В первом случае подсчитывается каждая строка по возрастающей.
- Во втором случае подсчитывается каждое значение температуры, не считая тех случаев, когда оно было NULL.
Колонка normal_count бесполезна для нас — это просто пример того, как выглядит скользящая функция COUNT. Однако второе вычисление, group_count, приближает нас к решению задачи!
Обратите внимание: этот способ подсчета гарантирует, что подсчитывается первое значение, стоящее непосредственно перед первым NULL, а затем, когда функция встречает NULL, ничего не происходит. Это обеспечивает “тегирование” каждого последующего NULL тем значением, которое было до прекращения измерения.
Чтобы двигаться дальше, скопируем первое тегированное значение во все остальные строки в той же группе. То есть для группы 2 все строки должны быть заполнены значением 15.0.
Как думаете, какая функция поможет это сделать? На данный вопрос есть не один ответ, но, надеюсь, хотя бы понятно, что сейчас мы рассматриваем простую оконную агрегацию с PARTITION BY.
SELECT
*,
FIRST_VALUE(temperature) OVER (PARTITION BY group_count) as filled_v1,
MAX(temperature) OVER (PARTITION BY group_count) as filled_v2
FROM (
SELECT
*,
COUNT(temperature) OVER (ORDER BY timestamp) as group_count
from sensor
) as grouped
ORDER BY timestamp ASC
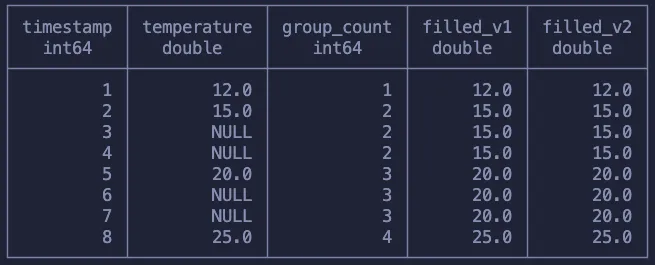
Чтобы добиться желаемого результата, можно использовать как FIRST_VALUE, так и MAX. Главное — получить первое ненулевое значение. Поскольку известно, что каждая группа содержит одно ненулевое значение и множество нулевых значений, обе эти функции работают!
Данный пример — отличный способ попрактиковаться в работе с оконными функциями. Если хотите решить похожую задачу, попробуйте добавить два датчика, а затем заполнить значения предыдущим показанием этого датчика. Что-то вроде этого:
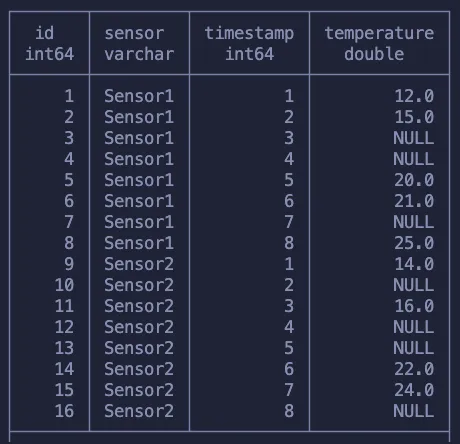
Можете это сделать? Тут не используется ничего, чего вы не узнали из вышеизложенного.
Теперь вы знаете, как работают оконные функции в SQL, так что пора переходить к выводам!
Подведение итогов
Что вы узнали:
- Ключевое слово
OVERиспользуется для написания оконных функций.
PARTITION BYиспользуется для указания подгрупп (окон).
- Если используется только ключевое слово
OVER(), то окном будет весь набор данных.
ORDER BYиспользуется, когда нужна скользящая функция, то есть для построчного вычисления.
- Оконные функции полезны, когда требуется сгруппировать данные для выполнения агрегирования, и при этом надо сохранить датасет в первоначальном виде.
Все изображения принадлежат автору, если не указано иное.
Читайте также:
- Полное руководство по CASE WHEN в SQL
- Индексирование в MySQL: руководство для начинающих
- Простой прием для молниеносных запросов LIKE и ILIKE
Читайте нас в Telegram, VK и Дзен
Перевод статьи Mateus Trentz: Understand SQL Window Functions Once and For All





